尚硅谷Docker笔记-高级篇
1.Docker复杂安装
1.1安装mysql主从复制搭建步骤
1.新建主服务器容器实例3307
docker run -p 3307:3306 --name mysql-master \
-v /mydata/mysql-master/log:/var/log/mysql \
-v /mydata/mysql-master/data:/var/lib/mysql \
-v /mydata/mysql-master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
docker ps
mysql8.0 记得多加上映射卷:
-v /MySql80Data/mysql-master/files:/var/lib/mysql-files/
2.进入/mydata/mysql-master/conf目录下新建my.cnf。
vim my.cnf(注意是cnf不是conf),粘贴以下内容
[mysqld]
##设置server_id,同一局域网中需要唯一
server_id=101
##指定不需要同步的数据库名称
binlog-ignore-db=mysql
##开启二进制日志功能
log-bin=mall-mysql-bin
##设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
##设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
##二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
##跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
##如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
3.修改完配置后重启master实例
docker restart mysql-master
docker ps
4.进入mysql-master容器
docker exec -it mysql-master /bin/bash
mysql -uroot -proot
> show databases;
5.master容器实例内创建数据同步用户并授权
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
mysql8版本设置账号要加一步:
# 名为'slave'的用户在任何地址('%')访问时的密码为'123456',并使用mysql_native_password身份验证插件来验证身份
ALTER USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
6.新建从服务器容器实例3308
跟第1步差不多,端口变为3308,名字变为slave
docker run -p 3308:3306 --name mysql-slave \
-v /mydata/mysql-slave/log:/var/log/mysql \
-v /mydata/mysql-slave/data:/var/lib/mysql \
-v /mydata/mysql-slave/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
docker ps
7.进入/mydata/mysql-slave/conf目录下新建my.cnf
vim my.cnf(注意是cnf不是conf),粘贴以下内容
[mysqld]
##设置server_id,同一局域网中需要唯一
server_id=102
##指定不需要同步的数据库名称
binlog-ignore-db=mysql
##开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
##设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
##设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
##二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
##跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
##如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
##relay_log配置中继日志
relay_log=mall-mysql-relay-bin
##log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
##slave设置为只读(具有super权限的用户除外)
read_only=1
centos 8,mysql 最新镜像,要在/mysql-master/conf、/mysql-slave/conf 两个目录下mkdir conf.d。否则启动后会立即退出。
问题:log-bin=mall-mysql-slave1-bin是不是应该去掉1
8.修改完配置后重启slave实例
docker restart mysql-slave
docker ps
9.在主数据库中查看主从同步状态
在master容器实例内部执行
show master status;

File和Position的值,在【第11步配置主从复制】要用到
10.进入mysql-slave容器
docker exec -it mysql-slave /bin/bash
mysql -uroot -proot
11.在从数据库中配置主从复制
change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30;
| 参数 | 说明 |
|---|---|
| master_host | 主数据库的IP地址 |
| master_port | 主数据库的运行端口 |
| master_user | 在主数据库创建的用于同步数据的用户账号 |
| master_password | 在主数据库创建的用于同步数据的用户密码 |
| master_log_file | 指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数 |
| master_log_pos | 指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数 |
| master_connect_retry | 连接失败重试的时间间隔,单位为秒 |
12.在从数据库中查看主从同步状态
# 可以像第9步一样执行show slave status;而\G是以kv键值对竖着显示
show slave status \G;

13.在从数据库中开启主从同步
start slave;
14.查看从数据库状态发现已经同步
show slave status \G;查看状态时Slave_IO_Running和Slave_SQL_Running变为YES。
Slave_IO_Running如果是Connecting,在master容器中执行第5步追加的命令ALTER USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';,再重新启动(stop slave; reset slave; start slave;)即可为YES
15.主从复制测试
主机新建库-使用库-新建表-插入数据
create database db01;
use db01;
create table t1 (id int, name varchar(20));
insert into t1 values(1, 'z3');
select * from t1;
从机使用库-查看记录
use db01;
select * from t1;
1.2安装redis集群
真题 三种哈希分区
大厂面试题第4季-分布式存储案例真题
cluster(集群)模式-docker版:哈希槽分区进行亿级数据存储
面试题:1~2亿条数据需要缓存,请问如何设计这个存储案例
单机单台肯定不可能,肯定是分布式存储,用redis如何落地?
上述问题阿里P6~P7工程案例和场景设计类必考题目,一般业界有3种解决方案
1.哈希取余分区

2亿条记录就是2亿个k,v,我们单机不行,必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。优点
简单粗暴,直接有效,只需预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请
求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。缺点
原来规划好的节点,在服务器个数固定不变时没有问题,但进行扩容、缩容(或故障停机)时就比较麻烦了。
不管扩缩,每次数据变动导致节点有变动,映射关系需重新计算,原来的取模公式就会发生变化:Hash(key)% 3会变成Hash(key)% ?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
2.一致性哈希算法分区
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。提出一致性Hash解决方案
目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
三大步骤
①算法构建一致性哈希环
一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间
[0, 232-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0=232),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说,
致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到232-1,也就是说0点左侧的第一个点代表232-1,0和232-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。

②服务器IP节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
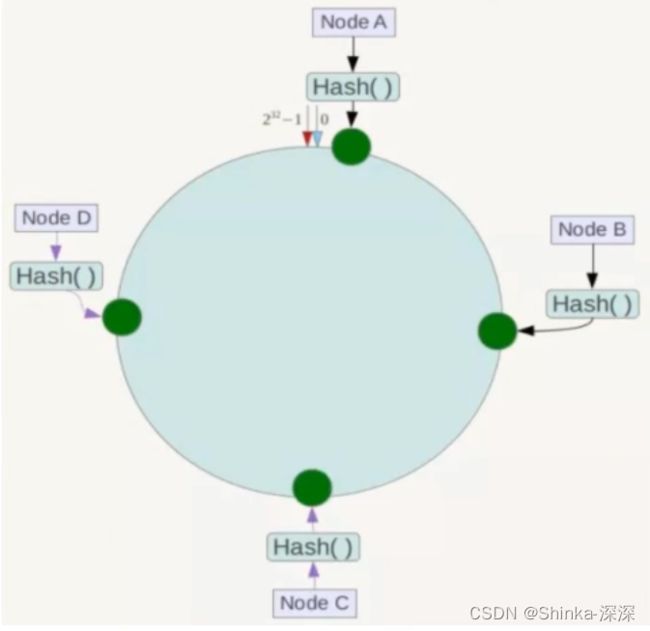
③key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。

优点
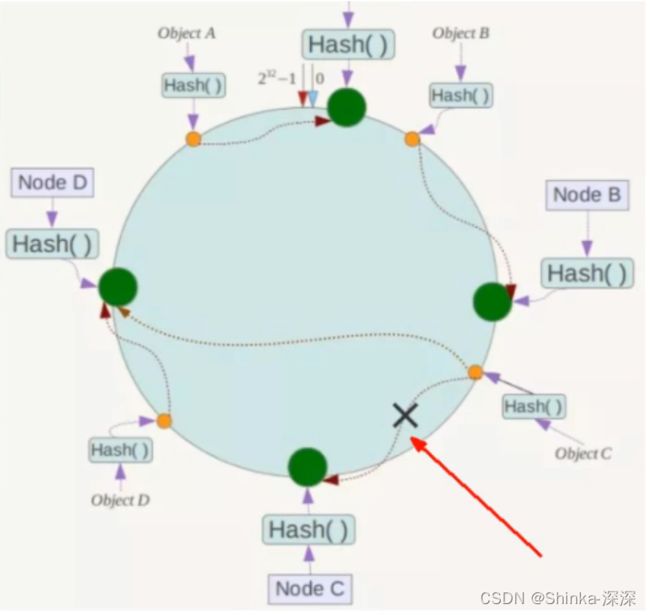
①一致性哈希算法的容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
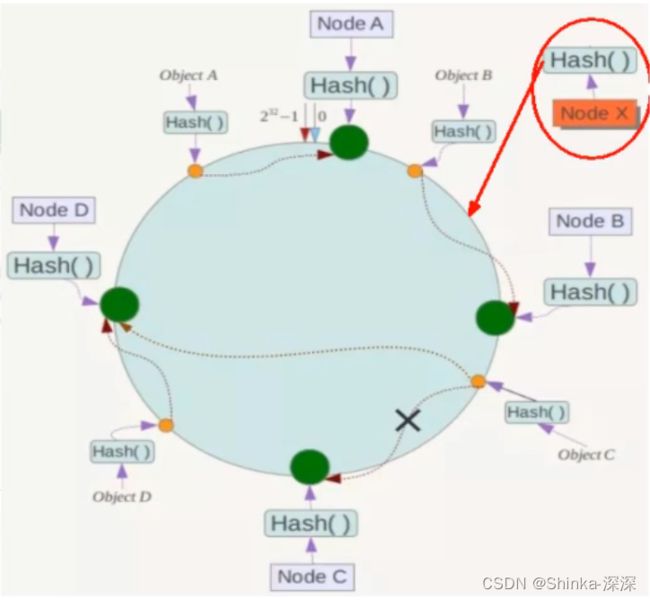
②一致性哈希算法的扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
缺点
一致性哈希算法的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器:

总结
为在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
3.哈希槽分区
为什么出现
一致性哈希算法的数据倾斜问题
哈希槽实质就是一个数组,数组[0, 2^14-1]形成hash slot空间。
能干什么
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
多少个hash槽
一个集群只能有16384个槽(redis集群默认就是16384个槽),编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,就是对16384取余,余数是几key就落入对应的槽里。 slot=CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。

哈希槽计算
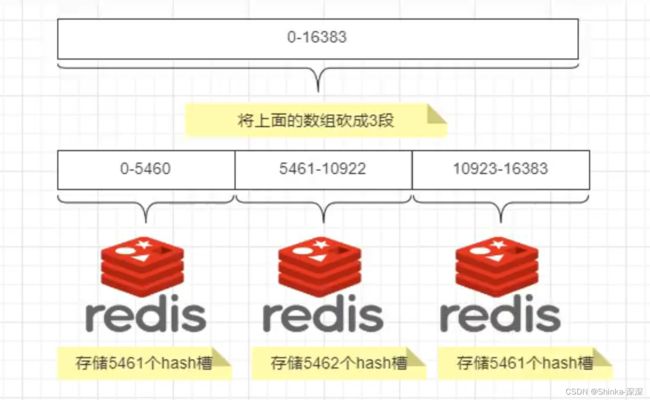
Redis集群中内置了16384个哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点。
当需要在Redis集群中放置一个key-value时,redis先对key使用crc16算法算出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,也就是映射到某个节点上。如下代码,key之A、B在Node2,key之C落在Node3上
3主3从redis集群扩缩容配置案例
架构说明
主从机器分配以实际情况为准,1号不一定对应4号
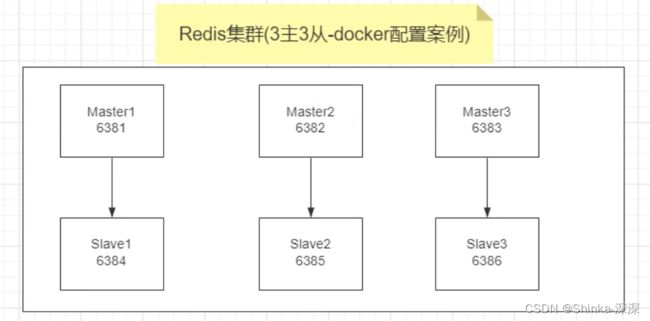
3主3从redis集群配置
关闭防火墙+启动docker后台服务
systemctl start docker
新建6个docker容器实例
# --net host 使用宿主机的ip和端口,默认
# --cluster-enabled yes 开启redis集群
# --appendonly yes 开启持久化
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
进入容器redis-node-1并为6台机器构建集群关系
# 进入容器
docker exec -it redis-node-1 /bin/bash
# 构建主从关系。进入docker容器后才能执行以下命令,且注意自己的真实ip地址
# --cluster-replicas 1 表示为每个master创建一个slave节点,此参数会自动绑定好主从关系,具体可以看打印的日志
redis-cli --cluster create 自己的ip:6381 自己的ip:6382 自己的ip:6383 自己的ip:6384 自己的ip:6385 自己的ip:6386 --cluster-replicas 1
# 一切OK的话,3主3从已经搞定
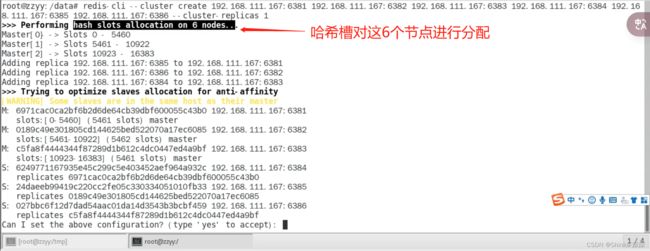
链接进入6381作为切入点,查看集群状态
docker exec -it redis-node-1 /bin/bash
# 端口号默认6379,此处链接我们的6381
redis-cli -p 6381
# info显示的 cluster_slots_ok:16384分配的槽位数量 cluster_konwn_nodes:6已经知道的节点数量
cluster info
cluster nodes
主从容错切换迁移案例
1 数据读写存储
启动6机构成的集群并通过exec进入
# 不能用以下单机版的命令,需要链接的是集群
docker exec -it redis-node-1 /bin/bash
redis-cli -p 6381
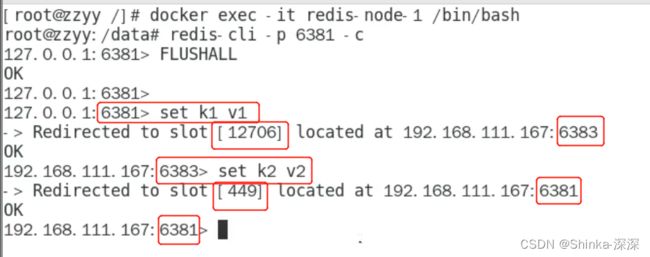
# 对6381新增两个key
set k1 v1 # 报错 (error) MOVED 12706 ip:6383
set k2 v2 # 不报错
防止路由失效加参数-c并新增两个key
docker exec -it redis-node-1 /bin/bash
redis-cli -p 6381 -c
set k1 v1
set k2 v2
查看集群信息
redis-cli --cluster check 自己ip:6381
2 容错切换迁移
主6381和从机切换,先停止主机6381
docker ps
docker stop redis-node-1
docker ps
# 这里建议在宿主机直接kill 6381对应容器的方式模拟,更加真实,通过在容器里停的方式,不能模仿主机宕机的场景
再次查看集群信息
docker exec -it redis-node-2 /bin/bash
redis-cli -p 6382 -c
cluster nodes
# 可以看到6381已经【master.fail】【disconnect】了,6384由以前的slave变为master了
get k1
get k2
先还原之前的3主3从
docker start redis-node-1
docker ps
# 在容器内部查看状态,会发现6384依然是master,新启动的6381变成slave
cluster nodes
查看集群状态
redis-cli --cluster check 自己ip:6381
主从扩容案例
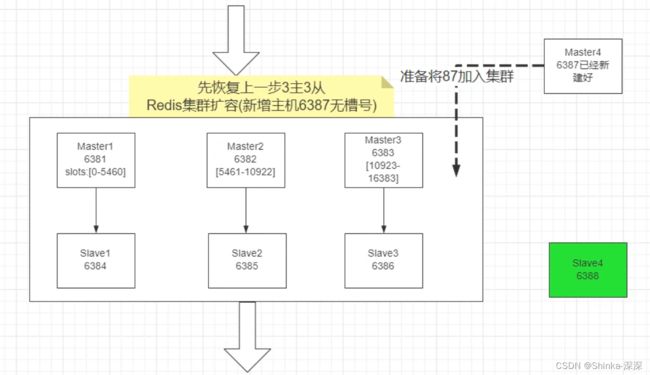


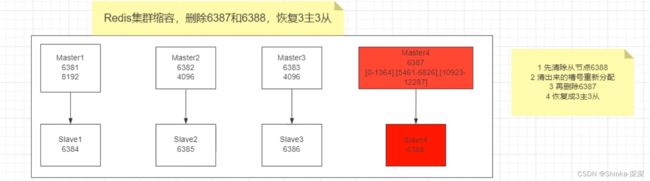
新建6387、6388两个节点+新建后启动+查看是否8节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes
--appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes
--appendonly yes --port 6388
docker ps
进入6387容器实例内部docker exec -it redis-node-7 /bin/bash
将新增的6387节点(空槽号)作为master节点加入原集群
# 将新增的6387作为master节点加入集群
redis-cli --cluster add-node 自己实际IP:6387 自己实际IP地址:6381
# 6387就是将要作为master新增节点
# 6381就是原来集群节点里面的领路人,相当于6387根据6381找到组织加入集群
检查集群情况第1次
redis-cli --cluster check 自己ip:6381
# 但6387会显示【0 slots | 0 slaves】,暂时没有槽号,也没有从节点
重新分派槽号
redis-cli --cluster reshard IP地址:端口号
redis-cli --cluster reshard 192.168.111.147:6381
# 提示【How many slots do you want to move(from 1 to 16384)】时,输入4096(16384个槽位 ÷ 4个主节点 = 4096)
# 提示【What is the receiving node ID】时,粘贴新加入的主节点的id
# 提示【Source node #1】时,输入all
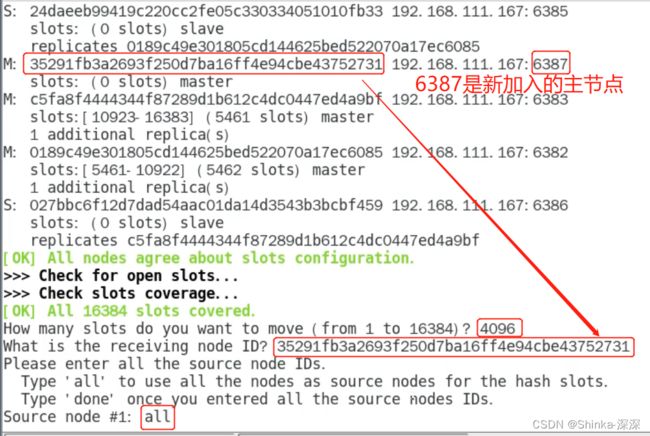
检查集群情况第2次
redis-cli --cluster check 自己ip:6381
# 各个节点的槽位变化了
槽号分派说明
为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387
为主节点6387分配从节点6388
redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli --cluster add-node 192.168.111.147:6388 192.168.111.147:6387 --cluster-slave --cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451----这个是6387的编号,按照自己实际情况
检查集群情况第3次
redis-cli --cluster check 自己ip:6382
# 端口号连谁都行,不用非得6381
主从缩容案例
目的:6387和6388下线
检查集群情况1获得6388的节点IDredis-cli --cluster check 自己ip:6382
从集群中将4号从节点6388删除
redis-cli --cluster del-node ip:从节点端口 从节点6388节点ID
redis-cli --cluster del-node 192.168.111.147:6388 5d149074b7e57b802287d1797a874ed7a1a284a8
# 检查节点个数
redis-cli --cluster check 自己ip:6382
将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
redis-cli --cluster reshard IP地址:端口号
redis-cli --cluster reshard 192.168.111.147:6381
# 补充 - 这个方法可以让槽位均匀:
# redis-cli --cluster rebalance --cluster-use-empty-masters ip:端口号
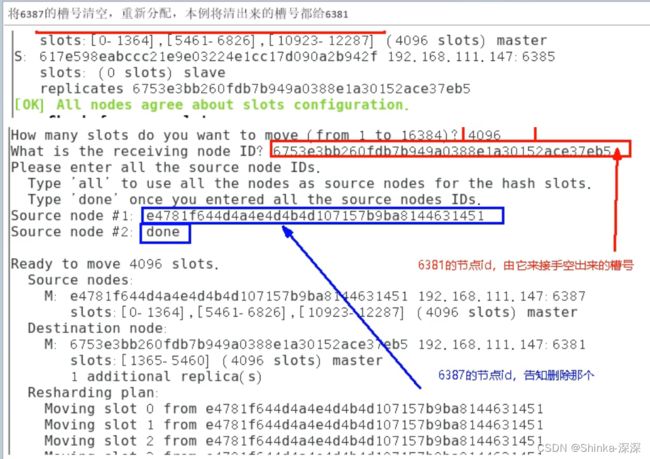
检查集群情况第二次
redis-cli --cluster check 自己ip:6381
# 会看到6387还在,但是槽位都空了(0 keys | 0 slots | 0 slaves)
# 而6381的槽位变为了8192个,因为刚才设置6387的槽位全都给6381了
将6387删除redis-cli --cluster del-node ip:节点端口 从节点6387节点ID
一检查集群情况第三次redis-cli --cluster check 自己ip:6381
2.DockerFile解析
概述
官网 Dockerfile reference | Docker Docs
Dockerfile是用来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本。

构建三步骤
编写Dockerfile文件
docker build命令构建镜像
docker run以镜像运行容器实例
DockerFile构建过程解析
Dockerfile内容基础知识
1.每条保留字指令都必须为大写字母且后面要跟随至少一个参数
2.指令按照从上到下,顺序执行
3.#表示注释
4.每条指令都会创建一个新的镜像层并对镜像进行提交
Docker执行Dockerfile的大致流程
1.docker从基础镜像运行一个容器
2.执行一条指令并对容器作出修改
3.执行类似
docker commit的操作提交一个新的镜像层4.docker再基于刚提交的镜像运行一个新容器
5.执行dockerfile中的下一条指令直到所有指令都执行完成
小总结
从应用软件的角度来看,Dockerfile、Docker镜像与Docker容器分别代表软件的三个不同阶段:
-
Dockerfile是软件的原材料
-
Docker镜像是软件的交付品
-
Docker容器则可以认为是软件镜像的运行态,也即依照镜像运行的容器实例
Dockerfile面向开发,Docker镜像成为交付标准,Docker容器则涉及部署与运维,三者缺一不可,合力充当Docker体系的基石。
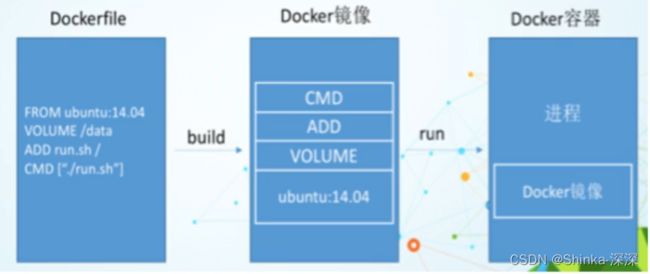
1.Dockefile。需要定义一个Dockerfile,Dockerfile定义了进程需要的一切东西。Dockerfile涉及的内容包括执行代码或者是文件、环境变量、依赖包、运行时环境、动态链接库、操作系统的发行版、服务进程和内核进程(当应用进程需要和系统服务和内核进程打交道,这时需要考虑如何设计namespace的权限控制)等等;
2.Docker镜像。在用Dockerfile定义一个文件之后,docker build时会产生一个Docker镜像,当运行Docker镜像时会真正开始提供服务;
3.Docker容器。容器是直接提供服务的。
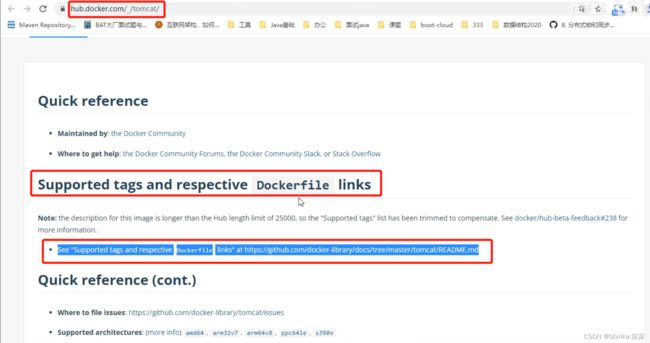
DockerFile常用保留字指令
参考tomcat8的dockerfile入门https://github.com/docker-library/tomcat
https://github.com/docker-library/tomcat/blob/master/9.0/jdk8/corretto-al2/Dockerfile
FROM
基础镜像,当前新镜像是基于哪个镜像的,指定一个已经存在的镜像作为模板,第一条必须是FROM
MAINTAINER
镜像维护者的姓名和邮箱地址
RUN
容器构建时需要运行的命令,RUN是在docker build构建时运行,有两种格式
shell格式
RUN <命令行命令>
#<命令行命令>等同于 在终端操作的shell命令
例:
RUN yum -y install vim
exec格式
RUN [“可执行文件”,“参数1”,“参数2”]
#例:
RUN ["./test.php","dev","offline"]等同于RUN ./test.php dev offline
EXPOSE
当前容器对外暴露出的端口
WORKDIR
指定在创建容器后,终端默认登陆的进来工作目录,一个落脚点
USER
指定该镜像以什么样的用户去执行,如果都不指定,默认是root
ENV
用来在构建镜像过程中设置环境变量
ENV MY_PATH /usr/mytest
这个环境变量可以在后续的任何RUN指令中使用,这就如同在命令前面指定了环境变量前缀一样;
也可以在其它指令中直接使用这些环境变量,比如:WORKDIR $MY_PATH
ADD
将宿主机目录下的文件拷贝进镜像且会自动处理URL和解压tar压缩包
COPY
类似ADD,拷贝文件和目录到镜像中。
将从构建上下文目录中<源路径>的文件/目录复制到新的一层的镜像内的<目标路径>位置
COPY src dest
COPY ["src", "dest"]
:源文件或者源目录
:容器内的指定路径,该路径不用事先建好,若不存在会自动创建
VOLUME
容器数据卷,用来数据保存和持久化工作
CMD
指定容器启动后的要干的事情
比如Tomcat的最后一行CMD ["catalina.sh", "run"]就是把catalina启动
CMD容器启动命令
CMD指令的格式和RUN相似,也是两种格式:
she11格式:CMD <命令>
exec格式:CMD [“可执行文件”,“参数1”,“参数2”.….]
参数列表格式:CMD [“参数1”,“参数2”….]。在指定了ENTRYPOINT指令后,月CMD指定具体的参数。
注意
Dockerfile中可以有多个CMD指令,但只有最后一个生效,CMD会被docker run之后的参数替换。
参考官网Tomcat的dockerfile演示讲解。官网最后一条命令:
EXPOSE 8080
CMD [“catalina.sh”, “run”]假设现在在末尾加了些别的,CMD命令可能就不生效了。
比如若执行命令
docker run -it -p 8080:8080 tomcat容器id,在tomcat启动后是能通过localhost:8080访问到页面的,
而若执行命令docker run -it -p 8080:8080 tomcat容器id /bin/bash,docker ps也是能看到tomcat容器是成功启动了的,就类似于在dockerfile文件末尾追加了一句CMD ["/bin/bash", "run"],会把上面原有的CMD覆盖掉,在tomcat启动后无法通过localhost:8080访问到页面。也就是,成功启动了容器,而tomcat服务由于没有执行CMD ["catalina.sh", "run"]是没有启动的。
它和前面RUN命令的区别
CMD是在docker run时运行。
RUN是在docker build构建镜像时运行。
ENTRYPOINT
也是用来指定一个容器启动时要运行的命令
类似于CMD指令,但是ENTRYPOINT不会被docker run后面的命令覆盖,而且这些命令行参数会被当作参数送给ENTRYPOINT指令指定的程序。
命令格式
ENTRYPOINT ["
ENTRYPOINT可以和CMD一起用,一般是变参(定参是参数个数固定,变参是参数个数可变)才会使用CMD,这里的CMD跟ENTRYPOINT一起用,相当于是在给ENTRYPOINT传参。
当指定了ENTRYPOINT后,CMD的含义就发生了变化,不再是直接运行其命令而是将CMD的内容作为参数传递给ENTRYPOINT指令,他两个组合会变成
" "
案例
假设已通过Dockerfile 构建了nginx:test镜像
FROM nginx
# 定参
ENTRYPOINT ["nginx", "-c"]
# 变参
CMD ["/etc/nginx/nginx.conf"]
| 是否传参 | 按照dockerfile编写执行 | 传参运行 |
|---|---|---|
| Docker命令 | docker run nginx:test | docker run nginx:test -c /etc/nginx/new.conf |
| 衍生出的实际命令 | nginx -c /etc/nginx/nginx.conf | nginx -c /etc/nginx/new.conf |
案例
自定义镜像mycentosjava8,要求Centos7镜像具备vim+ifconfig+jdk8
# 先下载好centOS镜像
docker run -it 镜像id /bin/bash
JDK的下载镜像地址
官网:https://www.oracle.com/java/technologies/downloads/#java8
找到Linux版本的,tar.gz。
mirrors.yangxingzhen.com/jdk/
编写Dockerfile文件
字母D一定要大写。创建路径/myfile并将jdk8放在该路径下。vim Dockerfile
1.下面Dockerfile中RUN写的太多了,建议使用一个,多个命令用换行代替。
多个run命令重复使用会导致镜像层数比较多,在构建镜像时会比较慢
2.最新版的centos8用yum会报错(默认就是去拉取版本8),原因是软件源的位置变了。需要先改成7的源。若是报错可以下不用最新的centos,里面FROM centos可以改为例如: FROM centos:7.7.1908或者FROM centos:7等,再无用的话可以试试重启网络、关闭防火墙或者加一个参数 docker build --network host -t centosjava8:1.5 .
3.Error: Failed to download metadata for repo ‘appstream’: Cannot prepare internal mirrorlist: No URLs。报appstream问题的请在安装vim之前添加额外两条指令rm -rf /etc/yum.repos.d/CentOS-Linux*,COPY CentOS-Base.repo /etc/yum.repos.d/
FROM centos
MAINTAINER zzyy
ENV MYPATH /usr/local
WORKDIR $MYPATH
#安装vim编辑器
RUN yum -y install vim
#安装ifconfig命令查看网络IP
RUN yum -y install net-tools
#安装java8及lib库
RUN yum -y install glibc.i686
RUN mkdir /usr/local/java
#ADD是相对路径jar,把jdk-8u171-linux-x64.tar.gz添加到容器中,安装包必须要和Dockerfile文件在同一路径下
ADD jdk-8u171-linux-x64.tar.gz /usr/local/java/
#配置java环境变量
ENV JAVA_HOME /usr/local/java/jdk1.8.0_171
ENV JRE_HOME $JAVA_HOME/jre
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
ENV PATH $JAVA_HOME/bin:$PATH
EXPOSE 80
CMD echo $MYPATH
CMD echo "success---------------ok"
CMD /bin/bash
构建
# 注意,TAG后面有个空格,有个点表示当前目录
docker build -t 新镜像名字:TAG .
docker build -t mycentosjava8:1.5 .
运行
docker run -it 新镜像名字:TAG
再体会下UnionFS(联合文件系统)
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union文件系统是Docker镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。
虚悬镜像
仓库名、标签都是
vim Dockerfile
FROM ubuntu
CMD echo 'action is success'
docker build .

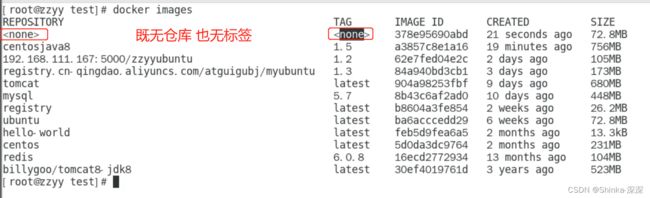
构建或者删除镜像时,可能会出现一些错误导致出现虚悬镜像,它们没有存在的价值,建议删除。
查看虚悬镜像命令:docker image Is -f dangling=true
删除虚悬镜像命令:docker image prune
作业-自定义镜像myubuntu
FROM ubuntu
MAINTAINER zzyy
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN apt-get update
RUN apt-get install net-tools
#RUN apt-get install -y iproute2
#RUN apt-get install -y inetutils-ping
EXPOSE 80
CMD echo $MYPATH
CMD echo "install inconfig cmd into ubuntu success----------ok"
CMD /bin/bash
小总结
| BUILD | Both | RUN |
|---|---|---|
| FROM | WORKDIR | CMD |
| MAINTAINER | USER | ENV |
| COPY | EXPOSE | |
| ADD | VOLUME | |
| RUN | ENTRYPOINT | |
| ONBUILD | ||
| .dockerignore |
3.Docker微服务实战
通过IDEA新建一个普通微服务模块
建Module
改POM
写YML
主启动
业务类
通过dockerfile发布微服务部署到docker容器
IDEA工具里面搞定微服务jar包:把package之后生成的服务的jar包(假设名字叫docker_boot_0.0.1-SNAPSHOT.jar)传到服务器的/mydocker路径下
建议先关闭防火墙,关完后需重启Docker
systemctl stop firewalld
systemctl restart docker
编写Dockerfile:将微服务jar包和Dockerfile文件上传到同一个目录下/mydocker
#基础镜像使用java。SpringBoot项目打成的jar包内嵌的tomcat,此处只需要Java8
FROM java:8
#作者
MAINTAINER zzyy
#VOLUME指定临时文件目录为/tmp,在主机/var/lib/docker目录下创建了一个临时文件并链接到容器的/tmp
VOLUME /tmp
#将jar包添加到容器中并更名为zzyy_docker.jar
ADD docker_boot-0.0.1-SNAPSHOT.jar zzyy_docker.jar
#运行jar包
RUN bash -c 'touch /zzyy_docker.jar'
ENTRYPOINT ["java","-jar","/zzyy_docker.jar"]
#暴露6001端口作为微服务
EXPOSE 6001
构建镜像,打包成镜像文件
docker build -t zzyy_docker:1.6 .
运行容器
docker images
docker run -d -p 6001:6001 镜像id或者tag
# 报错iptables faild则关闭防火墙,关完后需重启Docker。建议一开始就关掉防火墙,
systemctl stop firewalld
systemctl restart docker
访问测试
curl 127.0.0.1:6001/order/docker
curl 127.0.0.1:6001/order/index
# 以上是SpringBoot工程里做的两个接口,会return字符串。
# 除了curl的方式,也可以在浏览器里直接访问[宿主机ip:6001/order/docker]进行测试
4.Docker网络
这一章节在日常工作中敲命令用得不多,但必须懂,为后续Docker-compose容器编排做准备。
4.1Docker启动前后网络情况
Docker不启动,默认网络情况
ens33:inet为192.168.111.167,是Linux宿主机的地址
lo:local的简写,本地回环联络
virbr0:
在CentOS7的安装过程中如果选择相关虚拟化的的服务安装系统后,启动网卡时会发现有一个以网桥连接的私网地址的virbr0网卡(virbr0网卡:它还有一个固定的默认IP地址192.168.122.1),是做虚拟机网桥的使用的,其作用是为连接其上的虚机网卡提供NAT访问外网的功能。
我们之前学习Linux安装,勾选安装系统的时候附带了libvirt服务才会生成的一个东西,如果不需要可以直接将libvirtd服务卸载:
yum remove libvirt-libs.x86_64
Docker启动后,网络情况
会产生一个名为docker0的虚拟网桥。
4.2常用基本命令
查看网络docker network ls

默认会创建三大网络模式,主要用的是bridge,其次是host,一般不会用none。
docker network --help
# 创建一个网络,默认是bridge模式
docker network creat aa_network
docker network ls
# 删除网络
docker network rm aa_network
docker network ls
查看网络源数据docker network inspect XXX网络名字
4.3能干嘛
容器间的互联和通信以及端口映射
容器IP变动时可通过服务名直接网络通信而不受到影响
4.4网络模式
| 网络模式 | 简介 |
|---|---|
| bridge | 为每一个容器分配、设置IP等,并将容器连接到一个docker0虚拟网桥,默认为该模式。使用--network bridge指定,默认使用docker0。 |
| host | 容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。使用--network host指定。 |
| none | 容器有独立的 Network namespace,但并没有对其进行任何网络设置,如分配 veth pair 和网桥连接,IP等。几乎不会用该模式。使用--network none指定。 |
| container | 新创建的容器不会创建自己的网卡和配置自己的IP。而是和一个指定的容器共享IP、端口范围等。使用--network container:NAME指定或者容器ID指定。 |
4.5容器实例内默认网络IP生产规则
# 启动两个ubuntu
docker run -it --name u1 ubuntu bash
docker run -it --name u2 ubuntu bash
# 查看u1的网络信息,IPAddress是172.17.0.2
docker inspect u1 | tail -n 20
# 查看u1的网络信息,IPAddress是172.17.0.3
docker inspect u2 | tail -n 20
# 删掉u2,创建u3,查看u3的ip是172.17.0.3
docker rm -f u2
docker run -it --name u3 ubuntu bash
docker inspect u3 | tail -n 20
结论:docker容器内部的ip是有可能会发生改变的
4.6案例说明
bridge
查看网络源数据docker network inspect bridge
Docker服务默认会创建一个docker0网桥(其上有一个dockero内部接口),该桥接网络的名称为docker0。
它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。
Docker默认指定了docker0接口的IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信。
# 查看bridge网络的详细信息,并通过grep获取名称项
docker network inspect bridge | grep name
# 看docker0
ifconfig | grep docker
说明
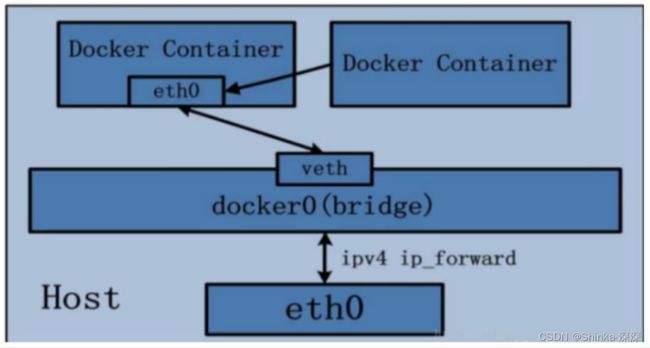
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
docker run时,没有指定network的话默认使用的网桥模式就是bridge,使用的就是docker0。在宿主机ifconfig,就可以看到docker0和自己create的network(后面讲)eth0,eth1,eth2……代表网卡一、二、三……,lo代表127.0.0.1,即localhost,inet addr用来表示网卡的IP地址网桥docker0创建一对对等虚拟设备接口一个叫veth,另一个叫eth0,成对匹配。
3.1 整个宿主机的网桥模式都是docker0,类似一个交换机有一堆接口,每个接口叫veth,在本地主机和容器内分别创建一个虚拟接口,并让他们彼此联通(这样一对接口叫veth pair);
3.2 每个容器实例内部也有一块网卡,每个接口叫eth0;
3.3 docker0上面的每个veth匹配某个容器实例内部的eth0,两两配对,一一匹配。
通过上述,将宿主机上的所有容器都连接到这个内部网络上,两个容器在同一个网络下,会从这个网关下各自拿到分配的ip,此时两个容器的网络是互通的。

代码
# 启动两个tomcat
docker run -d -p 8081:8080 --name tomcat81 billygoo/tomcat8-jdk8
docker run -d -p 8082:8080 --name tomcat81 billygoo/tomcat8-jdk8
docker ps
# 会发现多了几个类似【25:veth2844760@if24】。宿主机上是veth。
ip addr
# 进入tomcat81
docker exec -it tomcat81 bash
# 在tomcat81里面查看,有【24:eth0@if25】,容器内部是eth。
# 24和25,宿主机和容器内一一匹配。
ip addr
host
直接使用宿主机的IP地址与外界进行通信,不再需要额外进行NAT转换。
容器将不会得一个独立的Network Namespace, 而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡而是使用宿主机的IP和端口。

代码-警告
# 以前redis三主三从用的就是【--network host】模式
docker run -d -p 8083:8080 --network host --name tomcat83 billygoo/tomcat8-jdk8
问题:
docker启动时遇见警告
WARNING: PubLished ports are discarded when using host network mode
原因:
docker启动时指定--network=host或-net=host,如果还指定了-p映射端口,此时就会有该警告,
并且通过-p设置的参数将不会起到任何作用(docker ps查看该容器时PORTS列为空),端口号会以主机端口号为主,重复时则递增。
解决:
使用docker的其他网络模式,例如--network=bridge,这样就可以解决问题,或者直接无视
代码-正确
# 启动tomcat83,以host模式
docker run -d --network host --name tomcat83 billygoo/tomcat8-jdk8
# 在宿主机上查看tomcat83容器实例内部网络情况。由于跟宿主机共用一套,无之前的配对显示了,Gateway和IPAddress字段值是空的。
docker inspect tomcat83
# 在容器内部查看tomcat83容器实例内部网络情况。
docker exec -it tomcat83 bash
# 跟外面宿主机执行【ip addr】的查看结果几乎一样。
ip addr
没有设置-p的端口映射了,如何访问启动的tomcat83:
端口号会以主机端口号为主,重复时则递增。在浏览器访问【http://宿主机ip:8080/】
在CentOS里面用默认的火狐浏览器访问容器内的tomcat83看到访问成功,因为此时容器的IP借用主机的。
所以容器共享宿主机网络IP,这样的好处是外部主机与容器可以直接通信。
none
禁用网络功能,只有lo标识(就是127.0.0.1表示本地回环)
在none模式下,并不为Docker容器进行任何网络配置。
也就是说,这个Docker容器没有网卡、IP、路由等信息,只有一个lo
需要我们自己为Docker容器添加网卡、配置IP等。
案例
docker run -d -p 8084:8080 --network none --name tomcat84 billygoo/tomcat8-jdk8
# Gateway和IPAddress字段值是空的。
docker inspect tomcat84 | tail -n 20
# 查看该容器时PORTS列为空
docker ps
# 在容器内部查看tomcat84容器实例内部网络情况。
docker exec -it tomcat84 bash
# 查询结果只有一个lo
ip addr
container
新建的容器和已经存在的一个容器共享一个网络ip配置而不是和宿主机共享。
新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。
同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。
案例
# tomcat86和tomcat85共用同一个ip和同一个端口,导致端口冲突,用tomcat演示不合适。
docker run -d -p 8085:8080 --name tomcat85 billygoo/tomcat8-jdk8
docker run -d -p 8086:8080 --network container:tomcat85 ---name tomcat85 billygoo/tomcat8-jdk8
# 会报错:
# docker: Error response from daemon: conflicting options: port publishing and the container type network mode.
# See 'docker run … help)."vw wusmw. cw accay vpcavs. pw,. pwv
docker rm -f tomcat85
Alpine操作系统是一个面向安全的轻型Linux发行版
Alpine Linux是一款独立的、非商业的通用Linux发行版,专为追求安全性、简单性和资源效率的用户而设计。
可能很多人没听说过这个Linux发行版本,但是经常用Docker的朋友可能都用过,它以小、简单、安全而著称,所以作为基础镜像是非常好的一个选择,可谓是麻雀虽小但五脏俱全,镜像非常小巧,不到6M的大小,所以特别适合容器打包。
# 注意它是/bin/sh
docker run -it --name alpine1 alpine /bin/sh
docker run -it --network container:alpine1 --name alpine2 alpine /bin/sh
# 在两个容器内部各执行ip addr
# alpine1和alpine1显示的都是【28:eth0@if29】,inet都是【172.17.0.2】
ip addr
假如此时关闭alpine1,再ip addr看看alpine2,就没有刚才alpine1的ip和端口了。
自定义网络
未使用自定义网络时的痛点:按照ip能ping通,而按照名字不能。
docker run -d -p 8081:8080 --name tomcat81 billygoo/tomcat8-jdk8
docker run -d -p 8082:8080 --name tomcat82 billygoo/tomcat8-jdk8
# 上述成功启动,进入各自容器实例内部
docker exec -it tomcat81 bash
docker exec -it tomcat82 bash
# ip addr拿到各自ip,按照ip地址ping是OK的
ip addr
ping 对方ip
# 按照服务名ping,会报错【ping:tomcatXX:Name or service not known】
ping tomcat82
ping tomcat81
没有
ip addr直接apt update然后apt -y install iproute2ping命令下载:
apt install iputils-ping
自定义桥接网络,自定义网络默认使用的是桥接网络bridge
新建自定义网络
docker network create zzyy_network
docker network ls
新建容器加入上一步新建的自定义网络
docker run -d -p 8081:8080 --network zzyy_network --name tomcat81 billygoo/tomcat8-jdk8
docker run -d -p 8082:8080 --network zzyy_network --name tomcat82 billygoo/tomcat8-jdk8
docker exec -it tomcat81 bash
docker exec -it tomcat82 bash
# 此时可以用名字ping通了
结论:自定义网络本身就维护好了主机名和ip的对应关系(ip和域名都能通)
5.Docker-compose容器编排
定义
Docker-Compose是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。
Compose是Docker公司指出的一个工具软件,可以管理多个Docker容器组成一个应用。你需要定义一个YAML格式的配置文件docker-compose.yml,写好多个容器之间的调用关系。然后,只要一个命令,就能同时启动/关闭这些容器
作用
docker建议我们每一个容器中只运行一个服务,因为docker容器本身占用资源极少,所以最好是将每个服务单独的分割开来。但是这样我们又面临了一个问题:需要同时部署很多服务时,若每个服务单独写Dockerfile然后再构建镜像、构建容器,很麻烦,所以docker官方给我们提供了docker-compose多服务部署的工具。
例如要实现一个Web微服务项目,除了Web服务容器本身,往往还需要再加上后端的数据库mysql服务容器、redis服务器、注册中心,甚至
还包括负载均衡容器……Compose允许用户通过一个单独的docker-compose.yml模板文件(YAML格式)来定义一组相关联的应用容器为一个项目(project)。
可以很容易地用一个配置文件定义一个多容器的应用,然后使用一条指令安装这个应用的所有依赖,完成构建。Docker-Compose解决了容器与容器之间如何管理编排的问题。
官网 Compose file version 3 reference | Docker Docs
官网下载 Overview of installing Docker Compose | Docker Docs
docker18后面的版本自带compose了
docker compose version

Compose核心概念
一文件:
docker-compose.yml
两要素:
服务(service)- 一个个应用容器实例,比如订单微服务、库存微服务、MySQL容器、Nginx容器或者Redis容器等。
工程(project)- 由一组关联的应用容器组成的一个完整业务单元,在docker-compose.yml文件中定义。
Compose使用的三个步骤
编写Dockerfile定义各个微服务应用并构建出对应的镜像文件
使用docker-compose.yml定义一个完整业务单元,安排好整体应用中的各个容器服务。
最后,执行docker-compose up命令来启动并运行整个应用程序,完成一键部署上线
Compose常用命令
新版命令由docker-compose变为docker compose,没有中间的连接符
| 命令 | 释义 |
|---|---|
| docker-compose -h | 查看帮助 |
| docker-compose up | 启动所有docker-compose服务 |
| docker-compose up -d | 启动所有docker-compose服务并后台运行 |
| docker-compose down | 停止并删除容器、网络、卷、镜像。 |
| docker-compose exec yml里面的服务id | 进入容器实例内部 docker-compose exec docker-compose.yml文件中写的服务id /bin/bash |
| docker-compose ps | 展示当前docker-compose编排过的运行的所有容器 |
| docker-compose top | 展示当前docker-compose编排过的容器进程 |
| docker-compose logs yml里面的服务id | 查看容器输出日志 |
| dokcer-compose config | 检查配置 |
| dokcer-compose config -q | 检查配置,有问题才有输出 |
| docker-compose restart | 重启服务 |
| docker-compose start | 启动服务 |
| docker-compose stop | 停止服务 |
Compose编排微服务
改造升级微服务工程docker_boot
以前的基础版docker_boot只是最基础的能启动的一个SpringBoot工程
SQL建表建库
CREATE TABLE `t_user`(
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL DEFAULT '' COMMENT '用户名',
`password` varchar(50) NOT NULL DEFAULT '' COMMENT '密码',
`sex` tinyint(4) NOT NULL DEFAULT '0' COMMENT '性别 O=女 1=男',
`deleted` tinyint(4) unsigned NOT NULL DEFAULT '0' COMMENT '删除标志,默认0不删除,1删除 ',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY('id')
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户表'
改POM:引入一些比如Guava、redisson、swagger、springCache、MySQL等依赖
写YML:server.port=6001,以及其他引入依赖所需做的配置(Redis和MySQL等一些相关ip的配置目前都是固定写死的)
主启动类和业务类,做一个增删改查的接口,且有将数据写入Redis的逻辑。
mvn package命令将微服务形成新的jar包,并上传到Linux服务器/mydocker目录下(详见【3.Docker微服务实战】,Dockerfile和构建镜像的也一样)
编写Dockerfile
构建镜像:docker build -t zzyy_docker:1.6 .
不用Compose
单独的mysql容器实例
# 新建mysql容器实例
docker run -p 3306:3306 --name mysql57 --privileged=true \
-v /zzyyuse/mysql/conf:/etc/mysql/conf.d \
-v /zzyyuse/mysq/logs:/logs \
-v /zzyyuse/mysql/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
进入mysql容器实例
docker exec -it mysql57 bash
新建库db2021+新建表t_user
mysql -uroot -p
creat database db2021;
use db2021;
# 拷贝上面的建t_user表的语句
单独的redis容器实例
docker run -p 6379:6379 --name redis608 --privileged=true \
-v /app/redis/redis.conf:/etc/redis/redis.conf \
-v /app/redis/data:/data \
-d redis:6.0.8 \
redis-server /etc/redis/redis.conf
docker ps
docker exec -it redis608 bash
redis-cli -p 6379
微服务工程
docker images zzyy_docker:1.6
docker run -d -p 6001:6001 上面镜像的ID
docker ps
上面三个容器实例依次顺序启动成功
swagger测试
http://localhost:微服务端口/swagger-ui.html#/
调试接口插入和查询数据,查看容器内Redis和MySQL的读写数据情况。
上面成功了,有哪些问题?
先后顺序要求固定先mysql+redis才能微服务访问成功
多个run命令
容器间的启停或宕机,有可能导致IP地址对应的容器实例变化,映射出错,要么生产IP写死(可以但是不推荐),要么通过服务调用
使用Compose
编写docker-compose.yml文件
services:有几个服务容器实例
microService:自己定义的服务名,不冲突就可以。
container_name:容器名字。若不指定,则最终变成【当前路径_服务名字_1】,比如【mydocker_redis_1】
# yml中的第一大段相当于写了个docker run命令
docker run -d -p 6001:6001 --name ms01 \
-v /app/microServ \
--network atguigu_net \
zzyy_docker:1.6
version: "3"
services:
microService:
image: zzyy_docker:1.6
container_name: ms01
ports:
- "6001:6001"
volumes:
- /app/microService:/data
networks:
- atguigu_net
depends_on:
- redis
- mysql
redis:
image: redis:6.0.8
ports:
- "6379:6379"
volumes:
- /app/redis/redis.conf:/etc/redis/redis.conf
- /app/redis/data:/data
networks:
- atguigu_net
command: redis-server /etc/redis/redis.conf
mysql:
image: mysql:5.7
environment:
MYSQL_RO0T_PASSWORD: '123456'
MYSQL_ALLOW_EMPTY_PASSWORD: 'no'
MYSQL_DATABASE: 'db2021'
MYSQL_USER: 'zzyy'
MYSQL_PASSWORD: 'zzyy123'
ports:
- "3306:3306"
volumes:
- /app/mysql/db:/var/lib/mysql
- /app/mysql/conf/my.cnf:/etc/my.cnf
- /app/mysql/init:/docker-entrypoint-initdb.d
networks:
- atguigu_net
command: --default-authentication-plugin=mysql_native_password #解决外部无法访问
networks:
atguigu_net:
cd /mydocker
vim docker-compose.yml
# /mydocker路径下有Dockerfile、jar包、docker-compose.yml
第二次修改微服务工程docker boot
把SpringBoot工程中MySQL和Redis相关的配置,由ip改为docker-compose.yml文件中设置的容器名字
比如
#spring.datasource.url=jdbc:mysql://192.168.111.169:3306/db2021?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.url=jdbc:mysql://mysql:3306/db2021?useUnicode=true&characterEncoding=utf-8&useSSL=false
#spring.redis.host=192.168.111.169
spring.redis.host=redis
mvn package命令将微服务形成新的jar包,并上传到Linux服务器/mydocker目录下。
编写Dockerfile
把之前的镜像zzyy_docker:1.6删掉,Redis容器和MySQL容器也可以都停掉。
构建镜像docker build -t zzyy_docker:1.6 .
启动所有docker-compose服务
# 检查编写的配置语法格式,有问题才有输出。
docker-compose config -q
docker ps
# 执行docker-compose up(前台运行)或者docker-compose up -d(后台运行)
# docker-compose up
docker-compose up -d
# 会发现三个容器都启动好了,网络也创建了,网络名字叫mydocker_atguigu_net
docker network ls
docker ps
进入mysql容器实例并新建库db2021+新建表t_user(同上)
swagger测试通过(同上)
关停
docker-compose stop
6.Docker轻量级可视化工具Portainer
Portainer是一款轻量级的应用,它提供了图形化界面,用于方便地管理Docker环境,包括单机环境和集群环境。
安装
官网首页 https://www.portainer.io/
官网安装 Install Portainer
Install Portainer CE with Docker on Linux - Portainer Documentation
docker命令安装
# 可以先pull再run,但没必要
# docker pull portainer/portainer-ce:latest
# --restart=always表示若docker重启了,该容器也会跟着重启,保证随时在线
# 视频教程给出的【9000:9000】,2023.12官网给出的是【9443:9443】
# 官网映射的9443是https,若要用http访问就映射9000
docker run -d -p 8000:8000 -p 9000:9000 \
--name portainer \
--restart=always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v portainer_data:/data \
portainer/portainer-ce:latest

第一次登录需创建admin,访问地址:xxx.xxx.xxx.xxx:9000
设置admin用户和密码后首次登陆
选择local选项卡后本地docker详细信息展示
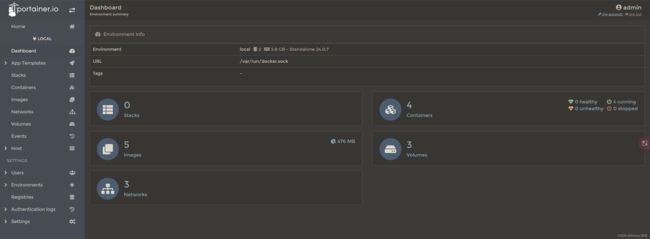
上一步的图形展示,对应命令是docker system df
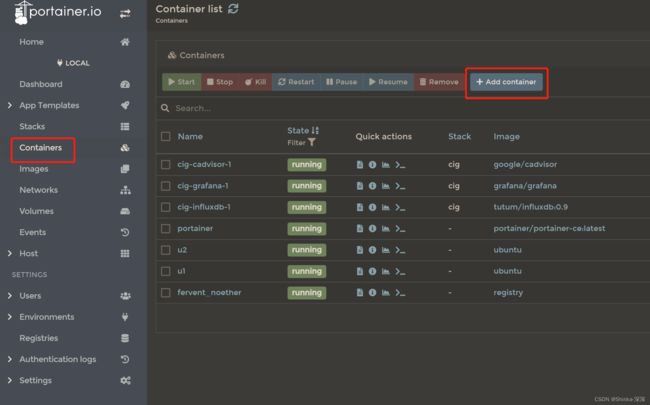
可尝试使用Portainer安装Nginx:左侧菜单栏Container - 点击Add Container按钮
7.Docker容器监控之CAdvisor+InfluxDB+Granfana
通过docker stats命令可以很方便地看到当前宿主机上所有容器的CPU、内存、网络流量等数据,一般小公司够用了。
但是,docker stats统计结果只能是当前宿主机的全部容器,数据资料是实时的,没有地方存储、没有健康指标过线预警等功能.
容器监控三剑客CIG
CAdvisor监控收集 + InfluxDB存储数据 + Granfana展示图表

CAdvisor
CAdvisor是一个容器资源监控工具,包括容器的内存、CPU、网络IO、磁盘IO等监控,同时提供了一个WEB页面用于查看容器的实时运行状态,默认存储2分钟的数据,而且只是针对单物理机。
CAdvisor提供了很多数据集成接口,支持InfluxDB、Redis、Kafka、Elasticsearch等集成,可以加上对应配置将监控数据发往这些数据库存储起来。
CAdvisor功能主要有两点:
展示Host和容器两个层次的监控数据。
展示历史变化数据。
InfluxDB
InfluxDB是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。
CAdvisor默认只在本机保存最近2分钟的数据,为了持久化存储数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。lnfluxDB是一个时序数据库,专门用于存储时序相关数据,很适合存储CAdvisor的数据。而且,CAdvisor本身已经提供了InfluxDB的集成方法,启动容器时指定配置即可。
InfluxDB主要功能:
基于时间序列,支持与时间有关的相关函数(如最大、最小、求和等)
可度量性:你可以实时对大量数据进行计算;
基于事件:它支持任意的事件数据;
Granfana
Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(支持的数据源包括InfluxDB、MySQL、Elasticsearch、OpenTSDB、Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。
Grafan主要特性:
灵活丰富的图形化选项
可以混合多种风格
支持白天和夜间模式
多个数据源
总结
cAdvisor - Collects, aggregates, processes, and exports information about running containers(收集、聚合、处理和导出有关正在运行的容器的信息)
InfluxDB - Time Series Database stores all the metrics(时间序列数据库存储所有指标)
Grafana - Metrics Dashboard(指标仪表板)
Compose容器编排CIG
新建目录mkdir /mydocker/cig并进入
新建3件套组合的vim docker-compose.yml
version: '3.1'
volumes:
grafana_data: {}
services:
influxdb:
image: tutum/influxdb:0.9
restart: always
environment:
- PRE_CREATE_DB=cadvisor
ports:
- "8083:8083"
- "8086:8086"
volumes:
- ./data/influxdb:/data
cadvisor:
image: google/cadvisor
links:
- influxdb:influxsrv
command: -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
restart: always
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/syS:ro
- /var/lib/docker/:/var/lib/docker:ro
grafana:
user: "104"
image: grafana/grafana
restart: always
links:
- influxdb:influxsrv
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- HTTP_USER=admin
- HTTP_PASS=admin
- INFLUXDB_HOST=influxsrv
- INFLUXDB_PORT=8086
- INFLUXDB_NAME=cadvisor
- INFLUXDB_USER=root
- INFLUXDB_PASS=root
# 检查语法
docker compose config -q
# 启动docker-compose文件
docker compose up
# 查看三个服务容器是否启动
docker ps
浏览cAdvisor收集服务,http:/ip:8080/
第一次访问慢,请稍等
cadvisor也有基础的图形展现功能,这里主要用它来作数据采集

浏览influxdb存储服务,http://ip:8083/
8083端口是对外暴露的web界面
8086端口是数据连接的

浏览grafana展现服务,http://ip:3000
默认账户密码admin/admin
grafana配置步骤
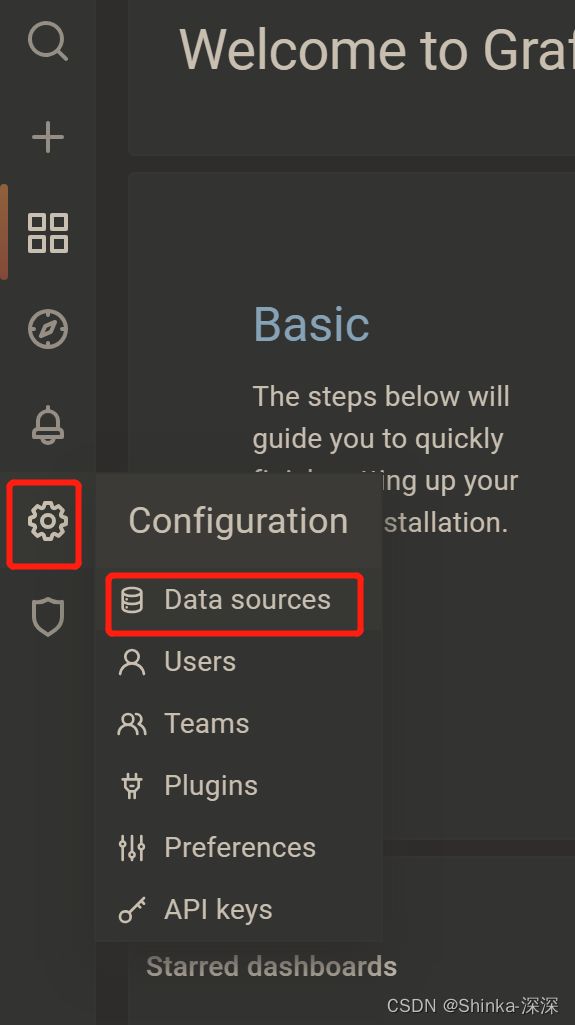
配置数据源
configuration - Data sources - 选择InfluxDB数据源
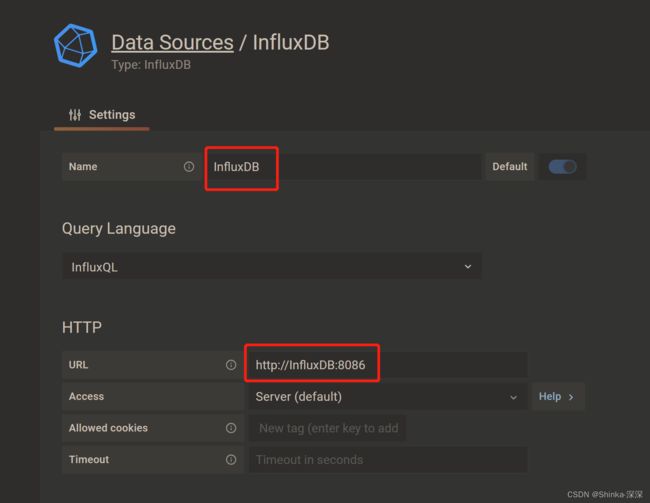
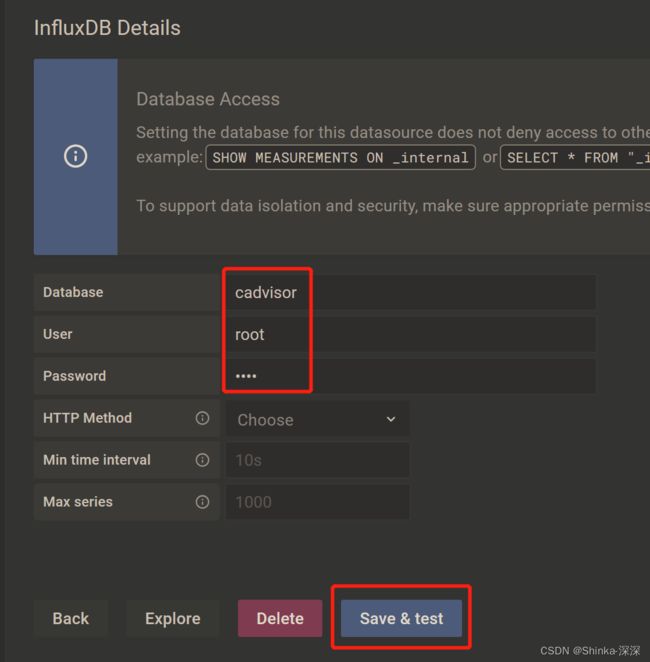
配置细节
配置面板panel
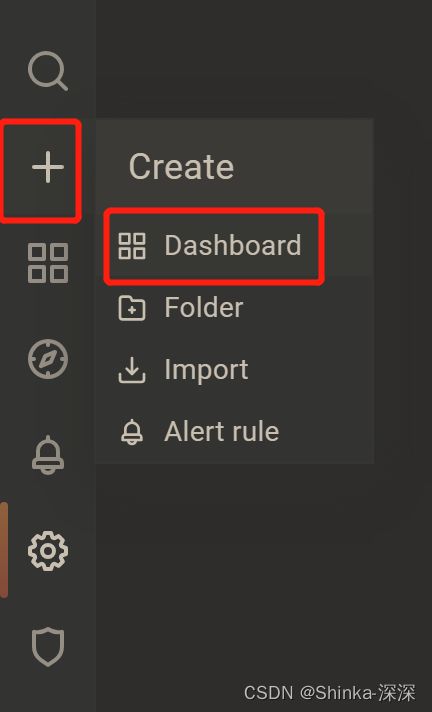



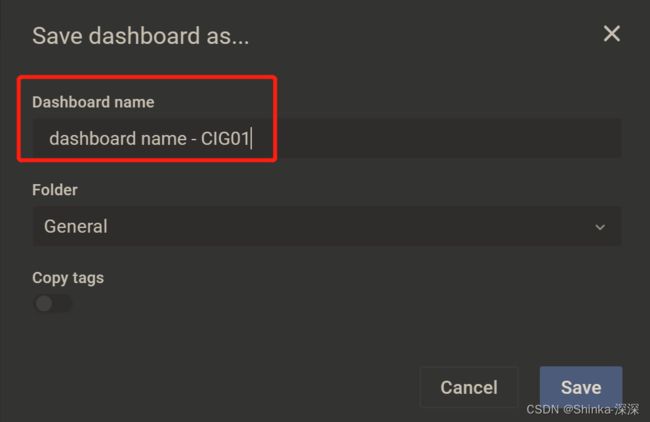

若要监控多个维度,可以【+Query】,比如一个监控CPU,一个监控内存之类的

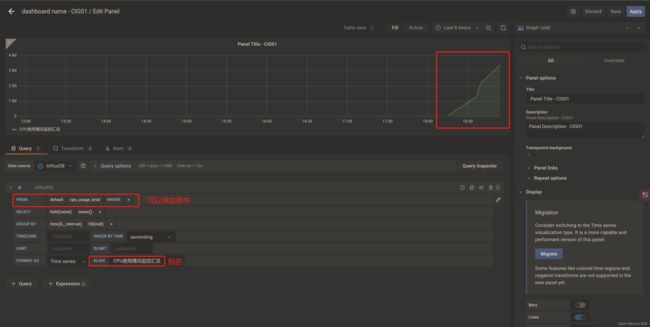
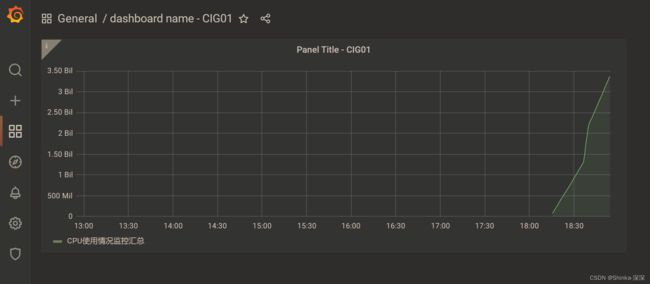
到这里cAdvisor+InfluxDB+Grafana容器监控系统就部署完成了