Nacos集群raft选举算法原理
Nacos集群raft选举算法原理
通过本文章你将获得raft算法选举原理并了解nacos是怎么实现该算法。
Raft算法
Nacos Discovery为了保证集群中数据一致性,采用Raft算法。通过对日志进行复制达到一致性的算法,Raft通过选举Leader并由Leader节点负责管理日志复制来实现各个节点间数据一致性。
Raft不是强一致算法,是最终一致性算法。
raft 算法演示地址 :http://thesecretlivesofdata.com/raft/
Nacos与CAP
默认情况下Nacos集群默认是AP,但也支持CP模式,需要进行转换。提交PUT请求完成AP到CP转换。
PUT请求:localhost:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP
角色转换

在Raft中,节点有三种角色:
Leader:唯一负责处理客户端写请求的节点,也可以处理客户端读请求,同时负责日志复制工作,整个集群只有一个Leader。Candidate:Leader选举的候选人,其可能会成为Leader。Follower:可以处理客户端读请求,负责同步来自于Leader的日志,当接收到其它Cadidate的投票请求后可以进行投票,当发现Leader挂了其会转变为Cadidate发起选举。
term:任期。一个新的Leader具有一个新的term,这个新term是上一个leader的term基础上加一获取到的。
Leader选举
选举过程主要分为三个阶段:选举、投票、结果处理。
我要选举
若follower在心跳超时范围内没有接收到来自于leader的心跳,则认为leader挂了,若在以下步骤还未发生时,接收到了其它cadidate的投票请求,则会先向其投票,然后follower会完成 以下步骤:
- 使其本地term增一(同步于leader)。
- 由follower转变为candidate。
- 向自己投一票(一个term内只能投一票)。
- 向其它节点发出投票请求,然后等待响应。
我要投票
follower在接收到投票请求后,其会根据以下情况来判断是否投票:
- 发来投票请求candidate的term编号不能小于我的term编号。
- 在我当前term内我还的票还未投递。
- 发来投票请求candidate的log编号不能于小我的log编号。
- 在我的选票尚未投出去时,接收到多个candidate请求,采取first-come-first-sverved(先来先服务)。
选举结果
当一个candidate发现投票请求后会等待其它节点的响应结果。这个响应结果可能有三种情况:
- 收到过半选票,成为新的leader,会将消息广播给其它节点,告诉大家我的新的leader(包含当前term)。
- 接收别的candidate发来新的leader通知,比较新leader的term并不比我的term小,则自己变follower。
- 经过一段时间后,没有收到过半票数,也没有收到新leader通知,则重新发出选举。
票数相同
若在选举过程中出现了各个candidate票数相同情况,无法选出leader。采用randomized election timeouts(随机选举发起时间)解决该问题,其会让这些candidate的选举在一个给定范围内随机timeout之后开始,此时先到达timeout的candidate会首先发出投票请求,并优先获取选票。
数据同步
Raft算法一致性的实现,是基于日志复制状态机的。状态机的最大特征是,不同的状态机若当前状态相同,然后接受了相同的输入,则一定会得到相同的输出。

当leader接收到client的写操作请求后,大体会经历以下流程:
- leader将数据封闭为日志。
- 将日志进行发送给follower,然后等待follower响应。
- 当leader接收到过半响应后,将日志commit到状态机,日志状态变为commited。
- leader向client响应。
- leader通知所有follower将日志apply到它们本地状态机,日志状态变为applied(也是commited状态只是leader和follower叫法不一样)
AP支持

Log由term index、log index及command构成。为了保证可以用性,各个节点中的日志可以不完全相同,但leader会不断给follower发送log,以使各个节点的log最终相同。实现最终一致性算法。
脑裂
在多机房部署中,由于网络连接问题,很容易形成多个分区。而多个分区的形成很容易产生脑裂,从而导致数据不一致。下面三机房部署为例进行分析,根据机房断网情况分为五种情况:
情况一

这种情况下,B机房中主机是感知不到时leader的存在的,所以B机房中的主机会发起新一轮的leader选举。由于B机房与C机房是相连的,虽然C机房的follower能够感知到A机房的leader,但由于接收到了更大term的投票请求,所以C机房的follower也就放弃了A机房的leader,参与了新leader选举,最终在B机房中会再产生一个新leader。
B机房中leader联合了C机房,所以其能够获取到过半的响应,所以其可以成功处理写操作请求。但这个写操作并不会被同步到A机房,A机房中的leader由于无法获取过半响应而无法处理写操作请求,不过并没有被“下课”,其仍为leader。所以A机房中的数据是不会发生变更的。故A机房与B、C机房中出现脑裂,且形成数据不一致。
解决方法有很多:follower长时间未响应将leader变为follower、在选举过程中解决该问题、在选举后解决该问题。
情况二

与情况一基本是一样的,不同的地方是新leader可能会产生B与C两个机房中。
情况三

无影响。
情况四

无影响。
情况五
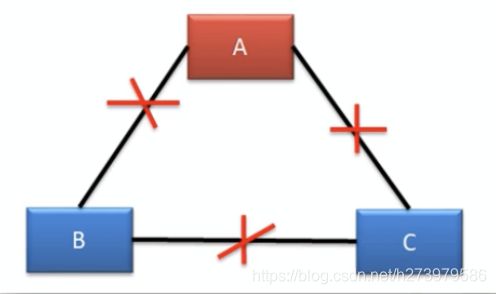
A机房无法处理写操作请求,但可以对外提供读服务。
B、C机房失去了leader,均会发起选举,由于投票数据不过半所以无法选举出新leader。
Leader宕机
请求到达前leader挂了
client发送写操作请求到达leader之前leader挂了,因为请求还没有到达集群,所有这个请求对于集群来说就没有存在过,对集群数据的一致性没有任何影响。leader挂了之后,会选举产生新的leader,由于stale leader并未向client发送成功接收响应,所以client会重新发送该写操作请求。
未开始同步数据前leader挂了
client发送写操作请求到leader,请求到达leader后,leader还没有开始向followers复制数据leader就挂了,此时数据为uncommited状态,这时会选举产生新的leader,之前挂掉的leader重启后作为follower加入集群,并同步新leader中的数据以保证数据一致性。之前接收到client的uncommited状态数据丢弃。由于state leader并未向client发送成功接收响应,所以client会重新发送该写操作请求。
同步完了一小半leader挂了
client发送写操作请求到leader,leader接收完数据后开始向follower复制数据,在复制完一小部分(未过半)follower后leader挂了,此时follower中这些已经被接收到的数据状态为uncommited。由于leader挂了,就会发起新leader选举,并且新leader会在这些接收了数据的follower中产生,新leader产生后所有节点开始从新leader同步数据,其中就包含前面的uncommited数据,由于state leader并未向client发送成功接收响应,所以client会重新发送该写操作请求。所以raft算法要求各个节点自身要实现去重机制,以避免数据的重复接收。
过半复制完毕leader挂了
client发送写操作请求到leader,leader在接收到过半节点完毕响应后,leader将日志写入到状态机,日志状态变为了committed。在leader还未向follower发送apply通知时leader挂了,此时会选举出新leader,且一定是在接收过日志的主机中产生。由于stale leader还未向client发送成功接收响应,所以client会重新发送该写操作请求。所以raft算法要求各个节点自身要实现去重机制,以避免数据的重复接收。