1、 调用模型库,定义参数,做数据预处理
import numpy as np
import torch
from torchvision.datasets import FashionMNIST
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc
import matplotlib.pyplot as plt
from torchvision import models
# 检查 GPU 可用性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
# 设置超参数
train_batch_size = 64
test_batch_size = 64
learning_rate = 0.001
num_epochs = 50
# 定义数据转换操作
transform = transforms.Compose([
transforms.RandomRotation(degrees=[-30, 30]), # 随机旋转
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.Resize((224, 224)), # 调整图像大小
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), # 颜色抖动
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,))
])
2、下载FashionMNIST训练集
# 下载FashionMNIST训练集
trainset = FashionMNIST(root='data', train=True,
download=True, transform=transform)
# 下载FashionMNIST测试集
testset = FashionMNIST(root='data', train=False,
download=True, transform=transform)
# 创建 DataLoader 对象
train_loader = DataLoader(trainset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(testset, batch_size=test_batch_size, shuffle=False)
3、使用预训练的ResNet-18模型
# 使用预训练的ResNet-18模型
model = models.resnet18(pretrained=True)
# 修改最后一层,使其适应FashionMNIST的输出类别数
model.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
model.fc = nn.Linear(model.fc.in_features, 10)
model = model.to(device)
# 冻结预训练模型的参数
for param in model.parameters():
param.requires_grad = False
# 只训练模型的最后一层
for param in model.fc.parameters():
param.requires_grad = True
# 初始化优化器和损失函数
optimizer = optim.Adam(model.fc.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
4、 训练循环
# 记录训练和测试过程中的损失和准确率
train_losses = []
test_losses = []
train_accuracies = []
test_accuracies = []
conf_matrix_list = []
accuracy_list = []
error_rate_list = []
precision_list = []
recall_list = []
f1_score_list = []
roc_auc_list = []
# 训练循环
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
data, target = data.to(device), target.to(device) # 将数据移到 GPU 上
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 计算训练准确率
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 计算平均训练损失和训练准确率
train_loss /= len(train_loader)
train_accuracy = 100. * correct / total
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
# 测试模型
model.eval()
test_loss = 0.0
correct = 0
all_labels = []
all_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device) # 将数据移到 GPU 上
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
all_labels.extend(target.cpu().numpy()) # 将结果移到 CPU 上
all_preds.extend(pred.cpu().numpy()) # 将结果移到 CPU 上
# 计算平均测试损失和测试准确率
test_loss /= len(test_loader)
test_accuracy = 100. * correct / len(test_loader.dataset)
test_losses.append(test_loss)
test_accuracies.append(test_accuracy)
# 计算额外的指标
conf_matrix = confusion_matrix(all_labels, all_preds)
conf_matrix_list.append(conf_matrix)
accuracy = accuracy_score(all_labels, all_preds)
accuracy_list.append(accuracy)
error_rate = 1 - accuracy
error_rate_list.append(error_rate)
precision = precision_score(all_labels, all_preds, average='weighted')
recall = recall_score(all_labels, all_preds, average='weighted')
f1 = f1_score(all_labels, all_preds, average='weighted')
precision_list.append(precision)
recall_list.append(recall)
f1_score_list.append(f1)
fpr, tpr, thresholds = roc_curve(all_labels, all_preds, pos_label=1)
roc_auc = auc(fpr, tpr)
roc_auc_list.append(roc_auc)
# 打印每个 epoch 的指标
print(f'Epoch [{epoch + 1}/{num_epochs}] -> Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}%, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.2f}%')
5、绘制Loss、Accuracy曲线图, 计算混淆矩阵
import seaborn as sns
# 绘制Loss曲线图
plt.figure()
plt.plot(train_losses, label='Train Loss', color='blue')
plt.plot(test_losses, label='Test Loss', color='red')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
plt.grid(True)
plt.show()
# 绘制Accuracy曲线图
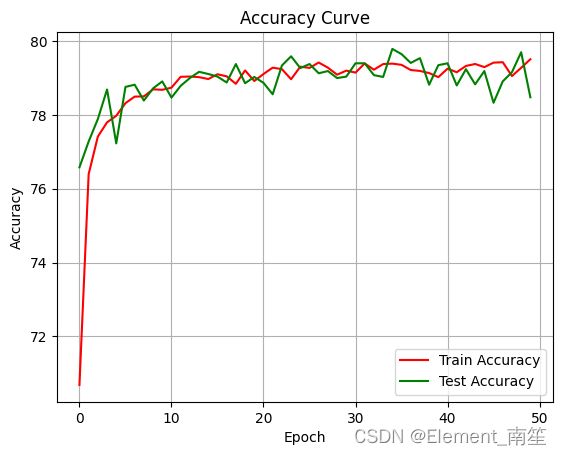
plt.figure()
plt.plot(train_accuracies, label='Train Accuracy', color='red') # 绘制训练准确率曲线
plt.plot(test_accuracies, label='Test Accuracy', color='green')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.grid(True)
plt.show()
# 计算混淆矩阵
confusion_mat = confusion_matrix(all_labels, all_preds)
class_labels = [str(i) for i in range(10)]
plt.figure()
sns.heatmap(confusion_mat, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.savefig('confusion_matrix.png')
plt.show()