1ms 推理延时!MobileOne:移动端高效部署Backbone
作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
导读
本文提出一种在移动设备上部署友好的神经网络模型 MobileOne。在 ImageNet 上达到 top-1 精度 75.9% 的情况下,在 iPhone12 上的推理时间低于 1 ms。并可以推广到多个任务:图像分类、对象检测和语义分割
本文目录
1 MobileOne:1ms 推理延时的移动端视觉架构
(来自 Apple)
1 MobileOne 论文解读
1.1 背景和动机
1.2 轻量化模型指标 Params,FLOPs,和 Latency 的相关性
1.3 延时的瓶颈在哪里
1.4 MobileOne Block 架构
1.5 MobileOne 架构
太长不看版
本文提出一种在移动设备上部署友好的神经网络模型 MobileOne。本文识别并分析了最近一些高效的神经网络的架构和优化的瓶颈,并提供了缓解这些瓶颈的方法。最终设计出来一个高效的 Backbone 模型 MobileOne,在 ImageNet 上达到 top-1 精度 75.9% 的情况下,在 iPhone12 上的推理时间低于 1 ms。MobileOne 是一种在端侧设备上很高效的架构。而且,与部署在移动设备上的现有高效架构相比,MobileOne 可以推广到多个任务:图像分类、对象检测和语义分割,在延迟和准确性方面有显著改进。
因为在推理的时候 MobileOne 是一个直筒型的架构,这种结构导致更低的内存访问成本,因此 MobileOne 的宽度可以适当增加。例如,MobileOne-S1 参数为 4.8M,时延为 0.89ms,而 MobileNet-V2 参数为 3.4M,但是时延却涨到了 0.98ms。而且,MobileOne 的 top-1 精度比 MobileNet-V2 高 3.9%。
 图1:MobileOne 的精度和延时比较
图1:MobileOne 的精度和延时比较
1 MobileOne:1ms 推理延时的移动端视觉架构
论文名称:An Improved One millisecond Mobile Backbone (CVPR 2023)
论文地址:
https://arxiv.org/pdf/2206.04040.pdf
1.1 背景和动机
针对移动设备的高效深度学习架构的设计和部署的方向之一是在提高精度的同时不断减少浮点运算量 (FLOPs) 和参数量 (Params)。但是这两个指标和模型具体的延时 (Latency) 的关系却不那么明朗。
比如说 FLOPs,相同 FLOPs 的两个模型,它们的延时可能会差出很远来。因为 FLOPs 只考虑模型总的计算量,而不考虑内存访问成本 (memory access cost, MAC) 和并行度 (degree of parallelism)[1]。
对于 MAC 而言,Add 或 Concat 所需的计算可以忽略不计,但是 MAC 却不能忽略。而 Add 或 Concat 并不占用计算量啊。由此可见,在相同的 FLOPs 下,MAC 大的模型将具有更大的延时。
对于并行度而言,在相同的 FLOPs 下,具有高并行度的模型可能比另一个具有低并行度的模型快得多。在 ShuffleNet V2[2] 中作者报告说碎片操作符的数量越多,对于高并行计算能力的设备 (如 GPU) 不友好,并引入了额外的开销,如内核启动和同步。相比而言,Inception 架构有多分支,而 VGG 类的直筒架构是单分支的。
再比如说 Params,相同 Params 的两个模型,它们的延时也不会完全一致。
对于 MAC 而言,Add 或 Concat 所需的参数是零,但是 MAC 却不能忽略。所以在相同的 Params 下,MAC 大的模型将具有更大的延时。
当模型使用共享参数时,会带来更高的 FLOPS,但是同时 Params 会降低。
因此,本文的目标是设计实际设备上面 Latency 较低的神经网络。测试的方法是使用 CoreML[3] 这个工具在 iPhone12 上测试 Latency。小模型的优化问题是另一个瓶颈,针对这个问题作者希望借助 RepVGG[4] 里面的结构重参数化技术的帮助。作者通过在整个训练过程中动态放松正则化来进一步缓解优化瓶颈,以防止小模型的过度正则化而导致的欠拟合问题。具体而言,本文设计了一个新的架构 MobileOne,其变体在 iPhone12 上运行不到 1ms,实现了很高的精度,同时在实际设备上运行得更快。
1.2 轻量化指标 Params,FLOPs,和 Latency 的相关性
作者首先评估了轻量化指标 Params,FLOPs,和 Latency 的相关性。具体来讲作者开发了一个 iOS 应用程序来测量 iPhone12 上 ONNX 模型的延迟,模型转换的工具包使用的是 CoreML[3] 这个包。
如下图2所示是延迟与 FLOPs 以及延迟与 Params 的关系。可以观察到许多具有较高 Params 的模型具有较低的延迟,FLOPs 和延迟之间也具有相似的关系。作者还估计了 Spearman rank correlation,如下图3所示。可以发现,对于移动设备上的高效架构,延迟与 FLOPs 中度相关,与 Params 弱相关。这种相关性在 CPU 上甚至更低。
 图2:轻量化模型指标的相关性:延迟与 FLOPs 以及延迟与 Params 的关系
图2:轻量化模型指标的相关性:延迟与 FLOPs 以及延迟与 Params 的关系  图3:FLOPs 和 Params 和 Latency 之间的斯皮尔曼相关系数
图3:FLOPs 和 Params 和 Latency 之间的斯皮尔曼相关系数
1.3 延时的瓶颈在哪里
激活函数
为了分析激活函数对延迟的影响,作者构建了一个30层卷积神经网络,并在 iPhone12 上使用不同的激活函数对其进行了基准测试。结果如下图4所示,可以看到延迟有很大的不同。简单的 ReLU 激活函数的延时成本最低。复杂的激活函数可能由于同步成本的原因,造成了较高的延时成本。在未来,这些激活可以被硬件加速。因此 MobileOne 中只使用 ReLU 作为激活函数。
 图4:不同激活函数的延时比较
图4:不同激活函数的延时比较
内存访问成本 (memory access cost, MAC) 和并行度 (degree of parallelism)[1]
如上文所述,在多分支架构中,内存访问成本显著增加。因为每个分支的激活必须被存储起来,以计算图中的下一个张量。如果网络的分支数量较少,则可以避免这种内存瓶颈。为了演示 MAC 等隐藏成本带来的影响,作者在30层卷积神经网络中使用 skip connections 和 squeeze-excite 块进行消融实验。从图5的结果中可以看到,这些东西都会带来 Latency 的提升。因此,我们在推理时采用了无分支的架构,从而减少了内存访问成本。
 图5:SE 块和跳跃连接对于 Latency 的影响
图5:SE 块和跳跃连接对于 Latency 的影响
1.4 MobileOne Block 架构
首先,MobileOne 的 Basic Block 是按照 MobileNet-V1[5]来设计的,采用的基本架构是 3x3 depthwise convolution + 1x1 pointwise convolution。
在训练的时候,MobileOne 使用结构重参数化技术,在训练时给 3x3 Depthwise Convolution 加上几个并行的分支,给 1x1 Pointwise Convolution 也加上几个并行的分支,如下图6所示。但是,和 RepVGG 不同的是:
RepVGG 在训练时给 3x3 Convolution 加上:1x1 convolution 和只有 BN 的 Shortcut 分支。
MobileOne 在训练时给 3x3 Depthwise Convolution 加上: 个 3x3 Depthwise Convolution,1x1 Depthwise Convolution 和只有 BN 的 Shortcut 分支。
 图6:MobileOne 架构
图6:MobileOne 架构
在推理的时候,MobileOne 模型没有任何分支,是一个直筒型的架构。结构重参数化的具体做法和 RepVGG 一致,都是先把 BN "吸" 到前面的卷积中,再合并平行的卷积的参数。
如下图7所示是关于平行的分支数 的消融实验,图8所示是是否使用结构重参数化带来的影响。可以看到,对于小模型而言,平行的分支数多了好一点。结构重参数化会对各种尺寸的模型带来提升。
 图7:平行分支数的消融实验
图7:平行分支数的消融实验  图8:是否使用结构重参数化的影响
图8:是否使用结构重参数化的影响
1.5 MobileOne 架构
如下图9所示是 MobileOne 的具体架构参数。设计的一般原则是在模型的浅层使用较少的 Blocks,深层则堆叠较多的 Blocks,因为浅层输入分辨率较大,使得整个模型的延时增加。
因为 MobileOne 模型在推理时没有多分支架构,因此不会产生数据移动成本,换句话讲节约了延时。所以,在设计模型时可以在不产生显著的 Latency 成本的情况下,使用更多的参数量。
 图9:MobileOne 架构
图9:MobileOne 架构
作者在保持所有其他参数不变的情况下消融了各种训练策略。可以看到,对 Weight decay 系数进行退火后得到0.5% 的精度提升。
 图10:训练策略的消融实验
图10:训练策略的消融实验
1.6 实验结果
图像分类实验结果
ImageNet-1K 上面的图像分类实验结果如下图11所示。可以看到,目前最先进的 MobileFormer 的 top-1 精度为79.3%,延迟为 70.76ms,而 MobileOne-S4 的准确率为 79.4%,延迟仅为 1.86ms,移动端速度快了38倍。MobileOne-S3 的 top-1 精度比 EfficientNet-B0 高 1%,移动端速度快了11倍。
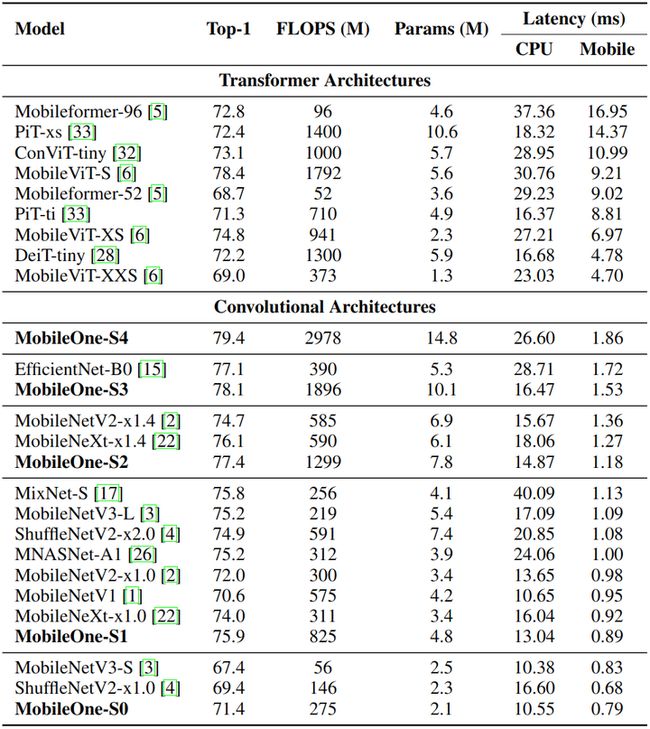 图11:图像分类实验结果
图11:图像分类实验结果
MobileOne 作为端侧的小模型,除了图像分类之外,还在下游任务上面做了实验,结果如下图12所示。
 图12:下游任务实验结果
图12:下游任务实验结果
COCO 目标检测实验结果
使用 ImageNet-1K 上预训练的 Backbone,加上 SSDLite 作为检测头。在 MS COCO 数据集上进行训练。输入分辨率设置 320×320,模型训练200个 Epochs。MobileOne 的最佳模型比 MNASNet 高出 27.8%,比 MobileViT 的最佳版本高出 6.1%。
Pascal VOC 和 ADE20K 语义分割实验结果
使用 ImageNet-1K 上预训练的 Backbone,加上 Deeplab V3 作为分割头。在 Pascal VOC 和 ADE20K 数据集上进行训练。对于 VOC 数据集,MobileOne 比 Mobile ViT 高出 1.3%,比 MobileNetV2 高出 5.8%。对于 ADE20K 数据集,MobileOne 比 MobilenetV2 高出 12.0%。使用更小的 MobileOne-S1,仍然高出 2.9%。
总结
MobileOne 是一种借助了结构重参数化技术的,在端侧设备上很高效的视觉骨干架构。而且,与部署在移动设备上的现有高效架构相比,MobileOne 可以推广到多个任务:图像分类、对象检测和语义分割,在延迟和准确性方面有显著改进。
参考
^abRepVGG: Making VGG-style ConvNets Great Again
^ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
^abhttps://coremltools.readme.io/docs
^https://zhuanlan.zhihu.com/p/344324470
^MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称