二叉树算法专栏一《理论基础》
下面我会介绍一些我在刷题过程中经常用到的二叉树的一些基础知识,所以我不会教科书式地将二叉树的基础内容通通讲一遍。
二叉树的种类
在我们解题过程中二叉树有两种主要的形式:满二叉树和完全二叉树。
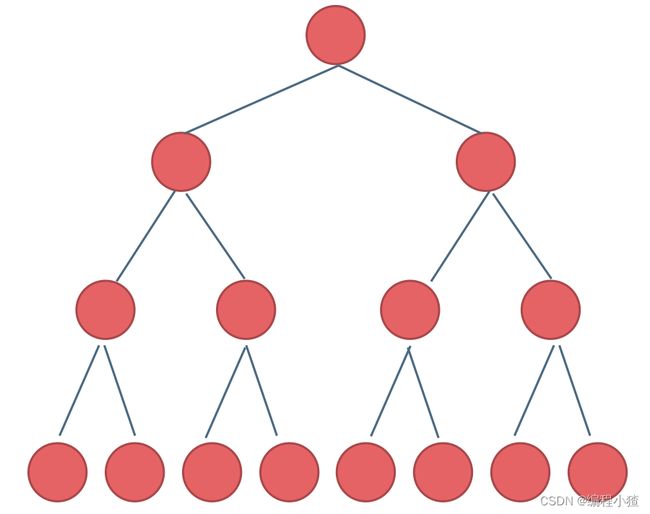
满二叉树
满二叉树是一种特殊的二叉树,具有以下特点:
- 在满二叉树中,每个节点要么没有子节点(度为0),要么恰好有两个子节点(度为二)。
- 对于深度为 k 的满二叉树,其节点数目为 2^k - 1,其中 k ≥ 1。也就是说,深度为 k 的满二叉树总共有 2^k - 1 个节点。
- 满二叉树的结构非常规整,每一层的节点数都是满的,且节点的分布非常均匀。
完全二叉树
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
下面我来举一个例子,看大家是否判断正确了呢
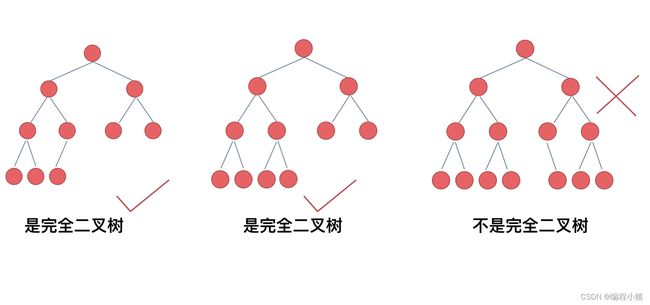
图3不是完全二叉树,因为叶子节点的那一层的所有叶子节点不是全集中在最左侧的位置。
几种特殊的二叉树
二叉搜索树
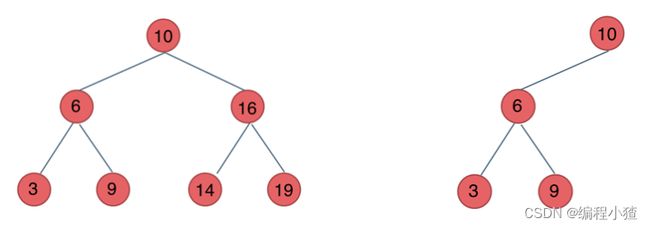
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
如下图就是两个二叉搜索树
平衡二叉搜索树
平衡二叉搜索树(Balanced Binary Search Tree,BBST),也称为自平衡二叉搜索树,是一种特殊的二叉搜索树,它能够在插入或删除节点时自动保持平衡。
二叉搜索树是一种有序的二叉树,其任意节点的值都大于其左子树中任意节点的值,小于其右子树中任意节点的值。但是,当我们在普通的二叉搜索树上插入或删除节点时,可能会出现树的不平衡,导致搜索树的时间复杂度退化为 O(n)。而平衡二叉搜索树通过旋转、重新分配节点等方式自动调整树的结构,使得树保持平衡,从而能够更快地进行查找、插入、删除等操作,时间复杂度能够保持在 O(log n)。
常见的平衡二叉搜索树包括AVL树、红黑树、Splay树、Treap等。
二叉平衡树具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如下图
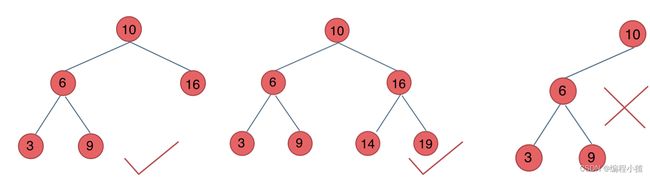
最后一棵 不是平衡二叉树,因为它的左右两个子树的高度差的绝对值超过了1。
java中的TreeMap、HashMap等容器底层都是平衡二叉搜索树实现的。
二叉树的存储方式
二叉树可以链式存储,也可以顺序存储。
链式存储
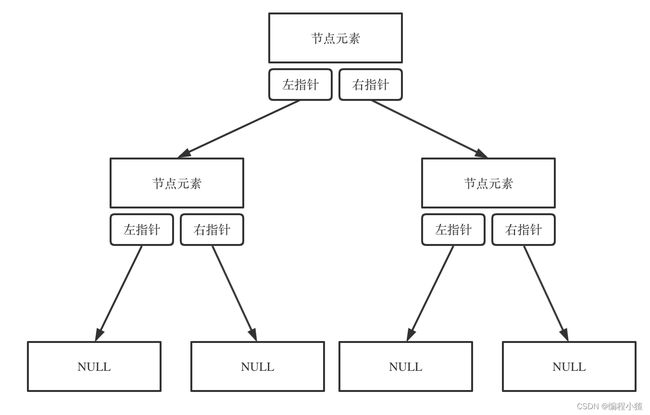
二叉树的链式存储是指使用节点对象和引用来表示二叉树的存储方式。每个节点对象包含一个数据域和两个指针域,分别指向左子节点和右子节点。因此链式存储在内存上是不连续的。
在链式存储中,通过创建节点对象,并通过引用将节点对象连接起来,形成二叉树的结构。根节点作为入口点,通过左右子节点的引用,逐层连接形成完整的二叉树。
下面是链式存储的示例代码:
package dataStructure.binaryTree;
/**
* @author CSDN编程小猹
* @data 2023/12/05
* @description
*/
//树节点类
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int val) {
this.val = val;
}
public TreeNode(){}
public TreeNode(TreeNode left, int val, TreeNode right) {
this.left = left;
this.val = val;
this.right = right;
}
@Override
public String toString() {
return String.valueOf(this.val);
}
}
链式存储如图:
顺序存储
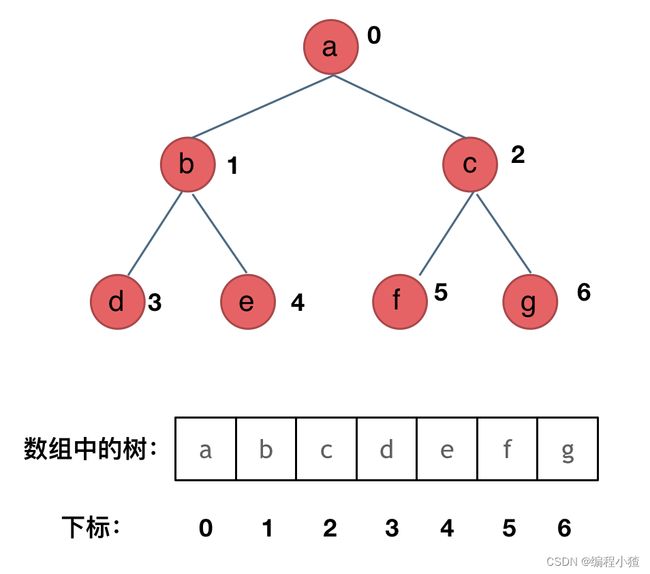
顺序存储就是将二叉树的节点按照某种顺序存储在数组中,因此顺序存储的元素在内存上是连续分布的。顺序存储方式通过数组的索引关系来表示节点之间的父子关系。
对于一棵完全二叉树,可以使用数组进行顺序存储。假设根节点在数组索引0的位置,对于任意节点 i,它的左子节点索引为 2i+1,右子节点索引为 2i+2。这样,我们可以利用数组的连续内存空间来存储二叉树的节点。
下面是顺序存储的示例代码:
package dataStructure.binaryTree;
/**
* @author CSDN编程小猹
* @data 2023/12/05
* @description
*/
public class BinaryTree {
int[] array;
int size;
public BinaryTree(int capacity) {
this.array = new int[capacity];
this.size = 0;
}
public void insert(int data) {
if (size >= array.length) {
throw new ArrayIndexOutOfBoundsException("Binary tree is full");
}
array[size++] = data;
}
public int getRoot() {
if (size == 0) {
throw new IllegalStateException("Binary tree is empty");
}
return array[0];
}
public int getLeftChild(int index) {
int leftChildIndex = 2 * index + 1;
if (leftChildIndex >= size) {
throw new IllegalArgumentException("Invalid index: " + index);
}
return array[leftChildIndex];
}
public int getRightChild(int index) {
int rightChildIndex = 2 * index + 2;
if (rightChildIndex >= size) {
throw new IllegalArgumentException("Invalid index: " + index);
}
return array[rightChildIndex];
}
}顺序存储如图:
二叉树的遍历方式
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
深度优先遍历
前序遍历
口诀:根左右
具体的前序遍历过程如下:
- 访问当前节点(根节点)。
- 递归地前序遍历左子树。
- 递归地前序遍历右子树。
前序遍历有两种方法,分别是递归法和迭代法。
递归法
/**
* 前序遍历
* @param node 节点
*/
static void preOrder(
//确定入参和返回值
TreeNode node) {
//终止条件
if (node == null) {
return;
}
//单层递归的逻辑
System.out.print(node.val + "\t"); // 值
preOrder(node.left); // 左
preOrder(node.right); // 右
}迭代法
//迭代遍历二叉树
前序遍历顺序:中-左-右,入栈顺序:中-右-左
public List preOrderTraversal(TreeNode root){
List result=new ArrayList<>();
if (root==null){
return result;
}
Stack stack=new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node=stack.pop();
result.add(node.val);
if (node.right!=null){
stack.push(node.right);
}
if (node.left!=null){
stack.push(node.left);
}
}
return result;
} 中序遍历
口诀:左根右
具体的前序遍历过程如下:
- 递归地中序遍历左子树
- 访问当前节点(根节点)
- 递归地中序遍历右子树
前序遍历有两种方法,分别是递归法和迭代法。
递归法
/**
* 中序遍历
* @param node 节点
*/
static void inOrder(TreeNode node) {
if (node == null) {
return;
}
inOrder(node.left); // 左
System.out.print(node.val + "\t"); // 值
inOrder(node.right); // 右
}迭代法
// 中序遍历顺序: 左-中-右 入栈顺序: 左-右
public List inOrderTraversal(TreeNode root) {
List result = new ArrayList<>();
if (root == null){
return result;
}
Stack stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
cur = cur.left;
}else{
cur = stack.pop();
result.add(cur.val);
cur = cur.right;
}
}
return result;
} 后序遍历
口诀:左右根
具体的前序遍历过程如下:
- 递归地后序遍历左子树
- 递归地后序遍历右子树
- 访问当前节点(根节点)
前序遍历有两种方法,分别是递归法和迭代法。
递归法
/**
* 后序遍历
* @param node 节点
*/
static void postOrder(TreeNode node) {
if (node == null) {
return;
}
postOrder(node.left); // 左
postOrder(node.right); // 右
System.out.print(node.val + "\t"); // 值
}迭代法
// 后序遍历顺序 左-右-中 入栈顺序:中-左-右 出栈顺序:中-右-左, 最后翻转结果
public List postOrderTraversal(TreeNode root) {
List result = new ArrayList<>();
if (root == null){
return result;
}
Stack stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.left != null){
stack.push(node.left);
}
if (node.right != null){
stack.push(node.right);
}
}
Collections.reverse(result);
return result;
} 看了上面的迭代法遍历二叉树,读者是不是发现每一种不同顺序的遍历代码都有较大的改动。下面介绍一下二叉树的统一迭代法
//二叉树的统一迭代法
//前序遍历
public List preorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
if (root != null) st.push(root);
while (!st.empty()) {
TreeNode node = st.peek();
if (node != null) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.peek(); // 重新取出栈中元素
st.pop();
result.add(node.val); // 加入到结果集
}
}
return result;
}
//中序遍历
public List inorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
if (root != null) st.push(root);
while (!st.empty()) {
TreeNode node = st.peek();
if (node != null) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.peek(); // 重新取出栈中元素
st.pop();
result.add(node.val); // 加入到结果集
}
}
return result;
}
//后序遍历
public List postorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
if (root != null) st.push(root);
while (!st.empty()) {
TreeNode node = st.peek();
if (node != null) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
st.push(node); // 添加中节点
st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.peek(); // 重新取出栈中元素
st.pop();
result.add(node.val); // 加入到结果集
}
}
return result;
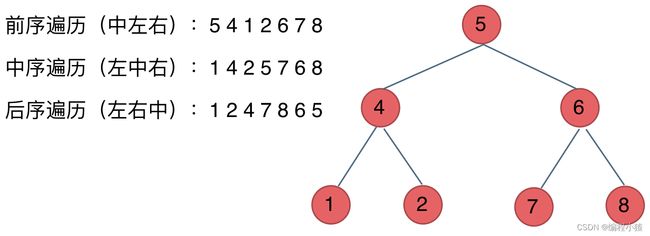
} 读者可以自己遍历一下下图这个二叉树,看你是否掌握了呢?
广度优先遍历
层次遍历
二叉树的层序遍历是一种广度优先搜索(BFS)的遍历方式,按照树的层级依次访问节点。从根节点开始,逐层遍历二叉树的节点。层序遍历可以保证按照从上到下、从左到右的顺序访问二叉树的节点,输出的结果就是二叉树节点的层级顺序。
例如,对于下面的二叉树:

层序遍历的结果为:1, 2, 3, 4, 5, 6。首先访问根节点1,然后是第二层的节点2和3,接着是第三层的节点4、5和6。
与上面的深度优先遍历一样,层次遍历也有递归法和迭代法两者遍历方式。
递归法
public List> resList=new ArrayList>();
public List> levelOrder(TreeNode root){
checkFun02(root,0);
return resList;
}
//递归方式进行层序遍历
private void checkFun02(
//递归要传的参数
TreeNode root, int deep) {
//终止条件
if (root==null) return;
//递归单层逻辑
deep++;
if (resList.size() item=new ArrayList<>();
resList.add(item);
}
//往所在层的集合添加该节点元素
resList.get(deep-1).add(root.val);
//递归调用
checkFun02(root.left,deep);
checkFun02(root.right,deep);
} 迭代法
public List> resList=new ArrayList>();
public List> levelOrder(TreeNode root){
checkFun01(root);
return resList;
}
//迭代方式进行层序遍历--借助队列
private void checkFun01(TreeNode root) {
if (root==null) return;
Queue queue=new LinkedList();
queue.offer(root);
while (!queue.isEmpty()) {
List itemList=new ArrayList<>();
int len=queue.size();
while (len>0){
TreeNode tempNode=queue.poll();
itemList.add(tempNode.val);
if (tempNode.left!=null) queue.offer(tempNode.left);
if (tempNode.right!=null) queue.offer(tempNode.right);
len--;
}
resList.add(itemList);
}
} 二叉树是一种基础数据结构,在算法面试中都是常客,也是众多数据结构的基石。
本篇我介绍了二叉树的种类、存储方式、遍历方式,比较全面的介绍了二叉树各个方面的重点,帮助大家扫一遍基础。后续我会再写一些关于二叉树刷题的博文。都看到这里了,读者大大就点个关注吧,你们的支持是我持续更新的最大动力。