初识Dubbo学习,一文掌握Dubbo基础知识文集(3)

作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。
多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。
欢迎 点赞✍评论⭐收藏
Dubbo知识专栏学习
| Dubbo知识云集 | 访问地址 | 备注 |
|---|---|---|
| Dubbo知识点(1) | https://blog.csdn.net/m0_50308467/article/details/135022007 | Dubbo专栏 |
| Dubbo知识点(2) | https://blog.csdn.net/m0_50308467/article/details/135032998 | Dubbo专栏 |
| Dubbo知识点(3) | https://blog.csdn.net/m0_50308467/article/details/135033596 | Dubbo专栏 |
| Dubbo知识点(4) | https://blog.csdn.net/m0_50308467/article/details/135033677 | Dubbo专栏 |
文章目录
- 一、 Dubbo 知识文集学习(3)
-
-
- 01. Dubbo 和 Dubbox 之间的区别?
- 02. Dubbo 和 Spring Cloud 的关系?
- 03. Dubbo 支持哪些协议,每种协议的应用场景,优缺点?
- 04. Dubbo 推荐用什么协议?
- 05. Dubbo 核心组件有哪些?
- 06. Dubbo 服务器注册与发现的流程?
- 07. Dubbo 的注册中心集群挂掉,服务提供者和订阅者之间还能通信么?
- 08. 同一个服务多个注册的情况下可以直连某一个服务吗?
- 09. 默认使用什么序列化框架,你知道的还有哪些?
- 10. Dubbo 的使用场景有哪些?
- 11. RPC 使用了哪些关键技术,NIO通信?
- 12. Dubbo 在使用过程中都遇到了些什么问题?
- 13. Dubbo 集群容错怎么做?
- 14. Dubbo 集群容错有几种方案?
- 15. Dubbo 能集成 SpringBoot 吗?举例demo说明?
- 16. 你还了解别的分布式框架吗,详细描述一下实现逻辑?
-
一、 Dubbo 知识文集学习(3)
01. Dubbo 和 Dubbox 之间的区别?
Dubbo和DubboX是两个相关的分布式服务框架,它们之间存在一些区别,下面我将详细说明它们之间的区别。
-
项目起源和维护状态:
- Dubbo是阿里巴巴开源的一款高性能Java RPC框架,于2011年发布,采用Apache License 2.0协议。Dubbo的主要维护者为阿里巴巴。
- DubboX是当当网在Dubbo的基础上进行二次开发的一个分支,主要针对了原Dubbo在某些特性上的不足,如对Spring的支持、多协议支持、消息队列等,因此增加了一些扩展特性,以满足当当公司的特定需求。
-
对Spring的支持:
- Dubbo在早期版本对Spring支持并不是很好,需要通过独立的XML配置方式进行集成。
- DubboX引入了对Spring的原生支持,可以直接通过Spring的注解和配置进行集成,提供了更便捷的方式来管理Dubbo的服务和配置。
-
功能扩展:
- Dubbo提供了丰富的服务治理功能以及高性能的远程调用能力,支持负载均衡、容错、路由、监控等特性。
- DubboX在原Dubbo的基础上增加了对多种协议的支持,例如HTTP、REST、WebService等,还增加了对消息中间件(如ActiveMQ、RabbitMQ)的支持,以满足更多场景的需求。
-
社区维护和活跃度:
- Dubbo由于是阿里巴巴的核心产品之一,拥有较为庞大的开发和维护团队,其社区活跃度较高,更新迭代较为频繁。
- DubboX的维护者为当当公司,相对而言,社区活跃度不如Dubbo,更新迭代的速度也相对较慢。
总的来说,Dubbo和DubboX有着一定的联系,DubboX是基于Dubbo的二次开发分支,在功能扩展和对Spring的支持上有所不同。在实际选择时,建议根据具体的业务需求和技术场景来进行评估和选择。目前来看,Dubbo作为主流的分布式 RPC 框架,在性能、稳定性和功能完备性等方面都有较大的优势。
02. Dubbo 和 Spring Cloud 的关系?
Dubbo和Spring Cloud是两个不同的分布式服务框架,它们在分布式系统架构中扮演不同的角色,但也可以结合使用。下面是它们之间的关系:
-
功能定位:
- Dubbo是一款高性能的Java RPC框架,专注于服务之间的远程调用和治理。
- Spring Cloud是一个构建和管理分布式系统的综合性解决方案,包括了服务注册与发现、配置中心、负载均衡、断路器、API Gateway等微服务场景下需要的功能。
-
结合使用:
- 实际应用中,可以将Dubbo用于服务之间的高性能远程调用,同时结合Spring Cloud的服务注册与发现、断路器等功能,实现完整的微服务架构。
- 比如,可以使用Dubbo作为服务之间的通信框架,同时使用Spring Cloud的Eureka来实现服务注册与发现,使用Ribbon来实现负载均衡,使用Hystrix来实现断路器功能,以及使用Zuul来实现API Gateway等。
-
生态整合:
- Spring Cloud生态系统中集成了对Dubbo的支持,通过Spring Cloud Alibaba项目,可以将Dubbo服务注册到Nacos、使用Sentinel进行服务熔断和降级等。
-
场景适用:
- 在传统的企业级应用中,可以使用Dubbo来实现服务之间的远程调用和治理。
- 当需要构建基于云架构的微服务系统时,可以选择Spring Cloud来完成微服务架构的构建和管理。
总的来说,Dubbo和Spring Cloud在分布式系统架构中有不同的定位,Dubbo专注于远程服务调用和治理,Spring Cloud则提供了更全面的微服务开发支持。它们可以在不同的场景下结合使用,充分发挥各自的优势,构建更为完善的分布式系统。
03. Dubbo 支持哪些协议,每种协议的应用场景,优缺点?
Dubbo支持多种协议,每种协议都有不同的应用场景、优点和缺点。下面是Dubbo支持的主要协议以及它们的特点:
-
Dubbo协议:
- 应用场景:Dubbo协议是Dubbo RPC框架的默认协议,适用于Java环境下的服务间通信。
- 优点:高性能,自动序列化协议,支持服务治理功能,适用于传统的Java微服务架构。
- 缺点:对其他语言的支持相对较弱,不太适用于跨语言的服务调用。
-
RMI协议:
- 应用场景:适用于Java环境下的远程方法调用,属于Java标准库的一部分。
- 优点:与Java集成紧密,支持Java标准库中的特性,适用于纯Java环境下的服务调用。
- 缺点:不支持跨语言调用,配置略显复杂,不够灵活。
-
Hessian协议:
- 应用场景:适用于跨语言的服务调用,支持Java、C++等多种语言。
- 优点:跨语言支持良好,性能较好,适用于需要跨语言调用的场景。
- 缺点:由于二进制序列化,通信效率相对较低,不够高效。
-
HTTP协议:
- 应用场景:适用于Web环境下的服务调用,支持跨平台、跨语言。
- 优点:通用性强,支持跨平台、跨语言,易于部署和调试。
- 缺点:相比于Dubbo协议,性能稍逊,不支持服务治理功能,适用于简单的服务调用场景。
-
WebService协议:
- 应用场景:适用于需要遵循WebService标准的服务调用。
- 优点:符合WebService标准,适用于需要遵循该标准的场景。
- 缺点:相对于Dubbo协议,性能和扩展性不足,适用范围有限。
-
Thrift协议:
- 应用场景:适用于多语言的跨平台服务调用。
- 优点:多语言支持,性能较好,适用于需要多语言支持的场景。
- 缺点:相比于Dubbo协议,配置和部署略显复杂,不够轻量级。
每种协议都有其适用的场景和局限性,需要根据具体的业务需求和技术架构来选择合适的协议。在实际应用中,可以根据服务调用的需求,灵活地选择合适的协议来实现服务的远程调用。
04. Dubbo 推荐用什么协议?
Dubbo官方推荐使用Dubbo协议作为默认的协议。Dubbo协议是基于TCP的高性能二进制序列化协议,具有以下优点:
-
高性能: Dubbo协议采用自定义的二进制序列化方式,相比于基于文本的协议,如JSON或XML,性能更优。它的协议头部很小,数据传输效率高,适用于高并发、低延迟的服务调用场景。
-
服务治理功能: Dubbo协议不仅提供基本的调用功能,还提供了丰富的服务治理能力,如负载均衡、容错处理、动态调整配置等。这使得开发者能够更好地管理和控制服务的调用行为。
举一个例子,假设有一个电商系统,需要实现用户服务和商品服务之间的远程调用。在这种场景下,使用Dubbo协议有以下步骤:
-
定义服务接口:定义用户服务和商品服务的接口,例如UserService和ProductService。
-
实现服务提供者:实现UserService和ProductService接口的具体实现,并通过Dubbo框架提供的注解和配置来暴露服务。
-
配置消费者:在用户服务的消费者端,配置Dubbo的消费者信息,包括注册中心的地址、服务接口的引用以及调用相关的配置。
-
调用远程服务:在用户服务中调用商品服务,通过Dubbo框架提供的远程调用功能,使用服务引用来调用商品服务提供的方法。
通过以上步骤,用户服务可以通过Dubbo协议远程调用商品服务,实现了服务的解耦和分布式部署。
总结来说,Dubbo协议由于其高性能和丰富的服务治理功能,是Dubbo框架推荐的默认协议。在构建分布式系统时,使用Dubbo协议可以获得更好的性能和可管理性。
以下是一个简单的示例来说明如何在Dubbo中使用Dubbo协议:
首先,定义一个服务接口,比如HelloService:
public interface HelloService {
String sayHello(String name);
}
然后,实现这个服务接口,在服务提供者端:
public class HelloServiceImpl implements HelloService {
public String sayHello(String name) {
return "Hello, " + name;
}
}
接下来,在服务提供者端,通过XML配置或注解方式,将服务暴露出去:
XML配置方式:
<dubbo:service interface="com.example.HelloService" ref="helloService" />
<bean id="helloService" class="com.example.HelloServiceImpl" />
注解方式:
@Service
public class HelloServiceImpl implements HelloService {
public String sayHello(String name) {
return "Hello, " + name;
}
}
然后,对于服务消费者端,需要引入服务并进行调用:
XML配置方式:
<dubbo:reference id="helloService" interface="com.example.HelloService" />
注解方式:
@Reference
private HelloService helloService;
public void someMethod() {
String result = helloService.sayHello("Alice");
System.out.println(result);
}
在上述示例中,Dubbo协议被作为默认协议来进行服务的提供和引用。在服务提供者端,通过Dubbo框架的配置方式将服务暴露出去,在服务消费者端,通过Dubbo框架的配置方式引入服务并进行远程调用。
05. Dubbo 核心组件有哪些?
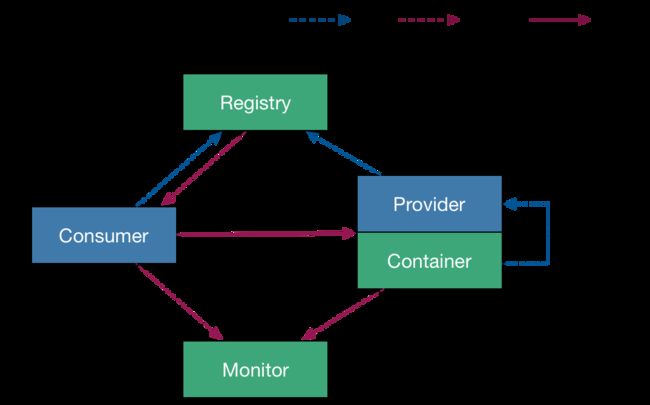
Dubbo框架的核心组件包括以下几部分:
-
服务提供者(Provider): 服务提供者是实际提供服务的一方,将自己的服务注册到注册中心,等待消费者的调用请求。
-
服务消费者(Consumer): 服务消费者是需要调用远程服务的一方,通过注册中心获取服务提供者的地址,并发起远程调用请求。
-
注册中心(Registry): 注册中心是Dubbo框架的核心,用于服务的注册与发现。它接收服务提供者的注册请求,记录服务提供者的地址和元数据,并将这些信息提供给服务消费者用于发起远程调用。
-
集群(Cluster): Dubbo的集群组件用于处理集群容错和负载均衡。它将多个远程服务提供者伪装成一个单一的服务提供者,消费者通过集群组件发起的调用会被分派到具体的服务提供者。
-
配置(Config): Dubbo提供了丰富的配置选项,包括服务接口的定义、提供者与消费者的配置、注册中心的地址与配置、集群的配置等。
-
调用(Invocation): 调用是Dubbo框架中的核心模型,封装了调用的相关信息,包括服务接口、方法名、参数等。调用组件负责将调用信息传递给目标服务提供者,并获取调用结果。
-
远程通信(Remoting): Dubbo支持多种远程通信方式,如基于TCP的Dubbo协议、HTTP协议、RMI协议等。远程通信组件负责处理网络通信细节,实现消息的编解码、传输等功能。
-
序列化(Serialization): Dubbo框架支持多种序列化协议,如Dubbo自带的Hessian、Java原生序列化、Protobuf等。序列化组件负责将Java对象转换为字节流,以便在网络中传输。
-
扩展(Extension): Dubbo框架中的扩展机制非常灵活,可以通过SPI(Service Provider Interface)方式对框架的各个组件进行扩展和替换。
这些核心组件共同构成了Dubbo框架的基础架构,实现了服务的注册、发现、通信和调用等功能,帮助开发者构建分布式应用系统。
06. Dubbo 服务器注册与发现的流程?
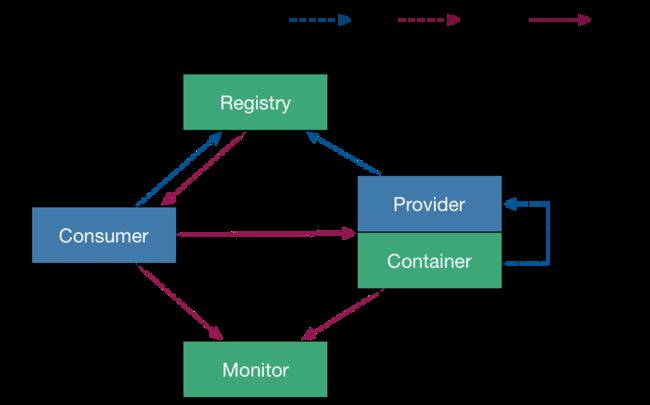
Dubbo 服务器的注册与发现流程如下:
-
服务提供者注册: 服务提供者启动时,会向注册中心注册自己提供的服务信息,包括服务名、地址、协议、端口等。这样,注册中心就会记录下这个服务提供者的信息。
-
服务消费者订阅: 服务消费者启动时,会向注册中心订阅它所需要的服务信息,即根据服务名获取该服务的提供者列表。
-
注册中心更新: 当有新的服务提供者上线或下线时,注册中心会相应地更新服务提供者列表,并通知所有相关的服务消费者。这样,服务消费者就可以获取到最新的服务提供者列表。
-
服务调用: 服务消费者收到注册中心通知后,就可以从最新的服务提供者列表中选择一个提供者,然后发起远程调用请求。
-
负载均衡: 在发起远程调用时,Dubbo框架的负载均衡组件会根据一定策略(例如轮询、随机、最小活跃数等)选择一个具体的服务提供者进行调用,以实现负载均衡的效果。
-
远程通信: 服务消费者通过远程通信组件,如Dubbo协议,与选定的服务提供者建立通信通道,并将调用请求发送给提供者。
-
调用处理: 服务提供者接收到请求后,会将请求交给对应的服务实现进行处理,并将处理结果返回给服务消费者。
以上就是Dubbo服务器注册与发现的完整流程。通过这个流程,Dubbo实现了服务的动态注册与发现,服务消费者可以根据最新的服务提供者列表进行远程调用,从而实现高可用性和负载均衡。
07. Dubbo 的注册中心集群挂掉,服务提供者和订阅者之间还能通信么?
当Dubbo的注册中心集群挂掉时,服务提供者和订阅者之间仍然可以通信。Dubbo框架在设计时就考虑了注册中心的容灾机制,即使注册中心不可用,服务提供者和订阅者之间仍然可以进行通信,但其中一些功能可能会受到影响。
具体影响主要取决于Dubbo中注册中心的选取和框架版本,一般来说,有以下几点影响:
-
服务提供者注册受影响: 新的服务提供者无法注册到注册中心,并且无法更新已注册的服务信息。这意味着新的服务可能无法被服务消费者发现。
-
服务消费者订阅受影响: 由于注册中心不可用,服务消费者无法获取最新的服务提供者列表。这可能导致服务消费者无法发现新的服务提供者,影响动态服务发现。
-
负载均衡失效: Dubbo框架中的负载均衡机制通常依赖于注册中心获取服务提供者列表,当注册中心不可用时,负载均衡可能失效,影响服务提供者的选择和调用质量。
虽然注册中心挂掉会带来上述影响,但Dubbo框架仍然会尽力保证服务提供者和订阅者之间的通信,只是在某些功能上可能会有一定的损失。为了应对这种情况,Dubbo支持多种注册中心的选择,包括Zookeeper、Redis、Nacos等,开发者可以根据自己的需求选择合适的注册中心,并且可以配置多个注册中心形成集群,以提高系统的容灾能力。
08. 同一个服务多个注册的情况下可以直连某一个服务吗?
在Dubbo中,同一个服务可以注册到多个注册中心,这样的情况下是可以直连某一个服务的。
当服务消费者启动时,Dubbo会先通过注册中心获取服务提供者的地址列表,然后再根据负载均衡策略选择一个服务提供者进行通信。默认情况下,Dubbo会使用注册中心作为服务调用的通道,即服务消费者从注册中心获取服务提供者的地址。
但Dubbo也提供了直连(Direct Connection)功能,即可以绕过注册中心直接连接指定的服务提供者。可以在消费者端的配置中,通过设置服务提供者的IP地址及端口,强制指定消费者直连到某个服务提供者。
这种直连的方式通常用于测试、调试或临时绕过注册中心的场景。需要注意的是,直连方式会绕过负载均衡和高可用等特性,因此需要谨慎使用,并确保指定的服务提供者可用。
在Dubbo中配置直连方式,可以通过url配置属性进行设置,例如:
<dubbo:reference id="demoService" interface="com.example.DemoService" url="dubbo://192.168.0.1:20880"/>
需要注意的是,直连方式只适用于单个服务提供者,如果服务提供者有多个实例构成集群,直连方式将无法有效地进行负载均衡。因此,在生产环境中,还是推荐使用注册中心来管理和发现服务。
09. 默认使用什么序列化框架,你知道的还有哪些?
Dubbo框架默认使用Hessian作为序列化框架。Hessian是一种基于HTTP的轻量级的网络传输协议,支持将Java对象进行序列化和反序列化,适合在分布式系统中进行远程调用。
除了Hessian,Dubbo还支持多种其他的序列化框架,包括:
-
Java原生序列化(Java Serialization): Dubbo也支持使用Java原生的序列化方式,即通过
java.io.Serializable接口进行对象的序列化和反序列化。不过相对于其他序列化框架,Java序列化性能较差,不推荐在高性能和大规模数据传输场景下使用。 -
JSON序列化: Dubbo也支持使用JSON格式进行对象序列化。JSON序列化对可读性友好,但相较于二进制格式,其序列化后的数据量较大,且性能较差。
-
Fastjson: Fastjson是阿里巴巴开源的JSON处理框架,提供了快速的JSON序列化和反序列化能力,Dubbo也支持使用Fastjson作为序列化框架。
-
Kryo: Kryo是一个快速、高效的Java对象图形序列化框架,相比Java原生序列化,Kryo具有更好的性能和序列化结果更小的特点,在Dubbo中也可以选择Kryo作为序列化框架。
-
FST: FST(Fast-Serialization)是一种高性能的Java序列化/反序列化库,它可以在不牺牲性能的情况下实现非常高的压缩比率。
这些序列化框架各有特点,在使用Dubbo时,可以根据系统需求和性能考量选择合适的序列化框架。Dubbo提供了灵活的配置选项,可以方便地切换不同的序列化实现。
10. Dubbo 的使用场景有哪些?
Dubbo作为一款高性能、轻量级的服务框架,适合在各种复杂的分布式应用场景中发挥作用。以下是Dubbo常见的使用场景:
-
微服务架构: Dubbo在微服务架构中扮演着至关重要的角色。通过Dubbo,可以实现微服务之间的远程调用、负载均衡、容错机制、服务注册与发现等功能。Dubbo提供的各种特性都使得它成为微服务架构中的理想选择。
-
服务治理: Dubbo提供了一系列服务治理的能力,包括监控、动态配置、路由、负载均衡、集群容错等。这使得Dubbo成为大型系统中实现服务治理的利器。
-
分布式系统: 在分布式系统中,各个节点通常以服务的形式进行交互。Dubbo的远程调用和服务注册功能,能够很好地适用于分布式系统中各个节点之间的通信和协作。
-
RPC服务: Dubbo最初是作为一个RPC框架而设计的,因此当需要在分布式系统中实现高性能的远程过程调用时,Dubbo是一个不错的选择。它提供了丰富的配置和扩展点,可以满足各种RPC场景的需求。
-
互联网应用: 很多互联网公司都在大规模的业务中采用Dubbo作为服务框架,用于支撑其复杂的业务场景。Dubbo在这些互联网应用中承担了服务注册、服务调用、容错处理等重要功能。
-
企业应用集成: 对于企业级应用,Dubbo可以作为服务集成的中间件,用于集成各种异构系统、服务和应用。通过Dubbo,企业可以更加灵活地整合和管理其各种业务和资源。
总的来说,Dubbo适用于各类需要远程调用、服务治理和分布式系统构建的场景,尤其在大型的、高并发的系统中表现出色。同时,Dubbo灵活的配置和扩展机制,也使得它在各种不同的业务场景中都能够发挥作用。
11. RPC 使用了哪些关键技术,NIO通信?

RPC(远程过程调用)使用了以下关键技术,其中包括NIO通信:
-
序列化与反序列化: 在RPC中,需要将数据从一个节点传输到另一个节点。为了在不同的语言和平台之间进行数据交换,需要将对象进行序列化(将对象转换成字节流的过程)和反序列化(将字节流转换成对象的过程)。常见的序列化框架有Hessian、JSON、Protocol Buffers等。
-
网络通信: RPC框架需要提供可靠的网络通信能力,以实现跨网络节点的远程调用。在传统的RPC框架中,通常使用基于阻塞式IO的Socket通信。但现代化的RPC框架通常采用基于NIO(非阻塞IO)实现的网络库,例如Netty、Mina等。NIO通信可以提供更高的并发性和吞吐量,以满足高性能的需求。
-
服务注册与发现: 在RPC架构中,服务提供者和服务消费者需要能够相互感知和发现彼此。为此,RPC框架通常会提供服务注册与发现机制,以便于服务提供者将自己注册到服务注册中心,并由服务消费者从注册中心获取可用的服务地址列表。常见的服务注册与发现机制有ZooKeeper、Consul等。
-
负载均衡: 当存在多个服务提供者时,RPC框架需要提供负载均衡策略,以实现请求的均衡分发到各个服务实例上,以提高系统性能和可靠性。常见的负载均衡策略有随机、轮询、一致性哈希等。
-
容错处理: 在RPC调用过程中,由于网络等原因,可能出现失败、超时、异常等情况。因此,RPC框架需要提供容错机制,以确保系统的稳定性和可靠性。常见的容错处理方式有重试、熔断、限流、降级等。
综上所述,RPC使用了序列化与反序列化技术来进行数据交换,借助NIO通信库实现高性能网络通信,同时结合服务注册与发现、负载均衡和容错处理等关键技术,以构建分布式的、高效的远程调用系统。
12. Dubbo 在使用过程中都遇到了些什么问题?
在使用Dubbo的过程中,一些常见的问题和挑战可能包括以下几点:
-
配置复杂性: Dubbo提供了丰富的配置选项和扩展点,为用户提供了灵活性,但也增加了配置的复杂性。对于新手来说,理解和配置Dubbo的各个组件、协议、注册中心、负载均衡策略等可能存在一定的学习曲线。
-
版本兼容性: Dubbo的不同版本之间可能存在一些不兼容的问题,特别是在升级Dubbo版本时,需要仔细检查和处理可能出现的兼容性问题,以保证系统的稳定运行。
-
网络通信故障: 由于网络的不可靠性,Dubbo在远程通信过程中可能面临网络波动、丢包、延迟等问题。这可能导致服务调用失败、超时等情况,需要合理配置和使用Dubbo提供的容错机制来处理。
-
性能优化: Dubbo在默认情况下配置了一些基本的性能参数,但在面对高并发、大规模的系统时,可能需要进一步进行性能优化。这可能涉及到调整线程池的大小、配置序列化方式、优化网络传输等方面。
-
分布式事务: 当使用Dubbo作为服务框架,涉及到分布式事务的场景时,需要特别关注分布式事务的一致性和可靠性,以确保各个事务操作能够正确执行和回滚。
-
监控和调试: Dubbo提供了一些监控和调试工具,例如Dubbo Admin、Dubbo Monitor等,但在集成和使用这些工具时,可能需要做一些额外的配置和调试工作,以监控和定位系统中的问题。
总的来说,Dubbo是一项功能强大的框架,但在使用过程中可能会遇到一些配置、兼容性、网络通信、性能、分布式事务和调试等方面的问题。然而,Dubbo拥有强大的社区支持和活跃的开发团队,可以通过文档、社区论坛、官方博客等渠道获得解决方案和支持。
13. Dubbo 集群容错怎么做?
Dubbo 提供了多种集群容错的策略,以保证在分布式系统中提供的服务在遇到异常情况时能够有所容错,提高系统的可靠性。以下是 Dubbo 中常用的集群容错策略:
-
Failover 失败自动切换: 默认的集群容错策略。当调用出现失败时,Dubbo 会自动切换到另一台机器上去,进行重试。适用于一些非幂等性的操作,如新增数据。
-
Failfast 快速失败: 当调用出现失败时,Dubbo 会立即抛出异常,不重试其它的结点。适合对实时性要求较高的读操作,如查询等。
-
Failsafe 失败安全: 当调用出现失败时,Dubbo 只记录错误,不抛出异常。适用于写入审计日志等操作。
-
Failback 失败自动恢复: 针对 Failover 的调用机制。用于对失败的服务调用进行恢复,当服务提供者重启后,返回服务。
-
Forking 并行调用: 将请求同时发送到多个服务提供者,只要有一个成功即返回。适合对可靠性要求较高的读操作,如广告推送等。
-
Broadcast 广播调用: 将请求发送到所有的服务提供者,任意一台报错则将异常抛出。适合通知所有提供者做同等操作的场景。
每种集群容错策略都有其适用的场景,根据具体业务需求和系统架构选择合适的策略是非常重要的。在 Dubbo 中,通过配置文件或者代码,可以灵活地指定所需的集群容错策略。
通过使用 Dubbo 提供的集群容错策略,可以有效地提高分布式系统的稳定性和可靠性,减少因为网络波动、节点故障等导致的服务不可用问题。
14. Dubbo 集群容错有几种方案?
Dubbo 提供了多种集群容错方案,用于处理分布式系统中服务调用的失败和异常情况,以提高系统的可靠性。以下是 Dubbo 中常用的集群容错方案:
-
Failover(失败自动切换):默认的集群容错策略。当服务调用失败时,Dubbo 会自动切换到另一台可用的服务提供者上进行重试。适用于一些非幂等的操作,例如写入数据库。
-
Failfast(快速失败):当服务调用失败时,Dubbo 会立即返回失败结果,不进行重试。适用于一些实时性要求较高的读操作,例如查询。
-
Failsafe(失败安全):当服务调用失败时,Dubbo 只会记录错误,不抛出异常,允许调用继续进行。适用于一些不影响正常流程的写入审计日志等操作。
-
Failback(失败自动恢复):针对 Failover 的调用机制。用于对失败的服务调用进行恢复,当服务提供者重启后,返回服务。
-
Forking(并行调用):将请求同时发送给多个服务提供者,只要有一个成功即返回结果。适用于对可靠性要求较高的读操作,例如广告推荐等。
-
Broadcast(广播调用):将请求发送给所有的服务提供者,任意一台出现异常则将异常抛出。适用于需要通知所有提供者做相同操作的场景。
通过配置合适的集群容错策略,可以根据业务需求和系统架构来进行选择,以实现系统的稳定运行和可靠性调用。Dubbo 的集群容错方案可以在配置文件或代码中进行灵活配置和指定。
15. Dubbo 能集成 SpringBoot 吗?举例demo说明?
当然可以!Dubbo可以很容易地与Spring Boot集成,实现微服务架构。以下是一个简单的示例,说明如何在Spring Boot应用程序中集成Dubbo:
首先,确保在pom.xml文件中添加Dubbo和Spring Boot的依赖:
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>2.7.14version>
dependency>
然后,创建一个Dubbo服务接口和实现:
// 接口
public interface HelloService {
String sayHello(String name);
}
// 实现
@Service
public class HelloServiceImpl implements HelloService {
public String sayHello(String name) {
return "Hello, " + name;
}
}
接着,将Dubbo服务暴露为一个Spring Bean:
@Configuration
public class DubboConfiguration {
@DubboService
private HelloService helloService;
// 可以在这里配置Dubbo的其他一些参数
}
最后,在application.properties文件中配置Dubbo的注册中心和协议:
# Zookeeper注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
# Dubbo协议端口
dubbo.protocol.port=20880
通过以上步骤,就成功地将Dubbo整合进Spring Boot应用程序中了。当Spring Boot启动时,Dubbo服务也会被自动注册到Zookeeper注册中心,并监听指定的端口。这样,其他消费者就可以通过Dubbo注册中心发现和调用这些服务了。
16. 你还了解别的分布式框架吗,详细描述一下实现逻辑?
除了Dubbo,还有一些其他的分布式框架,例如Spring Cloud、Apache Kafka和Apache ZooKeeper等。下面我将详细描述这些分布式框架的实现逻辑:
-
Spring Cloud:Spring Cloud是一个用于构建分布式系统的开发工具集。它提供了一系列组件和库,用于解决分布式系统常见的模式和问题,例如服务注册与发现、负载均衡、服务熔断、配置管理等。Spring Cloud一般基于Spring Boot开发,利用Spring的依赖注入和面向切面编程的特性,实现了分布式系统各个组件之间的协作和交互。通过使用Spring Cloud的注解和配置,可以快速构建和扩展分布式系统。
-
Apache Kafka:Apache Kafka是一个高性能的分布式消息队列系统。它基于发布-订阅的模式,用于处理大规模的流式数据。Kafka的实现逻辑主要包括以下几个组件:生产者、消费者和消息代理。生产者负责将消息发送到Kafka集群,消费者负责从集群中读取消息并进行处理,而消息代理则负责存储和分发消息。Kafka的关键特性是高吞吐量、持久性和可水平扩展性,使其非常适合构建实时流处理、日志聚合等大规模数据处理应用。
-
Apache ZooKeeper:Apache ZooKeeper是一个高性能的分布式协调服务。它通过提供一个分布式的、层次化的文件系统,来实现协调和共享信息的能力。ZooKeeper的实现逻辑主要涉及以下几个部分:数据模型、原子广播和客户端接口。ZooKeeper的数据模型类似于文件系统,可以创建和管理节点,节点可以存储数据和子节点。原子广播则确保在ZooKeeper集群中节点的一致性,通过Zab协议实现多节点之间的数据同步。客户端接口允许应用程序与ZooKeeper进行交互,例如创建和更新节点、监听节点变化等。ZooKeeper被广泛应用于分布式系统中的协调和配置管理等场景。
以上是对一些分布式框架的简要描述,每个分布式框架都有自己特定的实现逻辑和设计理念,具体的细节还需要进行进一步的学习和实践。
