【李宏毅深度强化学习笔记】2、Proximal Policy Optimization算法(PPO)
【李宏毅深度强化学习笔记】1、策略梯度方法(Policy Gradient)
【李宏毅深度强化学习笔记】2、Proximal Policy Optimization (PPO) 算法(本文)
【李宏毅深度强化学习笔记】3、Q-learning(Basic Idea)
【李宏毅深度强化学习笔记】4、Q-learning更高阶的算法
【李宏毅深度强化学习笔记】5、Q-learning用于连续动作 (NAF算法)
【李宏毅深度强化学习笔记】6、Actor-Critic、A2C、A3C、Pathwise Derivative Policy Gradient
【李宏毅深度强化学习笔记】7、Sparse Reward
【李宏毅深度强化学习笔记】8、Imitation Learning
-------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av63546968?p=2
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
-------------------------------------------------------------------------------------------------------
讲PPO前先铺垫一下On-policy和Off-policy的一点知识

所谓 on-policy (左图)指我们学习的 agent(即actor) 和与环境交互的 agent 是相同的,即 agent 一边和环境互动,一边学习;
而 off-policy (右图)指我们学习的 agent 与环境交互的 agent 是不同的,即 agent 通过看别人玩游戏来学习。
on-policy的过程是这样的:

1、使用actor 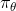 去收集数据,用这些数据来进行参数的更新,此时参数
去收集数据,用这些数据来进行参数的更新,此时参数 变为。
变为。
2、由于参数变为,原本actor 收集的数据就不能用了,所以要重新收集数据
3、再根据actor 收集的数据,将参数变为。
一直这样循环下去…………
On-policy的不足:
从上面的过程可以看出,更新后的actor 的参数变为,原来的数据就不能用了。就是说每更新一次参数就需要重新去收集数据,这样更新的效率很低,很花时间。
目标:
用 去收集数据,用这些数据去训练 。这样就可以更新参数很多次而只用同一批数据,这就是off-policy。
那怎么做呢?
Importance sampling
 代表从分布p中取样本x送入
代表从分布p中取样本x送入 并求期望,类似于从p中取N个
并求期望,类似于从p中取N个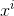 ,然后代入求平均,即
,然后代入求平均,即

现在假设我们不能从分布 p 中 sample 数据,只能从分布 q 中 sample,这样不能直接套上述近似。而要用:

即从p分布sample数据变为从q分布sample数据,只需在后面乘上一个weight,即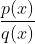
Importance Sampling 存在的问题:

通过上述公式看出,即便两者期望值一样,但是他们的方差(variance)不同,两式的区别在于红框那里多了一项。

这幅图具体说明了上述问题:蓝线代表 p的分布,绿线代表 q 分布,红线代表函数,现在我们要从 p、q 分布中 sample 出 x ,投到中计算。
可以看出 p、q 分布对于的计算而言差别是很大的。如果sample次数不够多,会造成只sample到每一种分布中,数量比较多的那些样本,比如从p中sample,会容易sample到使小于0的x;从q中sample,会容易sample到使大于0的x。
上面是sample次数不够多的情况,下面是sample次数足够的情况

可以看到,sample次数够多的时候,可能就能sample到左边的点,在这里可以人为给它设定一个很大的weight。
这样sample到左边绿线那个点的时候,会得到一个很大的值,这样就会将原本应该是正的拉回负的。
但这个前提是sample足够多次。如果sample次数不够多,就会造成 有很大的差别,这就是importance sampling的不足。
有很大的差别,这就是importance sampling的不足。
回到一开始,讲了importance sampling后,我们知道如何由θ变为θ’。只需将 变成
变成
 ,这样就能用actor收集数据,给actor去训练了。
,这样就能用actor收集数据,给actor去训练了。
使用 off-policy,使用梯度做参数更新时要注意的点:

1、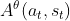 是总计的Reward减掉bias,即
是总计的Reward减掉bias,即 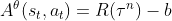 ,就是衡量在状态st下采取动作at的回报。是根据 sample 到的数据计算。
,就是衡量在状态st下采取动作at的回报。是根据 sample 到的数据计算。
2、因为是与环境做互动,所以要变为
3、这里我们估计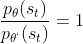 ,因为猜测 state 的出现与θ关系不大,况且这一项本来就无法计算,因为state出现的概率我们是不能控制或估计的。
,因为猜测 state 的出现与θ关系不大,况且这一项本来就无法计算,因为state出现的概率我们是不能控制或估计的。
4、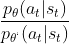 可以直接算,
可以直接算,
由此可以得到新的目标函数

上标代表跟环境互动的,是要更新的参数。
PPO / TRPO 算法:
进入主题
上面讲了和相差太多,会导致结果错误。那么为了防止和相差太多,就可以使用PPO算法。

在原来的目标函数后再加一项约束值 ,这个约束就像深度学习中的正则化项。
这一项和衡量和的差距,这里的差距指的是actor行为上的差距而不是参数上的差距。
下面这个是TRPO算法:

TRPO和PPO的区别:
TRPO在作梯度上升的时候,只对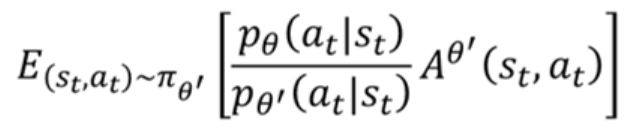 求梯度上升,而只作为一个额外的约束,很难计算。
求梯度上升,而只作为一个额外的约束,很难计算。
而PPO的是放到式子中减去的一项,这样作梯度上升的时候就是将一整个式子(和)一起算,比较容易算。
所以,为了方便使用,而且两者性能差不多,就直接使用PPO吧
那 要设多少呢?
要设多少呢?
PPO中 和学习率有点类似,需要手动设置。我们可以设定两个阈值 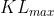 和
和 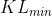 。经过一次参数更新后,查看KL的值,如果 大于 ,说明
。经过一次参数更新后,查看KL的值,如果 大于 ,说明 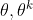 相差太大,需要加大 ,加大惩罚。反之则减小 ,减小惩罚。
相差太大,需要加大 ,加大惩罚。反之则减小 ,减小惩罚。
上面讲的是PPO,下面要讲的是PPO2。

min(a,b)函数就是取a和b中的最小值。
clip()函数的意思是: 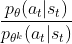 小于
小于 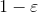 ,则取 ;若 大于
,则取 ;若 大于 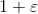 则取 ;若介于两者之间,则取 ,即输入等于输出。
则取 ;若介于两者之间,则取 ,即输入等于输出。

上面为clip()函数的图像,横轴指的就是。
总的图像:

绿线代表min()函数的第一项的图像,蓝线代表min()函数的第二项的图像,红线代表最终min()函数的输出结果。
若A>0,则取下图左边红线部分,若A<0则取下图右边红色部分。
这个式子其实就是让 和 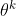 不要差距太大。如果A(advantage function)>0,代表当前的action是好的,所以我们希望
不要差距太大。如果A(advantage function)>0,代表当前的action是好的,所以我们希望 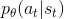 越大越好(即横轴代表的 增大),但是 和
越大越好(即横轴代表的 增大),但是 和 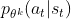 二者不能相差太多,所以设了一个上界 (上图左边);A<0,则说明当前的action不好,所以希望 越小越好(即横轴代表的 减小),但同样要设一个下界 。
二者不能相差太多,所以设了一个上界 (上图左边);A<0,则说明当前的action不好,所以希望 越小越好(即横轴代表的 减小),但同样要设一个下界 。
最后再放一下PPO和PPO2的对比:


这里有人纠结怎么一开始写的PPO是取期望,而这里的PPO和PPO2怎么变成是累加的?

TRPO / PPO2 等方法的实验效果:

这边可能不清晰,可以看论文原文(https://arxiv.org/abs/1707.06347)
简单说一下,PPO(Clip)是紫色的线,可以看到每个任务中的效果都是名列前茅。
总结
1、介绍了on-policy和off-policy的概念,和on-policy不足
2、为了实现 用 去收集数据,用这些数据去训练 (即off-policy),使用Importance sampling方法
3、在Importance sampling方法中要求和不要相差太多,否则会导致结果错误。进而引出PPO算法
4、介绍了PPO和TRPO和PPO2