- 【C语言小游戏】贪吃蛇
鱼弦
游戏开发c语言数学建模开发语言
鱼弦:CSDN内容合伙人、CSDN新星导师、51CTO(Top红人+专家博主)、github开源爱好者(go-zero源码二次开发、游戏后端架构https://github.com/Peakchen)贪吃蛇是一个经典的小游戏,以下是贪吃蛇的原理详细解释、使用场景解释,以及一些相关的文献材料链接和当前使用贪吃蛇的产品。原理详细解释:贪吃蛇游戏的原理是在一个有边界的游戏界面上控制一条蛇移动,蛇会不断吃
- RocketMQ 5.x 架构与端口差异、Java客户端代码示例及修改 RocketMQ Proxy 默认端口
RocketMQ5.x端口差异及代码解释端口差异的原因在RocketMQ5.x版本中,端口使用与之前版本不同,主要原因如下:架构变化:RocketMQ5.x引入了新的Proxy模块,作为客户端与Broker之间的中间层默认端口:4.x版本:NameServer默认端口9876,Broker默认端口109115.x版本:Proxy默认端口8080/8081分离设计:5.x将路由发现与消息传输分离,客
- Hadoop入门案例WordCount
码喵喵
hadoopmapreduce大数据
wordcount可以说是hadoop的入门案例,也是基础案例主要体现思想就是mapreduce核心思想原始文件为hadoop.txt,内容如下:hello,javahello,java,linux,hadoophadoop,java,linuxhello,java,linuxlinux,c,javac,php,java在整个文件中单词所出现的次数Hadoop思维:Mapreduce-----》M
- 【设计模式09】组合模式
鼠鼠我呀2
设计模式设计模式组合模式
前言适用于树形结构,如公司的组织架构,目录和文件夹UML类图代码示例packagecom.sw.learn.pattern.C_structre.c_composite;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.stereotype.Component;importj
- Hadoop入门案例
'Wu'
学习日常大数据hadoophdfs大数据
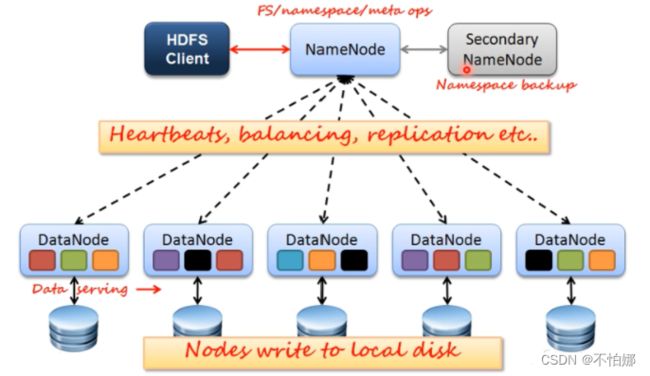
Hadoop的运行流程:客户端向HDFS请求文件存储或使用MapReduce计算。NameNode负责管理整个HDFS系统中的所有数据块和元数据信息;DataNode则实际存储和管理数据块。客户端通过NameNode查找需要访问或处理的文件所在的DataNode,并将操作请求发送到相应的DataNode上。当客户端上传一个新文件时(比如输入某些日志),它会被分成固定大小(默认64MB)并进行数据复
- MVC与MVVM架构模式详解:原理、区别与JavaScript实现
布兰妮甜
javascriptmvcmvvm架构
Hi,我是布兰妮甜!在当今复杂的前端开发领域,如何组织代码结构一直是开发者面临的核心挑战。MVC和MVVM作为两种经典的架构模式,为前端应用提供了清晰的责任划分和可维护的代码组织方案。本文将深入探讨这两种模式的原理、实现差异以及在实际项目中的应用场景,通过JavaScript代码示例展示它们的核心思想,帮助开发者理解如何根据项目需求选择合适的架构模式。文章目录一、架构模式概述二、MVC架构模式2.
- 揭开 MCP 的神秘面纱:标准化 AI 上下文管理的未来(上)
愤怒的可乐
大模型自然语言处理人工智能python开发语言
引言最近MCP大火,本文尝试揭开它神秘的面纱。文章较长,分为上下两篇。架构MCP协议遵循客户端-主机-服务器架构,其中一个主机应用运行多个客户端实例,每个客户端实例维护了和服务器建立的独立的连接。Host:希望通过MCP访问数据的程序,比如一个聊天应用程序。Client:与服务器保持1:1连接(会话)的客户端,Host通过这个Client连接不同的Server提供的功能。Server:通过MCP公
- Llama改进之——RoPE旋转位置编码
愤怒的可乐
NLP项目实战#LLaMARoPE旋转位置编码
引言旋转位置编码(RotaryPositionEmbedding,RoPE)将绝对相对位置依赖纳入自注意力机制中,以增强Transformer架构的性能。目前很火的大模型LLaMA、QWen等都应用了旋转位置编码。之前在[论文笔记]ROFORMER中对旋转位置编码的原始论文进行了解析,重点推导了旋转位置编码的公式,本文侧重实现,同时尽量简化数学上的推理,详细推理可见最后的参考文章。复数与极坐标复数
- ATmega16微控制器编程与应用实践
love彤彤
本文还有配套的精品资源,点击获取简介:ATmega16是一个基于AVR架构的8位微控制器,广泛用于嵌入式系统控制应用。本文将详细介绍如何在ATmega16上实现1602液晶显示、独立键盘操作、数码管扫描、蜂鸣器控制和流水灯设计等常用功能。通过这些功能的实践项目,读者可以掌握C语言在嵌入式系统开发中的应用,包括I/O口编程、定时器设置、中断处理和串行通信等关键技术。1.ATmega16微控制器简介A
- 手把手从零打造 Llama3:解锁下一代预训练模型
会飞的Anthony
信息系统人工智能AIGC自然语言处理人工智能llama3AIGC
引言Llama3相较于Llama2,不仅在模型架构上做了显著优化,尤其是全局查询注意力机制(GQA)的引入,使得模型在大规模数据处理上表现更加出色。同时,Llama3采用了与GPT一致的tiktoken分词器,大幅提升了分词效率。本篇文章将带你从头构建Llama3预训练流程,深入了解其关键细节和实现方式,让你掌握这一下一代模型的核心技术。1.启动训练脚本在这一步中,我们将实现Llama3的预训练框
- 从零实现Llama3:深入解析Transformer架构与实现细节
祁婉菲Flora
从零实现Llama3:深入解析Transformer架构与实现细节llama3-from-scratchllama3一次实现一个矩阵乘法。项目地址:https://gitcode.com/gh_mirrors/ll/llama3-from-scratch引言本文将深入探讨如何从零开始实现Llama3语言模型。我们将从最基本的张量操作开始,逐步构建完整的Transformer架构。通过这个过程,读者
- 音视频会议服务搭建(设计方案)-01
卜锦元
音视频webrtcgolang流媒体websocket音视频
前言最近在做音视频会议系统服务搭建的工作任务,因为内容过多,我会逐篇分享相关的设计方案、开发思路、编程语言、使用的组件集合等等。如果你也有大型音视频会议系统搭建架构的需求,希望这些可以对你有所帮助。EchoMeet音视频会议系统架构设计项目概述EchoMeet是基于WebRTC技术的企业级音视频会议解决方案,采用三层音视频架构和Go+Node.js双后端微服务设计,实现了高并发、低延迟、可扩展的视
- 音视频会议服务搭建(设计方案-两种集成方案对比)-03
卜锦元
流媒体websocket音视频webrtcgolang音视频gonode.jswebrtcc++redismysql
前言在开始计划之前,查阅了不少资料。一种方案是Go层做信令业务,nodejs层来管理和mediasoup的底层交互,通过客户端去调用Go层;第二种方案是客户端直接调用nodejs层来跟mediasoup去交互;最终,当然不出意料的选择了项目复杂的构建方案,为性能去考虑。EchoMeet架构方案对比分析1.两种架构方案概览方案A:Go+Node.js双系统架构(当前方案)前端Vue3+mediaso
- NUMA 架构科普:双路 CPU 系统是如何构建的?
NUMA(Non-UniformMemoryAccess,非一致性内存访问)是一种用于多处理器系统的内存架构设计,主要应用于服务器、工作站和高性能计算(HPC)领域。它的核心特点是不同CPU访问不同内存区域的速度不一致,这与传统的UMA(UniformMemoryAccess,一致性内存访问)架构不同。1.NUMA的物理结构(1)双路CPU系统的硬件组成在典型的双路(2P)服务器主板上,会有:2颗
- Web 服务器架构选择深度解析
后端
在Web服务与API设计中,服务器架构的选择直接决定系统的可扩展性、维护成本与性能上限。本文从架构演进脉络出发,系统解析单体架构、微服务、服务网格、Serverless等主流架构的核心特性、适用场景及Java技术栈实现。一、架构演进与核心分类1.1架构演进脉络1.2核心架构对比表架构类型核心特点典型技术栈(Java)部署复杂度扩展性单体架构所有功能模块打包为单一应用,共享数据库SpringBoot
- 为什么YashanDB数据库是大数据处理的理想选择?
数据库
在当今大数据时代,如何高效管理和处理海量数据成为了许多企业的首要挑战。针对这一问题,选择合适的数据库系统至关重要。尤其是在大数据场景中,诸如数据存储、数据访问效率和并发控制等技术要求提高,给数据库的选择带来了更高的标准。YashanDB作为一款高性能数据库,以其独特的架构设计与一系列优秀的功能,成为大数据处理的理想选择。高度可扩展的部署架构YashanDB支持多种部署形态,包括单机部署、分布式集群
- 为什么YashanDB适合中小企业?成本效益分析
数据库
在中小企业的运营中,有效的数据管理和访问是确保业务顺利进行的关键。然而,许多企业在选择合适的数据库时,面临着如何在性能与成本之间取得平衡的挑战。选择一个高效、经济的数据库系统至关重要,这不仅关系到数据的存储和查询效率,还影响到企业长远的经营成本与风险应对能力。YashanDB作为一款新兴的开源数据库,无疑是中小企业在寻找强大功能与高性价比解决方案时的理想选择。数据库体系架构与部署选项YashanD
- 什么是YashanDB?深入解析企业级数据库解决方案
数据库
在现代企业数据管理中,数据库技术面临着多个挑战,包括性能瓶颈、数据一致性以及高可用性等问题。随着数据量的激增和应用需求的多样化,传统数据库架构逐渐显示出其局限性。在此背景下,YashanDB作为一种新兴的企业级数据库解决方案,凭借其独特的架构和高效的数据处理能力受到越来越多企业的青睐。本文将深入探讨YashanDB的核心技术及其在企业级应用场景中所带来的优势,帮助开发人员及数据库管理员更好地理解这
- 企业为什么选择YashanDB数据库?七大核心优势解析
数据库
在快速发展的信息化时代,企业在选择数据库时面临许多挑战,包括性能瓶颈、数据一致性、可扩展性和高可用性等。随着数据量的不断增长,传统数据库难以满足日益增长的需求,企业需要一种更为高效、稳定的解决方案。YashanDB数据库凭借其独特的体系架构和丰富的功能逐渐崭露头角,成为企业数据存储和管理的优选平台。本文旨在深入剖析YashanDB的七大核心优势,帮助读者更好地理解其价值。高性能YashanDB采用
- 企业如何通过YashanDB实现数据的实时同步与备份?
数据库
在当今数据驱动的商业环境中,数据的实时同步与备份变得越来越重要。企业在运作中倘若未能有效管理数据同步及备份,不仅会影响业务效率,也会增加数据丢失的风险。如何实现高效、可靠的数据实时同步与备份,成为企业IT部门亟待解决的技术问题。YashanDB作为一款优秀的数据库,具备强大的实时同步与备份能力,为企业提供了有效的解决方案。YashanDB的部署架构YashanDB支持三种部署形态:单机部署、共享集
- 企业如何利用YashanDB提升系统稳定性
数据库
在现代多变的商业环境中,企业面临着信息处理能力的诸多挑战,如系统崩溃、数据丢失等。为应对这些挑战,提升数据库系统的稳定性显得尤为重要。YashanDB作为一款先进的分布式数据库,凭借其独特的架构和技术特性,能够为企业提供更为可靠的系统稳定性保障。本文将深入分析YashanDB提升系统稳定性的核心技术点及其优势。核心技术点高可用性架构YashanDB支持多种部署模式,如单机主备部署、分布式集群部署以
- 企业如何利用YashanDB实现数据资产价值最大化
数据库
在当今数据驱动的经济环境中,企业面临着如何有效优化数据管理以提升业务竞争力的挑战。尤其是数据库技术的应用能力,往往会直接影响到数据处理效率和决策支持的速度。因此,企业需要寻找有效的战略,比如"如何优化查询速度?"来实现数据资产的最大化。从而提升组织的决策质量及用户体验,有效推动业务创新。YashanDB体系架构与核心技术优势YashanDB作为一款现代化的数据库管理系统,其体系架构灵活多样,支持单
- 企业如何构建基于YashanDB的数据分析系统
数据库
随着大数据时代的到来,企业面临的一个核心技术问题是如何有效、快速地进行数据分析以指导决策。一个重要的性能瓶颈在于数据库的查询速度和存储结构的设计。尤其在处理海量数据时,如何在保证数据查询性能的同时确保数据的准确性和完整性,这问题显得尤为重要。YashanDB作为一个高性能的数据库系统,通过其独特的体系架构和强大的数据存储及访问机制,为企业构建高效的数据分析系统提供了可靠的技术支持。YashanDB
- 从用户需求出发设计YashanDB数据库的架构
数据库
在现代应用中,性能和可扩展性是数据库设计中至关重要的指标。随着数据量的增加,如何在保持高性能的前提下支持复杂的查询需求,已经成为数据库产业面临的一大难题。因此,当前迫切需要一种灵活和高效的数据库架构,能适应变动的用户需求,同时提供良好的业务连续性和可靠性。YashanDB的体系架构部署架构YashanDB支持三种主要的部署架构,包括单机部署、分布式集群部署和共享集群部署。单机部署:适用于小型应用和
- 从入门到精通:YashanDB数据库学习指南
数据库
在现代的数据库技术领域,性能瓶颈和数据一致性问题是开发人员和数据库管理员(DBA)面临的重要挑战。随着数据量的激增和对实时分析的需求上升,如何有效管理和利用数据库显得尤为重要。YashanDB作为一款新兴数据库,提供了一系列功能以应对这些挑战,适合希望深入理解数据库体系结构的开发者和DBA。本文旨在提供一份全面的YashanDB学习指南,内容涵盖系统架构、核心功能,并为实际应用提供具体建议,使读者
- 10倍速开发!飞算JavaAI实战:5分钟生成SpringCloud完整工程
LCG元
工具Python深度学习人工智能springcloudspring后端
目录一、颠覆性架构设计二、5分钟生成实战步骤1:定义服务架构(YAML配置)步骤2:执行AI生成命令(Python驱动)步骤3:验证生成结果(终端操作)三、双流程图解析横向对比:传统开发vsAI生成纵向核心流程四、量化性能对比五、生产级部署方案安全审计实现高可用部署架构六、技术前瞻性分析七、附录:完整技术图谱传统SpringCloud工程搭建平均耗时8小时,而使用飞算JavaAI只需5分钟,开发效
- 微服务介绍
背景:从单体架构到微服务的驱动力单体架构的痛点:初期简单:开发部署快,适合创业公司或小型项目(如简单的博客系统或早期电商平台)。后期瓶颈显著:可伸缩性差:用户量和流量激增时,单服务器性能成为瓶颈。单纯通过集群(复制整个应用)缓解,资源利用率不高且成本增加。复杂性高、耦合紧:业务膨胀导致代码库庞大臃肿,模块间高度耦合。修改一个小功能可能需编译、测试、部署整个应用,风险高、效率低。技术栈僵化:整个应用
- 计算机网络深度解析:HTTPS协议架构与安全机制全揭秘(2025演进版)
知识产权13937636601
计算机计算机网络https架构
摘要2025年全球HTTPS流量占比达99.7%(W3Techs数据),本文系统剖析HTTPS协议的技术演进与安全机制。从加密算法体系(国密SM2/3/4vsRSA/ECC)、TLS1.3协议超时优化、后量子密码迁移路径三大突破切入,结合OpenSSL3.2、BoringSSL实战案例,详解协议握手时延降低80%的底层逻辑,并首次公开混合加密、证书透明度、密钥交换攻击防御等关键工程部署策略,为开发
- 大规模分布式数据库读写分离架构:一致性、可用性与性能的权衡实践
目录1引言:数据库架构的核心三角2原创架构设计2.1读写分离系统架构2.2读写核心流程3企业级实现代码3.1Python路由服务核心代码3.2TypeScript复制状态监控3.3Kubernetes部署YAML示例4性能对比量化分析5生产级部署与安全方案5.1高可用部署架构5.2安全审计方案6技术前瞻性分析6.1演进路线图6.2关键趋势解读7附录:完整技术图谱结论1引言:数据库架构的核心三角在大
- 解密GPT工作原理:Transformer架构详解与自注意力机制剖析
AI智能应用
gpttransformer架构ai
解密GPT工作原理:Transformer架构详解与自注意力机制剖析关键词:GPT、Transformer、自注意力机制、神经网络、语言模型、深度学习、人工智能摘要:本文将深入浅出地解析GPT模型的核心架构——Transformer,重点剖析其革命性的自注意力机制。我们将从基本概念出发,通过生活化的比喻解释复杂的技术原理,并用Python代码示例展示实现细节,最后探讨这一技术的应用场景和未来发展方
- JAVA基础
灵静志远
位运算加载Date字符串池覆盖
一、类的初始化顺序
1 (静态变量,静态代码块)-->(变量,初始化块)--> 构造器
同一括号里的,根据它们在程序中的顺序来决定。上面所述是同一类中。如果是继承的情况,那就在父类到子类交替初始化。
二、String
1 String a = "abc";
JAVA虚拟机首先在字符串池中查找是否已经存在了值为"abc"的对象,根
- keepalived实现redis主从高可用
bylijinnan
redis
方案说明
两台机器(称为A和B),以统一的VIP对外提供服务
1.正常情况下,A和B都启动,B会把A的数据同步过来(B is slave of A)
2.当A挂了后,VIP漂移到B;B的keepalived 通知redis 执行:slaveof no one,由B提供服务
3.当A起来后,VIP不切换,仍在B上面;而A的keepalived 通知redis 执行slaveof B,开始
- java文件操作大全
0624chenhong
java
最近在博客园看到一篇比较全面的文件操作文章,转过来留着。
http://www.cnblogs.com/zhuocheng/archive/2011/12/12/2285290.html
转自http://blog.sina.com.cn/s/blog_4a9f789a0100ik3p.html
一.获得控制台用户输入的信息
&nbs
- android学习任务
不懂事的小屁孩
工作
任务
完成情况 搞清楚带箭头的pupupwindows和不带的使用 已完成 熟练使用pupupwindows和alertdialog,并搞清楚两者的区别 已完成 熟练使用android的线程handler,并敲示例代码 进行中 了解游戏2048的流程,并完成其代码工作 进行中-差几个actionbar 研究一下android的动画效果,写一个实例 已完成 复习fragem
- zoom.js
换个号韩国红果果
oom
它的基于bootstrap 的
https://raw.github.com/twbs/bootstrap/master/js/transition.js transition.js模块引用顺序
<link rel="stylesheet" href="style/zoom.css">
<script src=&q
- 详解Oracle云操作系统Solaris 11.2
蓝儿唯美
Solaris
当Oracle发布Solaris 11时,它将自己的操作系统称为第一个面向云的操作系统。Oracle在发布Solaris 11.2时继续它以云为中心的基调。但是,这些说法没有告诉我们为什么Solaris是配得上云的。幸好,我们不需要等太久。Solaris11.2有4个重要的技术可以在一个有效的云实现中发挥重要作用:OpenStack、内核域、统一存档(UA)和弹性虚拟交换(EVS)。
- spring学习——springmvc(一)
a-john
springMVC
Spring MVC基于模型-视图-控制器(Model-View-Controller,MVC)实现,能够帮助我们构建像Spring框架那样灵活和松耦合的Web应用程序。
1,跟踪Spring MVC的请求
请求的第一站是Spring的DispatcherServlet。与大多数基于Java的Web框架一样,Spring MVC所有的请求都会通过一个前端控制器Servlet。前
- hdu4342 History repeat itself-------多校联合五
aijuans
数论
水题就不多说什么了。
#include<iostream>#include<cstdlib>#include<stdio.h>#define ll __int64using namespace std;int main(){ int t; ll n; scanf("%d",&t); while(t--)
- EJB和javabean的区别
asia007
beanejb
EJB不是一般的JavaBean,EJB是企业级JavaBean,EJB一共分为3种,实体Bean,消息Bean,会话Bean,书写EJB是需要遵循一定的规范的,具体规范你可以参考相关的资料.另外,要运行EJB,你需要相应的EJB容器,比如Weblogic,Jboss等,而JavaBean不需要,只需要安装Tomcat就可以了
1.EJB用于服务端应用开发, 而JavaBeans
- Struts的action和Result总结
百合不是茶
strutsAction配置Result配置
一:Action的配置详解:
下面是一个Struts中一个空的Struts.xml的配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
&quo
- 如何带好自已的团队
bijian1013
项目管理团队管理团队
在网上看到博客"
怎么才能让团队成员好好干活"的评论,觉得写的比较好。 原文如下: 我做团队管理有几年了吧,我和你分享一下我认为带好团队的几点:
1.诚信
对团队内成员,无论是技术研究、交流、问题探讨,要尽可能的保持一种诚信的态度,用心去做好,你的团队会感觉得到。 2.努力提
- Java代码混淆工具
sunjing
ProGuard
Open Source Obfuscators
ProGuard
http://java-source.net/open-source/obfuscators/proguardProGuard is a free Java class file shrinker and obfuscator. It can detect and remove unused classes, fields, m
- 【Redis三】基于Redis sentinel的自动failover主从复制
bit1129
redis
在第二篇中使用2.8.17搭建了主从复制,但是它存在Master单点问题,为了解决这个问题,Redis从2.6开始引入sentinel,用于监控和管理Redis的主从复制环境,进行自动failover,即Master挂了后,sentinel自动从从服务器选出一个Master使主从复制集群仍然可以工作,如果Master醒来再次加入集群,只能以从服务器的形式工作。
什么是Sentine
- 使用代理实现Hibernate Dao层自动事务
白糖_
DAOspringAOP框架Hibernate
都说spring利用AOP实现自动事务处理机制非常好,但在只有hibernate这个框架情况下,我们开启session、管理事务就往往很麻烦。
public void save(Object obj){
Session session = this.getSession();
Transaction tran = session.beginTransaction();
try
- maven3实战读书笔记
braveCS
maven3
Maven简介
是什么?
Is a software project management and comprehension tool.项目管理工具
是基于POM概念(工程对象模型)
[设计重复、编码重复、文档重复、构建重复,maven最大化消除了构建的重复]
[与XP:简单、交流与反馈;测试驱动开发、十分钟构建、持续集成、富有信息的工作区]
功能:
- 编程之美-子数组的最大乘积
bylijinnan
编程之美
public class MaxProduct {
/**
* 编程之美 子数组的最大乘积
* 题目: 给定一个长度为N的整数数组,只允许使用乘法,不能用除法,计算任意N-1个数的组合中乘积中最大的一组,并写出算法的时间复杂度。
* 以下程序对应书上两种方法,求得“乘积中最大的一组”的乘积——都是有溢出的可能的。
* 但按题目的意思,是要求得这个子数组,而不
- 读书笔记-2
chengxuyuancsdn
读书笔记
1、反射
2、oracle年-月-日 时-分-秒
3、oracle创建有参、无参函数
4、oracle行转列
5、Struts2拦截器
6、Filter过滤器(web.xml)
1、反射
(1)检查类的结构
在java.lang.reflect包里有3个类Field,Method,Constructor分别用于描述类的域、方法和构造器。
2、oracle年月日时分秒
s
- [求学与房地产]慎重选择IT培训学校
comsci
it
关于培训学校的教学和教师的问题,我们就不讨论了,我主要关心的是这个问题
培训学校的教学楼和宿舍的环境和稳定性问题
我们大家都知道,房子是一个比较昂贵的东西,特别是那种能够当教室的房子...
&nb
- RMAN配置中通道(CHANNEL)相关参数 PARALLELISM 、FILESPERSET的关系
daizj
oraclermanfilespersetPARALLELISM
RMAN配置中通道(CHANNEL)相关参数 PARALLELISM 、FILESPERSET的关系 转
PARALLELISM ---
我们还可以通过parallelism参数来指定同时"自动"创建多少个通道:
RMAN > configure device type disk parallelism 3 ;
表示启动三个通道,可以加快备份恢复的速度。
- 简单排序:冒泡排序
dieslrae
冒泡排序
public void bubbleSort(int[] array){
for(int i=1;i<array.length;i++){
for(int k=0;k<array.length-i;k++){
if(array[k] > array[k+1]){
- 初二上学期难记单词三
dcj3sjt126com
sciet
concert 音乐会
tonight 今晚
famous 有名的;著名的
song 歌曲
thousand 千
accident 事故;灾难
careless 粗心的,大意的
break 折断;断裂;破碎
heart 心(脏)
happen 偶尔发生,碰巧
tourist 旅游者;观光者
science (自然)科学
marry 结婚
subject 题目;
- I.安装Memcahce 1. 安装依赖包libevent Memcache需要安装libevent,所以安装前可能需要执行 Shell代码 收藏代码
dcj3sjt126com
redis
wget http://download.redis.io/redis-stable.tar.gz
tar xvzf redis-stable.tar.gz
cd redis-stable
make
前面3步应该没有问题,主要的问题是执行make的时候,出现了异常。
异常一:
make[2]: cc: Command not found
异常原因:没有安装g
- 并发容器
shuizhaosi888
并发容器
通过并发容器来改善同步容器的性能,同步容器将所有对容器状态的访问都串行化,来实现线程安全,这种方式严重降低并发性,当多个线程访问时,吞吐量严重降低。
并发容器ConcurrentHashMap
替代同步基于散列的Map,通过Lock控制。
&nb
- Spring Security(12)——Remember-Me功能
234390216
Spring SecurityRemember Me记住我
Remember-Me功能
目录
1.1 概述
1.2 基于简单加密token的方法
1.3 基于持久化token的方法
1.4 Remember-Me相关接口和实现
- 位运算
焦志广
位运算
一、位运算符C语言提供了六种位运算符:
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移
1. 按位与运算 按位与运算符"&"是双目运算符。其功能是参与运算的两数各对应的二进位相与。只有对应的两个二进位均为1时,结果位才为1 ,否则为0。参与运算的数以补码方式出现。
例如:9&am
- nodejs 数据库连接 mongodb mysql
liguangsong
mongodbmysqlnode数据库连接
1.mysql 连接
package.json中dependencies加入
"mysql":"~2.7.0"
执行 npm install
在config 下创建文件 database.js
- java动态编译
olive6615
javaHotSpotjvm动态编译
在HotSpot虚拟机中,有两个技术是至关重要的,即动态编译(Dynamic compilation)和Profiling。
HotSpot是如何动态编译Javad的bytecode呢?Java bytecode是以解释方式被load到虚拟机的。HotSpot里有一个运行监视器,即Profile Monitor,专门监视
- Storm0.9.5的集群部署配置优化
roadrunners
优化storm.yaml
nimbus结点配置(storm.yaml)信息:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional inf
- 101个MySQL 的调节和优化的提示
tomcat_oracle
mysql
1. 拥有足够的物理内存来把整个InnoDB文件加载到内存中——在内存中访问文件时的速度要比在硬盘中访问时快的多。 2. 不惜一切代价避免使用Swap交换分区 – 交换时是从硬盘读取的,它的速度很慢。 3. 使用电池供电的RAM(注:RAM即随机存储器)。 4. 使用高级的RAID(注:Redundant Arrays of Inexpensive Disks,即磁盘阵列
- zoj 3829 Known Notation(贪心)
阿尔萨斯
ZOJ
题目链接:zoj 3829 Known Notation
题目大意:给定一个不完整的后缀表达式,要求有2种不同操作,用尽量少的操作使得表达式完整。
解题思路:贪心,数字的个数要要保证比∗的个数多1,不够的话优先补在开头是最优的。然后遍历一遍字符串,碰到数字+1,碰到∗-1,保证数字的个数大于等1,如果不够减的话,可以和最后面的一个数字交换位置(用栈维护十分方便),因为添加和交换代价都是1