python的学习day_05
目录
yecharts的入门和使用
构建一个折线图:
代码:
运行的结果:
设置全局配置项:
代码:
运行的结果:
小结:
JSON :
JSON 数据的示例:
随机生成JSON数据:
地图可视化
VisualMapOpts常见的属性:
代码:
运行的效果:
省份的地图可视化
代码:
运行的结果:
基础动态柱图:
代码:
运行结果:
小结:编辑
时间线柱状图的绘制:
时间线:
代码:
运行的结果:
编辑
列表的自定义排序方式:
代码:
运行的结果:
动态GDP柱状图
数据是:
代码:
运行结果:
代码分析:
面对对象:
初识对象:
设计类:(class)
创建对象:
对象属性赋值:
类的定义和使用:
成员方法的定义语法:
代码:
构造方法:
代码演示:
运行结果:
其他内置方法:
__str__ 字符串方法:
代码:
运行结果:
__lt__ 小于符号的比较方法
代码演示:
运行结果:
__le__小于等于比较符号方法:
代码:
运行结果:
__eq__ 相等方法:
代码:
小结:编辑
封装:
私有成员:
报错的私有变量代码:
报错的原因分析:
改正后的代码:
报错的私有成员方法:
运行结果:
报错的代码分析:
改正后的代码:
yecharts的入门和使用
构建一个折线图:
- 得到折线图的对象 line = Line()
- 向x轴添加数据 line.add_xaxis()
- 向y轴添加数据 line.add_yaxis()
- 生成图表 line.render()
代码:
# 导包 导入Line功能构建折现图像
from pyecharts.charts import Line
# 得到折线图对象
line = Line()
# 添加x轴数据
line.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
line.add_yaxis("GDP", [30, 20, 10])
# 生成图表
line.render()
运行的结果:
生成了一个html的文件
![]()
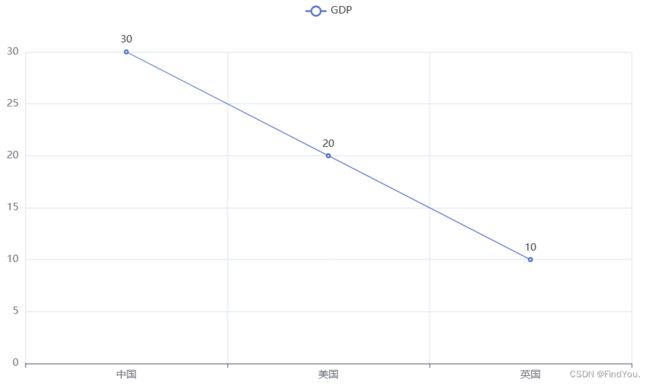
设置全局配置项:
代码:
# 导包 导入Line功能构建折现图像
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
# 得到折线图对象
line = Line()
# 添加x轴数据
line.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
line.add_yaxis("GDP", [30, 20, 50])
# 设置全局配置项
line.set_global_opts(
title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True), # 注意带逗号
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
# 生成图标
line.render()运行的结果:
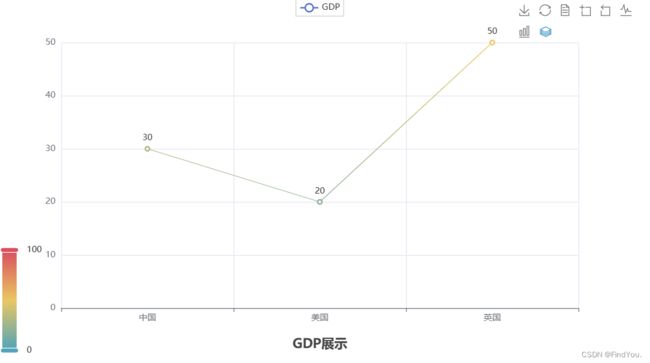
小结:

JSON :
JSON(JavaScript Object Notation)是一种常用的轻量级数据交换格式,具有易读、易解析、占用空间小等优点。它基于 JavaScript 语言的一个子集,但可以被多种不同编程语言解析和生成。
JSON 数据由键值对构成,形式类似于 Python 中的字典或者 Java 中的 Map。它的基本语法规则如下:
- 键名必须用双引号包裹,键值可以是布尔值、数字、字符串、数组、对象或者 null。
- 键值对之间使用英文逗号 , 分隔,键值对以花括号 {} 包围,表示一个对象。
- 数组是一组由逗号分隔的值,用方括号 [] 包围。数组可以包含对象和其他数组。
- JSON 中的字符串必须用双引号 "" 包裹。
JSON 数据的示例:
{
"name": "Tom",
"age": 20,
"isStudent": true,
"grades": [80, 90, 85],
"address": {
"city": "Beijing",
"street": "Xinjiekou"
},
"hobbies": ["reading", "music", "coding"]
}
随机生成JSON数据:
import json
import random
import calendar
from datetime import datetime
# 生成虚构的人工智能数据
ai_data = {
"中国": {
"投资": {},
"就业人数": {}
},
"美国": {
"投资": {},
"就业人数": {}
},
"印度": {
"投资": {},
"就业人数": {}
}
}
for country in ai_data:
for year in range(2019, 2022):
ai_data[country]["投资"][year] = {}
ai_data[country]["就业人数"][year] = {}
for month in range(1, 13):
days_in_month = calendar.monthrange(year, month)[1]
month_name = datetime(year, month, 1).strftime('%B')
ai_data[country]["投资"][year][month_name] = random.randint(1000000, 3000000) * days_in_month
ai_data[country]["就业人数"][year][month_name] = random.randint(50000, 200000) * days_in_month
# 将数据保存为JSON文件
filename = 'D:\\杂论\\人工智能数据.txt'
with open(filename, 'w', encoding="UTF-8") as f:
json.dump(ai_data, f, ensure_ascii=False, indent=4)
print(f"生成的JSON文件已保存为 {filename}")
地图可视化
- 用的是Map()
- 用中国的地图是:map.add('地图', data, "china")
- 用河南省的地图是 map.add('地图', data, "河南")
- set_global_opts 是 Pyecharts 中的一个方法,用于设置全局配置选项(Global Options)。
- VisualMapOpts 是 Pyecharts 中的一个类,用于设置图表中的视觉映射(Visual Map)选项。
VisualMapOpts常见的属性:
- type_:设置视觉映射的类型,可选值为 "continuous"(连续型)或 "piecewise"(分段型)。
- min_ 和 max_:设置连续型视觉映射的最小值和最大值。
- range_color:设置连续型视觉映射的颜色范围,可以定义一个颜色渐变过程。
- split_number:设置分段型视觉映射的段数。
- pieces:设置分段型视觉映射的每个段的范围和样式。
- is_piecewise:是否开启分段型视觉映射。
- orient:设置视觉映射的方向,可选值为 "horizontal"(水平)或 "vertical"(垂直)。
- pos_left、pos_top、pos_right、pos_bottom:通过调整百分比来设置视觉映射的位置。
- textstyle_opts:设置文字标签的样式。
- formatter:自定义视觉映射的文本格式化函数。
代码:
map.render("生成后的名字")
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
map = Map()
data = [ # 列表里面嵌套的是 元组
("北京市", 222),
('上海市', 119),
('天津市', 219),
('河南省', 223),
("广东省", 431)
]
map.add('地图', data, "china")
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
max_=500, # 设置最大值
min_=100, # 设置最小值
range_color=['#FF4500', '#FFFF00', '#7FFF00'] # 设置颜色范围
)
)
map.render("map.html")
运行的效果:
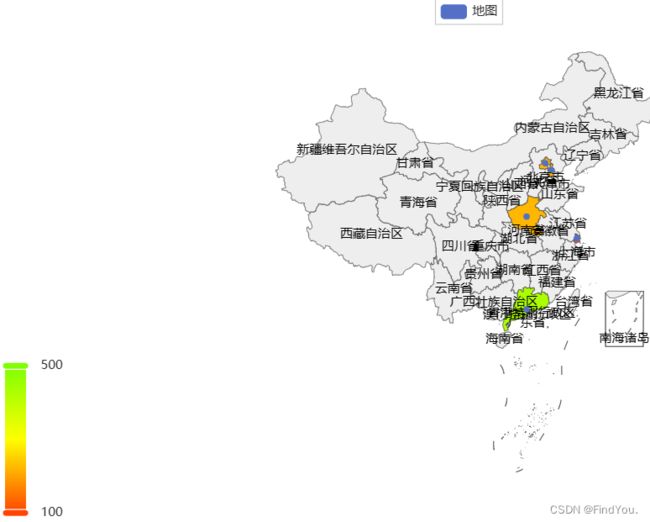
省份的地图可视化
只不过在地图add的时候 第三个参数由china改为了省份
代码:
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
map = Map()
data = [ # 列表里面嵌套的是 元组
("周口市", 222),
('信阳市', 119),
('驻马店市', 219),
('信阳市', 223),
("开封市", 431)
]
map.add('河南省的人工智能投资', data, "河南")
map.render("河南省的人工智能投资.html")运行的结果:
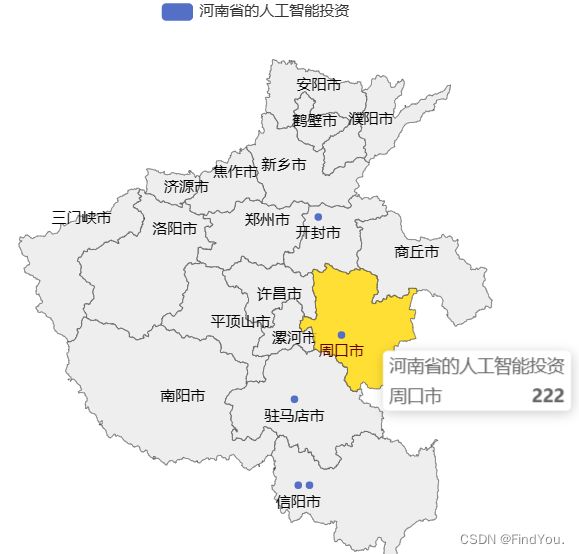
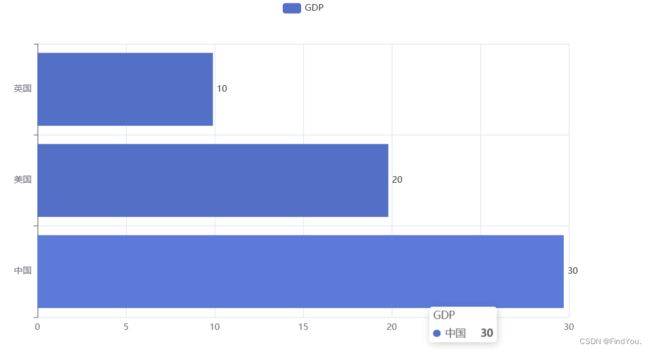
基础动态柱图:
- 构建柱状图对象 bar = Bar()
- 添加x轴数据 和之前是一样的 bar.add_xaxis()
- 反转xy轴 bar.reversal_axis()
- 绘图 bar.render("生成文件的名字")
代码:
from pyecharts.charts import Bar # 通过Bar构建基础柱状图
from pyecharts.options import *
# 构建柱状图对象
bar = Bar()
# 添加x轴数据
bar.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right")) # 数值标签添加到右边
# 反转xy轴
bar.reversal_axis()
# 绘图
bar.render("基础柱状图.html")运行结果:
小结:

时间线柱状图的绘制:
时间线:
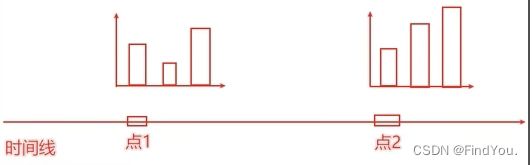
- 创建时间对象 timeline = Timeline()
- 还可以设置主题,在创建时间对象的括号里面 加上 {"theme": ThemeType.你喜欢的背景}
- timeline对象添加bar柱状图 timeline.add(bar1, "这一页你起的名字")

代码:
from pyecharts.charts import Bar, Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType
bar1 = Bar()
bar1.add_xaxis(["中国", "美国", "英国", "意大利"])
bar1.add_yaxis("GDP", [30, 20, 10, 12], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国", "美国", "英国", "意大利"])
bar2.add_yaxis("GDP", [50, 30, 10, 40], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
# 创建时间线对象
timeline = Timeline(
# 设置主题的颜色
{"theme": ThemeType.LIGHT}
)
# timeline对象添加bar柱状图
timeline.add(bar1, "2021年GDP")
timeline.add(bar2, "2022年GDP")
# 自动播放设置
timeline.add_schema(
play_interval=1000, # 播放的次数1秒1次
is_timeline_show=True,
is_auto_play=True, # 自动播放
is_loop_play=True # 循环播放
)
# 主题设置
# 通过时间线绘图
timeline.render("基础柱状图-时间线.html")
运行的结果:

列表的自定义排序方式:
list要是里面嵌套这list想去按照自定义的形式进行排序 怎么办?
- list.sort(key=你指定的方法, 是否翻转)
- def my_sor(t): return t[你按照什么排序]
代码:
my_list = [["a", 33], ["b", 55], ["c", 11]]
# 定义排序方法
def choose_sort_key(element):
return element[1]
my_list.sort(key=choose_sort_key, reverse=True)
# 或者 改为lambda
my_list.sort(key=lambda element: element[1], reverse=True) # 按照第二个值进行从小到大排序
print(my_list)
运行的结果:
![]()
动态GDP柱状图
我随机生成的2016到2022年10个国家的GDP 放在了D盘杂论里面
数据是:
{
"CountryA": [
2789.19,
3604.43,
3053.54,
2769.93,
2175.91,
3264.88,
2244.18
],
"CountryB": [
4469.69,
4821.95,
1978.86,
3979.45,
2691.59,
2883.42,
4635.42
],
"CountryC": [
448.08,
526.93,
199.07,
4179.84,
3912.97,
4363.06,
4895.23
],
"CountryD": [
4015.88,
2361.25,
3924.59,
679.54,
3235.61,
802.43,
4728.88
],
"CountryE": [
2657.06,
2131.84,
1396.32,
3893.75,
2335.14,
2885.33,
192.07
],
"CountryF": [
3126.41,
3099.27,
3122.98,
4724.37,
3440.92,
1861.59,
2241.46
],
"CountryG": [
3518.39,
395.1,
3367.16,
3386.13,
1130.87,
731.74,
1645.6
],
"CountryH": [
1882.18,
2893.96,
2249.15,
4943.03,
600.02,
1123.5,
890.42
],
"CountryI": [
3300.23,
1341.13,
2384.92,
1297.69,
878.95,
640.84,
3316.01
],
"CountryJ": [
777.1,
1063.25,
1906.75,
4122.87,
575.8,
4205.93,
570.88
]
}代码:
import json
from pyecharts.charts import Bar, Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType
# 读取文件并解析JSON数据
with open("D:\\杂论\\GDP.txt", "r", encoding="UTF-8") as file:
data_dict = json.load(file)
my_dict = {}
for country in data_dict:
for year in range(2016, 2023, 1):
gdp = data_dict[country][year - 2016]
try:
my_dict[year].append([country, gdp])
except KeyError:
my_dict[year] = []
my_dict[year].append([country, gdp])
for year in my_dict:
my_dict[year].sort(key=lambda t: t[1], reverse=False) # 按照从大到小的形式
timeline = Timeline({"theme": ThemeType.LIGHT})
for year in range(2016, 2022):
bar = Bar()
c1 = []
t1 = []
for country in my_dict[year]:
c1.append(country[0])
t1.append(country[1])
bar.add_xaxis(c1)
bar.add_yaxis("GDP", t1, label_opts=LabelOpts(position="right"))
bar.reversal_axis() # 反转x轴和y轴
# timeline对象添加bar柱状图
# 设置每一年bar的标题
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前10GDP")
)
timeline.add(bar, f"{year}年GDP")
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
# 主题设置
# 通过时间线绘图
timeline.render("my_GDP.html")
运行结果:
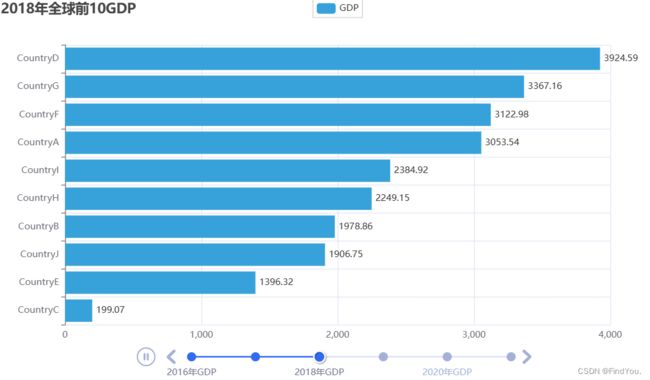
代码分析:
- json.load(file)函数会从给定的文件对象中读取全部内容,并将其解析为一个JSON数据结构。它会将文件的所有内容作为一个整体进行解析,因此需要确保被读取的文件内容是符合JSON格式的。
- 定义一个字典 my_dict 方便后面用
- 第一层for循环 是得到的是key也就是全部的国家了 gdp的获取就是data_dict[country][year - 2016]
- 为什么用try和except呢?因为我不知道当前这个year我是否已经存在在字典里面了,要是存在的话,直接就append([country, gdp]),不存在的话就创建一个字典,也就是my_dict[year] = []
- 给每个bar设置标题 bar.set_global_opts(title_opts=TitleOpts(title=f"{year}"年全球前10GDP))
- 按照gdp进行从大到小排序 对每一年的都进行排序,也就是for year in my_dict: my_dict[year].sort(key=lambda t: t[1], reverse=False), 注意key别忘写了
- 然后创建多个Bar() 利用循环去创建, 把这些bar放到timeline里面
面对对象:
初识对象:
设计类:(class)
class Student:
name = None创建对象:
stu_1 = Student()
stu_2 = Student()对象属性赋值:
stu_1.name = "Find"
stu_2.name = "You."类的定义和使用:

成员方法的定义语法:


代码:
class Student:
name = None
age = None
def say_hi(self):
print(f"大家好, 我叫{self.name}")
stu_1 = Student()
stu_1.name = "FindYou."
stu_1.say_hi()self关键字,尽管在参数列表中,但是传参的时候可以忽略它,完全不用理会
构造方法:
__init__() 前后都是两个下划线
![]()

代码演示:
self.name = name 既有定义的功能也有赋值的功能,因此 name = None等可以省略
class Student:
name = None # 可以省略
age = None
gender = None
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def Print(self):
print(f"姓名: {self.name}, 年龄: {self.age}, 性别: {self.gender}")
stu1 = Student("FindYou.", 20, "男")
stu1.Print()运行结果:
![]()
其他内置方法:
![]()
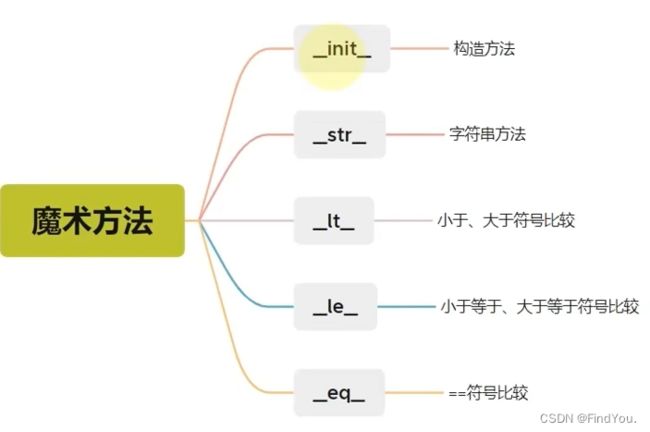
__str__ 字符串方法:
通过__str__方法,记得要 return 控制类转换为字符串的行为,类似于java里面的toString()
当使用print()函数打印一个对象时,实际上是调用了这个对象的__str__()方法。
代码:
class Student:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __str__(self): # 类似java里面的toString
return f"姓名: {self.name}, 年龄: {self.age}, 性别: {self.gender}"
print(Student("FindYou.", 20, "男"))运行结果:
![]()
__lt__ 小于符号的比较方法
lt是"less than"的缩写,表示小于的意思。
代码演示:
class Student:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __lt__(self, other):
return self.age < other.age # 按照年龄
stu1 = Student("FindYou", 20, "男")
stu2 = Student("LoveFinder", 19, "女")
print(stu1 < stu2) # False
print(stu1 > stu2) # True
运行结果:

__le__小于等于比较符号方法:
和__lt__没多大区别,就多了个等于的判断
代码:
class Student:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __le__(self, other):
return self.age <= other.age # 按照年龄
stu1 = Student("FindYou", 20, "男")
stu2 = Student("LoveFinder", 20, "女")
print(stu1 <= stu2) # True
print(stu1 >= stu2) # True
运行结果:

__eq__ 相等方法:
我才知道,python没有&& 而是and,也没有|| 而是 or
代码:
认为性别和名字和性别同时相等的时候,我们认为是同一个人
class Student:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __eq__(self, other):
return self.name == other.name and self.age == other.age and self.gender == other.gender
stu1 = Student("FindYou", 20, "男")
stu2 = Student("LoveFinder", 20, "女")
stu3 = Student("FindYou", 20, "男")
print(stu1 == stu2) # False
print(stu1 == stu3) # True
小结:

封装:
还是老样子,封装 继承 多态
私有成员:
定义私有的形式是: 变量名或者是方法名以两个下划线开头__
但是: 在 Python 中,私有变量的存在只是一种命名约定,即通过双下划线(__)开头的变量名实现。但是,Python 并不禁止直接访问和修改私有变量,只是建议开发者尽量避免这样做,以保证数据的封装性和安全性。
报错的私有变量代码:
class Student:
name = None
__score = 20 # 定义为私有的
def __Find(self):
print("I want find you")
stu1 = Student()
stu1.name = "FindYou."
print(stu1.__score)报错的原因分析:
这个代码报错的原因是因为尝试直接访问私有变量 __score 而不是使用名称修饰的方式。
在 Python 中,私有变量使用双下划线(__)前缀进行定义,以表示它们是类内部的私有成员。私有变量的目的是限制对其直接访问,只能通过类内部的方法来访问和修改。
当你尝试直接访问 stu1.__score 时,Python 会将其视为一个普通的实例变量,而不是私有变量。因此,Python 会在 stu1 实例中查找名为 __score 的变量,但由于该变量是私有的,无法从外部直接访问。
为了正确访问私有变量 __score,需要使用名称修饰的方式:stu1._Student__score。这样,你将能够访问到类中真正的私有变量。
改正后的代码:
在 Python 中,当在定义属性或方法时使用了双下划线(__)时,Python 会将其名称进行重命名以避免与其他类中的名称冲突,这种重命名方式为 _ClassName__name 的形式。
在你的代码中,__score 属性被重命名为 _Student__score,因此通过 stu1._Student__score 可以访问到该属性的值。虽然这种方式可以绕过属性的访问限制,但并不建议这样做,因为这种行为违背了私有属性的封装性原则。
class Student:
name = None
__score = 20 # 定义为私有的
def __Find(self):
print("I want find you")
stu1 = Student()
stu1.name = "FindYou."
print(stu1._Student__score) # 20报错的私有成员方法:
class Student:
name = None
__score = 20 # 定义为私有的
def __Find(self):
print("I want find you")
stu1 = Student()
stu1.name = "FindYou."
print(stu1.__Find())运行结果:

报错的代码分析:
这段代码会导致 AttributeError 错误( Python 中的一个内置异常类,用于指示发生了属性访问错误)。出现这个错误的原因是因为尝试直接访问一个私有方法 __Find。
在 Python 中,以双下划线(__)开头命名的方法是私有方法,它们只能在类的内部被访问,无法从外部直接调用
通过 _Student__Find() 的方式绕过访问限制来调用私有方法,但这种做法违背了封装的原则。
改正后的代码:
class Student:
name = None
__score = 20 # 定义为私有的
def __Find(self):
print("I want find you")
stu1 = Student()
stu1.name = "FindYou."
stu1._Student__Find() # I want find you