网络爬虫笔记—滑动验证码识别
一、什么是滑动验证码

点击之前

点击之后
像这种通过滑动图片,补全缺口的方式,就是滑动验证码。
二、识别思路
-
1)使用
selenium库操作谷歌浏览器,打开目标网站; -
2)模拟操作浏览器,对网页截图,先获取全屏截图;
-
3)根据滑动验证码的元素,获取滑动验证码不带缺口的图片和带缺口的图片;
-
4)通过不带缺口验证码图片和带缺口验证码图片的对比,识别滑动验证码缺口的位置;
-
5)模拟移动滑块,完成验证;
<运行效果>
三、具体实践
3.1、验证码获取
- 目标网站:https://cxcx.iachina.cn/
*该网站为财产保险公司自主注册产品查询平台,该教程仅是案例教学,请大家不要使用该方法恶意爬取或访问任何网站。
- 网站特点
该网站需要先输入用户名和密码,然后点击登录才可以弹出滑动验证码;

点击登录前
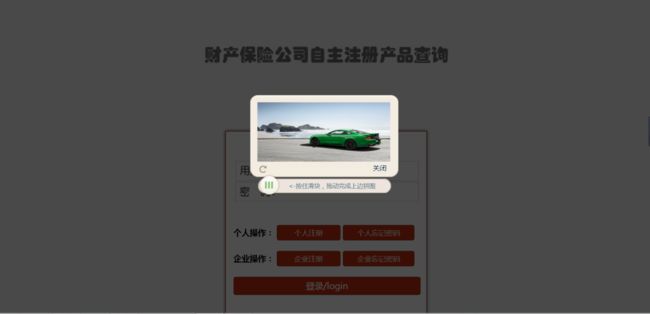
点击登录后
- 代码实现
打开网站→输入用户名和验证码→点击登录→全屏截图
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from PIL import Image
from selenium.webdriver import ActionChains
#1、隐藏Chrome 正受到自动测试软件的控制
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(options=chrome_options)
#2、打开浏览器
myurl="https://cxcx.iachina.cn/"
browser.get(myurl)#打开浏览器
browser.maximize_window()#将浏览器全屏
time.sleep(2)
#3、输入用户名和验证码
myname = browser.find_element(By.XPATH, "/html/body/form/div/div[2]/div[1]/input[1]")#运用Xpath方法,找到用户名的输入框
myname.send_keys("1111")#在用户名处,输入1111
mycode = browser.find_element(By.XPATH, '//*[@id="passWord"]')#运用Xpath方法,找到密码的输入框
mycode.send_keys("1111")#在密码处,输入1111
#4、点击登录按钮
button = browser.find_element(By.XPATH, '/html/body/form/div/div[3]/input[5]')#运用Xpath方法,找到登录的按钮
button.click()#点击登录按钮
time.sleep(2)#等待2秒
#5、全屏截图
screenshot_all = browser.save_screenshot("screenshot_all.png")#获取全屏截图,并保存到本地
- 代码答疑
a)1、隐藏Chrome 正受到自动测试软件的控制
用selenium操作谷歌浏览器时,会在浏览器左上角显示“Chrome 正受到自动测试软件的控制。”此处代码的目的,就是取消该显示,不取消一般也不影响系统的正常运行。
![]()
浏览器左上角的提示
b)3、输入用户名和验证码
此处用到了Xpath方法来定位元素
- 保存的全屏截图

screenshot_all.png
3.2、截取未带缺口的验证码
- 代码实现
获取验证码元素的位置信息→读取本地保存的全屏截图图片(screenshot_all.png)→截取出验证码图片
#6、获取验证码位置
code_element = browser.find_element(By.XPATH,'//*[@id="slideBar"]/div/div[1]/div[2]/div[2]/div[1]')#通过Xpath方法获取验证码元素
left = code_element.location['x']*1.5#返回一个字典格式,里面有两个参数x和y,代表元素的位置,1.5表示的电脑缩放比例
top = code_element.location['y']*1.5
right = code_element.size['width']*1.5+left#验证码元素右边的点位置
height = code_element.size['height']*1.5+top#验证码元素左上边点位置
#7、读取本地验证码并截取验证码图片
im = Image.open("screenshot_all.png")#读取全屏截图
img = im.crop((left, top, right, height))#截取验证码图片
img.save("beforecode.png")#保存验证码图片
- 代码解析
关于验证码的截取
- 保存的验证码图片

beforecode.png
3.3、截取带缺口的验证码
带缺口的验证码图片,只有点击下面的滑块后才会显示。显示出来之后,后面的方法就和“3.1、验证码获取”及“3.2、截取未带缺口的验证码”保持一致了。

获取方法
- 代码实现
获取滑块的位置信息→点击滑块→重复3.1及3.2的步骤
#8、滑块位置获取和点击滑块
button = browser.find_element(By.XPATH, '//*[@id="slideBtn"]')#运用Xpath方法,找到滑块的按钮
button.click()#点击滑块的按钮
time.sleep(3)#等待3秒
screenshot_all = browser.save_screenshot("afterscreenshot_all.png")#获取全屏截图,并保存到本地
#9、重复6和7步
code_element = browser.find_element(By.XPATH,'//*[@id="slideBar"]/div/div[1]/div[2]/div[2]/div[1]')#通过Xpath方法获取验证码元素
left = code_element.location['x']*1.5#返回一个字典格式,里面有两个参数x和y,代表元素的位置,1.5表示的电脑缩放比例
top = code_element.location['y']*1.5
right = code_element.size['width']*1.5+left#验证码元素右边的点位置
height = code_element.size['height']*1.5+top#验证码元素左上边点位置
im = Image.open("afterscreenshot_all.png")#读取全屏截图
img = im.crop((left, top, right, height))#截取验证码图片
img.save("aftercode.png")#保存验证码图片
- 保存的带缺口的验证码图片

3.4、缺口识别
通过对比两张图片可以看出,右边图片在缺口处有一个正方形的空白。因此,我们可以获取两张图片的像素点的RGB值,并遍历所有的像素点,如果两者像素点的RGB值相同,则代表不是缺口,如果不同则代表是缺口。
实际运行中为了避免出现误差,一般会设置一个阈值,只有两者的差异超过这个阈值,我们才认为是两个不同的点。
- 代码实现
读取两张照片的像素点RGB值→遍历所有像素点并进行比较→输出差异区域
#10、读取两张照片
beforecode = Image.open("beforecode.png").convert("L")#读取未带缺口的验证码图片,并转化为灰度图片
aftercode = Image.open("aftercode.png").convert("L")#读取带缺口的验证码图片,并转化为灰度图片
threshold = 60#设置差异阈值为60,即两个像素点的RGB值得差,大于60,才被认为是差异点
width = beforecode.size[0]#获取图片的宽度
height = beforecode.size[1]#获取图片的高度
#11、遍历像素点,输出差异区域
mylocal = []
for h in range(0,height):
for w in range(int(round(width/3,0)),width):#因为缺口一般在右边,所有我们从左边的1/3处开始遍历
beforepixel=beforecode.getpixel((w,h))#获取该像素点的RGB值,因为转化成灰度图片了,所有只有一个值
afterpixel=aftercode.getpixel((w,h))
if abs(beforepixel-afterpixel) > threshold:#遍历每一个像素点,并与阈值比较
if w not in mylocal:#为了排除重复值
mylocal.append(w)#将差异点的宽,保存到列表中。因为滑动验证码,只需要左右移动就可以了
- 思路解析
a)为什么要转化为灰度图片
电脑的彩色图片是由三个值决定的即RGB值,详情可见下图。对于图片来说,图片是由一些带颜色的点组成的,即我们常说的像素。每一个像素在电脑都会有三个值,即R值、G值、B值,这三个值共同决定了这个像素的颜色。但我们处理相片时,如果RGB三个值都遍历,则会加大计算量,因此我们可以将彩色图片变成灰度图片(黑白照片),这样图片的每个像素点将不是由RGB三个值决定的,而是仅有一个值,这个值决定了这个像素点的黑白程度。如果值越接近255则越白,越接近0则越黑。所以变成灰度图片的目的主要是方便计算。

RGB色彩
b)为什么从照片的1/3处开始识别不同
大多数验证码图片都是从左向右滑动,也就是说缺口会在照片右边,所以从照片1/3处开始向右遍历每个像素点。一是为了减少计算量;二是为了避免识别出左侧的不同的位置。这个位置设置,可以根据滑动验证码的实际情况,进行设置,不一定必须设置为1/3。
c)为什么缺口位置仅保留了宽的位置
这是因为,滑动验证码,大多都是向右移动的,不会上下移动,所以只需要保留宽度,记录向右移动的位置即可。
3.5、移动轨迹计算
现在滑动验证码都加了反爬虫识别,如果我们均速移动、匀加速移动或匀减速运动都会被系统识别为非人为操作,进而无法通过验证。
实际我们点击的时候,前面会移动的快,后面会移动的慢,因此我们可以先匀加速运动后匀减速运动,这样就可以模拟人的操作了。这里需要用到物理的匀加速公式,这里直接将其写出来,感兴趣的可以再去回味一下高中物理。
:初速度,:运动时间,:加速度,:移动流程。
- 代码实现
#12、移动轨迹计算
distance = mylocal[0]/1.5#滑块移动的距离,就是上面识别到的第一个差异点的w值
track = []# 移动轨迹,里面保留的是每次移动的距离
current = 0# 当前位移
mid = distance * 4 / 5# 减速阈值,前面4/5做匀加速移动,后面1/5做匀加速移动
t = 0.2# 计算间隔,每次移动两秒
v = 0# 初速度
while current < distance:#当移动的距离超过,目标距离后,就停止循环
if current < mid:
a = 2#前面匀加速的加速度为正2
else:
a = -3#后面匀减速的加速度为负3
v0 = v# 初速度 v0
v = v0 + a * t #当前速度 v = v0 + at
move = v0 * t + 1 / 2 * a * t * t # 移动距离 x = v0t + 1/2 * a * t^2
current = current + move#总位移
track.append(round(move))#每次移动的距离
track[-1]=distance-sum(track[0:-1])#上面计算的总距离,会超过目标距离,所以最后一个移动距离需要修正一下

移动距离示意图
- 代码解析
a)distance = mylocal[0]/1.5
为什么距离这里,要除以1.5?由于我的电脑是1.5倍显示的,但系统移动距离却是按照100%显示移动的,所以要恢复至原来的100%显示的距离。
b)track[-1]=distance-sum(track[0:-1])
为什么滑块最后一个移动距离要修正?按照上面的逻辑计算的移动距离会大于实际移动的距离,因此对于最后一步的移动距离需要用总距离修正一下,即总距离减去前面的移动距离和,就是最后一步需要移动的距离。
3.6、移动滑块
缺口位置和移动轨迹全部计算好之后,最后一步就是运用动作链来操作滑块移动,完成图片验证的操作。
- 代码实现
找到滑块的位置→运用动作链移动滑块
#13、移动滑块
actions = ActionChains(browser)#创建动作链
slider = browser.find_element(By.XPATH,'//*[@id="slideBtn"]')#运用Xpath方法获取滑块元素
actions.click_and_hold(slider).perform()#点击滑块,并保持点击动作
for x in track:
actions.move_by_offset(xoffset=x, yoffset=0).perform()#拖动滑块
time.sleep(1)
actions.release().perform()#松开滑块,验证完成。
- 代码解析
a)actions.click_and_hold(slider).perform()
slider为滑块元素,此代码可以保持点击滑块不松开的动作。
b)actions.move_by_offset(xoffset=x, yoffset=0).perform()
此代码表示持续的移动滑块,xoffset=x表示向左或向右移动的距离,yoffset=0表示向上或向下移动的距离。
c)actions.release().perform()
此代码表示松开滑块,取消点击动作。
最后
我们准备了一门非常系统的爬虫课程,除了为你提供一条清晰、无痛的学习路径,我们甄选了最实用的学习资源以及庞大的主流爬虫案例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。
01 专为0基础设置,小白也能轻松学会
我们把Python的所有知识点,都穿插在了漫画里面。
在Python小课中,你可以通过漫画的方式学到知识点,难懂的专业知识瞬间变得有趣易懂。


你就像漫画的主人公一样,穿越在剧情中,通关过坎,不知不觉完成知识的学习。
02 无需自己下载安装包,提供详细安装教程

03 规划详细学习路线,提供学习视频


04 提供实战资料,更好巩固知识
05 提供面试资料以及副业资料,便于更好就业


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】
