Apache SeaTunne简介
Apache SeaTunne简介
文章目录
- 1.Apache SeaTunne是什么?
-
- 1.1[官网](https://seatunnel.apache.org/)
- 1.2 项目地址
- 2.架构
- 3.特性
-
- 3.1 丰富且可扩展的连接器和插件机制
- 3.2 支持分布式快照算法以确保数据一致性
- 3.3 支持流、批数据处理,支持全量、增量和实时数据集成处理
- 3.4 多引擎支持
- 3.5 JDBC多路复用
- 3.5 高吞吐量和低延迟
- 3.6 完善的实时监控
- 3.7 支持两种作业开发方法:编码和画布设计
- 4.支持引擎对比
- 5.数据集成工具对比
- 6.官方好文分享
- 7.总结
1.Apache SeaTunne是什么?
Apache SeaTunne(前身 Waterdrop,2021 年 10 月更名为 SeaTunnel 并申请加入 Apache孵化器) 是一个分布式、高性能、易扩展、用于海量数据(离线 & 实时)同步和转化的数据集成平台。
1.1官网
https://seatunnel.apache.org/
1.2 项目地址
https://github.com/apache/seatunnel
https://github.com/apache/seatunnel#apache-seaTunnel-web-project
2.架构

架构的核心思想就是:
input—>transform—>output
输入 -> 转换 -> 输出
3.特性
3.1 丰富且可扩展的连接器和插件机制
SeaTunnel提供了一个不依赖于特定执行引擎的连接器API。基于此API开发的连接器(Source, Transform, Sink)可以在许多不同的引擎上运行,例如当前支持的SeaTunnel Engine, Flink和Spark,插件设计允许用户轻松开发自己的连接器并将其集成到SeaTunnel项目中。目前,SeaTunnel支持100多个连接器,而且这个数字还在飙升。
3.2 支持分布式快照算法以确保数据一致性
3.3 支持流、批数据处理,支持全量、增量和实时数据集成处理
基于SeaTunnel Connector API开发的连接器完美兼容离线同步、实时同步、全同步、增量同步等场景。它们大大降低了管理数据集成任务的难度
3.4 多引擎支持
SeaTunnel默认使用SeaTunnel引擎进行数据同步。SeaTunnel还支持使用Flink或Spark作为连接器的执行引擎,以适应企业现有的技术组件。SeaTunnel支持多个版本的Spark和Flink
3.5 JDBC多路复用
数据库日志多表解析:SeaTunnel支持多表或整个数据库同步,解决了JDBC过度连接的问题;支持多表或全数据库的日志读取和解析,解决了CDC多表同步场景需要处理日志重复读取和解析的问题
3.5 高吞吐量和低延迟
SeaTunnel支持并行读写,提供稳定可靠的高吞吐量和低延迟的数据同步能力
3.6 完善的实时监控
SeaTunnel支持对数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
3.7 支持两种作业开发方法:编码和画布设计
可视化界面操作集成作业管理:SeaTunnel web项目seatunnel-web提供了作业、调度、运行和监控功能的可视化管理
以上是我总结的关于Apache SeaTunne的主要特性,官方还有详细的说明,可以参看官方文档
4.支持引擎对比
Apache SeaTunne默认使用的是自研的SeaTunne Zeta引擎,还支持Spark、Flink计算引擎

5.数据集成工具对比
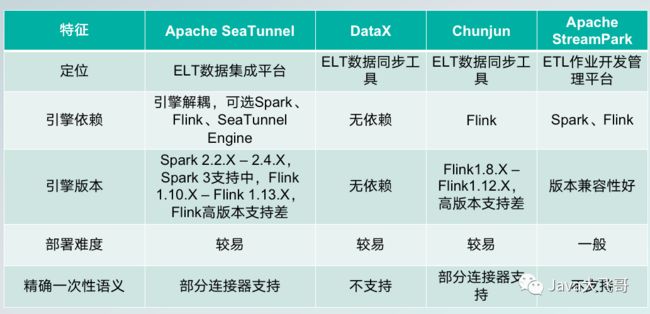
Apache SeaTunne和Apache StreamPark可以说是平台,而DataX和Chunjun只能说是工具。
6.官方好文分享
基于 SeaTunnel 构建 CDC 流式应用
https://mp.weixin.qq.com/s/3G_8JhePUexvuX1acV7dvg
Apache SeaTunnel Web部署指南
https://mp.weixin.qq.com/s/eNWGP_09Oh4pHdoQkmGPzg
基于Apache SeaTunnel 的数据精确一致性技术实践
https://mp.weixin.qq.com/s/cn9QCS-o8fYkilPHUoT_9g
SeaTunnel 与 DataX 、Sqoop、Flume、Flink CDC 对比
https://mp.weixin.qq.com/s/ayQIz7ImOI_IhaOmMB5pnA
从 0 到 1 快速入门 Apache SeaTunnel ,新一代数据集成平台的原理和实践
https://mp.weixin.qq.com/s/i631_RTIuTBAvsOeow0F7Q
7.总结
本文使用简短精炼的文字向大家介绍了Apache SeaTunne,相信通过本文对Apache SeaTunne有了跟多的认识,后面的文章会向大家分享在CentOs7.x上部署遇到的坑和windows10电脑上本地构建Apache SeaTunne运行mysql-jdb to mysql-jdbc的单表同步的demo以及断点调试欣赏Apache SeaTunne的源码和牛皮的设计思想,希望我的分享对你有所帮助,请一键三连,么么么哒!