从认识到使用精通,一问掌握Hibernate知识使用文集

作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。
多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。
欢迎 点赞✍评论⭐收藏
文章目录
- 认识Hibernate系列知识
-
- 一、认识Hibernate系列(1)
-
- 01. Hibernate 使用步骤?
- 02. Hibernate 中实体对象的三种状态?
- 03. Hibernate 的数据加载方式?
- 04. Hibernate 如何延迟加载?
- 05. Hibernate 中怎样实现类之间的关系?
- 06. 如何优化 Hibernate?
- 07. 说下 Hibernate 缓存机制?
- 08. Hibernate 的工作原理?
- 09. Hibernate 如何连接数据库?
- 10. Hibernate 如何进行数据库写操作?
- 11. Hibernate 如何从数据中载入对象?
- 12. Hibernate 如何进行数据库查询操作?
- 13. cascade 属性和 inverse 属性的作用和区别?
- 14. Hibernate 中 get( )与 load( )区别?
- 15. Hibernate 支持两种查询方式?
认识Hibernate系列知识
一、认识Hibernate系列(1)
01. Hibernate 使用步骤?

Hibernate 是一个流行的 Java ORM(对象关系映射)框架,它简化了将对象模型映射到关系数据库的过程。下面是 Hibernate 的使用步骤,并附带一个简单的示例:
步骤 1:添加 Hibernate 依赖
首先,需要在项目中添加 Hibernate 的相关依赖。可以通过 Maven 或 Gradle 进行管理,以下是一个 Maven 的示例:
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-coreartifactId>
<version>5.5.7.Finalversion>
dependency>
步骤 2:配置 Hibernate
在项目中创建 Hibernate 配置文件,通常是一个名为 hibernate.cfg.xml 的 XML 文件。在配置文件中,需要指定数据库连接信息、持久化类映射等。例如,以下是一个简单的配置文件示例:
DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialectproperty>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driverproperty>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/mydatabaseproperty>
<property name="hibernate.connection.username">rootproperty>
<property name="hibernate.connection.password">passwordproperty>
<property name="hibernate.hbm2ddl.auto">updateproperty>
<mapping class="com.example.User"/>
session-factory>
hibernate-configuration>
步骤 3:定义持久化类
创建 Java 类来表示数据库中的表格。这些类通常被称为实体类或POJO类。例如,以下是一个简单的 User 类示例:
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int age;
// Getter and Setter methods
// ...
}
步骤 4:使用 Hibernate 进行数据库操作
在代码中使用 Hibernate 进行数据库操作,如新增、查询、更新和删除等。以下是一个使用 Hibernate 保存用户的示例:
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class Main {
public static void main(String[] args) {
// 创建 Hibernate 配置对象
Configuration configuration = new Configuration().configure();
// 创建 SessionFactory
SessionFactory sessionFactory = configuration.buildSessionFactory();
// 创建 Session
Session session = sessionFactory.openSession();
// 在事务中保存用户
Transaction transaction = session.beginTransaction();
User user = new User();
user.setName("John");
user.setAge(25);
session.save(user);
transaction.commit();
// 关闭资源
session.close();
sessionFactory.close();
}
}
上述示例演示了 Hibernate 的基本用法,包括配置 Hibernate、定义实体类以及使用 Hibernate 进行数据库操作。
请注意,这只是 Hibernate 的基本用法示例,实际应用中可能涉及更多功能和配置。需要根据具体需求和项目情况来完善和扩展 Hibernate 的使用。
02. Hibernate 中实体对象的三种状态?
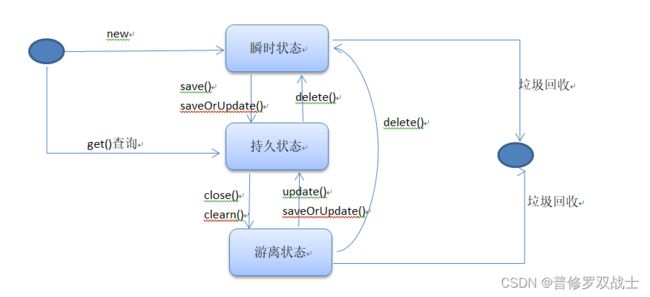
在 Hibernate 中,实体对象具有以下三种状态:
-
瞬时态(Transient):当一个 Entity 实例被创建时,它处于瞬时态。在这个状态下,实例与 Session 没有关联,没有被持久化,没有与数据库中的任何记录对应。如果想要将这个实例持久化,需要将其作为一个新的持久化对象保存在数据库中。
-
持久态(Persistent):当一个瞬时态的实例被保存到数据库中,并与 Session 关联时,它就变成了持久态。在这个状态下,实例与数据库中的相应记录对应,任何对实例的修改会在提交事务或者手动 flush 之后同步到数据库。
-
游离态(Detached):在一个 Session 关闭或者事务提交之后,持久化对象就变成了游离态。在这个状态下,实例与 Session 脱离关联,但是仍然与数据库中的相应记录对应。虽然游离态的实例不能直接进行持久化操作,但是可以通过调用 Session 的 update、merge 或者 saveOrUpdate 方法将其重新关联到一个新的 Session,将其状态变成持久态。
03. Hibernate 的数据加载方式?
Hibernate 提供了三种主要的数据加载方式:
1. 延迟加载(Lazy Loading):延迟加载是指在使用实体对象的关联属性时,不会立即从数据库中加载关联数据,而是在真正需要使用时才去执行数据库查询。例如,考虑一个订单(Order)实体类和商品(Product)实体类之间的一对多关系,使用延迟加载的方式,当你访问订单对象的商品集合时,Hibernate 会在需要时才查询加载相关的商品数据。
@Entity
public class Order {
// ...
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
private List<Product> products;
// ...
}
2. 即时加载(Eager Loading):即时加载是指在查询实体对象时,会立即从数据库中加载关联数据。即使你不明确通过访问关联属性来使用这些数据,Hibernate 也会一起加载。举个例子,如果一个订单对象(Order)具有一个客户对象(Customer)的引用,使用即时加载的方式,当查询订单对象时,Hibernate 会立即从数据库中加载并关联客户对象。
@Entity
public class Order {
// ...
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "customer_id")
private Customer customer;
// ...
}
3. 显式加载(Explicit Loading):显式加载是通过调用 Session 或者 Query 对象的方法来手动加载关联数据。这种方式可以在需要时灵活地控制数据加载的时机。例如,你可以使用 session.load() 方法在需要时加载一个对象的关联数据。
// 显式加载订单对象的商品集合
Order order = session.load(Order.class, 1L);
Hibernate.initialize(order.getProducts());
需要注意的是,延迟加载和即时加载是通过配置实体的映射注解(如 fetch 属性)来进行设置,而显式加载是在代码中通过调用相关方法来触发。具体的数据加载方式取决于你的业务需求和性能优化考虑。
04. Hibernate 如何延迟加载?
Hibernate 提供了两种方式来延迟加载实体对象的相关属性:
1. 使用 Fetch 属性:可以通过在实体类的映射注解中,使用 fetch = FetchType.LAZY 或 fetch = FetchType.LAZY 使属性进行延迟加载或即时加载。
@Entity
public class Order {
// ...
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
private List<Product> products;
// ...
}
在这个例子中,订单(Order)对象的商品集合属性(products)使用 FetchType.LAZY 进行了配置,在查询订单对象时,默认不会立即从数据库中加载关联的商品数据,只有在使用 getProducts() 方法时,才会真正去查询、加载数据。
2. 使用懒加载代理:Hibernate 还可以通过为延迟加载的属性属性创建一个代理对象来实现延迟加载。代理对象会在第一次访问属性时,通过代理方法去查询和加载属性相关的数据。
@Entity
public class Order {
// ...
@OneToMany(mappedBy = "order")
private List<Product> products;
public List<Product> getProducts() {
if (!(products instanceof HibernateProxy)) {
return products;
}
Hibernate.initialize(products);
return products;
}
// ...
}
在这个例子中,订单(Order)对象的商品集合属性(products)在 get 方法中使用了 Hibernate 提供的懒加载代理,当第一次访问商品集合属性时,会通过 Hibernate.initialize() 方法去加载关联的商品数据。
需要注意的是,延迟加载可以帮助减轻数据库负担,避免不必要的数据查询和加载,但同时也可能引发 N+1 问题(N+1 查询问题),特别是在向集合加载大量数据时。因此,在使用延迟加载时要结合具体业务需求和性能考虑,避免潜在的性能问题。
05. Hibernate 中怎样实现类之间的关系?
在 Hibernate 中,类之间的关系主要通过以下几种方式实现:
1. 一对一关系(One-to-One Relationship):一个类与另一个类之间的关系是一对一的关系。例如,一个人(Person)对象与身份证(IDCard)对象之间的关系可以是一对一的。在这种关系下,可以使用 @OneToOne 注解来建立关系。
@Entity
public class Person {
// ...
@OneToOne(mappedBy = "person")
private IDCard idCard;
// ...
}
@Entity
public class IDCard {
// ...
@OneToOne
private Person person;
// ...
}
2. 一对多关系(One-to-Many Relationship):一个类与另一个类之间的关系是一对多的关系。例如,一个订单(Order)对象与多个商品(Product)对象之间的关系可以是一对多关系。在这种关系下,可以使用 @OneToMany 和 @ManyToOne 注解来建立关系。
@Entity
public class Order {
// ...
@OneToMany(mappedBy = "order")
private List<Product> products;
// ...
}
@Entity
public class Product {
// ...
@ManyToOne
@JoinColumn(name = "order_id")
private Order order;
// ...
}
3. 多对一关系(Many-to-One Relationship):多个类与一个类之间的关系是多对一的关系。例如,多个商品(Product)对象与一个分类(Category)对象之间的关系可以是多对一关系。在这种关系下,可以使用 @ManyToOne 和 @OneToMany 注解来建立关系。
@Entity
public class Product {
// ...
@ManyToOne
@JoinColumn(name = "category_id")
private Category category;
// ...
}
@Entity
public class Category {
// ...
@OneToMany(mappedBy = "category")
private List<Product> products;
// ...
}
4. 多对多关系(Many-to-Many Relationship):多个类与多个类之间的关系是多对多的关系。例如,多个学生(Student)对象与多个课程(Course)对象之间的关系可以是多对多关系。在这种关系下,可以使用 @ManyToMany 注解来建立关系,并使用中间表来映射关联关系。
@Entity
public class Student {
// ...
@ManyToMany
@JoinTable(name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id"))
private List<Course> courses;
// ...
}
@Entity
public class Course {
// ...
@ManyToMany(mappedBy = "courses")
private List<Student> students;
// ...
}
通过以上的示例,可以清晰地看到如何通过不同的注解来建立类之间的关系,并使用外键或者中间表来维护这些关系。根据具体的业务需求,可以灵活地选择适合的关系方式来建模和映射对象之间的关联关系。
06. 如何优化 Hibernate?
Hibernate 作为一款 ORM 框架,可以帮助开发者快速地操作数据库,提高开发效率,但也会存在一些潜在的性能问题。下面列举几点 Hibernate 优化的方法:
-
缓存优化:Hibernate 采用了缓存机制,可以通过开启二级缓存或一级缓存来减少数据库访问次数。开启缓存机制以后,可以优化大量的查询,加快应用程序的响应速度。需要注意在使用缓存时,要避免缓存数据与数据库数据不一致的问题,应该谨慎选择合适的缓存策略。
-
懒加载优化:Hibernate 默认采用的是懒加载策略,可以通过设置 fetch 属性来决定对象关联属性的加载方式,提高查询效率。懒加载可以避免不必要的数据加载,减少数据库访问次数。
-
HQL 语句优化:Hibernate 采用 HQL 语句来操作数据库,可以优化 HQL 语句,尽量避免全表扫描,使用索引来加速查询。
-
批量操作优化:当需要对多个对象进行相似的操作时,可以使用批量操作来提高性能。例如,使用 BatchSize 注解控制批量加载的大小,使用批量插入、更新或删除操作来减少数据库访问次数。
-
数据库连接池优化:数据库连接池是一种常用的数据库连接管理方式,可以避免反复创建和销毁数据库连接对象,提高数据库连接的使用效率。可以通过设置连接池的最大连接数、最小连接数、连接超时时间等参数来优化应用程序的性能。
-
排序优化:在进行分页查询时,排序会影响查询效率。应该根据实际业务需求决定是否需要排序,避免不必要的排序操作。
-
事务管理优化:事务管理是保障数据完整性的重要手段,但也会对应用程序的性能产生一定的影响。在事务的管理上,应该尽量减少事务的范围,使用批量操作或分布式事务等技术来优化事务管理。
通过以上优化措施,可以提高 Hibernate 应用程序的性能,降低数据库访问次数,提高应用程序的响应速度。但是,需要注意使用优化方法时,应该结合实际需求来进行综合考虑,因为有时候优化措施可能会导致代码可读性和可维护性的降低,需要在优化和实用性之间做出合适的平衡。
07. 说下 Hibernate 缓存机制?
Hibernate 缓存机制是指通过将数据缓存在内存中,减少对数据库的访问,提高应用程序的性能和响应速度。Hibernate提供了两级缓存和查询缓存两种缓存机制。
-
二级缓存(Second-Level Cache):
二级缓存是对全局对象进行缓存,可以被多个 Session 共享。它的作用范围跨越 session,通常基于应用程序的整个生命周期或者更长的时间段。二级缓存的实现需要依赖外部的缓存提供者,如 Ehcache、Redis 等。
Hibernate 的二级缓存可以通过配置文件或注解指定使用哪个缓存提供者,如下所示:
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>二级缓存可以缓存实体对象或集合对象,可以通过设置
@Cacheable注解或配置文件来指定哪些实体或集合需要被缓存。 -
一级缓存(First-Level Cache):
一级缓存是基于 Session 的缓存,每个 Session 都有自己独立的一级缓存。当从数据库查询一个实体对象时,Hibernate 会将查询结果缓存在一级缓存中。如果后续查询相同的实体对象,Hibernate 将会直接从一级缓存中获取对象,而不再查询数据库。
一级缓存是默认开启的,不需要额外的配置。可以通过 Hibernate 的 Session 的
evict()、clear()等操作来管理一级缓存。 -
查询缓存(Query Cache):
查询缓存是用于缓存 HQL 或 Criteria 查询的结果。对于相同的查询语句,如果参数相同,Hibernate 会将查询结果缓存起来。在下次相同查询执行时,直接从查询缓存中获取结果,减少对数据库的访问。
查询缓存需要通过配置文件或注解手动开启,并通过
@QueryHint注解或查询配置文件指定要使用查询缓存。
缓存机制可以有效减少与数据库的交互次数,提高应用程序的性能。但需要注意的是,缓存机制也会带来一致性的问题。当数据库中的数据发生更新时,缓存中的数据可能不再与数据库保持一致,因此在使用缓存机制时需要谨慎考虑缓存的有效性和一致性问题。
08. Hibernate 的工作原理?

Hibernate 的工作原理可以分为如下几个步骤:
-
创建 SessionFactory:
SessionFactory 是 Hibernate 的核心组件,是生成并管理 Session 的工厂。SessionFactory 在应用程序启动时创建一次,并在整个应用程序的生命周期中使用。SessionFactory 会通过 Hibernate 配置或 Java 代码来读取持久化对象映射信息,然后生成对应的 Persistence Classes。
-
创建 Session:
在应用程序需要访问持久化数据时,需要创建一个 Session 对象,它代表了单个的数据库连接。Session 负责从数据库中读取或写入数据。Session 可以通过 SessionFactory 创建,而且通常情况下,一个 Session 表示单个事务,事务结束时,Session 会被关闭。
-
加载或保存对象:
在使用 Hibernate 时,需要加载或保存具体的实体对象。Session 对象提供了常规的 CRUD(Create、Retrieve、Update、Delete)操作方法,如
save(),get(),update(),delete()等,以及一些查询条件操作方法,如createQuery(),createCriteria()等。 -
生成 SQL 语句:
如果需要查询或保存对象,则 Hibernate 会将相应的 HQL 语句转换成 SQL 语句,并使用 JDBC API 与数据库进行交互,以获取或更新数据。Hibernate 通过解析 Persistence Classes 和 HQL 查询语句,生成对应的 SQL 语句,通过 JDBC 来与数据库进行通信。
-
执行 SQL 语句:
最后一步是执行 SQL 语句,并从数据库中读取或写入数据。Hibernate 使用 JDBC 驱动程序与数据库进行通信。Hibernate 会把结果集转换成具体对象,然后存储在 Session 对象的缓存中,供后续的查询操作使用。
以上就是 Hibernate 的工作原理,Hibernate 通过生成对应的 Persistence Classes 和 HQL 语句,然后转换成 SQL 语句并使用 JDBC 与数据库进行通信。Hibernate 还提供了缓存机制来提高应用程序性能和响应速度。开发人员可以通过 Hibernate 配置或注解来管理缓存的机制和行为。
09. Hibernate 如何连接数据库?
Hibernate连接数据库需要配置数据库连接信息,具体步骤如下:
-
添加相关依赖:
在项目的构建配置文件中,添加 Hibernate 相关的依赖,例如 Maven 的
pom.xml文件中添加如下依赖:<dependency> <groupId>org.hibernategroupId> <artifactId>hibernate-coreartifactId> <version>{Hibernate版本号}version> dependency> <dependency> <groupId>{数据库驱动程序的groupId}groupId> <artifactId>{数据库驱动程序的artifactId}artifactId> <version>{数据库驱动程序的版本号}version> dependency> -
配置 Hibernate 属性:
在项目的配置文件中,配置 Hibernate 的相关属性。可以使用 Hibernate 的 XML 配置文件或者通过 Java 代码进行配置。以下是一个 Hibernate 配置文件的示例:
DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driverproperty> <property name="hibernate.connection.url">jdbc:mysql://localhost:3306/mydatabaseproperty> <property name="hibernate.connection.username">rootproperty> <property name="hibernate.connection.password">passwordproperty> <property name="hibernate.dialect">org.hibernate.dialect.MySQLDialectproperty> <property name="hibernate.show_sql">trueproperty> <property name="hibernate.hbm2ddl.auto">updateproperty> <mapping class="com.example.model.User" /> session-factory> hibernate-configuration>在上述配置文件中,需要设置
hibernate.connection.driver_class为使用的数据库驱动程序的完整路径,以及hibernate.connection.url、hibernate.connection.username和hibernate.connection.password为数据库的连接信息。 -
创建 SessionFactory:
在应用程序中创建一个 SessionFactory 实例,可以通过如下方式之一创建:
a. 使用
StandardServiceRegistryBuilder和MetadataSources创建 SessionFactory:StandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder() .configure() // 加载 Hibernate 配置文件 .build(); MetadataSources sources = new MetadataSources(standardRegistry); // 注册持久化类 sources.addAnnotatedClass(com.example.model.User.class); // 构建 SessionFactory SessionFactory sessionFactory = sources.buildMetadata().buildSessionFactory();b. 使用
Configuration创建 SessionFactory:Configuration configuration = new Configuration().configure(); // 加载 Hibernate 配置文件 configuration.addAnnotatedClass(com.example.model.User.class); // 注册持久化类 SessionFactory sessionFactory = configuration.buildSessionFactory(); -
创建 Session:
使用 SessionFactory 创建 Session 对象,开始执行数据库操作。
Session session = sessionFactory.openSession();
以上是 Hibernate 连接数据库的一般步骤。在实际应用中,需要根据具体情况配置数据库连接信息,并注册持久化类。这样就可以通过 Hibernate 进行数据库操作了。
10. Hibernate 如何进行数据库写操作?

Hibernate 是一个开源的 Java 框架,它提供了一个对象-关系映射(ORM)工具,使得 Java 开发人员可以更便捷地访问和管理数据库。如果要进行数据库写操作,可以通过以下步骤使用 Hibernate:
- 为 Hibernate 配置数据源和 SessionFactory。
- 实例化 Hibernate 的 Session 对象。
- 开始事务。
- 创建一个持久化对象并设置其属性。
- 使用 Session 的 save() 方法将对象持久化到数据库中。
- 提交事务。
下面是一个示例代码:
Transaction transaction = null;
try (Session session = sessionFactory.openSession()) {
// 开始事务
transaction = session.beginTransaction();
// 创建一个持久化对象
CustomObject obj = new CustomObject();
obj.setName("Test");
obj.setValue(123);
// 保存对象到数据库
session.save(obj);
// 提交事务
transaction.commit();
} catch (Exception e) {
if (transaction != null) {
// 回滚事务
transaction.rollback();
}
e.printStackTrace();
}
在这个示例中,我们使用 SessionFactory 对象创建一个 Session 对象,并在事务的上下文中创建一个持久化对象,并通过 save() 方法将其保存到数据库中。最后,我们提交事务以确保写操作成功。
11. Hibernate 如何从数据中载入对象?

在 Hibernate 中,要从数据库中加载对象,可使用以下步骤:
- 为 Hibernate 配置数据源和 SessionFactory。
- 实例化 Hibernate 的 Session 对象。
- 打开会话并获取特定对象。
- 在事务的上下文中通过 Session 的 get() 或 load() 方法加载对象。
下面是一个示例代码:
try (Session session = sessionFactory.openSession()) {
// 开始事务
Transaction transaction = session.beginTransaction();
// 从数据库中加载对象
CustomObject obj = session.get(CustomObject.class, 1L);
// 提交事务
transaction.commit();
// 使用加载的对象进行后续操作
System.out.println(obj.toString());
} catch (Exception e) {
e.printStackTrace();
}
在这个示例中,我们使用 SessionFactory 对象创建了一个 Session 对象。然后,在事务的上下文中,通过调用 Session 的 get() 方法,我们从数据库中加载了一个 CustomObject 类型的对象。注意,我们需要传递类的类型和对象的标识符作为参数。
请注意,Hibernate 还提供了 load() 方法来加载对象。与 get() 方法不同的是,load() 方法在获取对象时只返回一个代理对象,并不立即执行数据库查询。只有在需要访问具体属性时,才会触发数据库查询。使用哪种方法取决于您的业务需求。
12. Hibernate 如何进行数据库查询操作?

在 Hibernate 中进行数据库查询操作可以使用 HQL(Hibernate Query Language)或者 Criteria API。下面分别介绍这两种方式:
1. 使用 HQL 进行数据库查询操作:
HQL 是 Hibernate 提供的一种面向对象的查询语言,类似于 SQL。您可以通过编写 HQL 查询语句来查询数据库中的数据。
示例代码:
try (Session session = sessionFactory.openSession()) {
// 开始事务
Transaction transaction = session.beginTransaction();
// 编写 HQL 查询语句
String hql = "SELECT obj FROM CustomObject obj WHERE obj.name = :name";
Query<CustomObject> query = session.createQuery(hql, CustomObject.class);
query.setParameter("name", "Test");
// 执行查询
List<CustomObject> resultList = query.getResultList();
// 提交事务
transaction.commit();
// 遍历查询结果
for (CustomObject obj : resultList) {
System.out.println(obj.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
在这个示例中,我们通过 HQL 查询语句选择了符合特定条件的 CustomObject 对象。通过 createQuery() 方法创建一个 Query 对象,并设置查询参数。然后,通过 getResultList() 方法执行查询操作,获取匹配的结果。
2. 使用 Criteria API 进行数据库查询操作:
Criteria API 是 Hibernate 提供的一种类型安全且面向对象的查询方式。您可以通过使用 Criteria API 构建查询条件并执行查询操作。
示例代码:
try (Session session = sessionFactory.openSession()) {
// 开始事务
Transaction transaction = session.beginTransaction();
// 使用 Criteria API 构建查询条件
CriteriaBuilder criteriaBuilder = session.getCriteriaBuilder();
CriteriaQuery<CustomObject> criteriaQuery = criteriaBuilder.createQuery(CustomObject.class);
Root<CustomObject> root = criteriaQuery.from(CustomObject.class);
criteriaQuery.select(root).where(criteriaBuilder.equal(root.get("name"), "Test"));
// 执行查询
List<CustomObject> resultList = session.createQuery(criteriaQuery).getResultList();
// 提交事务
transaction.commit();
// 遍历查询结果
for (CustomObject obj : resultList) {
System.out.println(obj.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
在这个示例中,我们使用 Criteria API 构建了查询条件。首先,通过 session 的 getCriteriaBuilder() 方法获取 CriteriaBuilder 对象,然后使用它来创建 CriteriaQuery 对象。使用 from() 方法获取实体类的根对象,并通过 criteriaBuilder 构建查询条件。最后,通过 session 的 createQuery() 方法执行查询并获取结果。
13. cascade 属性和 inverse 属性的作用和区别?
在 Hibernate 中,cascade 属性和 inverse 属性用于管理关系实体之间的级联操作和维护关系的所有者。它们的作用和区别如下:
-
cascade属性:- 作用:
cascade属性定义了当一个实体对象发生操作时,是否要级联操作关联的其他实体对象。 - 使用场景:当两个实体之间存在关联关系,例如一对多或多对多关系,通过设置
cascade属性可以自动同步关系的操作,减少手动处理的代码量。 - 示例:
@Entity public class Department { @Id private Long id; @OneToMany(mappedBy = "department", cascade = CascadeType.ALL) private List<Employee> employees; // 省略其他属性和方法 } @Entity public class Employee { @Id private Long id; @ManyToOne @JoinColumn(name = "department_id") private Department department; // 省略其他属性和方法 }在上面的例子中,当我们保存一个 Department 对象时,如果设置了
cascade = CascadeType.ALL,那么它关联的 Employee 对象也会被级联保存。这意味着,不需要手动保存关联的 Employee 对象,Hibernate 会自动处理。 - 作用:
-
inverse属性:- 作用:
inverse属性定义了在关系的另一侧是否要维护这个关系的所有者。通常,一端是关系的拥有者(owner)负责维护关系,而另一端被标记为inverse = true则代表不维护关系。 - 使用场景:当在一对多或多对多关系中,如果一方被标记为
inverse = true,那么它不会被用于维护关系,这意味着它的操作(例如添加、更新和删除)不会影响关系维护。 - 示例:
@Entity public class Department { @Id private Long id; @OneToMany(mappedBy = "department", cascade = CascadeType.ALL, orphanRemoval = true) private List<Employee> employees; // 省略其他属性和方法 } @Entity public class Employee { @Id private Long id; @ManyToOne @JoinColumn(name = "department_id") private Department department; // 省略其他属性和方法 } - 作用:
在上面的例子中,Department 实体拥有一个 employees 集合来存储关联的 Employee 实体。在 Department 实体上,标记了 cascade = CascadeType.ALL 和 orphanRemoval = true,这意味着当从 employees 集合中移除或替换 Employee 实体时,它会自动被删除。而在 Employee 实体上,通过 @ManyToOne 注解来指定部门,但没有设置 cascade 或 inverse 属性,因此它不负责维护关系。
综上所述,cascade 属性用于定义关系实体之间的级联操作,而 inverse 属性用于决定关系的另一侧是否要维护关系。根据具体的业务需求,您可以适用不同的属性来管理关系。
为了更好地解释 cascade 属性和 inverse 属性的区别,我在下面的表格中进行了一些总结:
| 属性 | 作用 | 使用场景 |
|---|---|---|
cascade |
定义了当一个实体对象发生操作时,是否要级联操作关联的其他实体对象。 | 在一对多或多对多关系中,通过设置 cascade 属性可以自动同步关系的操作,减少手动处理的代码量。 |
inverse |
定义了在关系的另一侧是否要维护这个关系的所有者。 | 在一对多或多对多关系中,如果一方被标记为 inverse = true,那么它不会被用于维护关系,这意味着它的操作(例如添加、更新和删除)不会影响关系维护。 |
总体来看,cascade 属性和 inverse 属性都涉及到了关系的维护。cascade 属性更关注于级联操作,即当一方实体对象被操作时,是否要自动操作关联的另一方实体对象。而 inverse 属性更关注于关系的所有权,即哪一方实体对象拥有关系,哪一方实体对象需要负责维护关联关系。
需要注意的是,cascade 属性和 inverse 属性的使用场景可以有重叠,也可以不一致。启用 cascade 属性并不意味着要使用 inverse 属性。相反,您可能会选择在一端使用 cascade 属性,在另一端使用 inverse 属性,这取决于您的业务逻辑和数据模型的设计。
希望这个表格可以帮助您更好地理解 cascade 属性和 inverse 属性的区别和使用场景。
14. Hibernate 中 get( )与 load( )区别?
在 Hibernate 中,get() 和 load() 都是用于根据主键获取实体对象的方法,但它们有以下的区别:
-
返回类型:
get()方法会立即查询数据库并返回完整的实体对象,而load()方法则是返回一个代理对象(proxy)。该代理对象只有在真正使用时,才会触发数据库查询。 -
延迟加载:
get()方法不支持延迟加载,它会立即从数据库中取得完整的实体对象。而load()方法支持延迟加载,只有在真正使用实体对象的属性时,才会触发数据库查询。
以下是一个例子来说明它们的区别:
// 假设有一个名为 "User" 的实体类,具有以下属性和主键
public class User {
private Long id;
private String name;
// ...
}
// 使用 get() 方法
User user1 = (User) session.get(User.class, 1L);
System.out.println(user1.getName()); // 立即从数据库中获取完整的实体对象
// 使用 load() 方法
User user2 = (User) session.load(User.class, 1L);
System.out.println(user2.getName()); // 延迟加载,只返回一个代理对象
在上面的例子中,使用 get() 方法获取的 user1 对象会立即从数据库中查询完整的实体对象,所以可以直接访问它的属性。而使用 load() 方法获取的 user2 对象只是返回一个代理对象,当访问代理对象的属性时,才会触发实际的数据库查询。
需要注意的是,如果使用 load() 方法获取的对象对应的数据在数据库中不存在,则在访问任何属性时会抛出 ObjectNotFoundException 异常。而使用 get() 方法不存在这种情况,因为它会返回 null。
总结起来,get() 方法是立即查询完整实体对象的方法,适合在需要立即使用完整对象的情况下使用。load() 方法是返回一个代理对象的方法,适合在惰性加载或需要延迟加载的情况下使用。
15. Hibernate 支持两种查询方式?
Hibernate 支持两种查询方式:HQL(Hibernate Query Language) 和 QBC(Criteria Query)。
HQL 是面向对象的查询语言,类似于 SQL,但使用的是实体类和属性名,而不是表名和列名。它是一种类型安全的查询语言,能够在保证代码易读性的情况下完成复杂的单表和多表查询。以下是一个简单的 HQL 查询示例:
String hql = "from User u where u.age > ? and u.gender = ?";
List<User> userList = session.createQuery(hql)
.setParameter(0, 18)
.setParameter(1, "Male")
.list();
在上面的代码中,使用 HQL 查询了所有年龄大于 18 岁且性别为男性的用户,并使用 list() 方法返回查询结果。
QBC(Criteria Query)是一种面向对象的查询 API,它不需要编写 HQL 或 SQL 语句,而是直接在代码中使用过滤器来定义查询条件和排序规则。以下是一个简单的 QBC 查询示例:
Criteria criteria = session.createCriteria(User.class);
criteria.add(Restrictions.gt("age", 18));
criteria.add(Restrictions.eq("gender", "Male"));
List<User> userList = criteria.list();
在上面的代码中,使用 QBC 查询了所有年龄大于 18 岁且性别为男性的用户,并使用 list() 方法返回查询结果。
需要注意的是,HQL 与 QBC 之间的性能差异并不明显,使用哪种查询方式取决于项目的具体情况和代码风格。在某些情况下,可能更喜欢使用 HQL,因为更接近 SQL 的语法可以更轻松地进行复杂查询。在其他情况下,使用 QBC 可能会更适合,因为它可以直接使用面向对象的过滤器定义查询条件和排序规则,使代码更易读和维护。
