数据结构(超详细讲解!!)第二十六节 图(下)
1.无向图的连通分量
图遍历时,对于连通图,无论是广度优先搜索还是深度优先搜索,仅需要调用一次搜索过程,即从任一个顶点出发,便可以遍历图中的各个顶点。对于非连通图,则需要多次调用搜索过程,而每次调用得到的顶点访问序列恰为各连通分量中的顶点集。
连通分量:无向图的极大连通子图
连通图只有一个连通分量,就是它本身
非连通图有多个连通分量
无向图的连通分量的求法:
从每个顶点出发进行遍历(深度或广度优先) 每一次从一个新的起点出发进行遍历得到的顶点序列就是一个连通分量的顶点集合。
2.无向网的最小生成树
生成树的性质:
每个连通图至少包含一颗生成树。
若G是(n,e)连通图,则e≥n-1
对于有n 个顶点的无向连通图,无论其生成树的形态如何,所有生成树中都有且仅有n-1 条边。
如果无向连通图是一个网,那么,它的所有生成树中必有一棵边的权值总和最小的生成树,我们称这棵生成树为最小生成树,简称为最小生成树。
生成树(Spanning Tree)
包含原连通图的所有n个顶点
包含原有的其中n-1条边
且保证连通(极小连通子图)
理解 :“包含所有顶点”:顶点一个都不能少
“极小”:那只能让边尽量少了
“连通”:但是又不能太少
应用:连通n个城市的需要多少条道路?
最多n(n-1)/2:任何两个城市之间都修一条路
最少n-1,问题是哪n-1条能使总代价最小呢?
问题转化为:如何在可能的路线中选择n-1条,能把所有城市(顶点)均连起来,且总耗费(各边权值之和)最小。
最小生成树不唯一,因为不同边的权值可能相等,当权值都相等时,就相当于无权图。 所有边权值均不相同的无向连通图的最小生成树是唯一的。 无论最小生成树是否唯一,但最小生成树的权值是唯一的。
最小生成树的性质(MST性质):
设连通网 N=(V,{E})
U为V的非空子集
F={(v1,v2)|(v1,v2)∈E,v1∈U,v2∈V-U}
设(u,v)是F中权值最小的边,则必存在一棵包含(u,v)的最小生成树
MST有多种算法,但最常用的是以下两种:
Prim算法特点: 将顶点归并,与边数无关,适于稠密网。(对顶点操作)
Kruskal算法特点:将边归并,适于求稀疏网的最小生成树。(对边操作)
1. 普里姆算法( Prim算法)
假设N=(V, {E})是连通网,TE为最小生成树中边的集合。
(1) 初始U={u0}(u0∈V), TE=φ;
(2)在所有u∈U, v∈V-U的边中选一条代价最小的边(u0, v0)并入集合TE,同时将v0并入U;
(3) 重复(2), 直到U=V为止。
此时,TE中必含有n-1条边,则T=(V,{TE})为N的最小生成树。
可以看出, 普利姆算法逐步增加U中的顶点, 可称为“加点法”。

所得生成树权值和:14+8+3+5+16+21 = 67

图采用邻接矩阵作为存储结构;
设置一个辅助数组closedge[ ]:
lowcost域 存放生成树外顶点集合(V-U)中的各顶点到生成树内(U)各顶点的各边上的当前最小权值;
adjvex域 记录生成树外顶点集合(V-U)各顶点距离树内集合(U)哪个顶点最近(即权值最小)。
struct{
int adjvex;
int lowcost;
}closedge[MAX_VERTEX_NUM];


struct{
int adjvex;
int lowcost;
}closedge[MAXVERTEXNUM];
void Prim(MGraph G,int v)
{ /*G为图的邻接矩阵存储,v是第一个进入集合U中的顶点的序号*/
int k,j,i,minCost;
closedge[v].lowcost=0;
for (j=0;j普里姆算法中的第二个for循环语句频度为n-1,其中包含的两个内循环频度也都为n-1,因此普里姆算法的时间复杂度为O(n2)。普里姆算法的时间复杂度与边数e无关,该算法更适合于求边数较多的带权无向连通图的最小生成树。
2. 克鲁斯卡尔算法( Kruskal算法)
假设N=(V, {E})是连通网,将N中的边按权值从小到大的顺序排列:
(1) 将n个顶点看成n个集合;
(2) 按权值由小到大的顺序选择边, 所选边应满足两个顶点不在同一个顶点集合内,将该边放到生成树边的集合中。同时将该边的两个顶点所在的顶点集合合并;
(3) 重复(2), 直到所有的顶点都在同一个顶点集合内。
可以看出,克鲁斯卡尔算法逐步增加生成树的边, 与普里姆算法相比,可称为“加边法”。

为实现克鲁斯卡尔算法需要设置一维辅助数组E,按权值从小到大的顺序存放图的边,数组的下标取值从0到e-1(e为图G边的数目)。 假设数组E存放图G中的所有边,且边已按权值从小到大的顺序排列。n为图G的顶点个数,e为图G的边数。克鲁斯卡尔算法如下:
typedef struct
{ int vex1; //边的起始顶点
int vex2; //边的终止顶点
int weight; //边的权值
}Edge;
Void kruskal(Edge E[],int n,int e)
{ int i,j,m1,m2,sn1,sn2,k;
int vset[MAXV]; //用于记录顶点是否属于同一集合的辅助数组
for(i=0;i如果给定带权无向连通图G有e条边,且边已经按权值递增的次序存放在数组E中,则用克鲁斯卡尔算法构造最小生成树的时间复杂度为O (e)。克鲁斯卡尔算法的时间复杂度与边数e有关,该算法适合于求边数较少的带权无向连通图的最小生成树。
3.有向无环图(AOV)进行拓扑排序
AOV-网----拓扑排序(Topological Sort)
用顶点表示活动,用弧表示活动间的优先关系的有向无环图,称为顶点表示活动的网(Activity On Vertex Network),简称为AOV-网。
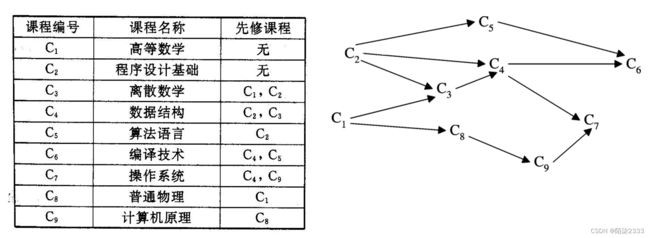
在有向图G=(V, {E})中, V中顶点的线性序列(vi1, vi2, vi3 …,vin)称为拓扑序列,序列必须满足如下条件:
对序列中任意两个顶点vi、vj,在G中有一条从vi到vj的路径,则在序列中vi必排在vj之前。
AOV-网的特性如下:
若vi为vj的先行活动,vj为vk的先行活动,则vi必为vk的先行活动,即先行关系具有可传递性。从离散数学的观点来看,若有
显然,在AOV-网中不能存在回路,否则回路中的活动就会互为前驱,从而无法执行。
AOV-网的拓扑序列不是唯一的。
拓扑排序的基本思想为:
(1) 从有向图中选一个无前驱的顶点输出;
(2) 将此顶点和以它为起点的弧删除;
(3) 重复(1)、(2),直到不存在无前驱的顶点;
(4) 若此时输出的顶点数小于有向图中的顶点数,则说 明有向图中存在回路,否则输出的顶点的顺序即为一个拓扑序列。
int TopoSort (AdjList G)
{Stack S;
int indegree[MAX-VERTEX-NUM];
int i, count, k;
ArcNode *p;
FindID(G, indegree); /*求各顶点入度*/
InitStack(&S); /*初始化辅助栈*/
for(i=0; iadjvex;
indegree[k]--; /*i号顶点的每个邻接点的入度减1*/
if(indegree[k]==0) Push(&S, k); /*若入度减为0,则入栈*/
p=p->nextarc;
}
} /*while*/
if (count 求顶点入度:
void FindID( AdjList G, int indegree[MAX-VERTEX-NUM])
/*求各顶点的入度*/
{int i; ArcNode *p;
for(i=0; iadjvex]++;
p=p->nextarc;
}
} /* for */
}
4.有向无环网(AOE)的关键路径
AOV-网----关键路径
有向图在工程计划和经营管理中有着广泛的应用。 通常用有向图来表示工程计划时有两种方法:
用顶点表示活动, 用有向弧表示活动间的优先关系, 即上节所讨论的AOV-网。
用顶点表示事件, 用弧表示活动, 弧的权值表示活动所需要的时间。
我们把用第二种方法构造的有向无环图叫做边表示活动的网(Activity On Edge Network), 简称AOE-网。
用顶点表示事件,弧表示活动,弧上权值代表活动所需的时间duration of time,这样的有向图叫AOE(Activity On Edge Network)网。 AOE网常用于估算工程完成时间。
AOE网的特点:
1.只有在某个顶点所代表的事件发生以后,该顶点引发的活动才能开始。
2.进入某事件的所有边所代表的活动都已完成,该顶点所代表的事件才能发生。
在AOE网中存在唯一的、入度为零的顶点,叫做源点;
存在唯一的、出度为零的顶点,叫做汇点。
从源点到汇点的最长路径的长度即为完成整个工程任务所需的时间,该路径叫做关键路径。
关键路径上的活动叫做关键活动。
这些活动中的任意一项活动未能按期完成,则整个工程的完成时间就要推迟。相反,如果能够加快关键活动的进度,则整个工程可以提前完成。
关键路径:从源点到汇点的路径长度最长的路径叫关键路径。
关键路径的特点:
关键路径的长度(路径上的边的权值之和)为完成整个工程所需要的最短时间。
关键路径的长度变化(即任意关键活动的权值变化)将影响整个工程的进度,而其他非关键活动在一定范围内的变化不会影响工期。
注意事项:
1、求关键路径必须在拓扑排序的前提下进行,有环图不能求关键路径。
2、只有减少关键活动的时间才可能缩短工期。
3、只有减少所有关键路径上共有的关键活动的时间才可能缩短工期。(关键路径不唯一)
4、只有在不改变关键路径的前提下减少关键活动的时间才可能缩短工期
求关键路径的基本步骤如下:
(1)对图中顶点进行拓扑排序,在排序过程中按拓扑序列求出每个事件的最早发生时间ET(i);
(2) 按逆拓扑序列求每个事件的最晚发生时间LT(i);
(3)求出每个活动ai的最早开始时间e(i)和最晚发生时间l(i);
(4) 找出e(i)=l(i) 的活动ai, 即为关键活动。
//修改后的拓扑排序
int ET[MAX-VERTEX-NUM]; /*每个顶点的最早发生时间*/
int TopoOrder(AdjList G, Stack * T)
/* G为有向网, T为返回拓扑序列的栈, S为存放入度为0的顶点的栈*/
{int count, i, j, k; ArcNode *p;
int indegree[MAX-VERTEX-NUM]; /*各顶点入度数组*/
Stack S;
InitStack(T); InitStack(&S); /*初始化栈T, S*/
FindID(G, indegree); /*求各个顶点的入度*/
for(i=0; iadjvex;
if(--indegree[k]==0) Push(&S, k); /*若顶点的入度减为0
, 则入栈*/
if (ET[j]+p->weight > ET[k])
ET[k]=ET[j]+p->weight;
p=p->nextarc;
} /*while*/
} /*while*/
if(count //关键路径
int CriticalPath(AdjList G)
{ArcNode *p;
int i, j, k, dut, ei, li; char tag;
int LT[MAX-VERTEX-NUM]; /*每个顶点的最迟发生时间*/
Stack T;
if(!TopoOrder(G, &T)) return(Error);
for(i=0; iadjvex; dut=p->weight;
if(LT[k]-dutnextarc;
} /* while */
} /* while*/
for(j=0; jAdjvex; dut=p->weight;
ei=ET[j]; li=LT[k]-dut;
tag=(ei==li)?′*′: ′ ′;
printf(″%c, %c, %d, %d, %d, %c\n″,
G.vertex[j].data, G.vertex[k].data, dut, ei, li, tag); /*输出关键活动*/
p=p->nextarc;
} /*while*/
} /* for */
return(Ok);
} /*CriticalPath*/

5.有向网中顶点间的最短路径
两种常见的求最短路径问题的方法:
单源最短路径—用Dijkstra(迪杰斯特拉)算法(一顶点到其余各顶点,图中不能含负的权值)
所有顶点间的最短路径—用Floyd(弗洛伊德)算法(任意两顶点之间,一次求各对顶点间最短路径)
我们可以将图中的顶点分为两组:
S——已求出的最短路径的终点集合(开始为{v0})。
V-S——尚未求出最短路径的顶点集合(开始为V-{v0}的全部结点)。
按最短路径长度的递增顺序逐个将第二组的顶点加入到第一组中。
一般情况下,下一条长度最短的最短路径的长度必是 dist[j]=Min{dist[i] | vi∈V-S} 其中,dist[i]或者是弧(v0,vi)上的权值, 或者是dist[k](vk∈S)和弧(vk,vi)上的权值之和。
1.Dijkstra算法
迪杰斯特拉算法的主要步骤如下:
(1) g为用邻接矩阵表示的带权图。 S←{v0} , dist[i]= g.arcs[v0][vi];将v0到其余顶点的路径长度初始化为权值;
(2) 选择vk,使得 vk为目前求得的下一条从v0出发的最短路径的终点。
(3) 修改从v0出发到集合V-S上任一顶点vi的最短路径的长度。如果 dist[k]+ g.arcs[k][i] (4) 重复(2)、(3) n-1次,即可按最短路径长度的递增顺序,逐 个求出v0到图中其它每个顶点的最短路径。 显然,算法的时间复杂度为O(n2) 。 弗罗伊德算法的基本思想如下: 设图g用邻接矩阵法表示,求图g中任意一对顶点vi、 vj间的最短路径 。 (-1) 将vi到vj 的最短的路径长度初始化为g.arcs[i][j], 然后进行如下n次比较和修正: (0) 在vi、vj间加入顶点v0,比较(vi, v0, vj)和(vi, vj)的路径的长度,取其中较短的路径作为vi到vj的且中间顶点号不大于0的最短路径。 (1) 在vi、vj间加入顶点v1,得(vi, …,v1)和(v1, …,vj), 其中(vi, …, v1)是vi到v1 的且中间顶点号不大于0的最短路径, (v1, …, vj) 是v1到vj 的且中间顶点号不大于0的最短路径,这两条路径在上一步中已求出。 将(vi, …, v1, …, vj)与上一步已求出的且vi到vj 中间顶点号不大于0的最短路径比较,取其中较短的路径作为vi到vj 的且中间顶点号不大于1的最短路径。 (2)在vi、vj间加入顶点v2,得(vi, …, v2)和(v2, …, vj), 其中(vi, …, v2)是vi到v2 的且中间顶点号不大于1的最短路径, (v2, …, vj) 是v2到vj 的且中间顶点号不大于1的最短路径,这两条路径在上一步中已求出。将(vi, …, v2, …, vj)与上一步已求出的且vi到vj 中间顶点号不大于1的最短路径比较, 取其中较短的路径作为vi到vj 的且中间顶点号不大于2的最短路径。typedef SeqList VertexSet;
ShortestPath-DJS(AdjMatrix g, int v0,
WeightType dist[MAX-VERTEX-NUM],
VertexSet path[MAX-VERTEX-NUM] )
/* path[i]中存放顶点i的当前最短路径。 dist[i]中存放顶点i的当前最短路径长度*/
{ VertexSet s; /* s为已找到最短路径的终点集合*/
for ( i =0; i2.Floyd算法
typedef SeqList VertexSet;
ShortestPath-Floyd(AdjMatrix g, WeightType dist [MAX-VERTEX-NUM][MAX-VERTEX-NUM], VertexSet path[MAX-VERTEX-NUM] [MAX-ERTEX-NUM] )
/* g为带权有向图的邻接矩阵表示法, path [i][j]为vi到vj的当前最短路径,dist[i][j]为vi到vj的当前最短路径长度*/
{
for (i=0; i