RabbitMQ学习文档
RabbitMQ
1. MQ
MQ全称为Message Queue,即消息队列。“消息队列”是在消息的传输过程中保存消息的容器。它是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦。
2. 认识RabbitMQ
RabbitMQ是由erlang语言开发,基于AMQP(Advanced Message Queue 高级消息队列协议)协议实现的消息队列,它是一种应用程序之间的通信方法,消息队列在分布式系统开发中应用非常广泛。
3. 常见的MQ产品
- Kafka:分布式消息系统,高吞吐量(大数据使用)
- ActiveMQ:基于JMS
- RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
- RocketMQ:基于JMS,阿里巴巴产品,目前交由Apache基金会
3.1 各类产品比较
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司得到应用,有较多的文档;各种协议支持较好 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |
4. 工作模式
4.1 单发送单接收(简单队列模式)
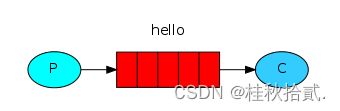
简单的发送与接收,没有特别的处理。
4.2 单发送多接收(工作队列模式)
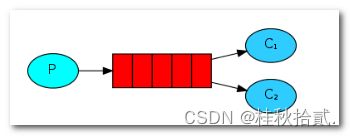
-
一个生产者,多个消费者;且一条消息只能被一个消费者消费,不能被多个消费者重复消费;
-
RabbitMQ默认的分发机制:轮询分发,默认情况下RabbitMQ会将接收到的消息逐个分发给消费者,并且是一次性分发完,它不等你,它就轮询发,你处理的慢就给你堆在那里自己慢慢去处理。
-
这显然不是我们想要的。我们想要的是,给处理的慢的消费者少发点,给处理的快的消费者多发点,这样可以不让消息在消费端造成堆积。这里我们做一个简单的配置,模拟能者多劳的“公平模式”。
-
设置prefetch=1,它表示限制每个Consumer在同一个时间点最多只能处理一个消息,我手里的活还没干完的话你就不能再给我分了。
spring:
rabbitmq:
host: localhost
port: 5672
username: sunxuchao
password: 123456
virtual-host: sunxuchao
listener:
simple:
# 公平分发
prefetch: 1
4.3 Publish/Subscribe(发布、订阅模式)

发送端发送广播消息,多个接收端接收。使用"fanout"方式发送,即广播消息,发送端不需要关心谁接收,一个队列可以有多个消费者,不用指定routing key,但发送到队列的消息只能被其中一个消费。
4.4 Routing (路由模式)

- 发送端按routing key发送消息,不同的接收端按不同的routing key接收消息。
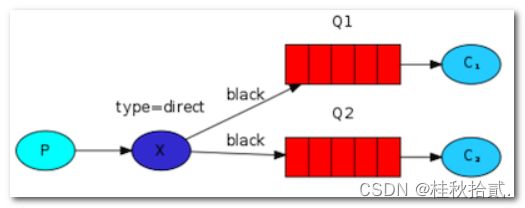
- 多个队列使用相同的绑定键是合法的。我们可以添加一个 X 和 Q1 之间的绑定,使用 black 绑定键。这样一来,直连交换机就和扇型交换机的行为一样,会将消息广播到所有匹配的队列。带有 black 路由键的消息会同时发送到 Q1 和 Q2队列中。
4.5 Topics(主题模式)
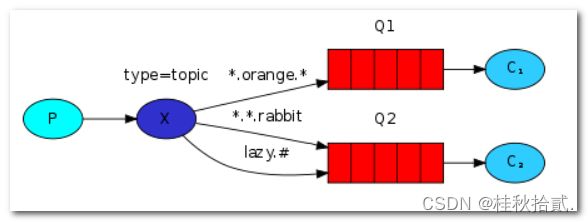
-
发送端不只按固定的routing key发送消息,而是按字符串“匹配”发送,接收端同样如此。
-
一个队列可以有多个消费者,但发送到队列的消息只能被其中一个消费。
-
topic 模式中Routing key必须具有固定的格式:以 . 间隔的一串单词
-
*可以替代一个单词,# 可以替代 0 或多个单词
5. RabbitMQ 的优点
- 基于AMQP协议、通过插件还支持JMS标准
- 高并发、高性能、高可用
- 强大的社区支持、高热度,很多大型公司都在使用(美团、滴滴、去哪、头条)
- 支持开发语言众多。支持插件
- 它是目前应用相当广泛的消息中间件,在企业级应用、微服务应用中,它起到了一个非常重要的角色。
- 在业务服务模块中解耦、异步通信、高并发限流、超时业务、数据延迟处理等都可以使用RabbitMQ。
- 可以用于不同开发语言开发应用间的通信,实现企业应用的集成。适合作为多个应用之间松耦合的接口,且不需要发送方和接收方同时在线。不用语言的软件解耦,可以最大限度的减少程序间的互相依赖,提高了系统的可用性和扩展性,同时还增加了消息的可靠传递和事务管理的功能。
6. 使用MQ的条件
- 生产者不需要从消费者处获得反馈。引入消息队列之前的直接调用,其接口的返回值应该为空,这才让明明下层的动作还没做,上层却当成动作做完了继续往后走,即所谓异步成为了可能。
- 容许短暂的不一致性。
- 确实是用了有效果。即解耦、提速、削峰这些方面的收益,超过加入MQ,管理MQ这些成本。
7. 适合的业务场景
7.1 解耦
解耦(应用之间不再直接相互访问,而是直接与消息对列对接)
7.2 异步
异步(分解一个费时的操作,把它变成多个异步执行的步骤)
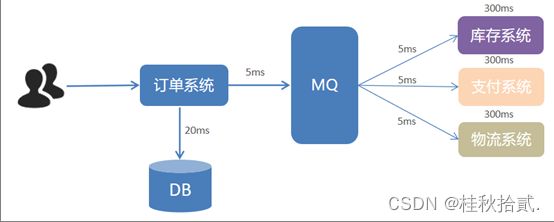
7.4 削峰填谷
削峰填谷(让处理程序相对均衡地处理数据)

7.5 不适用
- 代码繁琐
- 复用性
- 立马反馈
8. 核心组件
8.1 Broker(中间件)
Broker 简单理解就是RabbitMQ服务器。接受客户端的连接,实现AMQP实体服务。
8.2 Connection (连接)
我们知道无论是生产者还是消费者,都需要和 Broker 建立连接,这个连接就是Connection,是一条 TCP 连接 ,一个生产者或一个消费者与 Broker 之间只有一个Connection,即只有一条TCP连接。连接通常是长连接,使用认证机制并且提供TLS(SSL)保护
8.3 Channel (信道)
网络信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写通道,客户端可以建立对各Channel,每个Channel代表一个会话任务。
8.4 Message (消息)
服务与应用程序之间传送的数据,由 properties 和 body 组成,properties 可是对消息进行修饰,比如消息的优先级、延迟等高级特性,body则就是消息体的内容。
8.5 Virtual Host (虚拟主机)
-
每一个RabbitMQ服务器可以开设多个虚拟主机vhost,或者说每一个Broker里可以开设多个vhost,每一个vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的 “交换机exchange、绑定Binding、队列Queue”,更重要的是每一个vhost拥有独立的权限机制,这样就能安全地使用一个RabbitMQ服务器来服务多个应用程序,其中每个vhost服务一个应用程序。
-
每一个RabbitMQ服务器都有一个默认的虚拟主机 “/”,客户端连接RabbitMQ服务时须指定vHost,如果不指定默认连接的就是"/"。
-
用于多租户场景,提供权限范围控制,创建连接时可指定虚拟机和相对应的用户名密码。
8.6 Exchange(交换机)
交换机的作用就是根据路由规则,将消息转发到对应的队列上(不具备消息存储的能力)。
8.7 Queue(队列)
消息队列,保存消息的地方。
- Name 队列名
- Durable(消息代理重启后,队列依旧存在)是否持久化
- Exclusive(只被一个连接(connection)使用,而且当连接关闭后队列即被删除)是否独享、排外的
- Auto-delete(当最后一个消费者退订后即被删除)自动删除
- Arguments(队列的其他属性参数)
8.8 Routing key (路由键)
Routing key是消息头的属性,生产者将消息发送到交换机时,会在消息头上携带一个 key,这个 key就是routing key,来指定这个消息的路由规则。
8.9 Bindings (绑定)
绑定,可以理解成一个动词,它的作用就是把exchange和queue按照路由规则绑定起来。binding中可以保护多个routing key。
8.10 Binding key (绑定建)
在绑定Exchange与Queue时,一般会指定一个binding key,生产者将消息发送给Exchange时,消息头上会携带一个routing key,当binding key与routing key相匹配时,消息将会被路由到对应的Queue中。
9. 消息丢失
生产者将消息发送给RabbitMQ的Exchange交换机;Exchange交换机根据Routing key将消息路由到指定的Queue队列;消息在Queue中暂存,等待消费者消费消息;消费者从Queue中取出消息消费。
通过这种工作模式,很好地做到了两个系统之间的解耦,并且整个过程是一个异步的过程,producer发送消息后就可以继续处理自己业务逻辑,不需要同步等待consumer的消费结果。
该工作模式存在的问题——消息可能丢失
什么是消息丢失呢?简单来说,就是producer发送了一条消息出去,但由于某种原因(比如RabbitMQ宕机了),导致consumer没有消费到这条消息,最终导致producer与consumer两个系统的数据与期望结果不一致。
那消息是如何丢失的呢?既然在RabbitMQ的工作模式中,一条消息从producer到达consumer要经过4个步骤,那么在这4步中,任何一步都可能会把消息丢掉:
-
生产者将消息发送给Exchange交换机:假如producer向Exchange发送了一条消息,由于是异步调用,所以producer不关心Exchange是否收到了这条消息,就继续向下处理自己的业务逻辑。如果在Exchange收到消息之前,RabbitMQ宕机了,那这条消息就丢了。
-
Exchange交换机接收到消息后,会根据producer发送过来的Routing key将消息路由到匹配的Queue队列中。一般情况下,这一步不会出现什么问题,因为这一步是在RabbitMQ内部实现的,并且Exchange与Queue之间的Routing key都会在开发之前约定好,所以,只要保证producer发送消息时使用的Routing key是真实存在的即可正确地路由到指定的Queue队列。但万一小明在复制代码的时候,手一抖,导致发送消息时的Routing key多了个数字,此时,消息发出去后,Exchange虽然能收到消息,但由于匹配不到Routing key,所以无法将消息路由到Queue队列,那这条消息也算是变相消失了。
-
消息到达Queue中暂存,等待consumer消费:如果消息成功被路由到了Queue中,此时这条消息会被暂存在RabbitMQ的内存中,等到consumer消费,假如在consumer消费这条消息之前,RabbitMQ宕机了,那么这条消息也会丢失。
-
consumer从Queue中取走消息消费:如果前面一切顺利,并且消息也成功被consumer从Queue中取走消费,但consumer最后消费发生异常失败了。由于默认情况下,当一条消息被consumer取走后,RabbitMQ就会将这条消息从Queue中直接删除,所以,即使consumer消费失败了,这条消息也会消失,这样也会导致producer与consumer两个系统的数据不一致。
10. Confirm模式(推荐使用)

10.1 描述
- 生产者投递消息到 BroKer,如果没有到达交换机(exchange)或者由于其他原因无法路由到队列,则会触发 confirm 回调,ack = false
- 如果成功到达交换机(exchange)并正确路由到队列,则会触发 confirm 回调,ack = true
- 如果交换机(exchange)成功将消息转发到队列,不会回调 return
- 如果交换机(exchange)转到消息转发到队列失败,则会回调 return(需设置 mandatory = true,才能回调,否则不回调,消息就丢了)
10.2 在yml文件中开启回调确认
# 生产者
spring:
rabbitmq:
host: localhost
port: 5672
username: 账号
password: 密码
virtual-host: 虚拟空间
# 发布方return回调确认开启 (保证交换机到队列)
publisher-returns: true
# 开启是否达到交换机的回调(相关联的) none/correlated/simple (保证生产者到交换机)
publisher-confirm-type: correlated
10.3 消息接收确认三种模式(ack)
10.3.1手动确认
spring:
rabbitmq:
host: localhost
port: 5672
username: sunxuchao
password: 123456
virtual-host: sunxuchao
listener:
simple:
# 开启手动ack模式
acknowledge-mode: manual
在该模式下,消费者消费消息后需要根据消费情况给 Broker 返回一个回执,是确认 ack 使 Broker 删除该条已消费的消息,还是失败确认返回 nack,还是拒绝该消息。开启手动确认后,如果消费者接收到消息后还没有返回 ack 就宕机了,这种情况下消息也不会丢失,只有RabbitMQ接收到返回ack后,消息才会从队列中被删除。该模式下有三种确认方式:
-
basicAck(long deliveryTag, boolean multiple) 成功确认
basicAck方法表示,使用此方法后,消息会被 rabbitmq broker 删除,其中参数 long deliveryTag 为消息的唯一序号,boolean multiple 表示是否一次消费多条消息,false 表示只确认该序列号对应的消息,true 则表示确认该序列号对应的消息以及比该序列号小的所有消息,比如我先发送2条消息,他们的序列号分别为2,3,并且他们都没有被确认,还留在队列中,那么如果当前消息序列号为4,那么当 multiple 为 true,则序列号为2、3的消息也会被一同确认。
-
basicNack(long deliveryTag, boolean multiple, boolean requeue) 失败确认
basicNack方法表示失败确认,一般当我们消费消息时出现异常用到此方法,可以通过参数 requeue 设置是否将消息重新投递到队列。requeue 表示消息是否重新入列,如果 requeue = false 表示消息不重回队列并且丢弃该消息,如果为 requeue = true 则消息重回队列。
-
basicReject(long deliveryTag, boolean requeue) 方法表示拒绝消息
basicReject方法表示拒绝消息,requeue=false表示被拒绝的消息会被丢弃,requeue=true表示消息会重回队列,该方法与basicNack方法的区别就是不支持 multiple 批量确认。
10.3.2 自动确认
spring:
rabbitmq:
host: localhost
port: 5672
username: sunxuchao
password: 123456
virtual-host: sunxuchao
listener:
simple:
# 开启手动ack模式
acknowledge-mode: none
rabbitmq默认消费者正确处理所有请求。(不设置时的默认方式)
10.3.3 根据情况确认
spring:
rabbitmq:
host: localhost
port: 5672
username: sunxuchao
password: 123456
virtual-host: sunxuchao
listener:
simple:
# 开启手动ack模式
acknowledge-mode: auto
主要分成以下几种情况:
- 如果消费者在消费的过程中没有抛出异常,则自动确认。
- 当消费者消费的过程中抛出 AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝,且该消息不会重回队列。
- 当抛出 ImmediateAcknowledgeAmqpException 异常,消息会被确认。
- 如果抛出其他的异常,则消息会被拒绝,但是与前两个不同的是,该消息会重回队列,如果此时只有一个消费者监听该队列,那么该消息重回队列后又会推送给该消费者,会造成死循环的情况。
11. Transaction模式(不推荐)
Transaction模式类似于我们操作数据库的操作,首先开启一个事务,然后执行sql,最后根据sql执行情况进行commit或者rollback。
在RabbitMQ中实现Transaction模式时,首先要用Channel对象的txSelect()方法将信道设置成事务模式,broker收到该命令后,会向producer返回一个select-ok的命令,表示信道的事务模式设置成功;然后producer就可以向broker发送消息了。在消息发送完成后,producer要调用Channel对象的commit()方法提交事务。
整个流程可以用下图表示:

在Transaction模式中,producer只有收到了broker返回的 Commit-Ok 命令后才能提交成功,若在commit执行之前,RabbitMQ发生故障抛出异常,producer可以将其捕获,然后通过Channel对象的txRollback()方法回滚事务,同时可以重发该消息。
try {
channel.txSelect();
channel.basicPublish("exchangeName", "routingKey", false, null, "messgae".getBytes());
// 模拟broker发生故障导致异常
int i = 1/0;
channel.txCommit();
} catch (Exception e) {
channel.txRollback();
}
Transaction模式虽然可以保证消息从producer到broker的可靠性投递,但它的缺点也很明显,它是阻塞的,只有当一条消息被成功发送到RabbitMQ之后,才能继续发送下一条消息,这种模式会大幅度降低RabbitMQ的性能,不推荐使用。
12. 消费端消息处理
12.1 消费失败重试
12.1.1 配置文件
spring:
rabbitmq:
listener:
simple:
retry:
#开启消息重发控制
enabled: true
#重发次数
max-attempts: 3
#间隔时间
initial-interval: 3000
12.1.2 模拟消费出现异常重发
出现异常就会重发
// 监听某个队列
@RabbitListener(queues = DirectReliableConfig.DIRECT_RELIABLE_QUEUE_NAME)
public void revice(Message message) throws Exception {
log.info("我收到的消息是:{}",new String(message.getBody()));
// 模拟异常
throw new Exception("我错啦");
}
12.2 死信队列
12.2.1 什么是TTL
-
time to live 消息存活时间
-
如果消息在存活时间内未被消费,则会别清除
-
RabbitMQ支持两种ttl设置
- 单独消息进行配置ttl
- 整个队列进行配置ttl(居多)
12.2.2 什么是死信交换机
- Dead Letter Exchange(死信交换机,缩写:DLX)当消息成为死信后,会被重新发送到另一个交换机,这个交换机就是DLX死信交换机。
12.2.3 什么是死信队列
- 没有被及时消费的消息存放的队列
12.2.4 死信来源
- 消息被拒绝(basic.reject或basic.nack)并且requeue = false
- 消息TTL过期
- 队列达到最大长度(队列满了,无法再添加数据到mq中)
12.2.5 死信的处理方式
死信的产生既然不可避免,那么就需要从实际的业务角度和场景出发,对这些死信进行后续的处理,常见的处理方式大致有下面几种:
- 丢弃,如果不是很重要,可以选择丢弃
- 记录死信入库,然后做后续的业务分析或处理
- 通过死信队列,由负责监听死信的应用程序进行处理
综合来看,更常用的做法是第三种,即通过死信队列,将产生的死信通过程序的配置路由到指定的死信队列
12.3 重复消费和幂等问题
12.3.1 幂等来源
- 网络波动, 可能会引起重复请求
- 页面重复刷新
- 浏览器重复的HTTP请求
- 定时任务重复执行
- 用户双击提交按钮
- 数据的重复推送等等
举例:
比如你购物只想购买一件商品,但是网络卡顿,你按了多次提交按钮后,系统将此订单生成了两次!如上即数据库生成了两条订单记录!即产生了幂等性的问题!
正常情况:
一个商品页点提交,只会产生一条订单信息!
12.3.2 使用redis解决幂等问题
@RabbitListener(queues = DirectDLConfig.DIRECT_QUEUE_NAME)
public void recive(Message message, Channel channel) throws IOException {
try {
String messageId = message.getMessageProperties().getMessageId();
// 如果唯一id不为空,并没有存在redis中,说明没有被消费过
// 否则该消息是已被消费
if(messageId!=null && !(redisTemplate.hasKey(messageId))){
log.info("我收到的消息是:{}", new String(message.getBody()));
redisTemplate.opsForValue().setIfAbsent(messageId,true,60, TimeUnit.SECONDS);
}else {
System.out.println("已经消费了");
}
// 确认已被消费
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
} catch (Exception e) {
e.printStackTrace();
// 未消费
channel.basicNack(message.getMessageProperties().getDeliveryTag(),false,false);
}
}
12.4 延时队列
12.4.1 什么是延迟队列
-
一种带有延迟功能的消息队列,Producer 将消息发送到消息队列 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消息
-
延迟队列和普通队列最大的区别就是,普通队列里的消息是希望自己早点被取出来消费。而延迟队列中的消息都是由时间来控制的。也就是说,他们进入队列的时候,就已经被安排何时被取出了
12.4.2 使用场景
- 通过消息触发一些定时任务,比如在某一固定时间点向用户发送提醒消息
- 用户登录之后5分钟给用户做分类推送、用户多少天未登录给用户做召回推送
- 消息生产和消费有时间窗口要求:比如在天猫电商交易中超时未支付关闭订单的场景,在订单创建时会发送一条 延时消息。这条消息将会在 30 分钟以后投递给消费者,消费者收到此消息后需要判断对应的订单是否已完成支付。 如支付未完成,则关闭订单。如已完成支付则忽略
- 订单超时支付取消订单
- 用户发起退款卖家3天不处理自动退款
- 预约抢购活动,活动开始前10分钟短信通知用户
12.4.3 实现方式
- 定时任务高精度轮训
- 采用RocketMQ自带延迟消息功能
- RabbitMQ本身是不支持延迟队列的,怎么办?
- 使用普通队列和死信队列来模拟实现延迟的效果。大致上是将消息放入一个没有被监听的队列上,设置TTL(一条消息的最大存活时间)为延迟的时间,时间到了没有被消费,直接成为私信。监听私信队列来进行操作。
- 使用rabbitmq官方提供的delayed插件来真正实现延迟队列。本文对第二种进行详解
12.5 消费端限流
spring:
rabbitmq:
listener:
simple:
# 公平分发
prefetch: 1
# 开启手动ack
acknowledge-mode: manual
max-concurrency: 1 #每次最多拿一条消息