Python 爬虫(二)爬虫基本入门
在公司做了一次分享,顺便发个博客
一.什么是爬虫
1.定义
是一种按照 一定的规则,自动地抓取 万维网 信息的 程序或者 脚本.
爬虫是一个模拟浏览器进行HTTP 请求的过程。
2.目的
从网上抓取出来大量你想获取类型的数据,然后用来分析大量数据的类似点或者其他信息来对你所进行的工作提供帮助
3.为什么选取Python做爬虫
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如 Requests , mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的 beautifulsoap 提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
二.http协议概要
1.http协议
HTTP 协议是互联网应用中,客户端(浏览器)与服务器之间进行数据通信的一种协议。协议中规定了客户端应该按照什么格式给服务器发送请求,同时也约定了服务端返回的响应结果应该是什么格式。

一次完整的HTTP请求到响应的过程需要的步骤有哪些?
1. 域名解析
就是将网站名称转变成IP地址:localhost-->127.0.0.1 像什么hosts文件,DNS域名解析等等可以实现这种功能2. 发起TCP的3次握手
三次握手:
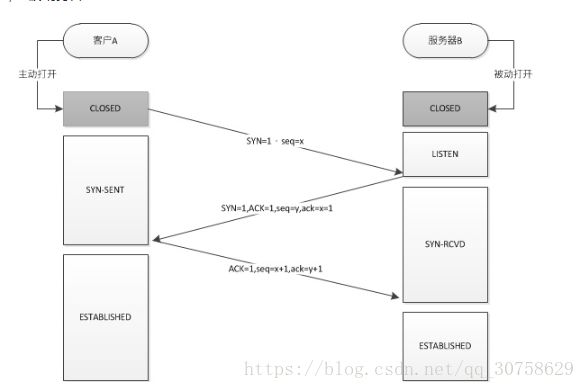
1.客户端发个请求“开门呐,我要进来”给服务器
2.服务器发个“进来吧,我去给你开门”给客户端
3.客户端有很客气的发个“谢谢,我要进来了”给服务器3. 建立TCP连接后发起http请求
a、请求行:包含请求方法、URI、HTTP版本信息
b、请求首部字段
c、请求内容实体4. 服务器端响应http请求,浏览器得到html代码
a、状态行:包含HTTP版本、状态码、状态码的原因短语
b、响应首部字段
c、响应内容实体5. 浏览器解析html代码,并请求html代码中的资源 6. 浏览器对页面进行渲染呈现给用户
三.辅助做爬虫的功能模块
1.requests
https://www.imooc.com/learn/736
requests 实现了 HTTP 协议中绝大部分功能,它提供的功能包括 Keep-Alive、连接池、Cookie持久化、内容自动解压、HTTP代理、SSL认证、连接超时、Session等很多特性,最重要的是它同时兼容 python2 和 python3。
请求方式:
http协议主要有那几个方法?
import requests
requests.get( "http://www.baidu.com" )
requests.post( "http://www.baidu.com" )
#requests.put("http请求")
#requests.delete("http请求")
#requests.head("http请求")
#requests.options("http请求")
(1).GET请求:
a.带参数GET请求
import requests
response = requests.get( "http://httpbin.org/get?name=gemey&age=22" )
print (response.text)
b.带请求头
#coding:utf-8
import requestsheads = {} header = { "User-Agent" : UA,
"Referer" : "https://ke.youdao.com/login" ,
"Cookie" : ""
}
response = requests.get( 'http://www.baidu.com' , headers =heads)
(2).POST请求:
#coding:utf-8
import requestsdata = { 'name' : 'tom' , 'age' : '22' }response = requests.post( 'http://httpbin.org/post' , data =data).status_code
#需要加cokkie使用下面的请求模式,get请求格式一致
#response = requests.post( 'http://httpbin.org/post' , data =data, cookies=cookies ).status_code
print response
(3).
持续保持同一会话
会话对象requests.Session能够跨请求地保持某些参数,比如cookies,即在同一个Session实例发出的所有请求都保持同一个cookies,而requests模块每次会自动处理cookies,这样就很方便地处理登录时的cookies问题。在cookies的处理上会话对象一句话可以顶过好几句urllib模块下的操作。
#coding:utf-8
import requests
#创建一个session对象
session = requests.Session() #保持同一会话的核心
# 用session对象发出get请求,设置cookies
session.get( 'http://httpbin.org/cookies/set/number/12345' )
response = session.get( 'http://httpbin.org/cookies' ) print (response.text)
由于http协议是一个种无状态的协议,为了使这种无状态变得有状态,引进了会话,简单的讲,就是通过session去记录这个状态。 当一个用户第一次请求web服务的时候,服务器会生成一个session,用于保存这个用户的信息;同时,服务器在返回给用户端时,会把这个sessionID保存在cookies里。 当用户再一次请求的时候,浏览器会把这个cookies带上 。因此在服务器端就能知道多次请求是否为同一个用户。因此我们可以 直接用cookies来登陆 ,我们直接请求数据,在请求的时候,把cookies带上就行了。 这样就极大的方便了登陆过程。
session:将用户信息存储在服务端达到保留状态的目的,压力从浏览器转到服务器
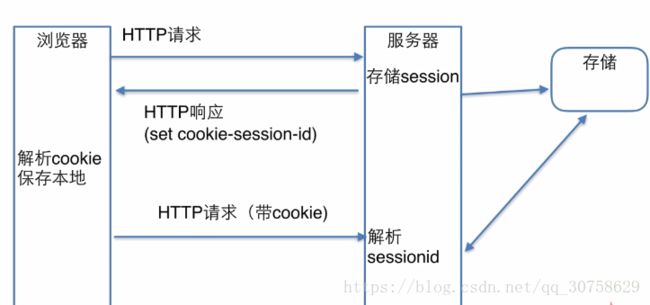
cookie:将用户信息存储在客户端达到保留状态的目的
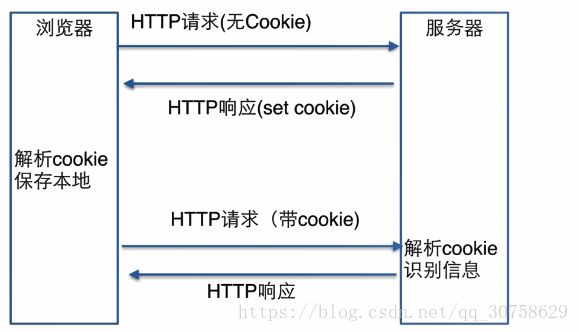
每次请求都要带着cookie,占用带宽,明文存储不安全
(4).证书取消验证
#coding:utf-8
import requests from requests.packages import urllib3urllib3.disable_warnings() #从urllib3中消除警告 response = requests.get( 'https://www.12306.cn' , verify = False ) #证书验证设为FALSE print (response.status_code)
(5).超时异常
#coding:utf-8
import requests from requests.exceptions import ReadTimeout try : res = requests.get( 'http://httpbin.org' , timeout = 0.1 ) print (res.status_code) except ReadTimeout: print (timeout)
(6).服务返回结果用法
#coding:utf-8
import requests
response = requests.get( 'http://www.baidu.com' )
print response.status_code # 打印状态码
print response.url # 打印请求url
print response.headers # 打印头信息
print response.cookies # 打印cookie信息
print response.text #以文本形式打印网页源码
print response.content #以字节流形式打印
2.bs4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
(1).创建beautifulsoup对象
# coding: utf-8
from bs4 import BeautifulSoup
import requests
html=requests.get( "http://www.baidu.com" ).text
soup = BeautifulSoup(html, "html.parser" ) #html可以是html内容
print type (soup)
(2).输出beautifulsoup对象及解析
a.标签(tag)分析
print soup.title #第一个title标签的内容
print soup.head #第一个 head 标签的内容
print soup.p #第一个p标签的内容
print soup. a #第一个 a 标签的内容
print u"标签对象: "
print type (soup.a)
print soup.a.name #第一个a标签本身名称
print soup.a.attrs #打印所有的属性
print soup.a[ "name" ] #获取属性值
print soup.get( "name" ) #同上
(3).NavigableString (标签内容)
print soup.title.string #打印第一个title标签的内容
print type (soup.a.string)
(4).html结构化分析
a.子节点
print soup.head.contents
print u"子节点内容类型: "
print type (soup.head.contents)
print u"生成器方式存储子节点: "
print soup.head.children
b.子孙节点
for i in soup.body.descendants: #生成结果也是生成器的方式
print i #结果也是一层一层向内部解析输出,对比结果体会
节点内容及多个节点内容
print soup.body.string#包含多个节点,所以无法确定打印哪个节点内容,所以结果为None
print soup.body.strings#获取所有子节点内容
print soup.body.stripped_strings#对内容中存在空行做处理
c.父节点
print soup.body.parent
content = soup.head.title.string#获取一个NavigableString对象
print content.parent.parent#获取父节点的父节点并打印
content.parent.parents#递归获取元素所有的父辈节点然后存成一个生成器,通过遍历可以输出
for i in content.parents:
print i.name
d.兄弟节点
print soup.a.next_sibling#此节点的下一个兄弟节点
print soup.p.previous_sibling#此节点的上一个兄弟节点
print soup.a.next_siblings#此节点的下一个兄弟节点,存储结果为生成器
print soup.p.previous_siblings#此节点的上一个兄弟节点,存储结果为生成器
for i in soup.a.next_siblings:#遍历所有下面兄弟节点
print i
e.前后节点
print soup.a.next_element#针对于所有节点中后节点
print soup.a.previous_element #针对于所有节点中前节点
print soup.a.next_elements#针对于所有节点中所有后节点
print soup.a.previous_elements #针对于所有节点中所有前节点
(5).遍历文档结构查询
Find_all
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
a.name参数 字符串
print soup.find_all( 'a' )
b.正则表达式
import re
for tag in soup.find_all(re.compile( "^b" )):
print (tag.name)
c.传属性参数筛选
import re
print soup.find_all( id = 'link2' )#搜索有id属性并且对应值为 link2
print soup.find_all( href =re.compile( "elsie" ))#搜索有href属性并且符合正则表达式值得结果
print soup.find_all( href =re.compile( "elsie" ), id = 'link1' )#同时满足两个条件得结果
print soup.find_all( "a" , class_ = "sister" )#对于类似class需要后面加上_
print soup.find_all( attrs ={ "class" : "title" })#attrs传键值对条件
d.text参数
print soup.find_all( text = "Lacie" )#搜索一个内容
print soup.find_all( text =[ "Tillie" , "Elsie" , "Lacie" ])#一次搜索三个内容
print soup.find_all( text =re.compile( "Dormouse" ))#根据正则表达式搜索内容
e.limit 参数
soup.find_all( "a" , limit = 2 )#对筛选结果筛选两个内容
(6).CSS选择器
a.过标签名查找
print soup.select( 'title' )#直接原值表示标签名
b.通过类名查找
print soup.select( '.sister' )#.加值代表类名
c.通过id查找
print soup.select( '#link1' )##字符代表id
d.组合查找
print soup.select( 'p #link1' )#p标签且id为link1得对象
print soup.select( "head > title" )#head标签下得title标签
print soup.select( 'p a[href="http://example.com/elsie"]' )#p标签下a属性得href值*对象
三.实战练习
见exercise.py
四.课后作业
抓取带有套餐,优惠券的课程详情页url,分别保存在文档中(txt,excel 均可)