python函数详解_python 函数中的内置函数及用法详解
今天来介绍一下Python解释器包含的一系列的内置函数,下面表格按字母顺序列出了内置函数:

下面就一一介绍一下内置函数的用法:
1、abs()
返回一个数值的绝对值,可以是整数或浮点数等。
print(abs(-18))
print(abs(0.15))
result:
18
0.15
2、all(iterable)
如果iterable的所有元素不为0、''、False或者iterable为空,all(iterable)返回True,否则返回False。
print(all(['a','b','c','d'])) #列表list,元素都不为空或0,返回True
True
print(all(['a','b','','d'])) #如果存在一个为空的元素,返回False
False
print(all([0,1,2,3])) #如果存在为0的元素,同样返回False
False
print(all([])) #空元组和空列表返回值为True
True
print(all(()))
True
3、any(iterable)
如果iterable的任何元素不为0、''、False,all(iterable)返回True,如果iterable为空,返回Fasle。
注意:此函数与all()函数的在于,any()函数中有任意一个元素为0、''、False不影响整体,会返回True,而all()函数中必须是全部不包含特殊元素才会返回True,只要有一个特殊元素,会直接返回False.
print(any(['a','b','c','d'])) #列表list,元素都不为空或0
True
print(any(['a','b','','d'])) #列表list,存在一个为空的元素,返回True
True
print(any([0,False])) #如果元素全部是0,Fasle,返回Fasle
False
print(any([])) #any函数中空列表和空元组返回Fasle
False
print(any(()))
False
4、bin()
将一个整数转换成一个二进制字符串,结果以'0b'为前缀。
print(bin(32)) #将十进制转换成二进制
print(bin(64))
print(bin(128))
result:
0b100000
0b1000000
0b10000000
5、hex()
将一个整数转换成一个小写的十六进制字符串,结果以'0x'为前缀。
print(hex(255)) #将整数转换成十六进制
print(hex(192))
result:
0xff
0xc0
6、oct()
将一个整数转换成八进制的字符串,结果以'0o'为前缀。
print(oct(255)) #将整数转换成八进制
print(oct(192))
result:
0o377
0o300
7、bool()
返回一个布尔值,True或False。
print(bool()) #bool值缺省为False
False
print(bool(0))
False
print(bool('jack'))
True
print(bool(""))
False
8、bytes()
将一个字符串转换成你想要的编码格式的字节。
print(bytes('你好',encoding='utf-8')) #将字符串转换成utf-8编码格式的字节
b'\xe4\xbd\xa0\xe5\xa5\xbd'
print(bytes('你好',encoding='gbk')) #将字符串转换gbk编码格式的字节
b'\xc4\xe3\xba\xc3'
9、chr()
介绍chr()函数之前先看一下ASCII码对照表:
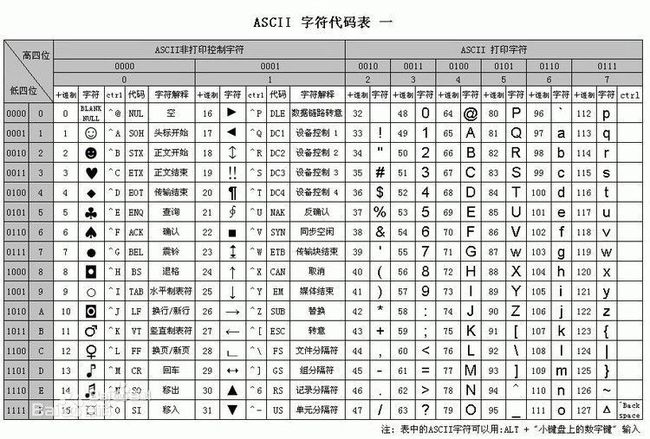
chr()函数就是返回整数对应的ASCII码对照表里的字符,取值范围[0~255]之间的正数。
ord()函数作用正好和chr()函数相反,不再介绍,请看下面例子:
n = chr(65) #根据十进制找到在ascii码里对应的字符
print(n)
result:A
a= ord("a") #根据字符找到在ascii码里对应的十进制
print(a)
result:97
10、compile(source,filename,mode)
将source编译为,代码对象能够通过exec语句来执行或者eval()进行求值。
source:字符串或者对象;
filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值;
model:编译代码的种类,可以指定为'exec','eval','single'。
code="for i in range(0,10):print(i)"
cmpcode = compile(code,'','exec') #可以将字符串转换成python代码执行
print(cmpcode)
result:
at 0x000002A54E938ED0, file "", line 1>
11、exec()
exec语句用来执行储存在字符串或文件中的Python语句。
exec("print('hello,world')") #执行exec()里的python语句
result:
hello,world
12、eval()
eval()函数将字符串str当成有效的表达式来求值并返回计算结果。
ret = eval("8*8") #执行表达式并返回结果
print(ret)
#result:64
t = exec("8*8") #执行python代码,可以接收或字符串,没有返回值
print(t)
#result:None
13、divmod(a,b)
divmod(a,b)方法是计算a,b的商和余数,即:a//b 余几,返回结果为元组。以后做网页翻页的时候会。
num = divmod(9,2) #9//2
print(num)
#result:
(4,1) #结果为商4余1
14、enumerate(iterable,start=0)
返回一个枚举对象。iterable必须是序列,迭代器,或者其他支持迭代的对象。
dic = {'name':'jack',
'age':18,
'sex':'boy',}
for i in enumerate(dic.keys(),start=0):
print(i)
#result:
(0, 'name')
(1, 'sex')
(2, 'age')
15、filter()
对于序列中的元素进行筛选,最终获取符合条件的序列。
filter() #循环第二个参数,让每个循环元素执行函数,如果函数返回值为True,表示元素合法
filter内部实现方法:
for item in 第二个参数:
r = 第一个参数(item)
if r:
result(item)
return result
#例:
def f1(args):
if args>22:
return True
li=[11,22,33,44]
ret = filter(f1,li)
print(list(ret)) #返回值为一个迭代器,所以使用list()函数来返回像上面这种简单的函数可以使用lambda函数来执行:
像上面这种简单的函数可以使用lambda函数来执行:
li = [11,22,33,44]
ret = filter(lambda a:a>22,li) #通过lambda函数处理,lambda是有返回值的,条件成立返回True
print(list(ret))
对于列表中字符串跟数字并存的提取方法:
li = [2,32,4,45,22,'tony',33,25,5,76,'liupeng',19,78,'jack',24]
l1 = []
ret = filter(lambda i:type(i) == str,li) #使用filter函数结合lambda表达式来过滤type为str的元素
print(ret,type(ret))
for i in ret:
l1.append(i) #把过滤掉的str元素导入到新列表中
print(l1)
#result:
['tony', 'liupeng', 'jack']
li = [11,22,33,44,55,66,77,88,99,90]
def numb(args):
if args % 2 ==0: #取列表中偶数值,要想取基数值把0变成1
return True
ret = filter(numb,li)
print(list(ret))
#result:
[22, 44, 66, 88, 90]
li1 = ['A','','B',None,'C',' ']
def numb1(args):
if args and args.strip(): # 去空
return True
ret = filter(numb1,li1)
print(list(ret))
#result:
['A', 'B', 'C']
filter主要的功能其实就是进行过滤及筛选。在此进行一段插曲。python中的正则表达式也可以进行过滤跟筛选,主要是面向于字符串的过滤中起到了很好的作用。对于正则表达式打算另起章节具体介绍,在此仅简单列举1-2个案例仅供参考。
小插曲(正则表达式筛选案例):
需求1:取出s变量中的speed跟angle。
import re #在这里我们需要提前导入re模块。目的为了是使用re模块中findall方法
s = 'speed=210,angle=150'
m = re.findall(r'(\w*[a-zA-Z]+)\w*',s) #\w代表匹配字母跟数字,*代表对于前一个字符重复0到无穷次,[a-zA-Z]代表匹配26个包含大小写的字母,而后面的+号表示把匹配到的字母拼接起来
# m = re.findall(r'([a-zA-Z]+)',s) #上述代码的简化版。不需要指定过度的匹配字符,因为[a-zA-Z]的范围已经是指定了所有字母组合了。
print (m)
#result:
['speed', 'angle']
需求2:从s这个字符串中,把数字跟字符分别提取出来。
import re
s = 'lajsfdhoiqu190821AWJKJE34ijoohoyyuoi1234uh12412io980843'
s1 = re.findall(r'[0-9]+',s) #使用方法跟需求1中的运用方法基本一致。只不过范围我们从字符转到了字母身上。而在指定字母的时候给出【0-9】的范围即可。
print(s1)
s2 = re.findall(r'([a-zA-Z]+)',s)
print(s2)
#result:
['190821', '34', '1234', '12412', '980843']
['lajsfdhoiqu', 'AWJKJE', 'ijoohoyyuoi', 'uh', 'io']
需求3:从s这个字符串中,把数字跟字符分别提取出来。
import re
relink = '(.*)'
info = 'baidu'
cinfo = re.findall(relink,info)
print (cinfo)
#result:
[('http://www.baidu.com', 'baidu')]
16、map(函数,可迭代的对象)
我们先看map。map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
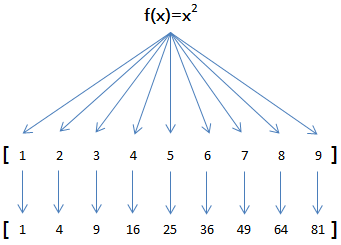
现在,我们用Python代码实现:
>>> def f(x):
... return x * x
...
>>> map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
[1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。
你可能会想,不需要map()函数,写一个循环,也可以计算出结果:
def f(x):
return x*x
L = []
for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(n))
print(L)
#result:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
的确可以,但是,从上面的循环代码,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list”吗?
所以,map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
>>> map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])
['1', '2', '3', '4', '5', '6', '7', '8', '9']
只需要一行代码(仅限于python2的版本。python3返回的是个迭代器需要for循环出元素)。
li = [11,22,33,44]
ret = map(str,li)
l1 = []
for x in ret:
l1.append(x)
print(l1)
#result:
['11', '22', '33', '44']
map结合lambda表达式案例:
li = [11,22,33,44]
new_list = map(lambda a:a+100,li)
print(list(new_list))
#result:
[111,122,133,144]
li = [11, 22, 33]
sl = [1, 2, 3]
new_list = map(lambda a, b: a + b, li, sl)
print(list(new_list))
#result:
[12, 24, 36]
map结合生成器案例:
def func(x,y):
return x*y*2 #返回结果为x*y的和再成2
li = [1,2,3,4]
li1= [2,3,4,5]
ret = map(func,li,li) # 第一个参数为func函数本身,第二个参数为x(li列表中的每个值),第三个参数为y(li1列表中的每个值)
print(ret.__next__())
for i in ret:
print(i)
#result:(结果为li列表跟li1列表每个值相乘再成2)
4
12
24
40
17、reduce()
对于序列内所有元素进行累计操作:
li = [11,22,33]
result = reduce(lambda x,y:x + y,li)
print (result)
#result: #注意在Python3中已经没有了reduce函数
66
当然也可以通过结合lambda表达式3行解决
1
from functools import reduce#python3中已经把reduce踢出了内置函数。需要通过import functools函数来引用reduceli = [11,22,33]result = reduce(lambda x,y:x+y,li)print(result)#result:66
18、isinstance()
判断对象是不是类的实例。
li = [11,22,33]
n = isinstance(li,list) #判断li是不是list类的实例
print(n)
#result:
True
19、len()
判断字符串长度。
s = "你好"
print(len(s)) #在python3中len函数既可以取的字符的长度,也可以取字节的长度
#python2.*中len函数只可以取字节的长度
#result:2
s = "你好"
b = bytes(s,encoding='utf-8')
print(len(b))
#result:6
分别使用2.*和3.*循环“你好”,查看结果:
2.7 for 循环“你好” #输出6个空字符
3.5 for 循环“你好”查看结果 #输出"字符串结果"
20、max()、min()、sum()
max():取最大值; min():取最小值; sum():取总的值
li=[11,22,33]
print(max(li)) #最大值
33
print(min(li)) #最小值
11
print(sum(li)) #总和
66
21、pow(x,y)
pow()返回x的y次方的值。
print(pow(2,3)) #计算2的3次方
8
print(pow(2,4)) #计算2的4次方
16
22、round()
round()方法返回浮点数x的四舍五入值。
print(round(2.3)) #四舍五入
2
print(round(2.8))
3
23、random()
random方法返回随机生成的一个实数,它在[0,1]范围内。random的使用一般对于自动生成密码,验证码之类的用的比较多。
import random
print('random:',random.random())
#result: random: 0.7037348886029884
# coding=utf-8
__author__ = 'hillfree'
import random
def testRand():
# 在[a, b]之间产生随机整数 random.randint(a, b)
for i in range(5):
ret = random.randint(100, 999)
print("random.randint(100, 999) = {0}".format(ret,))
# 在[a, b]之间产生随机浮点数 random.uniform(a, b)
for i in range(5):
ret = random.uniform(1.0, 100.0)
print("random.uniform(1.0, 100.0) = {0}".format(ret,))
# 在[0.0, 1.0)之间产生随机浮点数 random.random()
for i in range(5):
ret = random.random()
print("random.random() = {0}".format(ret,))
# 在样本population中随机选择k个 random.sample(population, k)
population = {"Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun" }
for i in range(5):
ret = random.sample(population, 3)
print("random.sample(population, 3) = {0}".format(ret,))
# 在序列seq中随机选择1个 random.choice(seq)
seq = ("to", "be", "or", "not", 'tobe', 'is', 'a', 'question')
for i in range(5):
ret = random.choice(seq)
print("random.choice(seq) = {0}".format(ret,))
# 从序列中随机获取指定长度的片断。不修改原有序列。
# random.sample(sequence, k)
sentence = "to be or not to be is a question"
for i in range(5):
ret = random.sample(sentence, 5)
print("random.sample(sentence, 5) = {0}".format(ret,))
# 三角分布的随机数 random.triangular(low, high, mode)
for i in range(5):
ret = random.triangular(0, 100, 10)
print(" random.triangular(0, 100, 10) = {0}".format(ret,))
# 高斯分布的随机数(稍快) random.gauss(mu, sigma)
for i in range(5):
ret = random.gauss(0, 1)
print(" random.gauss(0, 1) = {0}".format(ret,))
# beta β分布的随机数 random.betavariate(alpha, beta)
# 指数分布的随机数 random.expovariate(lambd)
# 伽马分布的随机数 random.gammavariate(alpha, beta)
# 对数正态分布的随机数 random.lognormvariate(mu, sigma)
# 正态分布的随机数 random.normalvariate(mu, sigma)
# 冯米塞斯分布的随机数 random.vonmisesvariate(mu, kappa)
# 帕累托分布的随机数 random.paretovariate(alpha)
# 韦伯分布的随机数 random.weibullvariate(alpha, beta)
if __name__ == "__main__" :
testRand()
random模块利用random生成一个简单的验证码案例
# import random 导入 随机模块,
#验证码的操作
random.randint(1,99) #随机数字
temp = '' 定义一个空字付串
for i in range(6): 循环6次
q = random.randrange(0,4) 自动生成一个0-4的随机数
if q == 3 or q == 1: 如果随机数等于3 或 1就生成小写字母
c2 = random.randrange(0,10) 生成 0--10内的随机数
temp = temp + str(c2) 向变量中添加当前数字对应的ascii码的字符
else:
c = random.randrange(65,91) 生成 65-91内的随机数
z = chr(c)
temp = temp + z 向变量中添加当前数字对应的ascii码的字符
print(temp)
随机生成密码:
这里用到了除random以外的另外一个模块(string),通过string模块可以更方便的为我们调取字母跟数字。不需要按照上例来自己创建范围来生成数字字母了。
import random
import string
sal = '!@#$%^&*()>
def passwd(length):
chars = string.ascii_letters + string.digits + sal
#return ''.join(random.choice(chars) for i in range(length))
return ''.join(random.sample(chars,8))
if __name__ == '__main__':
for i in range(1):
print(passwd(8))
24、choice()
choice()方法返回一个列表,元组或字符串的随机项。
import random
#取列表或元组的随机值
print("choice([1, 2, 3, 5, 9]) : ", random.choice([1, 2, 3, 5, 9]))
print("choice('A String') : ", random.choice('A String'))
#result:
choice([1, 2, 3, 5, 9]) : 9 #执行一次值会变一次
choice('A String') : i
25、randrange()
返回指定递增基数集合中的一个随机数,基数缺省值为1,听这个意思不是太好理解,下面举例说明:
import random
#随机输出100到1000间的偶数
print("rangrange(100,1000,2):",random.randrange(100,1000,2))
#随机输出100到1000间的其他数
print("rangrange(100,1000,2):",random.randrange(100,1000,3))
#result:
rangrange(100,1000,2): 260
rangrange(100,1000,2): 511
下面将上面三个函数放在一起,来做一道题,生成6位的随机数,其中包括大写字母,数字?
import random
li= []
for i in range(6): #循环6次
temp = random.randrange(65,91) #random随机数从ascii码里取65到91
c = chr(temp) #将随机数找到ascii码表里找到具体字符
li.append(c) #追加到空列表里
result = "".join(li) #再用join的方式将列表转换成字符串
print(result) #结果全是大写字母
li = [] #定义空列表
for i in range(6): #循环6次
r= random.randrange(0,5) #生成一个0-4的随机值,然后根据r的值判断数字出现的位置
if r ==2 or r==4: #如果第一次循环r==2或者4的时候,条件满足,在列表里随机添加一个数字
num = random.randrange(0,10) #生成一个0-9的随机数
li.append(str(num))
else:
temp = random.randrange(65,91) #如果上面条件不成立,添加字符串
c = chr(temp)
li.append(c)
result = "".join(li)
print(result)
26、zip()
利用每个可迭代元素,制作一个迭代器来聚合元素。
l1 = ['北京',11,22,33]
l2 = ['欢迎',11,22,33]
l3 = ['你',11,22,33]
r=zip(l1,l2,l3)
#print(list(r))
# [('北京', '欢迎', '你'), (11, 11, 11), (22, 22, 22), (33, 33, 33)]
temp = list(r)[0]
ret ="".join(temp)
print(ret)
今天的内置函数就介绍到这,由于还没有学习面向对象编程,一些内置函数会在学完面向对象编程以后,在更新。
总结
以上所述是小编给大家介绍的python 函数中的内置函数及用法详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!