Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练
abstract
大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为只有全局图像-文本对齐信息可用。在本文中,我们介绍放大镜![]() ,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的新视角学习细粒度语义对齐。为了有效地计算博弈论交互作用,我们进一步提出了一种不确定性感知神经Shapley交互学习模块。实验表明,LOUPE在各种视觉语言任务上都达到了最先进的性能。此外,无需任何对象级人工注释和微调,LOUPE 在对象检测和视觉接地方面实现了具有竞争力的性能。更重要的是,LOUPE开辟了一个新的有前途的方向,即从大规模原始图像-文本对中学习细粒度语义。这项工作的存储库位于 https://github.com/YYJMJC/LOUPE。
,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的新视角学习细粒度语义对齐。为了有效地计算博弈论交互作用,我们进一步提出了一种不确定性感知神经Shapley交互学习模块。实验表明,LOUPE在各种视觉语言任务上都达到了最先进的性能。此外,无需任何对象级人工注释和微调,LOUPE 在对象检测和视觉接地方面实现了具有竞争力的性能。更重要的是,LOUPE开辟了一个新的有前途的方向,即从大规模原始图像-文本对中学习细粒度语义。这项工作的存储库位于 https://github.com/YYJMJC/LOUPE。
1介绍
从大规模视觉语言预训练中学习可转移的跨模态表示,在各种下游任务中表现出卓越的性能。现存作品大多可分为两类:双编码器和融合编码器。双编码器方法JIA2021扩展; LI2021监督; 拉德福德2021学习; 姚2021菲利普采用两个独立的编码器嵌入图像和文本,并通过图像和文本的全局特征之间的余弦相似度对跨模态对齐进行建模。虽然这种架构通过离线预计算图像和文本表示来有效地进行大规模图像文本检索,但它们无法对视觉区域和文本短语之间的细粒度语义对齐进行建模。另一方面,融合编码器方法陈2020uniter; 金2021维尔特; LI2021对齐; LI2020奥斯卡; LU2019维尔伯特; QI2020图片伯特; TAN2019LXMERT; SU2019VL系列尝试使用单个多模态编码器对图像和文本的串联序列进行联合建模。这些方法通过高级跨模态注意力模拟软对准瓦斯瓦尼2017注意.然而,他们只能通过端到端训练来学习隐式对齐,缺乏明确的监督来鼓励视觉区域和文本短语之间的语义对齐。学习到的跨模态注意力矩阵通常是分散的和无法解释的。此外,它们的检索效率低下,因为它需要在推理过程中对每个图像-文本对进行联合编码。 从图像-文本预训练中学习细粒度语义对齐对于许多跨模态推理任务(例如,视觉基础)至关重要 yu2016建模、图片说明 XU2015展会),但由于视觉区域和文本短语之间的对齐信息不可用,因此它特别具有挑战性,这使得细粒度语义对齐学习成为弱监督学习问题。在本文中,我们解决了这个问题,同时保持了较高的检索效率,提出了放大镜![]() ,从博弈论的新颖视角来看,一个细粒度的语义L ignedvisiOn-langUage PrE-training 框架。我们将输入的补丁和单词标记表述为多个玩家到一个合作博弈中,并量化博弈论的相互作用(即 Shapley 相互作用 Grabisch1999公理; Shapley1953值),以调查语义对齐信息。LOUPE从两个阶段学习细粒度语义对齐:标记级Shapley交互建模和语义级Shapley交互建模,我们首先学习识别图像的语义区域,这些语义区域对应于一些语义上有意义的实体,然后将这些区域与配对文本中的短语对齐。
,从博弈论的新颖视角来看,一个细粒度的语义L ignedvisiOn-langUage PrE-training 框架。我们将输入的补丁和单词标记表述为多个玩家到一个合作博弈中,并量化博弈论的相互作用(即 Shapley 相互作用 Grabisch1999公理; Shapley1953值),以调查语义对齐信息。LOUPE从两个阶段学习细粒度语义对齐:标记级Shapley交互建模和语义级Shapley交互建模,我们首先学习识别图像的语义区域,这些语义区域对应于一些语义上有意义的实体,然后将这些区域与配对文本中的短语对齐。
具体来说,标记级 Shapley 交互建模旨在将图像的补丁标记分组到语义区域中,这些语义区域在语义上对应于某些视觉实例。从博弈论的角度来看,我们以补丁令牌为玩家,以图像和文本之间的相似度得分为博弈函数。 直观地讲,假设一组补丁标记对应图像中的视觉实例,那么它们往往具有很强的交互性,形成对应实例的完整语义,这有助于更好地判断与配对文本的相似度。 基于这一见解,我们将标记级Shapley交互作为软监督标签,以鼓励模型从图像中捕获语义区域。然后,语义层面的Shapley交互建模推断出语义区域和短语之间的细粒度语义对齐。我们将每个区域和短语视为玩家,并将细粒度的相似度分数定义为游戏函数。如果一个区域和一个短语有很强的对应关系,它们往往会相互作用,并有助于细粒度的相似性分数。通过测量每个区域-短语对之间的Shapley交互作用,我们获得了指导预训练模型的对齐信息。 由于计算精确的Shapley相互作用是一个NP难题松井2001NP,现有方法主要采用基于抽样的方法CASTRO2009多项式以获得无偏的估计。然而,随着玩家数量的增加,他们需要数千个模型评估。为了降低计算成本,我们进一步提出了一种高效的混合Shapley交互学习策略,其中不确定性感知神经Shapley交互学习模块与基于采样的方法协同工作。实验结果表明,该混合策略在保持估计精度的同时,显著节省了计算成本。更多分析见第 4.5 节。
我们的框架用作代理训练目标,明确地在局部区域和短语表示之间建立细粒度的语义对齐。对于下游任务,可以直接删除此代理目标,从而呈现高效且语义敏感的双编码器模型。实验表明,LOUPE在图像文本检索基准上达到了最先进的水平。在MSCOCO上进行文本到图像检索方面,LOUPE在recall@1上比其最强大的竞争对手高出4.2%。此外,无需任何微调,LOUPE就成功地以零样本方式转移到物体检测和视觉接地任务。对于物体检测,它在COCO上实现了12.1%的mAP,在PASCAL VOC上实现了19.5%的mAP。在视觉接地方面,它在 RefCOCO 上实现了 26.8% 的准确度,在 RefCOCO+ 上实现了 23.6% 的准确度。我们的贡献总结如下:
- •
我们建议放大镜
 这显式地学习了视觉区域和文本短语之间的细粒度语义对齐,同时保留了双编码器的高检索效率。
这显式地学习了视觉区域和文本短语之间的细粒度语义对齐,同时保留了双编码器的高检索效率。 - •
我们介绍了一种高效且有效的混合Shapley交互学习策略,该策略基于不确定性感知的神经Shapley交互学习模块和基于采样的方法。
- •
对图像文本数据进行预训练,LOUPE 实现了图像文本检索的新技术,并成功转移到需要更细粒度的对象级视觉理解(即对象检测和视觉基础)的任务中,而无需任何微调。
-
• 由于对大量对象类别进行手动注释既耗时又不可扩展,我们的工作展示了一种很有前途的替代方案,即从有关图像的原始文本中学习细粒度的语义,这些文本很容易获得并包含更广泛的视觉概念。
2相关工作
视觉语言预训练。预训练和微调范式在自然语言处理中的巨大成功Brown2020语言; 德夫林2018伯特和计算机视觉Dosovitskiy2020图片; HE2020势头; WEI2022MVP已扩展到视觉和语言的联合领域安德森2018底部; 安通2015VQA; LI2020无监督.占主导地位的视觉语言预训练模型可分为两类:双编码器和融合编码器。双编码器方法JIA2021扩展; LI2021监督; 拉德福德2021学习; 姚2021菲利普采用两个单独的编码器分别嵌入图像和文本,并通过余弦相似性对跨模态交互进行建模。这种架构对于大规模图像文本检索非常有效,因为图像和文本表示可以离线预先计算。然而,简单地测量全局表示之间的余弦相似性是肤浅的,无法捕获区域和短语之间的细粒度语义关系。 融合编码器方法陈2020uniter; 黄2021看到; 黄2020像素; 金2021维尔特; LI2021对齐; LI2020UNIMO; LI2020奥斯卡; LU2019维尔伯特; QI2020图片伯特; SU2019VL系列; TAN2019LXMERT; yu2020厄尼; 张2021VINVL采用单一的多模态编码器,对图像和文本的串联序列进行联合建模,实现更深层次的跨模态交互。然而,这些方法效率较低,因为图像和文本交织在一起以计算跨模态注意力,并且无法离线预先计算。此外,没有明确的监督信号来鼓励区域和短语之间的一致性。部分作品陈2020uniter; LI2020UNIMO; LI2020奥斯卡; LU2019维尔伯特; TAN2019LXMERT; yu2020厄尼; 张2021VINVL; 钟2022区域剪辑尝试利用现成的对象检测器来提取对象特征以进行预训练。然而,检测器通常在有限的对象类别上进行预训练。 此外,考虑到对内存和计算的过度需求,现有方法通常固定检测模型的参数,并将区域检测视为预处理步骤,与视觉语言预训练脱节。因此,性能也受到检测模型质量的制约。 菲 利 普姚2021菲利普使用标记级最大相似度来增强双编码器方法的跨模态交互。要学习显式细粒度语义对齐,GLIPLI2021停飞和 X-VLM曾2021多利用人工注释的数据集,其中具有边界框注释的区域与文本描述对齐。这种方式非常耗时,并且很难从互联网扩展到更大的原始图像文本数据。 相比之下,我们提出的框架从原始图像-文本数据中显式学习细粒度语义对齐,同时保持了双编码器的高效率。详细讨论可在附录 K. Shapley Values 中找到。Shapley 价值观Shapley1953值最初是在博弈论中引入的。从理论上讲,它已被证明是公平估计每个玩家在合作博弈中的贡献的独特指标,从而满足某些理想的公理Weber1988概率.凭借坚实的理论基础,Shapley值最近被研究为深度神经网络(DNN)的事后解释方法datta2016算法; Lundberg2017统一; 张2020口译.Lundberg等人。 Lundberg2017统一提出一种基于Shapley值的统一归因方法来解释DNN的预测。Ren 等人. REN2021统一建议用Shapley值来解释对抗性攻击。在本文中,我们提出了通过博弈论交互来模拟细粒度语义对齐,以及一种有效的Shapley交互学习策略。
3方法
在本节中,我们首先在第 3.1 节中介绍细粒度语义对齐视觉语言预训练的问题表述。然后,我们在第3.2节中提出了相应的细粒度语义对齐学习的LOUPE框架,并在第3.3节中提出了一种有效的Shapley交互学习方法。
3.1问题表述和模型概述
一般来说,视觉语言预训练旨在学习图像编码器�我和文本编码器�T通过跨模态对比学习,其中匹配的图像-文本对被优化以更接近,不匹配的对被优化以走得更远。让�我(我我)和�T(�我)表示图像和文本的全局表示形式。那么跨模态对比损失可以表述为:
| ℒCMC公司=−日志经验值(�我(我我)⊤�T(�我)/�))∑��经验值(�我(我我)⊤�T(��)/�)−日志经验值(�我(我我)⊤�T(�我)/�))∑��经验值(�我(我�)⊤�T(�我)/�)) | (1) |
哪里�是批大小和�是温度超参数。 虽然很直观,但这种方式只能学习图像和文本之间的粗略对齐,但无法明确捕获视觉区域和文本短语之间的细粒度语义对齐。为了学习细粒度的语义对齐,同时保持高检索效率,我们提出了LOUPE,这是一种从合作博弈论中萌芽的细粒度语义对齐视觉语言预训练框架。 如图 1 所示,LOUPE 从两个阶段学习细粒度语义对齐:标记级 Shapley 交互建模和语义级 Shapley 交互建模。 对于令牌级的Shapley交互建模,我们学习在基于令牌的语义聚合损失的指导下,将图像的补丁标记聚合到语义上对应于某些视觉概念的语义区域ℒ美国运输安全管理局(TSA).在语义层面的Shapley交互建模中,通过细粒度语义对齐损失,学习聚合区域与文本短语之间的语义对齐ℒFSA公司.结合两个新提出的损失,细粒度语义对齐的视觉语言预训练的完整目标可以表述为:
| ℒ=ℒCMC公司+ℒ美国运输安全管理局(TSA)+ℒFSA公司 | (2) |
这种新的预训练目标强制图像编码器捕获语义区域,并在视觉区域和文本短语之间建立细粒度的语义对齐。在推理过程中,可以直接将其删除,从而呈现出高效且语义敏感的双编码器。

图 1:LUUPE概述。我们的框架作为一个代理训练目标,鼓励图像编码器捕获语义区域,并在区域和短语表示之间建立语义对齐。对于下游任务,可以轻松删除代理训练目标,从而呈现高效且语义敏感的双编码器。
3.2将细粒度语义对齐解释为博弈论交互
3.2.1预赛
Shapley 价值观。Shapley 价值观Shapley1953值是一种经典的博弈论解决方案,用于对合作博弈中每个参与者的重要性或贡献进行公正的估计。考虑一款带有={1,...,�}球员⊆表示潜在的玩家子集。游戏�(⋅)作为映射每个子集的函数实现的玩家得分,当玩家在参与。具体说来�()−�(∅)表示游戏中所有玩家获得的贡献。Shapley 价值观�(我|)对于玩家我定义为玩家的平均边际贡献我所有可能的联盟在没有我:
| �(我|)=∑⊆∖{我}�()[�(∪{我})−�()],�()=||!(||−||−1)!||! | (3) |
哪里�()是正在采样。Shapley 值已被证明是满足以下公理的唯一指标:线性、对称性、假人和效率 Weber1988概率.我们在附录 B. Shapley 相互作用中总结了这些公理。在博弈论中,一些玩家倾向于结成联盟,总是一起参与游戏。联盟中的玩家可能会相互互动或合作,这为游戏带来了额外的贡献。Shapley互动Grabisch1999公理与球员单独工作的情况相比,衡量联盟带来的这种额外贡献。对于联盟,我们考虑[]作为一个单一的假设玩家,这是玩家的联合.然后,通过删除从游戏中添加[]到游戏中。Shapley 价值观�([]|∖∪{[]})对于玩家[]可以使用公式 3 在简化博弈中计算。同样,我们可以获得�(我|∖∪{我})哪里我是个人玩家�.最后,沙普利联盟的互动配方如下:
| 我([])=�([]|∖∪{[]})−∑我∈�(我|∖∪{我}) | (4) |
这样,我([])反映内部的互动.较高的值我([])表示玩家在彼此密切合作。
3.2.2代币级 Shapley 交互建模
由于文本和图像之间固有的语义单元不匹配,直接计算单词和像素(补丁)之间的对齐方式是无效的。文本短语通常是指特定的图像区域,该区域由多个色块组成,代表一个视觉实例。因此,我们首先引入令牌级 Shapley 交互建模,将补丁聚合到语义区域。输入表示。给定一个图像-文本对,输入图像我被切成斑块并压平。然后是线性投影层和位置嵌入,我们得到了补丁令牌序列我={我我}我=1�1具有额外的令牌嵌入。输入文本[CLS_I]�被标记化并嵌入到单词标记序列中�={我�}我=1�2,添加了位置嵌入。我们还在单词标记序列中预置了一个可学习的特殊标记。然后,采用双编码器结构分别对patch token序列和word token序列进行编码。在图像和文本编码器之上,我们获得了补丁令牌序列的表示[CLS_T]~我={~我我}我=1�~1和单词标记序列~�={~我�}我=1�~2.我们将学习到的表示和标记作为图像和文本的全局表示。图像-文本对的全局相似性是通过它们之间的余弦相似度来衡量的。[CLS_I][CLS_T]
通过Shapley交互理解语义区域。假设一组斑块代表了图像中一个完整的视觉实例,那么它们往往具有很强的Shapley相互作用,因为它们共同作用形成一个视觉实例,这有助于更好地判断与文本的相似性。从博弈论的角度来看,我们以补丁标记和单词标记作为玩家=我∪�,以及图像和文本之间的全局相似性作为游戏分数�1(⋅).计算�1(),我们将令牌保存在并屏蔽输入标记∖到零。因此,全局相似性仅考虑,这反映了代币的贡献到全局相似性判断。
语义区域生成。受 YOLOv3 启发 2018YOLOv3,我们设计了一个轻量级的区域生成模块。它采用每个补丁令牌表示形式~我我作为输入并生成以~我我,对应于视觉区域ℛ我={我,�我}�=1�我跟�我补丁令牌。区域生成模块还可以预测置信度分数�(ℛ我)对于每个区域。我们选择顶部�预测作为语义区域。然后,Shapley的相互作用ℛ我可以定义为:
| 我([ℛ我])=�([ℛ我]|�∖ℛ我∪{[ℛ我]})−∑我,�我∈ℛ我�(我,�我|∖ℛ我∪{我,�我}) | (5) |
根据等式 3,我们可以将 Shapley 值重新表述为期望的形式:
| �([ℛ我]|∖ℛ我∪{[ℛ我]})=�{⊆∖ℛ我||=�[�1(∪ℛ我)−�1()]} | (6) |
哪里�代表联盟规模。�(我,�我|�∖ℛ我∪{我,�我})可以用类似的方式定义,并且ℛ我可以重新表述为(我们在附录 C 中提供证明):
| 我([ℛ我])=�{⊆∖ℛ我||=�[�1(∪ℛ我)−∑我,�我∈ℛ我�1(∪{我,�我})+(�−1)�1()]} | (7) |
服用归一化我′([�我])作为软监督标签,基于令牌的语义聚合损失被定义为交叉熵损失:
| ℒ美国运输安全管理局(TSA)=−1�∑我=1�[我′([ℛ我])日志(�(ℛ我))+(1−我′([ℛ我]))日志(1−�(ℛ我))] | (8) |
它将梯度传播到区域生成模块和图像编码器,以调整边界框预测,从而捕获更准确的语义区域。
3.2.3语义级 Shapley 交互建模
在获得推断的语义区域后,我们提出了语义层面的Shapley交互建模,以显式地模拟区域和短语之间的细粒度语义对齐。我们首先定义细粒度相似度得分,然后基于博弈论解释语义对齐。 我们在每个Avg-Poolingℛ我获取区域表示形式我我∈ℝ�.我们使用现成的选区解析器从文本中提取短语并获得短语表示我�∈ℝ�由。总的来说,我们获得了Avg-Pooling�地区ℋ我={我我}我=1�和�短语ℋ�={��}�=1�.对齐矩阵可以定义为:一个=[一个我�]�×�哪里一个我�=我我⊤��表示我-th region 和�-th短语。接下来,我们将 softmax-normalization 应用于一个获得一个~.对于我-th 区域,我们将其最大对齐分数计算为麦克斯�一个~我�.然后,我们使用所有区域的平均最大对齐分数作为细粒度图像与文本的相似度�1.同样,我们可以获得细粒度的文本与图像的相似度�2,并且可以定义总的细粒度相似度分数:�=(�1+�2)/2.通过Shapley交互理解语义对齐。如果一个区域和一个短语具有很强的语义对应关系,那么它们往往会相互合作,并有助于细粒度的相似性分数。因此,我们可以考虑ℋ=ℋ我∪ℋ�作为玩家和细粒度相似度得分�作为游戏得分�2(⋅).它们的Shapley相互作用可以表述为:
| 我([ℋ我�]) | =�([ℋ我�]|ℋ∖ℋ我�∪{[ℋ我�]})−�(我我|ℋ∖ℋ我�∪{我我})−�(��|ℋ∖ℋ我�∪{��}) | (9) | ||
| =�{⊆ℋ∖ℋ我�||=�[�2(∪ℋ我�)−�2(∪{我我})−�2(∪{��})+�2()]} | (10) |
哪里[ℋ我�]代表由联盟组成的单一玩家我-th region 和�-th短语。服用归一化我′([ℋ我�])作为软标签,细粒度语义对齐损失可以定义为:
| ℒFSA公司=−1��∑我=1�∑�=1�我′([ℋ我�])日志(一个~我�) | (11) |
3.3不确定性感知神经Shapley交互学习
根据等式 3 和等式 4,精确计算 Shapley 值是一个 NP 难题松井2001NP.以前的方法主要采用基于抽样的方法CASTRO2009多项式来近似它。虽然基于抽样的近似是无偏的,但准确的近似需要数千次模型评估。为了降低计算成本,我们提出了一种不确定性感知神经Shapley交互学习(UNSIL)模块,与基于采样的方法配合,提供了一种高效且有效的混合策略。 具体来说,基于抽样的方法CASTRO2009多项式通过抽样来估计等式 7 和等式 10 中的期望项,以计算 Shapley 相互作用。灵感来自嘈杂的标签学习Kendall2017不确定性,联塞综合行动模块学习预测Shapley相互作用和相应的不确定性�∈(0,1).直观地说,如果联塞综合活动模块做出的预测不确定性较低,我们可以直接将其预测应用于ℒ美国运输安全管理局(TSA)和ℒFSA公司,避免了数千次模型评估。如果不确定性很高,我们就会采用基于抽样的方法进行更准确的估计。 在训练期间,联塞综合活动模块首先预测具有不确定性的目标相互作用�.然后,我们对一个值进行采样�从均匀分布(0,1).如果�>�,我们直接使用它的预测。如果�≤�,然后我们使用基于抽样的方法计算Shapley相互作用,并根据基于抽样的结果更新UNSIL模块。请注意,在前几次迭代中,我们直接采用基于采样的方法,并使用其结果来训练 UNSIL 模块。
让我*和我^分别表示基于抽样的方法和联塞综合体模块的结果。采取我*作为基本事实,联塞综合活动模块由以下人员训练:
| ℒ联塞综合会议=1�1�ℒMSE的(我^,我*)+�2� | (12) |
其中第一项是均方误差ℒMSE的根据不确定性加权,第二项作为预测不确定性的正则化项,并且�是权重超参数。联塞综合行动模块隐式地从回归损失函数中学习不确定性。我们在第 4.5 节和附录 D 中讨论了联塞综合会议模块的实施细节。
4实验
4.1训练前详情
由于足够的数据是视觉语言预训练的先决条件,我们构建了一个来自互联网的 240M 图像文本对的数据集。我们通过 Swin-L 实现图像编码器刘2021Swin以及 BERT-Small 的文本编码器德夫林2018伯特.输入图像的大小调整为224×224输入文本由 WordPiece 标记化,最大长度为 60。我们在 128 个 NVIDIA V100 GPU 上使用 512 个批处理大小对模型预训练了 20 个 epoch。我们利用 AdamWLoshchilov2017解耦学习率为2×10−4权重衰减为0.01。附录 D、E 中提供了更多培训前和评估详细信息。我们还在附录 G、J 中分析了图像编码器和训练效率。
表 1:Flickr30K 和 MSCOCO 数据集上零样本图像文本检索的结果 (%)。
| Flickr30K的 | MSCOCO公司 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 图像到文本 | 文本到图像 | 图像到文本 | 文本到图像 | |||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| 图像BERT | 70.7 | 90.2 | 94.0 | 54.3 | 79.6 | 87.5 | 44.0 | 71.2 | 80.4 | 32.3 | 59.0 | 70.2 |
| 统一 | 83.6 | 95.7 | 97.7 | 68.7 | 89.2 | 93.9 | - | - | - | - | - | - |
| 夹 | 88.0 | 98.7 | 99.4 | 68.7 | 90.6 | 95.2 | 58.4 | 81.5 | 88.1 | 37.8 | 62.4 | 72.2 |
| 對齊 | 88.6 | 98.7 | 99.7 | 75.7 | 93.8 | 96.8 | 58.6 | 83.0 | 89.7 | 45.6 | 69.8 | 78.6 |
| 菲 利 普 | 89.8 | 99.2 | 99.8 | 75.0 | 93.4 | 96.3 | 61.3 | 84.3 | 90.4 | 45.9 | 70.6 | 79.3 |
| 放大镜 | 90.5 | 99.5 | 99.8 | 76.3 | 93.9 | 96.7 | 62.3 | 85.1 | 91.2 | 50.1 | 75.4 | 83.3 |
表2:在 11 个数据集上零样本图像分类的 Top-1 准确率 (%)。
|
CIFAR10 |
食物101 |
斯坦福汽车 |
孙氏397 |
鲜花102 |
国家211 |
FER2013 |
飞机 |
牛津宠物 |
加州理工学院101 |
图像网 |
平均 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 夹 | 96.2 | 92.9 | 77.3 | 67.7 | 78.7 | 34.9 | 57.7 | 36.1 | 93.5 | 92.6 | 75.3 | 73.0 |
| 放大镜 | 95.9 | 94.3 | 79.9 | 69.8 | 87.4 | 37.8 | 53.3 | 54.9 | 94.1 | 93.9 | 76.1 | 76.1 |
4.2零样本图像文本检索
我们比较了广泛使用的 MSCOCO 上的 LOUPELIN2014微软和 Flickr30Kplummer2015flickr30k数据。首先,表 1 中的结果表明,LOUPE 在两个数据集的大多数指标上都实现了最先进的零样本性能,证明了我们的预训练框架具有更强的泛化性。其次,虽然以前的工作主要在较大的数据集(CLIP 400M、ALIGN 1800M、FILIP 340M)上进行预训练,但 LOUPE 仍然使用更少的训练数据 (240M) 实现了卓越的性能。第三,与直接计算标记相似度的FILIP相比,我们的模型捕获了视觉区域和文本短语之间的语义对齐,这在语义上更具意义。对于MSCOCO上的文本到图像检索,LOUPE在recall@1上的表现明显优于FILIP4.2%。
4.3零样本图像分类
在本节中,我们将评估零样本图像分类任务的 LOUPE。我们在 11 个下游分类数据集上比较了 LOUPE 和 CLIP,遵循与 CLIP 相同的评估设置拉德福德2021学习.结果如表2所示。如表2所示,我们的LOUPE优于CLIP,平均改善3.1%。值得注意的是,在 11 个数据集中最大的数据集 ImageNet 上,我们的 LOUPE 比 CLIP 高出 0.8%。此外,我们观察到 LOUPE 在几个细粒度图像分类数据集(即 Flowers102 和 Aircrafts)上实现了显着的性能提升。它证明了我们的LOUPE在细粒度语义理解方面的优越性。 我们还评估了LOUPE在图像分类上的线性探测性能。详细结果见附录I。
表 3:无需微调,物体检测和视觉接地的零样本传输性能。
| 可可 | 帕斯卡挥发性有机化合物 | RefCOCO公司 | RefCOCO+系列 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| [email protected] | [email protected] | [email protected] | [email protected] | 瓦尔 | 种皮 | 测试B | 瓦尔 | 种皮 | 测试B | |
| CLIP + 像素 | 8.5 | 4.5 | 18.2 | 7.3 | 6.7 | 6.2 | 5.8 | 6.1 | 7.0 | 5.7 |
| CLIP + K-均值 | 6.4 | 1.9 | 11.7 | 4.8 | 2.1 | 2.3 | 1.7 | 1.7 | 2.0 | 2.8 |
| CLIP + 渐变凸轮 | 7.1 | 3.2 | 19.1 | 8.2 | 5.5 | 5.2 | 4.8 | 4.4 | 5.6 | 4.9 |
| 适应夹 | 14.9 | 6.6 | 28.7 | 12.9 | 16.7 | 18.4 | 18.0 | 17.5 | 18.9 | 19.6 |
| 放大镜 | 25.3 | 12.1 | 30.3 | 19.5 | 25.2 | 26.8 | 24.5 | 22.9 | 23.3 | 23.6 |

图 2:使用提示模板将 LOUPE 零样本传输到对象检测的示例。
4.4零样本传输至物体检测和视觉接地
为了回答我们的模型是否学习了细粒度语义,我们进一步评估了对象检测的 LOUPEREN2015更快和视觉接地yu2016建模,这需要更细粒度的语义理解能力,根据对象标签或指称表达式识别图像中的特定视觉区域。 视觉基础可以看作是广义的对象检测,其中预定义的类标签被引用表达式句子的语言所取代。由于 LOUPE 可以生成一组与文本短语对齐的语义区域,因此它可以轻松应用于对象检测和视觉基础,而无需修改结构。为了视觉基础,我们将引用表达式作为输入文本。对于对象检测,如图 2 所示,我们使用 prompt 将检测标签展开为输入文本。然后,我们通过学习到的文本编码器对输入文本进行编码,通过测量候选区域表示和文本表示之间的相似性来完成这些任务。 为了进行比较,我们通过在CLIP的空间特征图上应用几种非参数方法,将CLIP(ViT-L/14)零样本转移到目标检测和视觉接地。我们还与 AdaptCLIP 进行了比较LI2022适应,这是一种同时未发布的方法,它利用了经典的超级像素(SLIC阿昌塔2012SLIC) 和边界框建议(选择性搜索UIJLINGS2013选择性) 方法将 CLIP 转换为短语本地化。我们使用其公开的官方实现来获得实验结果。对于目标检测,我们在 IoU 阈值{0.3,0.5}在COCO上LIN2014微软(65 级)和 PASCAL VOC埃弗林厄姆2008帕斯卡(20节课)。对于视觉基础,我们在 RefCOCO 上评估了它们在 IoU 阈值为 0.5 时的前 1 精度yu2016建模和 RefCOCO+yu2016建模.CLIP变体和LOUPE的实验细节见附录E。 表 3 总结了结果。1) 总体而言,LOUPE 的性能大大优于所有 CLIP 变体。显著更高的性能说明了我们细粒度语义对齐的预训练范式更强的零样本迁移能力。2)其次,所有CLIP变体都依赖于CLIP特征图上的预处理步骤(例如,AdaptCLIP首先使用SLIC对像素进行分组,然后使用选择性搜索生成大量提案),这非常耗时。相比之下,我们的方法基于补丁标记表示直接预测语义区域。3)第三,在四个基准测试中始终如一的竞争性能验证了LOUPE可以从原始文本监督中学习细粒度语义。LOUPE展示了一种很有前途的替代方案,即从大规模的原始图像文本对中学习细粒度的语义,这些文本对很容易获得,并且包含更广泛的视觉概念集。 由于耗时的人工注释对于现实世界中的大量对象类是不可扩展的,因此最近的一些工作班萨尔2018零; 拉赫曼2020改进目标是训练对象检测器,对基本对象类进行注释,以泛化到同一数据集的其余对象类。最新作品GU2021开放; Zareian2021开放 leverage the generalizability of vision-language pre-training models to further improve the zero-shot performance on novel classes. However, these zero-shot approaches still require bounding box annotations on base classes for task-specific supervised learning. In contrast, our LOUPE is trained on large-scale raw image-text pairs, which are already accessible on the Internet and contain more diverse semantics.
Table 4:Ablation study of each component across three tasks.
| MSCOCO | COCO | RefCOCO | Training Time | ||||||
|---|---|---|---|---|---|---|---|---|---|
| I2T | T2I | [email protected] | [email protected] | val | testA | testB | (sec/iter) | ||
| 1 | Backbone | 31.0 | 24.8 | 3.8 | 1.0 | 1.3 | 0.9 | 0.8 | 1.17 |
| 2 | Backbone + ℒTSA | 32.4 | 26.2 | 7.6 | 3.3 | 1.8 | 2.0 | 2.6 | 8.38 |
| 3 | Backbone + ℒTSA + ℒFSA | 33.5 | 28.3 | 9.4 | 5.9 | 4.1 | 4.6 | 4.3 | 9.90 |
| 4 | Backbone + ℒTSA + ℒFSA + UNSIL | 33.3 | 28.1 | 9.0 | 5.6 | 4.5 | 4.9 | 4.4 | 1.93 |

Figure 3:(a) Instability of the Shapley interaction approximation with respect to different sampling numbers. (b, c) Uncertainty and error of the UNSIL module with different structures.
4.5Ablation Study
Effectiveness of Individual Components. In this section, we investigate the effectiveness of each component in Table 4. Given the costly training time, all ablation studies are based on a relatively small dataset (Conceptual Captions 3M 2018Conceptual). We start with the backbone model that consists of a dual-encoder trained by cross-modal contrastive loss. We then gradually add token-level Shapley interaction modeling supervision ℒTSA (Row 2), semantics-level Shapley interaction modeling supervision ℒFSA (Row 3), and UNSIL module (Row 4). For Row 2 and Row 3, the Shapley interaction is only computed by the sampling-based method. The results in Table 4 show that both ℒTSA and ℒFSA bring significant improvement for all tasks. We observe that ℒTSA boosts a 3.8% improvement on object detection. And the improved fine-grained visual semantic understanding further facilitates the cross-modal retrieval performance (+1.4%). The semantics-level Shapley interaction modeling further improves the performance on all tasks by modeling the semantic alignment between visual regions and textual phrases. Comparing Row 3 and Row 4, we observe that the UNSIL module maintains the estimation accuracy while avoiding intensive computations. The averaged training time is reduced from 9.90 seconds per iteration to 1.93 seconds per iteration. Accuracy of the Shapley Interaction Learning. Since we use the sampling-based method castro2009polynomial to compute the Shapley Interaction and train the UNSIL module, we conduct a study to evaluate the accuracy of the sampling-based method and the error of the UNSIL module. As zhang2020interpreting, we compute the interaction multiple times and measure the instability of them. A lower instability means that we obtain similar interactions from different sampling processes. It indicates a high accuracy. Specifically, the instability is defined as �,�:�≠�|ℑ�−ℑ�|�|ℑ�|, where ℑ� denotes the interaction computed in the �-th time. We average the instability values over Shapley interaction of 100 image-text pairs. We report the average instability values with respect to different sampling numbers. As shown in Figure 3 (a), the instability decreases along with the increase of the sampling number. When the sampling number is larger than 500, the approximated Shapley interaction is stable enough with instability less than 0.06. Further, we attempt different models (i.e., Conv1D, 3-Layer MLP + Attention, 3-Layer Transformer) to implement the UNSIL module (please see Appendix D for more details). We test them on 1000 samples and report their mean uncertainty and relative error in Figure 3 (b) and (c). We observe that MLP + Attention is good enough to predict the interaction with lower complexity. Thus, we implement the UNSIL module by MLP + Attention.

Figure 4:Qualitative examples of object detection on COCO and visual grounding on RefCOCO+.

Figure 5:Visualization of learned fine-grained semantic alignment and corresponding Shapley interaction values. The values in the red boxes represent the Shapley interaction of regions.
4.6Qualitative Analysis
Qualitative Examples. As shown in Figure 4, LOUPE successfully captures the regions that correspond to the detected objects, and grounds the referring expressions onto the referred regions. Visualization of Learned Fine-Grained Semantic Alignment. In Figure 5, we visualize some key semantic regions and corresponding alignment matrices inferred by LOUPE. We present the regions with top-3 confidence (Region 1 – 3) and two randomly sampled regions (white boxes). The red boxes at the bottom of bounding boxes indicate their normalized token-level Shapley interaction values. Comparing their Shapley interaction values, we observe that the token-level Shapley interaction successfully distinguishes semantic regions from randomly sampled regions. The semantically meaningful regions tend to have stronger interaction. It indicates that token-level Shapley interaction can provide correct supervision for semantic region generation. Further, we show the alignment matrices inferred by semantics-level Shapley interaction and LOUPE, respectively. As shown in the right case of Figure 5, LOUPE successfully recognizes the leash region ![]() and aligns it with the “a leash” phrase. Note that existing object detection datasets do not contain the “leash” category.
and aligns it with the “a leash” phrase. Note that existing object detection datasets do not contain the “leash” category.
5Conclusion
This paper introduces a novel vision-language pre-training framework, LOUPE![]() , which models the fine-grained semantic alignment between visual regions and textual phrases by game-theoretic interactions. To efficiently compute the interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Comprehensive experiments show that LOUPE achieves new state-of-the-art on image-text retrieval datasets and can transfer to object detection and visual grounding in a zero-shot manner. This work demonstrates a new promising direction of learning fine-grained semantics from large-scale raw image-text data. Limitations. 1) The phrases are extracted by off-the-shelf constituency parsers, whose predictions might not be completely accurate. 2) The web data might inevitably contain mismatched image-text pairs, leading to noisy supervision. Social Impacts. Our model is trained on noisy data from the Internet, which may contain unsuitable images, violent text, or private information. Thus, additional analysis of the data is necessary. Further, the use of our model for privacy surveillance or other nefarious purposes should be prohibited. Acknowledgment. This work has been supported in part by the National Key Research and Development Program of China (2018AAA0101900), Zhejiang NSF (LR21F020004), Key Research and Development Program of Zhejiang Province, China (No. 2021C01013), Chinese Knowledge Center of Engineering Science and Technology (CKCEST). We thank all the reviewers for their valuable comments.
, which models the fine-grained semantic alignment between visual regions and textual phrases by game-theoretic interactions. To efficiently compute the interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Comprehensive experiments show that LOUPE achieves new state-of-the-art on image-text retrieval datasets and can transfer to object detection and visual grounding in a zero-shot manner. This work demonstrates a new promising direction of learning fine-grained semantics from large-scale raw image-text data. Limitations. 1) The phrases are extracted by off-the-shelf constituency parsers, whose predictions might not be completely accurate. 2) The web data might inevitably contain mismatched image-text pairs, leading to noisy supervision. Social Impacts. Our model is trained on noisy data from the Internet, which may contain unsuitable images, violent text, or private information. Thus, additional analysis of the data is necessary. Further, the use of our model for privacy surveillance or other nefarious purposes should be prohibited. Acknowledgment. This work has been supported in part by the National Key Research and Development Program of China (2018AAA0101900), Zhejiang NSF (LR21F020004), Key Research and Development Program of Zhejiang Province, China (No. 2021C01013), Chinese Knowledge Center of Engineering Science and Technology (CKCEST). We thank all the reviewers for their valuable comments.
Appendix AAppendix Overview
In this appendix, we present:
- •
Axiomatic Properties of Shapley Value (Section B).
- •
Proofs of Equation 7 and Equation 10 (Section C).
- •
Hyperparameters and Implementation Details (Section D).
- •
Pre-Training and Evaluation Details (Section E).
- •
More Experiment Results on Downstream Vision-Language Generation Task (Section F).
- •
Further Analysis on the Image Encoder (Section G).
- •
More Qualitative Examples on Object Detection and Visual Grounding (Section H).
- •
Linear Probing Evaluation (Section I).
- •
Training Efficiency Discussion (Section J).
- •
Detailed Discussion with Some Related Works (Section K).
Appendix BAxiomatic Properties of Shapley Value
In this section, we mainly introduce the axiomatic properties of Shapley value. Weber et al. weber1988probabilistic have proved that Shapley value is the unique metric that satisfies the following axioms: Linearity, Symmetry, Dummy, and Efficiency. Linearity Axiom. If two independent games � and � can be linearly merged into one game �()=�()+�(), then the Shapley value of each player �∈ in the new game � is the sum of Shapley values of the player � in the game � and �, which can be formulated as:
| ��(�|)=��(�|)+��(�|) | (13) |
Symmetry Axiom. Considering two players � and � in a game �, if they satisfy:
| ∀∈∖{�,�},�(∪{�})=�(∪{�}) | (14) |
then ��(�|)=��(�|). Dummy Axiom. The dummy player is defined as the player that has no interaction with other players. Formally, if a player � in a game � satisfies:
| ∀∈∖{�},�(∪{�})=�()+�({�}) | (15) |
then this player is defined as the dummy player. In this way, the dummy player � has no interaction with other players, i.e., �({�})=��(�|). Efficiency Axiom. The efficiency axiom ensures that the overall reward can be assigned to all players, which can be formulated as:
| ∑�∈��(�)=�()−�(∅) | (16) |
Appendix CProofs of Equation 7 and Equation 10
In this section, we provide detailed proofs for Equation 7 in Section 3.2.2 and Equation 10 in Section 3.2.3. We first provide proof for Equation 7. The token-level Shapley interaction for ℛ� can be decomposed as follows:
| ℑ([ℛ�]) | =�([ℛ�]|�∖ℛ�∪{[ℛ�]})−∑�,��∈ℛ��(�,��|∖ℛ�∪{�,��}) | (17) | ||
| =�{⊆∖ℛ�||=�[�1(∪ℛ�)−�1()]}−∑�,��∈ℛ��{⊆∖ℛ�||=�[�1(∪{�,��})−�1()]} | (18) | |||
| =�{⊆∖ℛ�||=�[�1(∪ℛ�)−�1()]}−�{⊆∖ℛ�||=�[∑�,��∈ℛ�(�1(∪{�,��})−�1())]} | (19) | |||
| =�{⊆∖ℛ�||=�[�1(∪ℛ�)−�1()−∑�,��∈ℛ�(�1(∪{�,��})−�1())]} | (20) | |||
| =�{⊆∖ℛ�||=�[�1(∪ℛ�)−�1()−∑�,��∈ℛ��1(∪{�,��})+∑�,��∈ℛ��1()]} | (21) | |||
| =�{⊆∖ℛ�||=�[�1(∪ℛ�)−∑�,��∈ℛ��1(∪{�,��})+(�−1)�1()]} | (22) |
We then provide proof for Equation 10. The semantics-level Shapley interaction between region � and phrase � can be decomposed as follows:
| ℑ([ℋ��]) | =�([ℋ��]|ℋ∖ℋ��∪{[ℋ��]})−�(��|ℋ∖ℋ��∪{��})−�(��|ℋ∖ℋ��∪{��}) | (23) | ||
| =�{⊆ℋ∖ℋ��||=�[�2(∪ℋ��)−�2()]}−�{⊆ℋ∖ℋ��||=�[�2(∪{��})−�2()]} | (24) | |||
| −�{⊆ℋ∖ℋ��||=�[�2(∪{��})−�2()]} | (25) | |||
| =�{⊆ℋ∖ℋ��||=�[�2(∪ℋ��)−�2(∪{��})−�2(∪{��})+�2()]} | (26) |
Table 5:A summary of various hyperparameters in LOUPE.
| Hyperparameter | Value |
| Image Encoder - Swin-L | |
| input image size | 224×224 |
| \hdashlinestage 1 - patch size | 4×4 |
| stage 1 - hidden size | 192 |
| stage 1 - window size | 7×7 |
| stage 1 - number of heads | 6 |
| \hdashlinestage 2 - patch size | 8×8 |
| stage 2 - hidden size | 384 |
| stage 2 - window size | 7×7 |
| stage 2 - number of heads | 12 |
| \hdashlinestage 3 - patch size | 16×16 |
| stage 3 - hidden size | 768 |
| stage 3 - window size | 7×7 |
| stage 3 - number of heads | 24 |
| \hdashlinestage 4 - patch size | 32×32 |
| stage 4 - hidden size | 1536 |
| stage 4 - window size | 7×7 |
| stage 4 - number of heads | 48 |
| Text Encoder - BERT-Small | |
| maximum length of word tokens | 60 |
| vocabulary size | 30522 |
| attention dropout probability | 0.1 |
| hidden activation function | GELU |
| hidden dropout probability | 0.1 |
| initializer range | 0.02 |
| intermediate size | 2048 |
| layer norm eps | 1�−12 |
| hidden size | 512 |
| number of attention heads | 8 |
| number of hidden layers | 4 |
| Pre-Training | |
| number of epochs | 20 |
| batch size | 512 |
| learning rate | 2e-4 |
| learning schedule | OneCycle |
| cycle momentum | Ture |
| base momentum | 0.85 |
| max momentum | 0.95 |
| AdamW weight decay | 0.01 |
| AdamW �1 | 0.9 |
| AdamW �2 | 0.999 |
Appendix DHyperparameters and Implementation Details
In this section, we summarize the hyperparameters in our LOUPE model in Table 5, including the hyperparameters of the image encoder, text encoder, and pre-training process. For the uncertainty-aware neural Shapley interaction learning module, we attempt three kinds of models (i.e., Conv1D, 3-Layer MLP + Attention, 3-Layer Transformer) to implement it for token-level and semantics-level Shapley interaction approximation. For token-level Shapley interaction approximation, it takes the patch token sequence �={��}�=1�1, word token sequence �={��}�=1�2, and the visual region ℛ�={�,��}�=1�� as input, and estimates the corresponding token-level Shapley interaction value for ℛ� along with the uncertainty �. Conv1D model first performs over learned patch representations of Avg-Poolingℛ� to obtain the region representation ��, and then fuse the word and patch token representations with the region representation ��, respectively. Specifically, we project them into an unified semantic space by fully-connected layers and then fuse them through Hadamard product as:
| ℱ�=(1��1�)⊙(2�) | (27) |
where 1 and 2 are the learnable projection parameters, 1� is the transpose of an all-ones vector, and ⊙ represents Hadamard product. We can obtain ℱ� in a similar manner. Then, we apply 1D convolution operation with kernel size = 4 and stride = 2 over ℱ� and ℱ�, respectively. Following with operation, we obtain Max-Pooling~�∈ℝ� and ~�∈ℝ�. Next, we concatenate them with �� and feed them to two separate 1-layer fully connected layers to get the Shapley interaction estimation and corresponding uncertainty. 3-Layer MLP + Attention model first performs over learned patch representations of Avg-Poolingℛ� to obtain the region representation ��. Then, we use �� as the query to attend the patch token sequence and compute a weighted sum of the patch token representations as:
| �~��= | 3(���ℎ(4��+5��)) | (28) | ||
| ��= | �������([�~1�,…,�~�1�]) | (29) | ||
| �= | ∑�=1����� | (30) |
Where �1 is the number of patch tokens. We can obtain � for word token sequence in a similar manner. Consequently, we concatenate them and �� and feed them to two separate 3-layer fully connected layers to get the Shapley interaction estimation and corresponding uncertainty. 3-Layer Transformer model takes the concatenated sequence � and � as input. We add position embeddings and three kinds of token type embeddings (i.e., word token, context patch token, region patch token) to them. We then apply three layers of transformer blocks to jointly encode the input sequence and take the output token to predict the Shapley interaction estimation and corresponding uncertainty, separately. For semantics-level Shapley interaction approximation, it takes the [CLS]� regions ℋ�={��}�=1�, � phrases ℋ�={��}�=1�, and the target region-phrase pair <��,��> as input, and estimates the corresponding semantics-level Shapley interaction value for <��,��> along with the uncertainty �. The architectures of the three models are consistent with their token-level implementations.
Appendix EPre-Training and Evaluation Details
E.1Pre-Training Dataset Details
As recent works jia2021scaling; radford2021learning; yao2021filip have shown that pre-training models can obtain great performance gain by scaling up the dataset, we construct a large-scale dataset, which consists of 240 million image-text pairs and covers a broad set of visual concepts. Concretely, we elaborate more details in the following. Raw image-text pair collection. We first harvest large-scale noisy image-text pairs from the web and design multiple filtering rules to improve the quality of the web data. Image-based filtering. Following ALIGN jia2021scaling, we remove pornographic images and keep only images where both dimensions are larger than 200 pixels. Also, we remove the images whose aspect ratio is larger than 10. To prevent from leaking testing data, we remove the images that appear in all downstream evaluation datasets (e.g., MSCOCO, Flickr30K). Text-based filtering. We remove the repeated captions and keep only English texts. The texts that are shorter than 3 words or longer than 100 words are discarded. As ALIGN jia2021scaling, we also remove the texts that contain any rare token (outside of 100 million most frequent unigrams and bigrams from the raw dataset). Joint image-text filtering. Although the above filtering rules have filtered out many noisy data, it is hard to detect the mismatched image-text pairs, where the texts do not accurately describe the visual content of the images, resulting in undesirable noisy signals to vision-language pre-training. Inspired by BLIP li2022blip, we train a discriminator as a filtering model to predict whether the text is matched to the image. Specifically, the filtering model consists of an image encoder and an image-grounded text encoder, which takes the cross-attention to fuse image features and text features. The filtering model is trained on CC12M dataset using image-text contrastive loss and image-text matching loss.
E.2Evaluation Details
Zero-Shot Image-Text Retrieval. We evaluate the zero-shot performance of LOUPE on the image-text retrieval task over the widely used Flickr30K plummer2015flickr30k and MSCOCO lin2014microsoft datasets. The image-text retrieval consists of two subtasks: image-to-text retrieval and text-to-image retrieval, where a model is required to identify an image from candidates given a caption describing its content, or vice versa. The MSCOCO dataset consists of 123,287 images, and each image is aligned with five captions. The Flickr30K dataset contains 31,783 images and five captions for each image. Following previous works jia2021scaling; yao2021filip, we evaluate the zero-shot performance on the 1K and 5K test sets of Flickr30K and MSCOCO, respectively. We take the final representation of tokens as the global representations of images and texts, and use them to measure the image-text similarity. We first compute the similarity scores for all image-text pairs. Then, we take the top-K candidates for ranking and report the top-K retrieval results. Zero-Shot Transfer to Object Detection. Without any fine-tuning, we evaluate the zero-shot transfer performance of LOUPE on the object detection task [CLS]ren2015faster over the COCO lin2014microsoft and PASCAL VOC everingham2008pascal datasets. For the COCO Objects dataset, we use their 2017 validation split for evaluation. Previous zero-shot object detection models bansal2018zero; rahman2020improved; zhu2020don follow the split proposed by bansal2018zero, which consists of 48 base classes and 17 novel classes. They train models on base classes and evaluate models on novel classes. Differently, we directly evaluate the zero-shot transfer performance on both the base and novel classes, without fine-tuning on the base classes. Totally, we evaluate models on 4,836 test images that contain 33,152 instances of 65 classes. PASCAL VOC is a widely used object detection dataset, which contains 20 object classes. For PASCAL VOC, we evaluate models on 9657 instances of 5072 images. To complete object detection, we first use the region generation module to generate a set of candidate regions and then use prompt text (i.e., an image of [object class name].) to expand each detection label to a sentence. Next, we encode sentences for each object class by the learned text encoder and measure their similarity with the candidate regions as the classification scores. Following most zero-shot object detection methods, we use mean Average Precision (mAP) at IoU of {0.3,0.5} as evaluation metrics. Zero-Shot Transfer to Visual Grounding. Visual grounding yu2016modeling (also known as phrase localization and referring expression comprehension) aims to locate a specific visual region of the input image, according to the language referring expression. Visual grounding can be seen as generalized object detection, where the pre-defined class labels are replaced by language referring expression sentences. Without any fine-tuning, we evaluate the zero-shot transfer performance of LOUPE on the visual grounding task over the RefCOCO yu2016modeling and RefCOCO+ yu2016modeling datasets. These two datasets are collected by the ReferitGame kazemzadeh2014referitgame, where a player is asked to write a language expression to refer to a specific object in the image, and another player is required to locate the target object given the image and the referring expression. RefCOCO dataset consists of 142,209 refer expressions for 50,000 objects in 19,994 images, which is split into train (120,624 expressions), val (10,834 expressions), testA (5,657 expressions), testB (5,095 expressions) sets. The images in testA set involve multiple persons and the images in testB set involve multiple objects. RefCOCO+ dataset consists of 141,564 expressions for 49,856 objects in 19,992 images, which is split into train (120,191 expressions), val (10,758 expressions), testA (5,726 expressions), testB (4,889 expressions) sets. We report the zero-shot transfer performance on the val, testA, and testB sets of both datasets.
Table 6:Image captioning evaluation results on COCO “Karpathy” test split.
| Image Captioning | ||||
| BLEU@4 | METEOR | CIDEr | SPICE | |
| VLP zhou2020unified | 36.5 | 28.4 | 117.7 | 21.3 |
| OSCARlarge li2020oscar | 37.4 | 30.7 | 127.8 | 23.5 |
| VinVLlarge zhang2021vinvl | 38.5 | 30.4 | 130.8 | 23.4 |
| BLIPViT−L li2022blip | 40.4 | - | 136.7 | - |
| LEMONlarge hu2021scaling | 40.6 | 30.4 | 135.7 | 23.5 |
| LOUPE | 40.9 | 31.5 | 137.8 | 24.3 |
Appendix FMore Experiment Results on Vision-Language Generation Task
To further validate the generalization ability of the learned cross-modal representations by our LOUPE, we adapt the pre-trained LOUPE to vision-language generation task, i.e., image captioning anderson2018bottom. Image captioning is the task of describing images with natural languages, which requires models to identify and describe the fine-grained semantics of images. The input images are encoded by the learned image encoder. As BLIP li2022blip, we train an image-grounded text decoder which shares the feed forward layers with the learned text encoder and adopts cross-attention to attend to the image features. The text decoder is trained with a language modeling loss to generate captions according to the images. We evaluate the image captioning performance on the MSCOCO lin2014microsoft dataset, which is split into train (113, 287 images), val (5,000 images), “Karpathy” test split (5,000 images). Each image has 5 captions. We use the train split to train the image-grounded text decoder and report the performance on the public “Karpath” 5k test split. Following standard metrics, we use BLEU@4, METEOR, CIDEr, and SPICE as evaluation metrics. We compare our LOUPE model with recent vision-language pre-training generation models hu2021scaling; li2022blip; li2020oscar; zhang2021vinvl; zhou2020unified. All methods are fine-tuned with cross-entropy loss only, without CIDEr optimization. As shown in Table 6, our LOUPE achieves competitive performance on all metrics, which verifies the strong generalization ability of our model on downstream vision-language generation tasks.
Table 7:Further ablation results (R@1) with respect to different image encoders.
| Image Encoder | Flickr30K | MSCOCO | |||
|---|---|---|---|---|---|
| image-to-text | text-to-image | image-to-text | text-to-image | ||
| 1 ALIGN jia2021scaling | EfficientNet | 88.6 | 75.7 | 58.6 | 45.6 |
| 2 FILIP yao2021filip | ViT-L | 89.8 | 75.0 | 61.3 | 45.9 |
| 3 CLIP radford2021learning | ViT-L | 88.0 | 68.7 | 58.4 | 37.8 |
| 4 CLIP* | Swin-L | 88.7 | 74.3 | 59.3 | 46.2 |
| 5 LOUPE | Swin-L | 90.5 | 76.3 | 62.3 | 50.1 |
Appendix GFurther Analysis on the Image Encoder
In our work, we adopt the Swin-L liu2021Swin as our image encoder due to the following considerations. (1) The shifted windowing scheme of Swin Transformer achieves linear computational complexity with respect to image size, which is more efficient than ViT dosovitskiy2020image. This merit is particularly beneficial to the vision-language pre-training as we need to process large-scale images (240M). (2) The hierarchical architecture of Swin Transformer is more flexible to model semantic regions at various scales. To further verify the performance gain from our proposed fine-grained semantically aligned vision-language pre-training framework, we implement a variant version of CLIP that adopts Swin-L as the image encoder (Row 4 in Table 7), using the same training dataset as our LOUPE. It can also be viewed as the backbone of our LUOPE (without optimization from our token-level and semantics-level Shapley interaction modeling). As shown in Table 7, comparing CLIP* with CLIP, the Swin-L image encoder does bring some improvements over CLIP. However, there is still a clear performance gap between CLIP* and our LOUPE. With the same architecture, our LOUPE has 2.68 points higher average R@1 than the CLIP* over two datasets. This further verifies that the main performance gain comes from our proposed fine-grained semantically aligned vision-language pre-training framework. Notably, we observe that the text-to-image retrieval of our implementation is obviously higher than CLIP. This phenomenon has also been confirmed by jia2021scaling; yao2021filip (see Row 1 and Row 2 in Table 7). We suppose that it might be caused by some training details or the dataset collection of CLIP.
Appendix HMore Qualitative Examples on Object Detection and Visual Grounding
For a more intuitive view of the performance of our model on object detection and visual grounding, we visualize more qualitative examples. Concretely, Figure 6 and Figure 7 show more object detection examples on the COCO lin2014microsoft and PASCAL VOC everingham2008pascal datasets. Figure 8 and Figure 9 show more visual grounding examples on the RefCOCO yu2016modeling and RefCOCO+ yu2016modeling datasets.

Figure 6:Qualitative examples of object detection on COCO Objects dataset.
Figure 7:Qualitative examples of object detection on PASCAL VOC dataset.

Figure 8:Qualitative examples of visual grounding on RefCOCO dataset.
Figure 9:Qualitative examples of visual grounding on RefCOCO+ dataset.
Appendix ILinear Probing Evaluation
In this section, we evaluate the linear probing performance of our LOUPE on image classification. Following the same evaluation setting as CLIP radford2021learning, we freeze the whole backbone network and only fine-tuning the last linear classification layer, which takes the token as input. We report the linear probing performance over 11 datasets in Table 8. Our LOUPE outperforms CLIP with average improvement of 1.6%. Notably, on ImageNet, the largest dataset among 11 datasets, our LOUPE surpasses CLIP by 1.8%.[CLS]
Table 8:Linear probing performance (top-1 accuracy) over 11 datasets.
|
CIFAR10 |
Food101 |
StanfordCars |
SUN397 |
Flowers102 |
Country211 |
FER2013 |
Aircrafts |
OxfordPets |
Caltech101 |
ImageNet |
|
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP | 98.0 | 95.2 | 90.9 | 81.8 | 99.2 | 46.4 | 72.9 | 69.4 | 95.1 | 96.5 | 83.9 |
| LOUPE | 97.6 | 96.0 | 92.1 | 82.6 | 99.5 | 49.3 | 70.7 | 80.2 | 95.5 | 97.5 | 85.7 |
Table 9:Comparison of training cost and architecture parameters.
| Pre-Training Image-Text Pairs | Parameters | GPUs | Days | GPU Days | |
|---|---|---|---|---|---|
| CLIP | 400M | 425M | 256 V100 | 12 days | 3072 |
| ALIGN | 1800M | 820M | 1024 TPUv3 | - | - |
| FILIP | 340M | 417M | 192 V100 | 24 days | 4608 |
| LOUPE | 240M | 226M | 128 V100 | 20 days | 2560 |
Appendix JTraining Efficiency Discussion
Although our proposed Shapley interaction modeling increases the training time per iteration, it enables our model to converge with fewer total iterations by encouraging our model to learn fine-grained region-phrase alignment beyond coarse image-text alignment. As shown in Table 9, our LOUPE achieves the best performance while using relatively small GPU days (128 GPUs × 20 days). Indeed, the proposed Shapley interaction modeling increases the training time per iteration, but it enables our model to learn fine-grained region-phrase alignment from raw image-text pairs without any object-level human annotations. Our LOUPE can be used as a zero-shot object detector without any fine-tuning. Compared with the expensive cost of human annotations, the increased training time might be acceptable. Meanwhile, manual annotations for extremely diverse object categories in the real world are unscalable and even impossible while our model demonstrates a promising alternative, that is, learning fine-grained semantics from raw texts about images, which are easily available and contain a broader set of visual concepts. For example, the right case of Figure 4 in the main paper shows that LOUPE successfully recognizes the leash region and aligns it with the “a leash” phrase. Note that the “leash” category has never appeared in any existing object detection datasets. On the other hand, our method is much more efficient than methods that rely on off-the-shelf object detectors (e.g., Faster R-CNN) to extract visual features. Recent studies kim2021vilt; yao2021filip have noticed that extracting visual features using object detectors greatly slows down the training (about 20 FPS per GPU) and requires more GPU memory. Thus, our model avoids such a heavy burden while being able to identify semantic-rich visual regions without any pre-training detectors or human annotations.
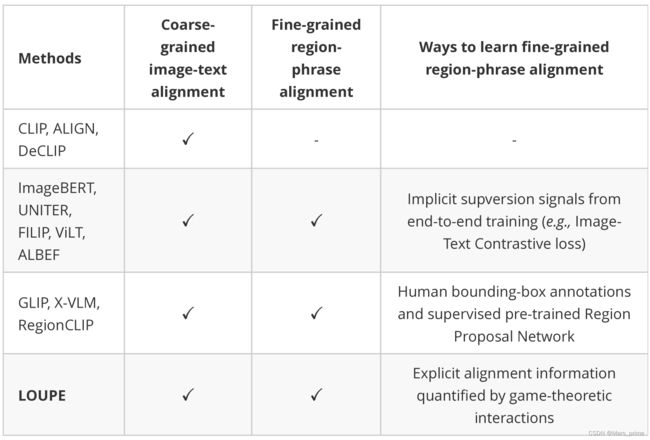
Figure 10:Comparison of the LOUPE with existing methods.
Appendix KDetailed Discussion with Some Related Works
In this section, we first provide comparison table to highlight key differences of our LOUPE with various methods. Then, we provide a detailed discussion with three recent works (i.e., FILIP yao2021filip, RegionCLIP zhong2022regionclip, X-VLM zeng2021multi), which also investigate fine-grained semantic alignment. We highlight key differences in Figure 10. Our LOUPE differs as it explicitly learns fine-grained region-phrase alignment from the novel perspective of game-theoretic interactions, without resorting to any object-level human annotations and pre-trained Region Proposal Network (RPN). Notably, the human bounding-box annotations are usually limited to the pre-defined object categories, and the RPN can only detect regions belonging to the pre-defined categories of pre-training object detection datasets. Thus, the methods that use human bounding-box annotations or pre-trained RPN usually suffer from detecting novel objects beyond the pre-defined categories while LOUPE learns from large-scale raw image-text pairs, which are more scalable and contain a broader set of visual concepts. Compared with FILIP, the superiorities of using Shapley Interaction modeling are mainly three-fold: 1) We suppose that directly computing token-wise alignment between every patch token and word token is not efficient and meaningful because an individual word token or patch token might not contain complete semantics. A semantic-rich phrase (e.g., “a girl in a blue coat”) usually consists of multiple words, and its corresponding visual region is composed of multiple patches. Also, some words (e.g., "is", "the") and patches (e.g., background pixels) are not meaningful. Based on this insight, our LOUPE differs as we first propose token-level Shapley interaction modeling to aggregate patches into semantic-meaningful regions, and then introduce semantics-level Shapley interaction modeling to explicitly model the fine-grained semantic alignment between semantic-meaningful regions and phrases. 2) Although FILIP computes token-wise similarity to simulate the fine-grained alignment, it can only learn implicit alignment from the supervision of image-text contrastive loss, lacking training signals to explicitly encourage semantic alignment between visual regions and textual phrases. In contrast, our Shapley interaction modeling provides explicit supervision signals (e.g., the alignment matrices visualized in Figure 4) to learn the fine-grained alignment. The consistently superior performance of our LOUPE than FILIP over all metrics also demonstrates the benefit of explicit fine-grained alignment learning. 3) FILIP can not be directly applied to object detection and visual grounding through implicit token-wise alignment learning while our LOUPE can immediately transfer to these tasks without any fine-tuning. It is because the proposed Shapley interaction modeling enables our model to identify semantic regions and align these regions with language. As shown in Table 2, without any bounding-box annotations and fine-tuning, our LOUPE achieves competitive performance across four object detection and visual grounding benchmarks. Our LOUPE is different from RegionCLIP in the following aspects: 1) RegionCLIP uses pre-trained Region Proposal Network (RPN) to detect regions in images. However, RPN is usually pre-trained on pre-defined object categories (e.g., 80 classes for MSCOCO), which can not cover extensive categories of objects in the large-scale pre-training dataset. Furthermore, since the RPN casts excessive demand on memory and computation, existing methods (i.e., RegionCLIP) usually fix the parameters of RPN and regard region detection as pre-processing step, disconnected with vision-language pre-training. Thus, the performance of RegionCLIP is also restricted by the quality of the RPN. In contrast, our LOUPE learns to identify semantic regions of images by token-level Shapley interaction modeling, which is more scalable and enables our LOUPE to learn a broader set of visual concepts from large-scale pre-training dataset. 2) RegionCLIP constructs a pool of object concepts from image-text corpus and aligns visual regions with these concepts. These concepts are usually individual nouns (e.g., boy, kite, bus). In contrast, our LOUPE focuses on phrases that involve rich context (e.g., "a boy running on the grass"). By aligning visual regions with phrases that contain rich semantic context, our LOUPE can learn a boarder set of visual concepts (e.g., objects, actions, relations) from the large-scale pre-training dataset. As for X-VLM, the main differences lie in three-fold: 1) X-VLM is trained on well-annotated datasets, where regions with bounding-box annotations are provided and each of them is associated with a description text. Such a manner is time-consuming and hard to scale to larger raw image-text data from the web. Our LOUPE differs as we are trained on noisy image-text pairs from the Internet. 2) X-VLM takes ground-truth regions as input and is trained to predict the bounding-box supervised by the regression loss on the ground-truth coordinates. In contrast, our LOUPE learns to identify semantic regions of images without such strong supervision signals from human annotations. 3) X-VLM has ground-truth alignment information between regions and their corresponding description texts, which provide strong supervision signals for region-text matching. By comparison, our LOUPE learns the fine-grained region-phrase alignment from game-theoretic interactions.
References
- (1)Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine Süsstrunk.Slic superpixels compared to state-of-the-art superpixel methods.IEEE transactions on pattern analysis and machine intelligence, 34(11):2274–2282, 2012.
- (2)Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang.Bottom-up and top-down attention for image captioning and visual question answering.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6077–6086, 2018.
- (3)Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh.Vqa: Visual question answering.In Proceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015.
- (4)Ankan Bansal, Karan Sikka, Gaurav Sharma, Rama Chellappa, and Ajay Divakaran.Zero-shot object detection.In Proceedings of the European Conference on Computer Vision (ECCV), pages 384–400, 2018.
- (5)Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al.Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020.
- (6)Javier Castro, Daniel Gómez, and Juan Tejada.Polynomial calculation of the shapley value based on sampling.Computers & Operations Research, 36(5):1726–1730, 2009.
- (7)Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu.Uniter: Universal image-text representation learning.In European conference on computer vision, pages 104–120. Springer, 2020.
- (8)Anupam Datta, Shayak Sen, and Yair Zick.Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems.In 2016 IEEE symposium on security and privacy (SP), pages 598–617. IEEE, 2016.
- (9)Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova.Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2018.
- (10)Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al.An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020.
- (11)Mark Everingham, Andrew Zisserman, Christopher KI Williams, Luc Van Gool, Moray Allan, Christopher M Bishop, Olivier Chapelle, Navneet Dalal, Thomas Deselaers, Gyuri Dorkó, et al.The pascal visual object classes challenge 2007 (voc2007) results.2008.
- (12)Michel Grabisch and Marc Roubens.An axiomatic approach to the concept of interaction among players in cooperative games.International Journal of game theory, 28(4):547–565, 1999.
- (13)Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui.Open-vocabulary object detection via vision and language knowledge distillation.arXiv preprint arXiv:2104.13921, 2021.
- (14)Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick.Momentum contrast for unsupervised visual representation learning.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020.
- (15)Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang.Scaling up vision-language pre-training for image captioning.arXiv preprint arXiv:2111.12233, 2021.
- (16)Zhicheng Huang, Zhaoyang Zeng, Yupan Huang, Bei Liu, Dongmei Fu, and Jianlong Fu.Seeing out of the box: End-to-end pre-training for vision-language representation learning.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12976–12985, 2021.
- (17)Zhicheng Huang, Zhaoyang Zeng, Bei Liu, Dongmei Fu, and Jianlong Fu.Pixel-bert: Aligning image pixels with text by deep multi-modal transformers.arXiv preprint arXiv:2004.00849, 2020.
- (18)Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig.Scaling up visual and vision-language representation learning with noisy text supervision.In International Conference on Machine Learning, pages 4904–4916. PMLR, 2021.
- (19)Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg.Referitgame: Referring to objects in photographs of natural scenes.In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
- (20)Alex Kendall and Yarin Gal.What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017.
- (21)Wonjae Kim, Bokyung Son, and Ildoo Kim.Vilt: Vision-and-language transformer without convolution or region supervision.In International Conference on Machine Learning, pages 5583–5594. PMLR, 2021.
- (22)Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi.Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation.arXiv preprint arXiv:2201.12086, 2022.
- (23)Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi.Align before fuse: Vision and language representation learning with momentum distillation.Advances in Neural Information Processing Systems, 34, 2021.
- (24)Jiahao Li, Greg Shakhnarovich, and Raymond A Yeh.Adapting clip for phrase localization without further training.arXiv preprint arXiv:2204.03647, 2022.
- (25)Juncheng Li, Xin Wang, Siliang Tang, Haizhou Shi, Fei Wu, Yueting Zhuang, and William Yang Wang.Unsupervised reinforcement learning of transferable meta-skills for embodied navigation.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12123–12132, 2020.
- (26)Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al.Grounded language-image pre-training.arXiv preprint arXiv:2112.03857, 2021.
- (27)Wei Li, Can Gao, Guocheng Niu, Xinyan Xiao, Hao Liu, Jiachen Liu, Hua Wu, and Haifeng Wang.Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning.arXiv preprint arXiv:2012.15409, 2020.
- (28)Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al.Oscar: Object-semantics aligned pre-training for vision-language tasks.In European Conference on Computer Vision, pages 121–137. Springer, 2020.
- (29)Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan.Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm.arXiv preprint arXiv:2110.05208, 2021.
- (30)Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick.Microsoft coco: Common objects in context.In European conference on computer vision, pages 740–755. Springer, 2014.
- (31)Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo.Swin transformer: Hierarchical vision transformer using shifted windows.In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- (32)Ilya Loshchilov and Frank Hutter.Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017.
- (33)Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee.Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.Advances in neural information processing systems, 32, 2019.
- (34)Scott M Lundberg and Su-In Lee.A unified approach to interpreting model predictions.Advances in neural information processing systems, 30, 2017.
- (35)Yasuko Matsui and Tomomi Matsui.Np-completeness for calculating power indices of weighted majority games.Theoretical Computer Science, 263(1-2):305–310, 2001.
- (36)Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik.Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models.In Proceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015.
- (37)Di Qi, Lin Su, Jia Song, Edward Cui, Taroon Bharti, and Arun Sacheti.Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data.arXiv preprint arXiv:2001.07966, 2020.
- (38)Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al.Learning transferable visual models from natural language supervision.In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- (39)Shafin Rahman, Salman Khan, and Nick Barnes.Improved visual-semantic alignment for zero-shot object detection.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11932–11939, 2020.
- (40)J. Redmon and A. Farhadi.Yolov3: An incremental improvement.arXiv e-prints, 2018.
- (41)Jie Ren, Die Zhang, Yisen Wang, Lu Chen, Zhanpeng Zhou, Yiting Chen, Xu Cheng, Xin Wang, Meng Zhou, Jie Shi, et al.A unified game-theoretic interpretation of adversarial robustness.arXiv preprint arXiv:2111.03536, 2021.
- (42)Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015.
- (43)Lloyd S Shapley.A value for n-person games, contributions to the theory of games, 2, 307–317, 1953.
- (44)P. Sharma, N. Ding, S. Goodman, and R. Soricut.Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018.
- (45)Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai.Vl-bert: Pre-training of generic visual-linguistic representations.arXiv preprint arXiv:1908.08530, 2019.
- (46)Hao Tan and Mohit Bansal.Lxmert: Learning cross-modality encoder representations from transformers.arXiv preprint arXiv:1908.07490, 2019.
- (47)Jasper RR Uijlings, Koen EA Van De Sande, Theo Gevers, and Arnold WM Smeulders.Selective search for object recognition.International journal of computer vision, 104(2):154–171, 2013.
- (48)Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin.Attention is all you need.Advances in neural information processing systems, 30, 2017.
- (49)Robert J Weber.Probabilistic values for games.The Shapley Value. Essays in Honor of Lloyd S. Shapley, pages 101–119, 1988.
- (50)Longhui Wei, Lingxi Xie, Wengang Zhou, Houqiang Li, and Qi Tian.Mvp: Multimodality-guided visual pre-training.arXiv preprint arXiv:2203.05175, 2022.
- (51)Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio.Show, attend and tell: Neural image caption generation with visual attention.In International conference on machine learning, pages 2048–2057. PMLR, 2015.
- (52)Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu.Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021.
- (53)Fei Yu, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang.Ernie-vil: Knowledge enhanced vision-language representations through scene graph.arXiv preprint arXiv:2006.16934, 2020.
- (54)Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg.Modeling context in referring expressions.In European Conference on Computer Vision, pages 69–85. Springer, 2016.
- (55)Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih-Fu Chang.Open-vocabulary object detection using captions.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14393–14402, 2021.
- (56)Yan Zeng, Xinsong Zhang, and Hang Li.Multi-grained vision language pre-training: Aligning texts with visual concepts.arXiv preprint arXiv:2111.08276, 2021.
- (57)Hao Zhang, Yichen Xie, Longjie Zheng, Die Zhang, and Quanshi Zhang.Interpreting multivariate shapley interactions in dnns.arXiv preprint arXiv:2010.05045, 2020.
- (58)Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao.Vinvl: Revisiting visual representations in vision-language models.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5579–5588, 2021.
- (59)Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al.Regionclip: Region-based language-image pretraining.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- (60)Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason Corso, and Jianfeng Gao.Unified vision-language pre-training for image captioning and vqa.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 13041–13049, 2020.
- (61)Pengkai Zhu, Hanxiao Wang, and Venkatesh Saligrama.Don’t even look once: Synthesizing features for zero-shot detection.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11693–11702, 2020.