Spring data elasticsearch添加同义词组件实现同义词热更新
文章目录
-
-
- 写在前边
- SpringBoot 版本
- Elasticsearch版本(7.6.2)
- 需求说明
- 实现步骤
- 添加同义词组件
- 项目中添加配置
-
-
- 配置说明(来自于GitHub中项目说明(README.md))
- 使用配置
- 开发同步同义词接口
-
- 在项目启动之后创建索引
- 不完善的地方
-
写在前边
这是我做完之后整理出来的,如有遗漏或错误的地方,请在评论区指出,非常感谢!假设你做该功能时,已经搭建好Spring data es的环境(elasticsearch和项目都已经搭建成功),es安装了analysis-ik分词器插件,请注意使用的版本号是否与我一致,我会将spring boot版本和es的版本放在下边
SpringBoot 版本
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.5.RELEASEversion>
<relativePath/>
parent>
Elasticsearch版本(7.6.2)
{
"name": "kms-1",
"cluster_name": "kms-application",
"cluster_uuid": "h766_yfYTv2wfy7bHsqIxw",
"version": {
"number": "7.6.2",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date": "2020-03-26T06:34:37.794943Z",
"build_snapshot": false,
"lucene_version": "8.4.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
需求说明
项目中有个需求是我在项目中维护同义词功能,操作之后需要同步到Es中去,比如添加一组同义词:番茄、西红柿; 那么这些应该同步到es中,并且生效。
实现步骤
在es中添加同义词组件 ===>>> 提供组件需要的接口(同步同义词) ===>>> 改变Spring data Es 创建索引的方式。
添加同义词组件
存放于GitHub中的该项目中有README.md,其中指出了同义词组件的打包安装方式,这里我就简单说下。
在github中将同义词组件(是一个java项目)下载,下载之后通过idea打开,更改pom.xml中版本号,改为es的版本号,比如我版本号是7.6.2,那么pom中的项目版本就改为7.6.2。如下所示:
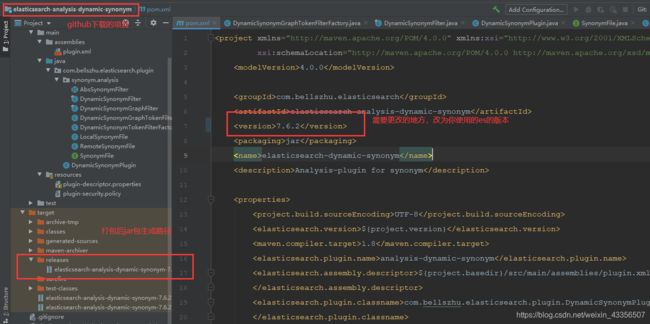
修改完成之后等待maven更新完毕,在当前项目目录下执行mvn package,或者在idea中点击package打包,如下:

打包完毕之后将 target/releases 下的压缩包复制到es的plugins/dynamic-synonym目录下解压,具体目录如下:


重启es,至此同义词组件安装完毕。
项目中添加配置
- 在resources目录下创建一个目录 elasticsearch(名称不限)
- 在该目录中创建一个文件 settings.json(名称不限)

settings.json内容如下:
{
"index" : {
"analysis" : {
"analyzer" : {
"synonym" : {
"tokenizer" : "ik_max_word",
"filter" : ["remote_synonym"]
}
},
"filter" : {
"remote_synonym" : {
"type" : "dynamic_synonym",
"synonyms_path" : "http://localhost:2000/kms/synonymWord/synchronizeSynonym",
"interval": 30
},
"local_synonym" : {
"type" : "dynamic_synonym",
"synonyms_path" : "synonym.txt"
},
"synonym_graph" : {
"type" : "dynamic_synonym_graph",
"synonyms_path" : "http://localhost:2000/kms/synonymWord/synchronizeSynonym"
}
}
}
}
}
配置说明(来自于GitHub中项目说明(README.md))
type:dynamic_synonym或dynamic_synonym_graph,必填
synonyms_path:相对于Elastic配置文件或URL的文件路径,必填
interval:刷新同义词文件的时间间隔(以秒为单位),默认值:60,可选
ignore_case:忽略同义词文件中的大小写,默认值:false,可选
expand:展开,默认:true,可选
lenient:导入同义词时抛出的异常例外,默认值:false,可选
format:同义词文件格式,默认值:’’,可选。对于WordNet结构,可以将其设置为’wordnet’
使用配置
完成之后再需要使用同义词的地方通过@Setting(settingPath = “elasticsearch/settings.json”) 引入
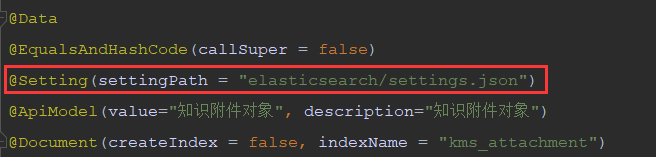
字段中指定分词器是需使用settings中指定的分词器 synonym。完整java类文件如下:
package com.focustar.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.data.elasticsearch.annotations.Setting;
import java.io.Serializable;
/**
*
* 知识附件对象
*
*
* @author 天玺
* @since 2020-11-18
*/
@Data
@EqualsAndHashCode(callSuper = false)
@Setting(settingPath = "elasticsearch/settings.json")
@Document(createIndex = false, indexName = "kms_attachment")
public class TKmsAttachment implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@TableId(value = "PID", type = IdType.AUTO)
private Long pid;
@TableField("Title")
@Field(searchAnalyzer = "synonym", type = FieldType.Text, analyzer = "synonym")
private String title;
private String content;
}
注意:
Document注解中的createIndex 被我设置成false了,不要让他自动创建
title字段上的Field注解,指定的分词器就是settings.json中指定的。
开发同步同义词接口
示例如下:
@GetMapping("/synchronizeSynonym")
public String synchronizeSynonym() {
log.info("开始同步数据库同义词...");
HttpServletRequest request = SpringContextUtils.getCurrentRequest();
String eTag = request.getHeader("If-None-Match");
String modified = request.getHeader("If-Modified-Since");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String currentDate = sdf.format(new Date());
StringBuilder synonymStr = new StringBuilder();
if (!Objects.equals(currentDate, modified)) {
int count = itKmsSynonymwordService.count();
if (!Objects.equals(count + "", eTag)) {
// 获取所有同义词
List<TKmsSynonymword> synonymWords = itKmsSynonymwordService.list();
// 根据同义词组分组
Map<Long, List<TKmsSynonymword>> synonymWordGroup = synonymWords.stream().collect(Collectors.groupingBy(TKmsSynonymword::getSynGroupPid));
for (Map.Entry<Long, List<TKmsSynonymword>> longListEntry : synonymWordGroup.entrySet()) {
// map的key是组ID,value集合对应的就是该组所有同义词
for (TKmsSynonymword tKmsSynonymword : longListEntry.getValue()) {
// 遍历,以 “,” 分割
synonymStr.append(tKmsSynonymword.getSynWord()).append(",");
}
if (synonymStr.length() > 0) {
synonymStr.deleteCharAt(synonymStr.length() - 1);
synonymStr.append("\n");
}
}
eTag = count + "";
modified = currentDate;
} else {
log.info("同义词未更新,不需同步...");
}
}
HttpServletResponse response = SpringContextUtils.getCurrentResponse();
//更新时间
response.setHeader("Last-Modified", modified);
response.setHeader("ETag", eTag);
response.setHeader("Content-Type", "text/plain");
return synonymStr.toString();
}
返回格式:
番茄,西红柿
奔驰,大奔
之后再settings.json中指定该接口
我settings.json中指定的url是:
http://localhost:2000/kms/synonymWord/synchronizeSynonym
es启动时会加载同义词组件,同义词组件根据这个来获取同义词;这个路径是相对于es来说的,es和项目都是在我本地;
在项目启动之后创建索引
package com.focustar.runner;
import com.focustar.entity.custom.TKmsAttachmentCustom;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.IndexOperations;
import org.springframework.data.elasticsearch.core.document.Document;
import org.springframework.data.elasticsearch.core.index.MappingBuilder;
import org.springframework.stereotype.Component;
/**
* 项目启动后调用
*
* @author vains
* @date 2021/2/16 16:57
*/
@Slf4j
@Component
@AllArgsConstructor
public class StartedRunner implements ApplicationRunner {
private final ElasticsearchOperations elasticsearchOperations;
@Override
public void run(ApplicationArguments args) {
// 初始化TKmsAttachmentCustom在es中的索引
initAttachmentIndex();
}
/**
* 在这里创建索引是因为es添加了同义词插件,同义词插件会通过本项目的接口去获取对应的同义词,
* 如果让Spring data es自动创建,那么项目控制器尚未加载成功,这时插件无法获取同义词(请求接口404),
* 那么es 就无法加载同义词插件,如果项目启动成功之后再去创建索引就不会出现上述问题。
*/
private void initAttachmentIndex() {
log.info("开始创建索引...");
IndexOperations indexOperations = elasticsearchOperations.indexOps(TKmsAttachment.class);
MappingBuilder builder = new MappingBuilder(elasticsearchOperations.getElasticsearchConverter());
String mapping = builder.buildPropertyMapping(TKmsAttachment.class);
Document document = Document.parse(mapping);
try {
if (indexOperations.exists()) {
indexOperations.delete();
log.info("索引已经存在,重新创建。");
}
indexOperations.create();
indexOperations.putMapping(document);
log.info("索引创建成功...");
} catch (Exception e) {
log.error("索引创建失败.原因:", e);
}
}
}
至此,同义词组件整合完毕。