bottom-up-attention-vqa-master 成功复现!!!
代码地址
1、create_dictionary.py
建立词典和使用预训练的glove向量
(1)create_dictionary()
- 遍历每个question文件
- 取出所关注的question部分,qs

- 遍历qs,对每个问题的文本内容进行分词,并将分词结果添加到字典中,True表示添加新词而非索引
#创建词典
#词典用于将文本数据中的单词映射到唯一的整数标识符
def create_dictionary(dataroot):
dictionary = Dictionary()
questions = []
files = [
'v2_OpenEnded_mscoco_train2014_questions.json',
'v2_OpenEnded_mscoco_val2014_questions.json',
'v2_OpenEnded_mscoco_test2015_questions.json',
'v2_OpenEnded_mscoco_test-dev2015_questions.json'
]
#遍历files列表中的每个文件
for path in files:
#将根目录dataroot与当前文件名path连接起来,得到每个问题文件的完整路径
question_path = os.path.join(dataroot, path)
#打开当前问题文件,加载其中的JSON数据,然后选择其中的question键对应的值
qs = json.load(open(question_path))['questions']
#遍历qs
for q in qs:
#对每个问题的文本内容进行分词,并将分词结果添加到字典中,True表示将新词添加到词典中而非词的索引
dictionary.tokenize(q['question'], True)
return dictionary
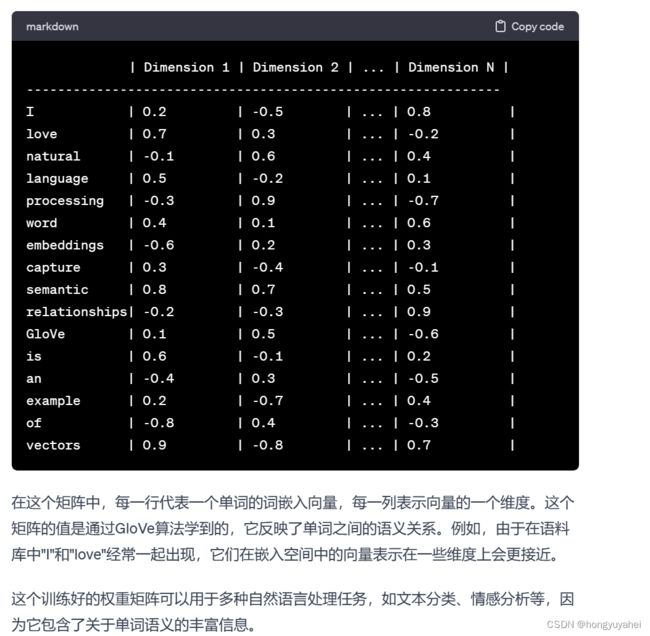
(2)create_glove_embedding_init()
从预训练Glove词嵌入文件(glove.6B.300d.txt)中创建一个初始化权重矩阵
- word2emb:存储从单词到词嵌入向量的映射
- 读取Glove文件中的所有行,每一行包含一个单词及其对应的嵌入向量entries
- 从第一行获取嵌入向量维度emb_dim
- 创建一个与词汇表大小相同的零矩阵,用于存储嵌入向量的权重weights
- 遍历Glove文件的每一行,entries->entry。获取当前单词word及嵌入向量的值(字符串->浮点数)。存储单词及其对应嵌入向量word2emb[word]
- 遍历词汇表中每个单词(在word2emb中的)将对应嵌入向量赋值给初始化的权重矩阵
- 返回weights、word2emb
#从预训练的Glove词嵌入文件中创建一个初始化权重矩阵
def create_glove_embedding_init(idx2word, glove_file):
word2emb = {} #用于存储从单词到嵌入向量的映射
with open(glove_file, 'r',encoding='utf-8') as f:
#读取Glove文件的所有行,每一行包含一个单词及其对应的嵌入向量
entries = f.readlines()
#从第一行获取嵌入向量的维度
emb_dim = len(entries[0].split(' ')) - 1
print('embedding dim is %d' % emb_dim)
#创建一个与词汇表大小相同的零矩阵,该矩阵用于存储嵌入向量的权重
weights = np.zeros((len(idx2word), emb_dim), dtype=np.float32)
#遍历Glove文件的每一行
for entry in entries:
vals = entry.split(' ')
word = vals[0]#获取当前行的单词
vals = list(map(float, vals[1:]))#获取嵌入向量的值,从字符串值转换为浮点数
word2emb[word] = np.array(vals)#将单词及其对应的嵌入向量存储在word2emb字典中
#enumerate组合为一个索引序列,同时返回索引和元素
#遍历词汇表中的每个单词
for idx, word in enumerate(idx2word):
#如果单词不在word2emb中,跳过
if word not in word2emb:
continue
#否则,将词汇表中每个单词的嵌入向量赋值给初始化的权重矩阵
weights[idx] = word2emb[word]
#返回初始化的权重矩阵和单词到嵌入向量的映射
return weights, word2emb


(3)main
- 创建词典,并保存到指定路径dump_to_file
- 加载词典对象(load_from_file),设置嵌入维度为300
- 获取初始化权重和单词到嵌入向量的映射(create_glove_embedding_init()),保存至glove6b_init_300d.npy
#创建词典
d = create_dictionary('D:/bottom-up-attention-vqa-master/data')
#将创建的词典对象保存到指定路径下
d.dump_to_file('D:/bottom-up-attention-vqa-master/data/dictionary.pkl')
#加载词典对象
d = Dictionary.load_from_file('D:/bottom-up-attention-vqa-master/data/dictionary.pkl')
emb_dim = 300 #设置嵌入维度为300
#'data/glove/glove.6B.300.txt'
glove_file = 'D:/bottom-up-attention-vqa-master/data/glove/glove.6B.%dd.txt' % emb_dim
#获取初始化权重矩阵和单词到嵌入向量的映射
weights, word2emb = create_glove_embedding_init(d.idx2word, glove_file)
#将初始化的权重矩阵保存到下列文件中
np.save('D:/bottom-up-attention-vqa-master/data/glove6b_init_%dd.npy' % emb_dim, weights)
2、compute_softscore.py
annotation部分的处理。
(1)main
- 打开并加载JSON数据中的annotation部分(训练集答案信息、验证集答案信息)、question部分(训练集问题信息、验证集问题信息)
- answers = train_answers + val_answers
- filter_answers() :对答案数据集进行预处理和筛选,返回occurence
- create_ans2label():创建答案到标签的映射ans2label,标签到答案的映射label2ans,并保存为2个文件,返回答案到标签的映射ans2label
- compute_target():为数据集中的答案计算目标标签并保存,用于训练和评估模型
if __name__ == '__main__':
train_answer_file = 'D:/bottom-up-attention-vqa-master/data/v2_mscoco_train2014_annotations.json'
#打开并加载JSON数据中的annotations部分,其中包含训练集的答案信息
train_answers = json.load(open(train_answer_file))['annotations']
val_answer_file = 'D:/bottom-up-attention-vqa-master/data/v2_mscoco_val2014_annotations.json'
#验证集的答案信息
val_answers = json.load(open(val_answer_file))['annotations']
#训练集的问题信息
train_question_file = 'D:/bottom-up-attention-vqa-master/data/v2_OpenEnded_mscoco_train2014_questions.json'
train_questions = json.load(open(train_question_file))['questions']
#验证集的问题信息
val_question_file = 'D:/bottom-up-attention-vqa-master/data/v2_OpenEnded_mscoco_val2014_questions.json'
val_questions = json.load(open(val_question_file))['questions']
answers = train_answers + val_answers
#对答案数据集进行预处理及筛选,并返回一个字典occurence
occurence = filter_answers(answers, 9)
# 创建答案到标签的映射、标签到答案的映射,并保存为两个文件,返回答案到标签的映射
ans2label = create_ans2label(occurence, 'trainval')
compute_target(train_answers, ans2label, 'train')
compute_target(val_answers, ans2label, 'val')
(2)filter_answers(answers_dest,min_occurence)
- occurence 字典,键:预处理过的答案,值:包含该答案的问题ID的set集合
- 遍历answers_dest中的每个答案 ans_entry

answers = ans_entry[‘answer’]
最常见的基准真值gtruth = ans_entry['multiple_choice_answer]
preprocess_answer(gtruth):对gtruth进行预处理
若gtruth不在occurence中,第一次遇到这个答案,将gtruth作为字典的键,对应是一个空set集合
将当前问题id ans_entry[‘question_id’]添加到occurence字典的键的set集合中 - 遍历occurence字典的键(答案),移除出现次数小于min_occurence的答案及对应ID
- 打印经过筛选后的occurence的长度
- 返回occurence
#对答案数据集进行筛选,并返回一个字典occurence
def filter_answers(answers_dset, min_occurence):
"""This will change the answer to preprocessed version
"""
#字典,键:预处理过的答案preprocess_answer(),值:包含该答案的问题ID的set集合
occurence = {}
#遍历answers_dest中的每个答案
for ans_entry in answers_dset:
answers = ans_entry['answers']
gtruth = ans_entry['multiple_choice_answer']
gtruth = preprocess_answer(gtruth)#对答案进行预处理
#若gtrush不在occurence中,说明第一次遇到这个答案,将gtrush作为字典的键,对应的值是一个空的集合
if gtruth not in occurence:
occurence[gtruth] = set()
occurence[gtruth].add(ans_entry['question_id'])#将当前问题id添加到occurence中gtruth为键的值set集合当中
#遍历occurence字典的键(答案),移除出现次数小于min_occurence的答案及对应的问题ID
for answer in list(occurence.keys()):
if len(occurence[answer]) < min_occurence:
occurence.pop(answer)
#打印经过筛选后的occurence的长度
print('Num of answers that appear >= %d times: %d' % (
min_occurence, len(occurence)))
return occurence
a、preprocess_answer(answer)
对答案进行预处理
- process_digit_article(process_punctuation(answer))
- 移除答案中的逗号,返回answer
b、process_punctuation(inText)
处理输入文本中的标点符号
- 遍历punct中定义好的每个符号
- 若标点在inText的两侧或是千位分割符,删除该标点;否则,将标点替换成空格
- 去除文本中的句号
- 返回经过处理的文本
#处理输入文本中的标点符号
def process_punctuation(inText):
outText = inText
#遍历punct中定义好的每一个标点符号
for p in punct:
#若该标点在inText的两侧或inText匹配定义好的comma_strip,则删除该标点
if (p + ' ' in inText or ' ' + p in inText) \
or (re.search(comma_strip, inText) != None):
outText = outText.replace(p, '')
#否则,将标点替换为一个空格
else:
outText = outText.replace(p, ' ')
#使用period_strip去除文本中的句号
outText = period_strip.sub("", outText, re.UNICODE)
#返回经过处理的文本
return outText
c、process_digit_article(inText)
处理输入文本中的数字及冠词
- 将inText转换为小写并拆分成单词 tempText
- 遍历tempText中的每个单词
- 若word在manual_map中,将数字单词映射为相应数字,否则,保持不变
- 若word不是冠词,则添加到outText中,否则,跳过不处理
- 遍历outText并获取wordId及word。若单词为缩写词,则替换为规范化文本
- 将处理后的单词列表通过空格连成字符串
- 返回outText
def process_digit_article(inText):
outText = []#存储处理后的文本
tempText = inText.lower().split()#将inText转换为小写,并拆分成单词
#遍历tempText中的每个单词
for word in tempText:
#如果word在manual_map中,将其映射为相应的数字;否则,保持不变
word = manual_map.setdefault(word, word)
#若word不是冠词,则添加到outText列表中;否则,跳过不处理
if word not in articles:
outText.append(word)
else:
pass
#遍历outText并获取wordId及word
for wordId, word in enumerate(outText):
#如果单词为缩写词,则替换为规范化文本
if word in contractions:
outText[wordId] = contractions[word]
#将处理后的单词列表通过空格连接成一个字符串
outText = ' '.join(outText)
return outText
(3)create_ans2label(occurence,name,cache_root)
- ans2label:存储答案到标签的映射的字典,label2ans:存储标签到答案的列表。label=0 标签计数器
- 遍历occurence字典中每个答案
将ans添加到label2ans列表中
将ans映射到当前label,存储在ans2label字典中
标签计数器label递增 - 使用pickle序列化将ans2label、label2ans存储到对应文件中,返回ans2label
#创建答案到标签的映射,并保存为两个文件
def create_ans2label(occurence, name, cache_root='D:/bottom-up-attention-vqa-master/data/cache'):
"""Note that this will also create label2ans.pkl at the same time
occurence: dict {answer -> whatever}
name: prefix of the output file
cache_root: str
"""
ans2label = {}#存储答案到标签的映射
label2ans = []#存储标签到答案的映射
label = 0#初始化一个标签计数器
#遍历occurence字典中的每个答案
for answer in occurence:
label2ans.append(answer)#将答案添加到label2ans列表中
ans2label[answer] = label#将答案映射到当前标签,存储在ans2label字典中
label += 1#标签计数器递增
utils.create_dir(cache_root)#创建一个目录,确保存储文件的目录存在
cache_file = os.path.join(cache_root, name+'_ans2label.pkl')#构建存储映射的文件路径
pickle.dump(ans2label, open(cache_file, 'wb'))#使用pickle序列化将ans2label存储到对应文件中
cache_file = os.path.join(cache_root, name+'_label2ans.pkl')
pickle.dump(label2ans, open(cache_file, 'wb'))
#返回存储答案到标签的映射字典
return ans2label
(4)compute_target(answers_dest,ans2label,name,cache_root)
为数据集中的答案计算目标标签,并将计算得到的标签信息保存到文件中,标签信息用于训练和评估模型
-
taeget:空列表,存储目标标签
-
遍历answers_dest中每个答案ans_entry
answers = ans_entry[‘answers’]是一个包含10个元素的list
answer_count:字典,记录每个答案出现次数
遍历当前答案answers中的所有答案answer,获取具体答案answer_,将答案出现的次数记录在answer_count字典中
列表:标签labels 分数scores
遍历answer_count中的每个答案,若不在已创建的ans2label中,跳过当前答案;否则,将答案映射到标签,并添加到labels中,根据答案出现的次数计算分数score,将分数添加到scores列表中
将问题id、图像id、labels、scores组成一个字典并添加到target列表中 -
将target保存到文件当中,返回target
#出现次数越多的答案,分数越高
def get_score(occurences):
if occurences == 0:
return 0
elif occurences == 1:
return 0.3
elif occurences == 2:
return 0.6
elif occurences == 3:
return 0.9
else:
return 1
#为数据集中的答案计算目标标签,并将计算得到的标签信息保存到文件中,标签信息用于训练和评估模型
def compute_target(answers_dset, ans2label, name, cache_root='E:/bottom-up-attention-vqa-master/data/cache'):
"""Augment answers_dset with soft score as label
***answers_dset should be preprocessed***
Write result into a cache file 结果写入缓存文件
"""
target = []#创建一个空列表,用于存储计算得到的目标标签
#遍历answers_dest中的每个答案数据项ans_entry
for ans_entry in answers_dset:
answers = ans_entry['answers']
answer_count = {} #创建一个空字典,用于记录每个答案的出现次数
#遍历当前答案中的所有答案
for answer in answers:
answer_ = answer['answer']#获取answer的具体内容
#将答案出现的次数记录在answer_count字典中
answer_count[answer_] = answer_count.get(answer_, 0) + 1
#创建两个空列表,用于存储标签和对应的分数
labels = []
scores = []
#遍历answer_count中的每个答案
for answer in answer_count:
#如果答案不在已经创建的答案到标签的映射中,跳过当前答案
if answer not in ans2label:
continue
#否则,将答案映射到标签,并添加到labels列表中
labels.append(ans2label[answer])
score = get_score(answer_count[answer])#根据答案出现的次数计算一个分数
scores.append(score)#将分数添加到scores列表中
#将整个过程得到的信息(问题id、图像id、标签列表、分数列表)组成一个字典,并添加到target列表中
target.append({
'question_id': ans_entry['question_id'],
'image_id': ans_entry['image_id'],
'labels': labels,
'scores': scores
})
utils.create_dir(cache_root)
cache_file = os.path.join(cache_root, name+'_target.pkl')
pickle.dump(target, open(cache_file, 'wb'))
return target
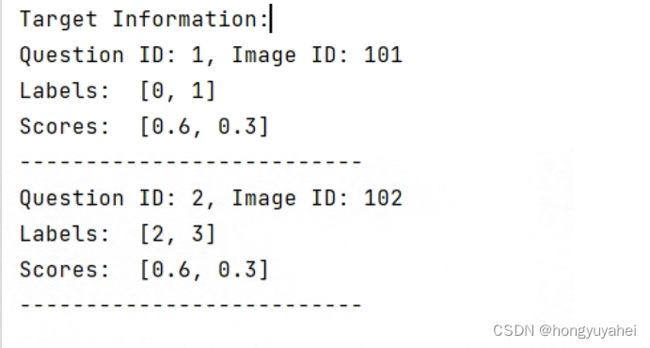
结合一段实际案例,理解上述这段代码:
# 定义答案数据集(answers_dset),答案到标签的映射(ans2label)
answers_dset = [
{'question_id': 1, 'image_id': 101, 'answers': [{'answer': 'yes'}, {'answer': 'yes'}, {'answer': 'no'}]},
{'question_id': 2, 'image_id': 102, 'answers': [{'answer': 'dog'}, {'answer': 'cat'}, {'answer': 'dog'}]},
# ... 其他答案数据项
]
ans2label = {'yes': 0, 'no': 1, 'dog': 2, 'cat': 3}
# 调用 compute_target 函数计算目标标签和分数
target = compute_target(answers_dset, ans2label, 'example')
# 打印结果
print("Target Information:")
for entry in target:
print(f"Question ID: {entry['question_id']}, Image ID: {entry['image_id']}")
print("Labels: ", entry['labels'])
print("Scores: ", entry['scores'])
print("--------------------------")
输入结果如下图所示:
3、detection_features_converter.py
- 创建2个HDF5文件对象h_train、h_val,以写入模式打开
- 从train_ids_file、val_ids_file文件(图像id数据),打开并加载其中保存的数据到train_imgids、val_imgids
- 字典 train_indices 、val_indices存储图像ID到特征索引的映射关系
- 创建训练集、验证集的图像特征、图像边框信息、空间特征信息的数据集
- train_counter、val_counter初始化为0
- 打开tsv文件进行读取
从tsv文件中读取每一行,并将其解析为字典FIELDNAMES
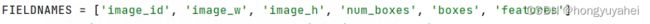
a、进行一些数据类型转换
b、bboxes:每行代表一个边界框,每列:左上角x坐标、左上角y坐标、右下角x坐标、右下角y坐标
box_width、box_height分别表示边界框宽、高度,归一化后为scaled_width、scaled_height
左上角坐标归一化后为scaled_x、scaled_y
c、将上述数据进行维度扩展,便于拼接
d、生成空间特征:归一化后的左上角x、y坐标 右下角x、y坐标、边界框宽度、高度
e、根据图像ID的归属(是否在训练集或验证集中),将处理后的数据存储到相应的HDF5中
以train_imgids为例
- 从train_imgids中移除当前的image_id
- 将image_id映射到train_counter,训练集当前图像索引train_indice
- train_img_bb的第train_counter行存储当前的边界框信息
- train_img_features存储图像特征信息
- train_spatial_img_features存储空间特征信息(这些信息存储在HDF5文件中)
- train_counter加一
最后,将图像ID到索引的映射关系保存成文件(train36_imgid2idx.pkl),即可以通过该文件确定图像ID对应的特征信息存储在HDF5文件的第train_counter行。
"""
读取一个预训练的bottom-up attention 特征的TSV文件,并将其存储为HDF5格式。
同时,将{图像ID:特征索引}映射存储为一个pickle文件
HDF5文件的层次结构如下:
{
'image_features':num_images * num_boxes *2048 的特征数组
'image_bb':num_images * num_boxes *4 的边界框数组
}
"""
FIELDNAMES = ['image_id', 'image_w', 'image_h', 'num_boxes', 'boxes', 'features']
infile = 'D:/bottom-up-attention-vqa-master/data/trainval_36/trainval_resnet101_faster_rcnn_genome_36.tsv'
train_data_file = 'D:/bottom-up-attention-vqa-master/data/train36.hdf5'
val_data_file = 'D:/bottom-up-attention-vqa-master/data/val36.hdf5'
train_indices_file = 'D:/bottom-up-attention-vqa-master/data/train36_imgid2idx.pkl'
val_indices_file = 'D:/bottom-up-attention-vqa-master/data/val36_imgid2idx.pkl'
train_ids_file = 'D:/bottom-up-attention-vqa-master/data/train_ids.pkl'
val_ids_file = 'D:/bottom-up-attention-vqa-master/data/val_ids.pkl'
feature_length = 2048
num_fixed_boxes = 36
if __name__ == '__main__':
#使用h5py库创建两个HDF5文件对象:h_train、h_val,并以写入模式打开这两个文件
h_train = h5py.File(train_data_file, "w")
h_val = h5py.File(val_data_file, "w")
#检查文件系统中是否存在train_ids_file和val_ids_file(此时已存在)
if os.path.exists(train_ids_file) and os.path.exists(val_ids_file):
#若存在,打开这两个文件并加载其中保存的数据到train_imgids、val_imgids
train_imgids = pickle.load(open(train_ids_file,'rb'))
val_imgids = pickle.load(open(val_ids_file,'rb'))
else:
#否则,从相应目录中加载图像ID数据,并保存到对应文件中
train_imgids = utils.load_imageid('data/train2014')
val_imgids = utils.load_imageid('data/val2014')
pickle.dump(train_imgids, open(train_ids_file, 'wb'))
pickle.dump(val_imgids, open(val_ids_file, 'wb'))
#创建两个空字典,用于存储图像ID到特征索引的映射关系
train_indices = {}
val_indices = {}
#训练集图像特征、图像边框信息、空间特征信息的数据集
train_img_features = h_train.create_dataset(
'image_features', (len(train_imgids), num_fixed_boxes, feature_length), 'f')
train_img_bb = h_train.create_dataset(
'image_bb', (len(train_imgids), num_fixed_boxes, 4), 'f')
train_spatial_img_features = h_train.create_dataset(
'spatial_features', (len(train_imgids), num_fixed_boxes, 6), 'f')
#验证集图像特征、图像边框信息、空间特征信息的数据集
val_img_bb = h_val.create_dataset(
'image_bb', (len(val_imgids), num_fixed_boxes, 4), 'f')
val_img_features = h_val.create_dataset(
'image_features', (len(val_imgids), num_fixed_boxes, feature_length), 'f')
val_spatial_img_features = h_val.create_dataset(
'spatial_features', (len(val_imgids), num_fixed_boxes, 6), 'f')
train_counter = 0
val_counter = 0
print("reading tsv...")
#打开tsv文件infile以进行读写
with open(infile, "r") as tsv_in_file:
#从tsv文件中读取每一行,并将其解析为一个字典,字段名由FIELDNAMES定义
reader = csv.DictReader(tsv_in_file, delimiter='\t', fieldnames=FIELDNAMES)
#对每一行数据进行处理
for item in reader:
#转换数据类型
item['num_boxes'] = int(item['num_boxes'])
image_id = int(item['image_id'])
image_w = float(item['image_w'])
image_h = float(item['image_h'])
#从tsv文件中读取包含边界框信息的base64编码字符串中解析出一个二维float32类型的numpy数组bboxes,
# 行数为item['num_boxes'],列数根据数据长度自动计算
bboxes = np.frombuffer(
base64.decodebytes(item['boxes'].encode()),
dtype=np.float32).reshape((item['num_boxes'], -1))
#boxes是一个二维数组,每行代表一个边界框,每列包含该边界框的不同属性
#列:左上角x坐标、左上角y坐标、右下角x坐标、右下角y坐标
#切片bboxes[:,2]表示选取所有行中的第3列数据,即右下角x坐标
box_width = bboxes[:, 2] - bboxes[:, 0]#边界框宽度
box_height = bboxes[:, 3] - bboxes[:, 1]#边界框高度
#宽度和高度的归一化
scaled_width = box_width / image_w
scaled_height = box_height / image_h
#左上角点的x和y坐标想对于图像宽度和高度的归一化值
scaled_x = bboxes[:, 0] / image_w
scaled_y = bboxes[:, 1] / image_h
#扩展维度,(n)的一维数组转换为形状为(n,1)的二维数组
box_width = box_width[..., np.newaxis]
box_height = box_height[..., np.newaxis]
scaled_width = scaled_width[..., np.newaxis]
scaled_height = scaled_height[..., np.newaxis]
scaled_x = scaled_x[..., np.newaxis]
scaled_y = scaled_y[..., np.newaxis]
#生成空间特征,将下列数组沿着第二个轴(列轴)进行拼接
#包含归一化的x坐标、y坐标、右下角x坐标、右下角y坐标、宽度和高度,皆为用于描述边界框的空间特征
spatial_features = np.concatenate(
(scaled_x,
scaled_y,
scaled_x + scaled_width,
scaled_y + scaled_height,
scaled_width,
scaled_height),
axis=1)
#根据图像ID的归属(是否在训练集或验证集中),将处理后的数据存储到相应的HDF5数据集中
if image_id in train_imgids:
train_imgids.remove(image_id)#从train_imgids中移除当前的image_id
train_indices[image_id] = train_counter#将image_id映射到train_counter,即训练集中当前图像的索引
train_img_bb[train_counter, :, :] = bboxes #将边界框信息存储到train_img_bb数据集的第train_counter行
train_img_features[train_counter, :, :] = np.frombuffer(
base64.decodebytes(item['features'].encode()),
dtype=np.float32).reshape((item['num_boxes'], -1))
train_spatial_img_features[train_counter, :, :] = spatial_features
train_counter += 1
elif image_id in val_imgids:
val_imgids.remove(image_id)
val_indices[image_id] = val_counter
val_img_bb[val_counter, :, :] = bboxes
val_img_features[val_counter, :, :] = np.frombuffer(
base64.decodebytes(item['features'].encode()),
dtype=np.float32).reshape((item['num_boxes'], -1))
val_spatial_img_features[val_counter, :, :] = spatial_features
val_counter += 1
else:
assert False, 'Unknown image id: %d' % image_id
if len(train_imgids) != 0:
print('Warning: train_image_ids is not empty')
if len(val_imgids) != 0:
print('Warning: val_image_ids is not empty')
#将图像ID到索引的额映射关系保存到文件系统中
pickle.dump(train_indices, open(train_indices_file, 'wb'))
pickle.dump(val_indices, open(val_indices_file, 'wb'))
h_train.close()
h_val.close()
print("done!")
4、main.py
- parse_args()解析命令行参数:epochs、num_hid、model、output、batch_size、seed
- 设置pytorch的随机种子,生成随机数、pytorch在cuda设备上的随机种子,启动cudnn库的benchmark模式,根据输入数据的大小、硬件性能等自动选择最优算法提高速度
- 加载词典 dictionary
- 构造VQAFeatureDataset并初始化train_dest、eval_deat
- 使用给定数据集和隐藏层维度获取并实例化模型对象(base_model->build_baseline0_newatt)
- 加载预训练词嵌入权重,初始化文本嵌入器w_emb
- 数据并行处理,GPU加速
- 创建用于训练、评估的数据加载器
- 开始训练
#解析命令行参数
def parse_args():
parser = argparse.ArgumentParser()#创建命令行参数
#添加命令行参数的定义
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--num_hid', type=int, default=1024)
parser.add_argument('--model', type=str, default='baseline0_newatt')
parser.add_argument('--output', type=str, default='D:/bottom-up-attention-vqa-master/saved_models/exp0')
parser.add_argument('--batch_size', type=int, default=512)
parser.add_argument('--seed', type=int, default=1111, help='random seed')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
#设置pytorch的随机种子,用于生成随机数
torch.manual_seed(args.seed)
#设置pytorch在cuda设备上的随机种子
torch.cuda.manual_seed(args.seed)
#启动cudnn库的benchmark模式,会根据输入数据的大小和硬件性能自动选择最优的算法来提高速度,以加速深度学习计算
torch.backends.cudnn.benchmark = True
#从文件中加载词典
dictionary = Dictionary.load_from_file('D:/bottom-up-attention-vqa-master/data/dictionary.pkl')
#构造VQAFeatureDataset对象并初始化
train_dset = VQAFeatureDataset('train', dictionary)
eval_dset = VQAFeatureDataset('val', dictionary)
batch_size = args.batch_size
constructor = 'build_%s' % args.model
#动态获取类并实例化得到的模型对象,使用给定的数据集和隐藏层维度
model = getattr(base_model, constructor)(train_dset, args.num_hid).cuda()
model.w_emb.init_embedding('D:/bottom-up-attention-vqa-master/data/glove6b_init_300d.npy')
model = nn.DataParallel(model).cuda()
train_loader = DataLoader(train_dset, batch_size, shuffle=True, num_workers=0)
eval_loader = DataLoader(eval_dset, batch_size, shuffle=True, num_workers=0)
train(model, train_loader, eval_loader, args.epochs, args.output)
5、dataset.py
(1)Dictionary
- 构造函数 word2idx:将词映射到索引(字典);idx2word:将索引映射回词(列表)
- ntoken()返回词典中词的数量
- padding_idx()返回词典中词的数量,用作特殊标记的索引,表示填充索引从该位置开始
- tokenize() 将句子分词
小写
去除。?将’'s’替换为‘ ‘s’,便于更好分离
使用空格分割句子,得到单词列表 sentence ->words
tokens 空列表,存储分词
根据add_word,True则将新词添加到词典中;False将返回词的索引 - dump_to_file()将包含word2idx和idx2word的列表保存到文件中,dictionary.pkl
- load_from_file()从文件中加载词典
- add_word()将新单词添加到idx2word、word2idx
class Dictionary(object):
#类的构造函数,用于初始化词典
def __init__(self, word2idx=None, idx2word=None):
#word2idx:将词映射到索引的字典
#idx2word:将索引映射回词的列表
#如果没有提供这些参数,默认是空字典和空列表
if word2idx is None:
word2idx = {}
if idx2word is None:
idx2word = []
self.word2idx = word2idx
self.idx2word = idx2word
@property
#返回词典中词的数量
def ntoken(self):
return len(self.word2idx)
@property
#返回词典中特殊标记(padding标记)的索引
#返回词典中词的数量,用作特殊标记的索引,表示新词的索引将从该位置开始
def padding_idx(self):
return len(self.word2idx)
#将句子分词
def tokenize(self, sentence, add_word):
sentence = sentence.lower()#将句子转换为小写
#去除逗号、问号、将'\'s'替换为' \'s',以便更好地分割's与其他单词
sentence = sentence.replace(',', '').replace('?', '').replace('\'s', ' \'s')
words = sentence.split()#使用空格分割句子,得到一个单词的列表
tokens = [] #空列表,存储分词
#根据add_word选择将新词添加到词典中,还是返回词的索引
if add_word:
for w in words:
tokens.append(self.add_word(w))
else:
for w in words:
tokens.append(self.word2idx[w])
return tokens
#将包含word2idx和idx2word的列表保存到文件中
def dump_to_file(self, path):
pickle.dump([self.word2idx, self.idx2word], open(path, 'wb'))
print('dictionary dumped to %s' % path)
@classmethod
#从文件中加载词典
def load_from_file(cls, path):
print('loading dictionary from %s' % path)
word2idx, idx2word = pickle.load(open(path, 'rb'))
#创建新的词典示例,并使用加载的映射关系进行初始化
d = cls(word2idx, idx2word)#cls,特殊变量表示当前的类
return d#返回新创建的词典实例
#将新单词添加到idx2word、word2idx中
def add_word(self, word):
if word not in self.word2idx:
self.idx2word.append(word)
self.word2idx[word] = len(self.idx2word) - 1
return self.word2idx[word]
def __len__(self):
return len(self.idx2word)
(2)VQAFeatureDataset
a、构造函数
- 初始化ans2label、label2ans、num_ans_candidates(答案候选数量)、dictionary、img_id2idx、features、spatials、v_dim、s_dim
- 调用load_dataset函数加载问题-答案的条目列表
- 调用**tokenize()**分词
- 调用**tensorize()**转换为tensor格式
#类的初始化方法
def __init__(self, name, dictionary, dataroot='D:/bottom-up-attention-vqa-master/data'):
#通过super()调用父类的构造函数
super(VQAFeatureDataset, self).__init__()
#断言,确保name的值在指定列表['train','val']中,若不在,将引发AssertionError异常
assert name in ['train', 'val']
#构建文件路径
ans2label_path = os.path.join(dataroot, 'cache', 'trainval_ans2label.pkl')
label2ans_path = os.path.join(dataroot, 'cache', 'trainval_label2ans.pkl')
#从文件中加载ans2label和label2ans的映射关系
self.ans2label = pickle.load(open(ans2label_path, 'rb'))
self.label2ans = pickle.load(open(label2ans_path, 'rb'))
self.num_ans_candidates = len(self.ans2label)#初始化答案候选数量,即答案到标签映射关系中的标签数量
self.dictionary = dictionary
#初始化img_id到idx的映射关系
self.img_id2idx = pickle.load(
open(os.path.join(dataroot, '%s36_imgid2idx.pkl' % name),'rb+'))
print('loading features from h5 file')
#构建HDF5文件路径
h5_path = os.path.join(dataroot, '%s36.hdf5' % name)
#使用h5py库打开HDF5文件并读取图像特征和空间特征
with h5py.File(h5_path, 'r') as hf:
self.features = np.array(hf.get('image_features'))
self.spatials = np.array(hf.get('spatial_features'))
#调用_load_dataset()函数加载问题-答案的条目列表
self.entries = _load_dataset(dataroot, name, self.img_id2idx)
self.tokenize()#分词
self.tensorize()#转换为tensor格式
#获取图像特征的维度和空间特征的维度
#索引2可以获取第三大维度的大小
self.v_dim = self.features.size(2)#2048
self.s_dim = self.spatials.size(2)#6
b、load_dataset()
加载数据集中的问题和答案信息,并生成一个包含特定字段的条目列表
- 加载问题JSON数据,并按照question_id排序questions
- 加载目标标签target,并按question_id排序answers
- 检查问题-答案数量是否相等
- entries :条目列表
- 遍历questions、answers,构建条目列表create_entry()
#加载数据集中的问题和答案信息,并生成一个包含特定字段的条目列表
def _load_dataset(dataroot, name, img_id2val):
"""
加载条目
img_id2val:字典{img_id ->val} val可用于检索图像或特征
dataroot: 数据集的根路径
name: ’train','val'
"""
#构建问题文件路径
question_path = os.path.join(
dataroot, 'v2_OpenEnded_mscoco_%s2014_questions.json' % name)
#加载问题JSON数据并按照question_id进行排序
questions = sorted(json.load(open(question_path))['questions'],
key=lambda x: x['question_id'])
#构建目标标签文件路径
answer_path = os.path.join(dataroot, 'cache', '%s_target.pkl' % name)
#加载目标标签并按照question_id进行排序
answers = pickle.load(open(answer_path, 'rb'))
answers = sorted(answers, key=lambda x: x['question_id'])
#检查问题和答案的数量是否相等
utils.assert_eq(len(questions), len(answers))
#创建一个空的条目列表
entries = []
#遍历问题和答案,构建条目列表
for question, answer in zip(questions, answers):
#检查问题和答案的标识符是否匹配
utils.assert_eq(question['question_id'], answer['question_id'])
utils.assert_eq(question['image_id'], answer['image_id'])
img_id = question['image_id']#获取img_id
#使用_create_entry函数创建一个条目,并添加到条目列表中
entries.append(_create_entry(img_id2val[img_id], question, answer))
return entries
- 构建条目列表,其中answer字段是target去除question_id、image_id,即包含labels、scores
#创建包含特定字段的字典entry,用于表示一个问题-回答对应的条目
def _create_entry(img, question, answer):
#移除answer字典中image_id和question_id字段
answer.pop('image_id')
answer.pop('question_id')
entry = {
'question_id' : question['question_id'],
'image_id' : question['image_id'],
'image' : img,
'question' : question['question'],
'answer' : answer}
return entry
c、tokenize()
#分词
def tokenize(self, max_length=14):
"""Tokenizes the questions.
This will add q_token in each entry of the dataset.
-1 represent nil, and should be treated as padding_idx in embedding
"""
for entry in self.entries:
#将问题进程分词,不添加新词汇到词典中,返回词的索引
tokens = self.dictionary.tokenize(entry['question'], False)
#根据指定最大长度max_length截断或填充分词列表
tokens = tokens[:max_length]
if len(tokens) < max_length:
# Note here we pad in front of the sentence
padding = [self.dictionary.padding_idx] * (max_length - len(tokens))
tokens = padding + tokens
utils.assert_eq(len(tokens), max_length)
entry['q_token'] = tokens
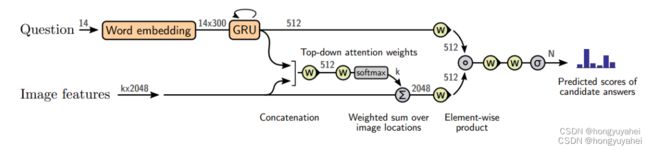
6、base_model.py
#基础模型
class BaseModel(nn.Module):
'''
构造函数,初始化,接收6个参数:
w_emb:文本嵌入器
q_emb:问题嵌入器
v_att:视觉注意力模块
q_net:问题网络
v_net:视觉网络
classifier:分类器
'''
def __init__(self, w_emb, q_emb, v_att, q_net, v_net, classifier):
super(BaseModel, self).__init__()
self.w_emb = w_emb
self.q_emb = q_emb
self.v_att = v_att
self.q_net = q_net
self.v_net = v_net
self.classifier = classifier
def forward(self, v, b, q, labels):
"""Forward
v: [batch, num_objs, obj_dim]视觉特征
b: [batch, num_objs, b_dim]边界框特征
q: [batch_size, seq_length]问题特征
return: logits, not probs
"""
q = torch.tensor(q).to(torch.int64)
w_emb = self.w_emb(q)#将问题特征q转换为文本嵌入
q_emb = self.q_emb(w_emb) # [batch, q_dim]通过问题嵌入去将文本嵌入转换为问题嵌入
att = self.v_att(v, q_emb)#计算视觉特征v关于问题嵌入q_emb的注意力权重att
#将注意力权重与视觉特征逐元素相乘,每个对象的加权视觉特征进行求和,得到视觉嵌入
v_emb = (att * v).sum(1) # [batch, v_dim]
q_repr = self.q_net(q_emb)#使用问题网络对问题嵌入转换为问题表示
v_repr = self.v_net(v_emb)
joint_repr = q_repr * v_repr#对问题表示和视觉表示逐元素相乘,得到联合表示
logits = self.classifier(joint_repr)
return logits
def build_baseline0(dataset, num_hid):
w_emb = WordEmbedding(dataset.dictionary.ntoken, 300, 0.0)
q_emb = QuestionEmbedding(300, num_hid, 1, False, 0.0)
v_att = Attention(dataset.v_dim, q_emb.num_hid, num_hid)
q_net = FCNet([num_hid, num_hid])
v_net = FCNet([dataset.v_dim, num_hid])
classifier = SimpleClassifier(
num_hid, 2 * num_hid, dataset.num_ans_candidates, 0.5)
return BaseModel(w_emb, q_emb, v_att, q_net, v_net, classifier)
#基准模型
def build_baseline0_newatt(dataset, num_hid):
#词嵌入层初始化,将单词映射到300维的嵌入空间
w_emb = WordEmbedding(dataset.dictionary.ntoken, 300, 0.0)
#问题嵌入层初始化
q_emb = QuestionEmbedding(300, num_hid, 1, False, 0.0)
#注意力机制初始化
v_att = NewAttention(dataset.v_dim, q_emb.num_hid, num_hid)
#问题网络初始化,将问题特征映射到num_hid维隐藏空间
q_net = FCNet([q_emb.num_hid, num_hid])
# 视觉网络初始化,将视觉特征映射到num_hid维隐藏空间
v_net = FCNet([dataset.v_dim, num_hid])
#分类器初始化
classifier = SimpleClassifier(
num_hid, num_hid * 2, dataset.num_ans_candidates, 0.5)
return BaseModel(w_emb, q_emb, v_att, q_net, v_net, classifier)
7、language_model.py
#词嵌入层,WoedEmbedding类,继承自nn.Module
class WordEmbedding(nn.Module):
"""Word Embedding
The ntoken-th dim is used for padding_idx, which agrees *implicitly*
with the definition in Dictionary.
词嵌入
第ntoken维度用于填充索引(padding_idx),这与字典(Dictionary)中的定义隐含一致
"""
#构造函数:ntoken:词汇表大小、emb_dim:词嵌入维度、dropout:dropout层的概率
def __init__(self, ntoken, emb_dim, dropout):
super(WordEmbedding, self).__init__()#调用父类nn.Module的构造函数
#创建Embedding层,将输入整数序列转换为词嵌入表示
#标记为padding_idx的位置被视为填充标记
self.emb = nn.Embedding(ntoken+1, emb_dim, padding_idx=ntoken)
#创建dropout层,用于在训练过程中随机丢弃部分神经元,以防止过拟合
self.dropout = nn.Dropout(dropout)
self.ntoken = ntoken#将输入词汇表的大小存储为类的属性
self.emb_dim = emb_dim#将输入的词嵌入维度存储为类的属性
#初始化词嵌入层的权重
def init_embedding(self, np_file):
#从numpy文件加载预训练的词嵌入权重,并将其转换为pytorch张量
weight_init = torch.from_numpy(np.load(np_file))
#断言确保加载的权重与词汇表大小和词嵌入维度匹配
assert weight_init.shape == (self.ntoken, self.emb_dim)
#将加载的权重赋值给词嵌入层的权重,只覆盖词汇表大小范围内的部分
#data[:self.notoken]:切片操作,取列表data的前self.ntoken个元素
self.emb.weight.data[:self.ntoken] = weight_init
#定义前向传播方法,接收输入x并返回词嵌入表示
def forward(self, x):
#x = torch.tensor(x).to(torch.int64)
emb = self.emb(x)#将输入x传递给词嵌入层,获取词嵌入表示
emb = self.dropout(emb)#对词嵌入表示应用dropout操作,随机丢弃部分神经元
return emb
#QuestionEmbedding类,继续自nn.Module
#将输入的问题序列进行嵌入,可以选择性地返回整个序列或仅仅返回最后一个时间步的嵌入,捕捉序列信息
class QuestionEmbedding(nn.Module):
#构造函数,初始化
'''
接收系列参数如下:
in_dim:输入维度
num_hid:隐藏单元数量
nlayers:层数
bidirect:是否双向
dropout:Dropout层的概率
rnn_type:RNN类型,默认为GRU
'''
def __init__(self, in_dim, num_hid, nlayers, bidirect, dropout, rnn_type='GRU'):
"""Module for question embedding
"""
super(QuestionEmbedding, self).__init__()#调用父类构造函数
#断言确保RNN类型为LSTM或GRU,避免输入错误的RNN类型
assert rnn_type == 'LSTM' or rnn_type == 'GRU'
rnn_cls = nn.LSTM if rnn_type == 'LSTM' else nn.GRU#根据指定的RNN类型选择相应的Pytorch RNN类
#创建RNN层,根据构造函数中的参数配置
#batch_first=True表示输入的第一个维度是批次大小
self.rnn = rnn_cls(
in_dim, num_hid, nlayers,
bidirectional=bidirect,
dropout=dropout,
batch_first=True)
self.in_dim = in_dim
self.num_hid = num_hid
self.nlayers = nlayers
self.rnn_type = rnn_type
self.ndirections = 1 + int(bidirect)#是否双方设置方向的数量
#初始化RNN的隐藏状态,接收一个参数batch表示批次大小
def init_hidden(self, batch):
# just to get the type of tensor
#self.parameters()返回模型中所有参数的迭代器
#next()获取这个迭代器的下一个元素,即模型的第一个参数
#.data属性用于访问参数的底层数据,即包含实际权重值的张量
#weight = next(self.parameters()).data#获取模型的第一个参数(权重)并访问其底层数据(tensor),返回模型参数的数据部分
weight = 0
weight = torch.tensor(weight,dtype=torch.float32)
weight = weight.cuda()
#计算RNN中隐藏状态的形状
#三元组:(层数*方向数,批次大小,隐藏单元数量)
hid_shape = (self.nlayers * self.ndirections, batch, self.num_hid)
if self.rnn_type == 'LSTM':
#若是LSTM模型,返回包含LSTM的隐藏状态和细胞状态,零初始化
#Variable:包装张量
#weight.new(*hid_shape):使用模型参数(权重),通过new创建与模型参数相同类型和设备的新张量,形状为hid_shape,_zero()表示将所有元素都设置为零
return (Variable(weight.new(*hid_shape).zero_()),
Variable(weight.new(*hid_shape).zero_()))
else:
#GRU模型,返回GRU的隐藏状态
return Variable(weight.new(*hid_shape).zero_())
#前向传播
def forward(self, x):
# x: [batch, sequence, in_dim]
batch = x.size(0)#获取输入的批次大小
hidden = self.init_hidden(batch)#初始化RNN的隐藏状态
self.rnn.flatten_parameters()#将参数展平
#将输入序列x和隐藏状态传递给RNN,获取输出和更新后的隐藏状态
output, hidden = self.rnn(x, hidden)
#单向RNN,返回最后一个时间步的输出
if self.ndirections == 1:
return output[:, -1]
#双向RNN
forward_ = output[:, -1, :self.num_hid]#获取最后一个时间步的前向部分的输出
backward = output[:, 0, self.num_hid:]#获取第一个时间步的后向部分的输出
return torch.cat((forward_, backward), dim=1)#将前向和后向的输出在维度1上进行连接,并返回结果
#返回所有时间步的输出
def forward_all(self, x):
# x: [batch, sequence, in_dim]
batch = x.size(0)
hidden = self.init_hidden(batch)
self.rnn.flatten_parameters()
output, hidden = self.rnn(x, hidden)
return output
8、attention.py
#注意力机制
class Attention(nn.Module):
'''
构造函数,初始化,接收以下三个参数:
v_dim:视觉特征维度
q_dim:问题特征维度
num_hid:隐藏层维度
'''
def __init__(self, v_dim, q_dim, num_hid):
super(Attention, self).__init__()#调用父类nn.Module的构造函数
#创建全连接网络FCNet,用于处理拼接视觉特征和问题特征的输入
self.nonlinear = FCNet([v_dim + q_dim, num_hid])#指定输入和输出的维度
#创建一个带有权重标准化的线性层,用于将处理后的输入映射为注意力权重
#nn.Linear(num_hid,1)指定输入和输出的维度
#dim=None表示对所有权重进行标准化
self.linear = weight_norm(nn.Linear(num_hid, 1), dim=None)
#前向传播方法:接收视觉特征v和问题特征q,并返回注意力权重
def forward(self, v, q):
"""
v: [batch, k, vdim]
q: [batch, qdim]
"""
logits = self.logits(v, q)#调用logits方法计算未经softmax处理的注意力得分
w = nn.functional.softmax(logits, 1)#对得分进行归一化,得到最终的注意力权重
return w
#计算注意力得分
def logits(self, v, q):
num_objs = v.size(1)#获取视觉特征中对象的数量
#q.unsqueeze(1),在张量q的第一维上增加一个维度[batch,1,q_dim],便于与v进行拼接操作
#repeat(1,num_objs,1)对张量进行复制,变为[batch,num_objs,q_dim]
q = q.unsqueeze(1).repeat(1, num_objs, 1)
vq = torch.cat((v, q), 2)#在第3维上进行拼接,将视觉特征和问题特征合并在一起[batch,num_objs,q_dim+v_dim]
joint_repr = self.nonlinear(vq)#将拼接后的特征输入到全连接网络中进行处理,得到联合表示
logits = self.linear(joint_repr)#将联合表示输入到线性层中,得到注意力得分,未经softmax处理
return logits
#新的注意力机制
class NewAttention(nn.Module):
'''
构造函数,初始化,接收4个参数
v_dim:视觉特征维度
q_dim:问题特征维度
num_hid:隐藏层的维度
dropout:Dropout层的概率,默认为0.2
'''
def __init__(self, v_dim, q_dim, num_hid, dropout=0.2):
super(NewAttention, self).__init__()#调用父类nn.Module的构造函数
self.v_proj = FCNet([v_dim, num_hid])#全连接层处理视觉特征,投影到隐藏层的维度
self.q_proj = FCNet([q_dim, num_hid])#全连接层处理问题特征,投影到隐藏层的维度
self.dropout = nn.Dropout(dropout)#dropout层,在训练时随机丢失部分神经元,以防止过拟合
#创建一个带有权重标准化的线性层,用于将处理后的问题特征映射为注意力得分(标量)
self.linear = weight_norm(nn.Linear(q_dim, 1), dim=None)
def forward(self, v, q):
"""
v: [batch, k, vdim]
q: [batch, qdim]
"""
logits = self.logits(v, q) #计算注意力得分
w = nn.functional.softmax(logits, 1) #使用softmax函数将注意力得分转换为注意力权重,得到归一化的权重分布
return w #返回注意力权重
#计算注意力得分的函数,接受视觉特征v和问题特征q
def logits(self, v, q):
batch, k, _ = v.size()
v_proj = self.v_proj(v) # v_dim ->num_hid ->[batch,k,num_hid] #将视觉特征投影到隐藏层的维度
q_proj = self.q_proj(q).unsqueeze(1).repeat(1, k, 1) #q_dim -> num_dim ->[batch,k,num_hid],便于和视觉特征对齐
joint_repr = v_proj * q_proj #逐元素乘法,点乘
joint_repr = self.dropout(joint_repr)
logits = self.linear(joint_repr) #得注意力得分
return logits
8、fc.py
#非线性全连接网络FCNet,用于处理输入数据
class FCNet(nn.Module):
"""Simple class for non-linear fully connect network
"""
#构造函数,接受参数dims
def __init__(self, dims):
#调用父类构造函数
super(FCNet, self).__init__()
layers = []#创建一个空列表,用于存储网络的层
#遍历输入维度和输出维度列表,创建线性层和激活函数的序列
for i in range(len(dims)-2):
in_dim = dims[i]#获取当前层的输入维度
out_dim = dims[i+1]#获取当前层的输出维度
#添加带有权重归一化的线性层
layers.append(weight_norm(nn.Linear(in_dim, out_dim), dim=None))
#添加ReLU激活函数
layers.append(nn.ReLU(inplace=False))
#添加输出层的线性层,同样使用权重归一化
layers.append(weight_norm(nn.Linear(dims[-2], dims[-1]), dim=None))
layers.append(nn.ReLU(inplace=False))#添加输出层的ReLU激活函数
#将层序列封装成nn.Sequential对象并赋值给类的main属性,main序列中定义了整个网络的前向传播过程
self.main = nn.Sequential(*layers)
#定义前向传播函数,接收x并返回网络的输出
def forward(self, x):
#将输入x通过网络的前向传播得到输出
return self.main(x)
if __name__ == '__main__':
fc1 = FCNet([10, 20, 10])
print(fc1)
print('============')
fc2 = FCNet([10, 20])
print(fc2)

10、classifier.py
#简单分类器模型
class SimpleClassifier(nn.Module):
def __init__(self, in_dim, hid_dim, out_dim, dropout):
super(SimpleClassifier, self).__init__()
layers = [
weight_norm(nn.Linear(in_dim, hid_dim), dim=None),#线性层,全连接层,权重标准化
nn.ReLU(inplace=False),#ReLU激活函数
nn.Dropout(dropout, inplace=False),#inplace表示原地操作,修改原始输入张量
weight_norm(nn.Linear(hid_dim, out_dim), dim=None)
]
#创建一个序列容器,将之前定义的层按顺序组合起来形成整个模型
self.main = nn.Sequential(*layers)
def forward(self, x):
logits = self.main(x)
return logits
11、train.py
def instance_bce_with_logits(logits, labels):
#断言确保输入的logits张量是二维的
#若logits的维度是2,则程序继续执行;否则,触发AssertionError异常,中断程序执行
assert logits.dim() == 2
#计算二分类交叉熵损失
loss = nn.functional.binary_cross_entropy_with_logits(logits, labels)
loss = loss * labels.size(1)#将损失乘以真实标签的维度(通常是类别的数量),将损失值按照每个样本的平均损失进行缩放
return loss
#计算分类模型得分
def compute_score_with_logits(logits, labels):
#torch.max(logits,1)选择每行的最大值,返回的元组中的第一个元素是最大值,第二个元素的最大值对应的索引
#[1]取得索引,.data取得数据的张量部分
logits = torch.max(logits, 1)[1].data # argmax 找到预测的类别
#创建一个与labels大小相同的全零张量,移动到GPU(若可用),用于存储独热编码
one_hots = torch.zeros(*labels.size()).cuda()
#logits.view(-1,1)将logits张量变形为一个列向量,列数为1,-1表示自动推断该维度大小
#维度索引为1的指定位置赋值为1
#创建一个独热编码,只有预测类别对应的位置上的值为1,其他位置都为0
new_one_hots = torch.scatter(one_hots, 1, logits.view(-1, 1), 1)
scores = (new_one_hots * labels)#按元素相乘,只有对应正确类别的位置上的值保留,其他位置都是0
return scores
def train(model, train_loader, eval_loader, num_epochs, output):
utils.create_dir(output)#创建一个由output指定的目录
optim = torch.optim.Adamax(model.parameters())#创建Adamax优化器
logger = utils.Logger(os.path.join(output, 'log.txt'))#创建日志记录器对象
best_eval_score = 0 #模型在验证集上的某个性能的最佳值
#开始训练循环,循环次数为num_epochs
for epoch in range(num_epochs):
#初始化训练过程中的总损失和总分数
total_loss = 0
train_score = 0
t = time.time()#获取当前的时间戳
#遍历训练数据集中的每个batch
for i, (v, b, q, a) in enumerate(train_loader):
v = Variable(v).cuda()
b = Variable(b).cuda()
q = Variable(q).cuda()
a = Variable(a).cuda()
#v = v.float()
#q = q.float()
pred = model(v, b, q, a)#得到模型的预测
loss = instance_bce_with_logits(pred, a)#计算二分类交叉熵损失
loss.backward() # 反向传播,计算梯度
nn.utils.clip_grad_norm(model.parameters(), 0.25) # 对梯度进行裁剪,防止梯度爆炸,所有参数的梯度的L2范数,指定阈值0.25
optim.step() # 执行一步优化,更新模型参数
optim.zero_grad() # 清零梯度,为下一个batch的梯度计算做准备
batch_score = compute_score_with_logits(pred, a.data).sum()#计算当前batch的得分
#loss.data[0]获取当前batch损失值,v.size(0)获取当前batch样本数
total_loss = total_loss + loss.item() * v.size(0)
train_score = train_score + batch_score
total_loss = total_loss / len(train_loader.dataset)#整个训练集上的平均损失
train_score = 100 * train_score / len(train_loader.dataset)
model.train(False)#评估模式
eval_score, bound = evaluate(model, eval_loader)
model.train(True)#训练模式
#记录训练和评估过程中的一些信息,写入日志文件中
logger.write('epoch %d, time: %.2f' % (epoch, time.time()-t))
logger.write('\ttrain_loss: %.2f, score: %.2f' % (total_loss, train_score))
logger.write('\teval score: %.2f (%.2f)' % (100 * eval_score, 100 * bound))
#更新最佳得分并保存模型参数
if eval_score > best_eval_score:
model_path = os.path.join(output, 'model.pth')
torch.save(model.state_dict(), model_path)
best_eval_score = eval_score
def evaluate(model, dataloader):
score = 0 #评分
upper_bound = 0 #最大可能评分
num_data = 0 #处理的数据样本总数
#遍历数据加载器中的每个batch
for v, b, q, a in iter(dataloader):
#将v、b、q数据转换为pytorch变量并移动到GPU上
v = Variable(v, volatile=True).cuda()
b = Variable(b, volatile=True).cuda()
q = Variable(q, volatile=True).cuda()
pred = model(v, b, q, None)#使用模型进行预测,无需提供真实标签
batch_score = compute_score_with_logits(pred, a.cuda()).sum()#计算当前batch的得分
score = score + batch_score #累计分数
#a.max(1)计算第一维度上的最大值,返回元组包含两个张量,第一个是每个样本的最大值,第二个是每个最大值的索引
# [0].sum()表示对最大值进行求和
upper_bound = upper_bound + (a.max(1)[0]).sum() #累计最大可能评分
num_data = num_data + pred.size(0)#累计当前的样本数
score = score / len(dataloader.dataset) #平均值
upper_bound = upper_bound / len(dataloader.dataset) #最大可能得分平均值
return score, upper_bound
12、最终复现结果:
epoch 0, time: 269.13
train_loss: 9.98, score: 39.04
eval score: 50.29 (92.66)
epoch 1, time: 265.49
train_loss: 3.96, score: 52.18
eval score: 55.46 (92.66)
epoch 2, time: 267.10
train_loss: 3.61, score: 56.99
eval score: 58.44 (92.66)
epoch 3, time: 266.44
train_loss: 3.39, score: 60.05
eval score: 59.83 (92.66)
epoch 4, time: 256.31
train_loss: 3.24, score: 62.45
eval score: 60.87 (92.66)
epoch 5, time: 255.20
train_loss: 3.11, score: 64.41
eval score: 61.67 (92.66)
epoch 6, time: 254.13
train_loss: 3.00, score: 66.10
eval score: 62.00 (92.66)
epoch 7, time: 255.00
train_loss: 2.91, score: 67.69
eval score: 62.59 (92.66)
epoch 8, time: 254.41
train_loss: 2.82, score: 69.16
eval score: 62.96 (92.66)
epoch 9, time: 255.63
train_loss: 2.74, score: 70.57
eval score: 62.94 (92.66)
epoch 10, time: 254.48
train_loss: 2.67, score: 71.77
eval score: 63.12 (92.66)
epoch 11, time: 255.29
train_loss: 2.60, score: 73.00
eval score: 63.30 (92.66)
epoch 12, time: 256.36
train_loss: 2.54, score: 74.11
eval score: 63.26 (92.66)
epoch 13, time: 255.14
train_loss: 2.48, score: 75.12
eval score: 63.37 (92.66)
epoch 14, time: 255.62
train_loss: 2.42, score: 76.04
eval score: 63.38 (92.66)
epoch 15, time: 255.27
train_loss: 2.37, score: 76.91
eval score: 63.45 (92.66)
epoch 16, time: 255.21
train_loss: 2.32, score: 77.71
eval score: 63.40 (92.66)
epoch 17, time: 255.82
train_loss: 2.28, score: 78.40
eval score: 63.38 (92.66)
epoch 18, time: 255.40
train_loss: 2.24, score: 79.02
eval score: 63.34 (92.66)
epoch 19, time: 254.87
train_loss: 2.20, score: 79.57
eval score: 63.29 (92.66)
epoch 20, time: 255.41
train_loss: 2.16, score: 80.13
eval score: 63.23 (92.66)
epoch 21, time: 255.24
train_loss: 2.13, score: 80.62
eval score: 63.29 (92.66)
epoch 22, time: 255.93
train_loss: 2.09, score: 81.14
eval score: 63.19 (92.66)
epoch 23, time: 255.59
train_loss: 2.06, score: 81.58
eval score: 63.12 (92.66)
epoch 24, time: 254.89
train_loss: 2.03, score: 81.94
eval score: 63.28 (92.66)
epoch 25, time: 256.18
train_loss: 2.00, score: 82.31
eval score: 63.25 (92.66)
epoch 26, time: 256.01
train_loss: 1.98, score: 82.73
eval score: 63.20 (92.66)
epoch 27, time: 255.60
train_loss: 1.95, score: 83.09
eval score: 63.09 (92.66)
epoch 28, time: 255.98
train_loss: 1.93, score: 83.35
eval score: 63.19 (92.66)
epoch 29, time: 255.50
train_loss: 1.90, score: 83.69
eval score: 63.16 (92.66)