JavaWeb——第四章 XML_Tomcat10_HTTP
第四章 XML_Tomcat10_HTTP
- 1. XML
-
- 1.1 常见配置文件类型
-
- 1.1.1 properties配置文件
- 1.1.2 xml配置文件
- 1.2 DOM4J进行XML解析
-
- 1.2.1 DOM4J的使用步骤
- 1.2.2 DOM4J的API介绍
- 2. Tomcat10
-
- 2.1 WEB服务器
- 2.2 Tomcat服务器
-
- 2.2.1 简介
- 2.2.2 安装
- 2.3 Tomcat目录及测试
- 2.4 WEB项目的标准结构
- 2.5 WEB项目部署的方式
- 2.6 IDEA中开发并部署运行WEB项目
-
- 2.6.1 IDEA关联本地Tomcat
- 2.6.2 IDEA创建web工程
- 2.6.3 IDEA部署-运行web项目
- 3. HTTP协议
-
- 3.1 HTTP简介
-
- 3.1.1 发展历程
- 3.1.2 HTTP协议的会话方式
- 3.1.3 HTTP1.0和HTTP1.1的区别
- 3.1.4 在浏览器中通过F12工具抓取请求响应报文包
- 3.2 请求和响应报文
-
- 3.2.1 报文的格式
- 3.2.2 请求报文
- 3.2.3 响应报文
1. XML

XML是EXtensible Markup Language的缩写,翻译过来就是可扩展标记语言。所以很明显,XML和HTML一样都是标记语言,也就是说它们的基本语法都是标签。
-
可扩展 三个字表面上的意思是XML允许自定义格式。但这不代表你可以随便写。
-
在XML基本语法规范的基础上,你使用的那些第三方应用程序、框架会通过XML约束的方式强制规定配置文件中可以写什么和怎么写
-
XML基本语法这个知识点的定位是:我们不需要从零开始,从头到尾的一行一行编写XML文档,而是在第三方应用程序、框架已提供的配置文件的基础上修改。要改成什么样取决于你的需求,而怎么改取决XML基本语法和具体的XML约束。
1.1 常见配置文件类型
- properties文件,例如druid连接池就是使用properties文件作为配置文件
- XML文件,例如Tomcat就是使用XML文件作为配置文件
- YAML文件,例如SpringBoot就是使用YAML作为配置文件
- json文件,通常用来做文件传输,也可以用来做前端或者移动端的配置文件
- 等等…
1.1.1 properties配置文件
示例
atguigu.jdbc.url=jdbc:mysql://localhost:3306/atguigu
atguigu.jdbc.driver=com.mysql.cj.jdbc.Driver
atguigu.jdbc.username=root
atguigu.jdbc.password=root
语法规范
- 由键值对组成
- 键和值之间的符号是等号
- 每一行都必须顶格写,前面不能有空格之类的其他符号
1.1.2 xml配置文件
示例
<students>
<student>
<name>张三name>
<age>18age>
student>
<student>
<name>李四name>
<age>20age>
student>
students>
XML的基本语法
- XML的基本语法和HTML的基本语法简直如出一辙。其实这不是偶然的,XML基本语法+HTML约束=HTML语法。在逻辑上HTML确实是XML的子集。
- XML文档声明 这部分基本上就是固定格式,要注意的是文档声明一定要从第一行第一列开始写
- 根标签
- 根标签有且只能有一个。
- 标签关闭
- 双标签:开始标签和结束标签必须成对出现。
- 单标签:单标签在标签内关闭。
- 标签嵌套
- 可以嵌套,但是不能交叉嵌套。
- 注释不能嵌套
- 标签名、属性名建议使用小写字母
- 属性
- 属性必须有值
- 属性值必须加引号,单双都行
XML的约束(稍微了解)
将来我们主要就是根据XML约束中的规定来编写XML配置文件,而且会在我们编写XML的时候根据约束来提示我们编写, 而XML约束主要包括DTD和Schema两种。
- DTD
- Schema
Schema约束要求我们一个XML文档中,所有标签,所有属性都必须在约束中有明确的定义。
下面我们以web.xml的约束声明为例来做个说明:
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
1.2 DOM4J进行XML解析
1.2.1 DOM4J的使用步骤
- 导入jar包 dom4j.jar
- 创建解析器对象(SAXReader)
- 解析xml 获得Document对象
- 获取根节点RootElement
- 获取根节点下的子节点
1.2.2 DOM4J的API介绍
1.创建SAXReader对象
SAXReader saxReader = new SAXReader();
2. 解析XML获取Document对象: 需要传入要解析的XML文件的字节输入流
Document document = reader.read(inputStream);
3. 获取文档的根标签
Element rootElement = documen.getRootElement()
4. 获取标签的子标签
//获取所有子标签
List<Element> sonElementList = rootElement.elements();
//获取指定标签名的子标签
List<Element> sonElementList = rootElement.elements("标签名");
5. 获取标签体内的文本
String text = element.getText();
6. 获取标签的某个属性的值
String value = element.attributeValue("属性名");
2. Tomcat10
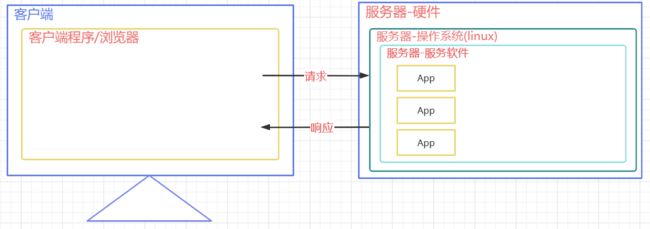
2.1 WEB服务器
Web服务器通常由硬件和软件共同构成。
- 硬件:电脑,提供服务供其它客户电脑访问
- 软件:电脑上安装的服务器软件,安装后能提供服务给网络中的其他计算机,将本地文件映射成一个虚拟的url地址供网络中的其他人访问。
常见的JavaWeb服务器:
- Tomcat(Apache):当前应用最广的JavaWeb服务器
- Jetty:更轻量级、更灵活的servlet容器
- JBoss(Redhat红帽):支持JavaEE,应用比较广EJB容器 –> SSH轻量级的框架代替
- GlassFish(Orcale):Oracle开发JavaWeb服务器,应用不是很广
- Resin(Caucho):支持JavaEE,应用越来越广
- Weblogic(Orcale):要钱的!支持JavaEE,适合大型项目
- Websphere(IBM):要钱的!支持JavaEE,适合大型项目
2.2 Tomcat服务器
2.2.1 简介

Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。最新的Servlet 和JSP 规范总是能在Tomcat 中得到体现,因为Tomcat 技术先进、性能稳定,而且免费,因而深受Java 爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web 应用服务器。
2.2.2 安装
版本
- 版本:企业用的比较广泛的是8.0和9.0,目前比较新正式发布版本是Tomcat10.0, Tomcat11仍然处于测试阶段。
- JAVAEE 版本和Servlet版本号对应关系 Jakarta EE Releases
| Servlet Version | EE Version |
|---|---|
| 6.1 | Jakarta EE ? |
| 6.0 | Jakarta EE 10 |
| 5.0 | Jakarta EE 9/9.1 |
| 4.0 | JAVA EE 8 |
| 3.1 | JAVA EE 7 |
| 3.1 | JAVA EE 7 |
| 3.0 | JAVAEE 6 |
- Tomcat 版本和Servlet版本之间的对应关系
| Servlet Version | **Tomcat ** Version | JDK Version |
|---|---|---|
| 6.1 | 11.0.x | 17 and later |
| 6.0 | 10.1.x | 11 and later |
| 5.0 | 10.0.x (superseded) | 8 and later |
| 4.0 | 9.0.x | 8 and later |
| 3.1 | 8.5.x | 7 and later |
| 3.1 | 8.0.x (superseded) | 7 and later |
| 3.0 | 7.0.x (archived) | 6 and later (7 and later for WebSocket) |
下载
- Tomcat官方网站:http://tomcat.apache.org/
- 安装版:需要安装,一般不考虑使用。
- 解压版: 直接解压缩使用,我们使用的版本。
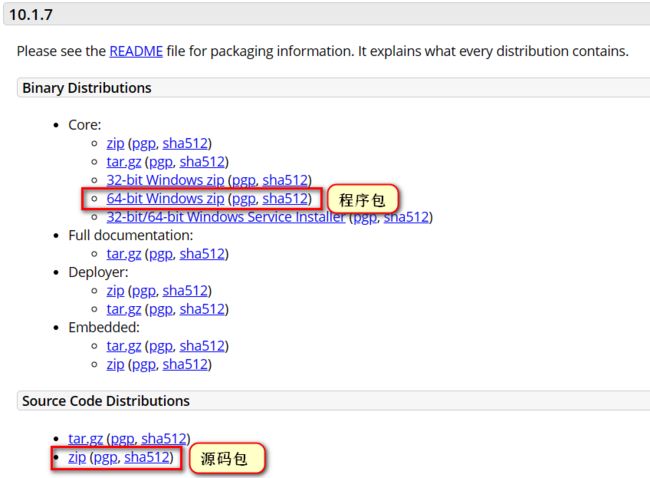
安装
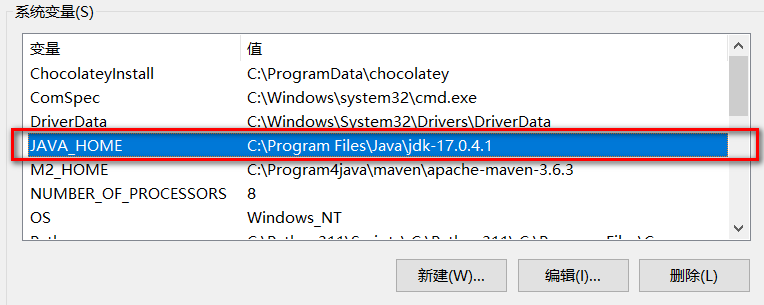
- 正确安装JDK并配置JAVA_HOME(以JDK17为例 https://injdk.cn中可以下载各种版本的JDK)
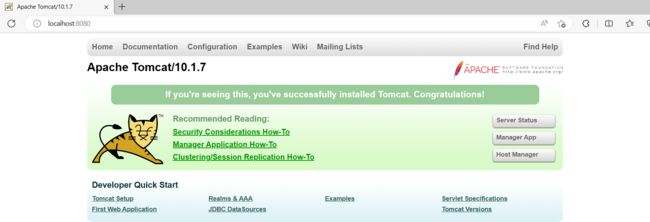
- 解压tomcat到非中文无空格目录

- 点击bin/startup.bat启动


- 打开浏览器输入 http://localhost:8080访问测试
- 直接关闭窗口或者运行 bin/shutdown.bat关闭tomcat
- 处理dos窗口日志中文乱码问题: 修改conf/logging.properties,将所有的UTF-8修改为GBK
- 修改前
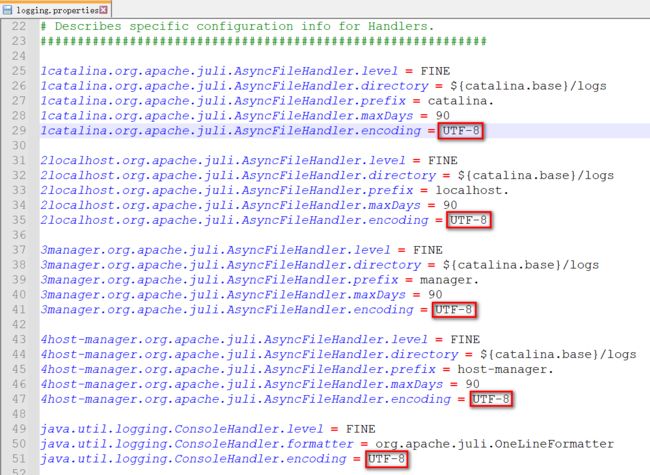
- 修改后
- 重启测试

2.3 Tomcat目录及测试
C:\Program4java\apache-tomcat-10.1.7 这个目录下直接包含Tomcat的bin目录,conf目录等,我们称之为Tomcat的安装目录或根目录。
-
bin:该目录下存放的是二进制可执行文件,如果是安装版,那么这个目录下会有两个exe文件:tomcat10.exe、tomcat10w.exe,前者是在控制台下启动Tomcat,后者是弹出GUI窗口启动Tomcat;如果是解压版,那么会有startup.bat和shutdown.bat文件,startup.bat用来启动Tomcat,但需要先配置JAVA_HOME环境变量才能启动,shutdawn.bat用来停止Tomcat;
-
conf:这是一个非常非常重要的目录,这个目录下有四个最为重要的文件:
-
server.xml:配置整个服务器信息。例如修改端口号。默认HTTP请求的端口号是:8080
-
tomcat-users.xml:存储tomcat用户的文件,这里保存的是tomcat的用户名及密码,以及用户的角色信息。可以按着该文件中的注释信息添加tomcat用户,然后就可以在Tomcat主页中进入Tomcat Manager页面了;
<tomcat-users xmlns="http://tomcat.apache.org/xml" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://tomcat.apache.org/xml tomcat-users.xsd" version="1.0"> <role rolename="admin-gui"/> <role rolename="admin-script"/> <role rolename="manager-gui"/> <role rolename="manager-script"/> <role rolename="manager-jmx"/> <role rolename="manager-status"/> <user username="admin" password="admin" roles="admin-gui,admin-script,manager-gui,manager-script,manager-jmx,manager-status" /> tomcat-users>web.xml:部署描述符文件,这个文件中注册了很多MIME类型,即文档类型。这些MIME类型是客户端与服务器之间说明文档类型的,如用户请求一个html网页,那么服务器还会告诉客户端浏览器响应的文档是text/html类型的,这就是一个MIME类型。客户端浏览器通过这个MIME类型就知道如何处理它了。当然是在浏览器中显示这个html文件了。但如果服务器响应的是一个exe文件,那么浏览器就不可能显示它,而是应该弹出下载窗口才对。MIME就是用来说明文档的内容是什么类型的!
-
context.xml:对所有应用的统一配置,通常我们不会去配置它。
-
-
lib:Tomcat的类库,里面是一大堆jar文件。如果需要添加Tomcat依赖的jar文件,可以把它放到这个目录中,当然也可以把应用依赖的jar文件放到这个目录中,这个目录中的jar所有项目都可以共享之,但这样你的应用放到其他Tomcat下时就不能再共享这个目录下的jar包了,所以建议只把Tomcat需要的jar包放到这个目录下;
-
logs:这个目录中都是日志文件,记录了Tomcat启动和关闭的信息,如果启动Tomcat时有错误,那么异常也会记录在日志文件中。
-
temp:存放Tomcat的临时文件,这个目录下的东西可以在停止Tomcat后删除!
-
webapps:存放web项目的目录,其中每个文件夹都是一个项目;如果这个目录下已经存在了目录,那么都是tomcat自带的项目。其中ROOT是一个特殊的项目,在地址栏中访问:http://127.0.0.1:8080,没有给出项目目录时,对应的就是ROOT项目.http://localhost:8080/examples,进入示例项目。其中examples"就是项目名,即文件夹的名字。
-
work:运行时生成的文件,最终运行的文件都在这里。通过webapps中的项目生成的!可以把这个目录下的内容删除,再次运行时会生再次生成work目录。当客户端用户访问一个JSP文件时,Tomcat会通过JSP生成Java文件,然后再编译Java文件生成class文件,生成的java和class文件都会存放到这个目录下。
-
LICENSE:许可证。
-
NOTICE:说明文件。
2.4 WEB项目的标准结构
一个标准的可以用于发布的WEB项目标准结构如下
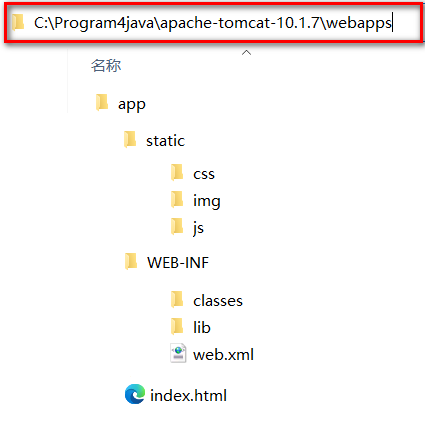
- app 本应用根目录
- static 非必要目录,约定俗成的名字,一般在此处放静态资源 ( css js img)
- WEB-INF 必要目录,必须叫WEB-INF,受保护的资源目录,浏览器通过url不可以直接访问的目录
- classes 必要目录,src下源代码,配置文件,编译后会在该目录下,web项目中如果没有源码,则该目录不会出现
- lib 必要目录,项目依赖的jar编译后会出现在该目录下,web项目要是没有依赖任何jar,则该目录不会出现
- web.xml 必要文件,web项目的基本配置文件. 较新的版本中可以没有该文件,但是学习过程中还是需要该文件
- index.html 非必要文件,index.html/index.htm/index.jsp为默认的欢迎页
url的组成部分和项目中资源的对应关系
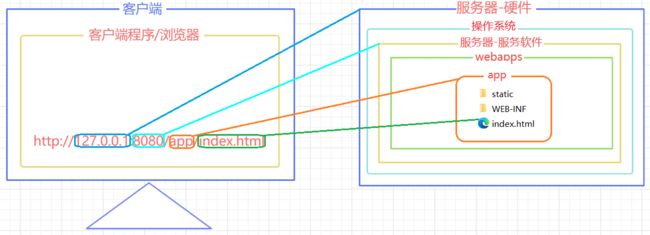
2.5 WEB项目部署的方式
方式1 直接将编译好的项目放在webapps目录下 (已经演示)
方式2 将编译好的项目打成war包放在webapps目录下,tomcat启动后会自动解压war包(其实和第一种一样)
方式3 可以将项目放在非webapps的其他目录下,在tomcat中通过配置文件指向app的实际磁盘路径
- 在磁盘的自定义目录上准备一个app
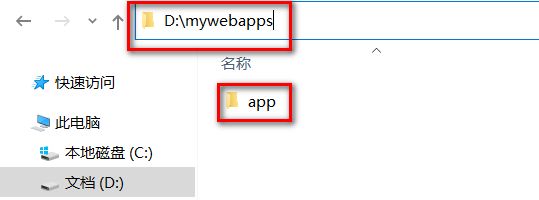
- 在tomcat的conf下创建Catalina/localhost目录,并在该目录下准备一个app.xml文件
<Context path="/app" docBase="D:\mywebapps\app" />
- 启动tomcat访问测试即可
2.6 IDEA中开发并部署运行WEB项目
2.6.1 IDEA关联本地Tomcat
可以在创建项目前设置本地tomcat,也可以在打开某个项目的状态下找到settings
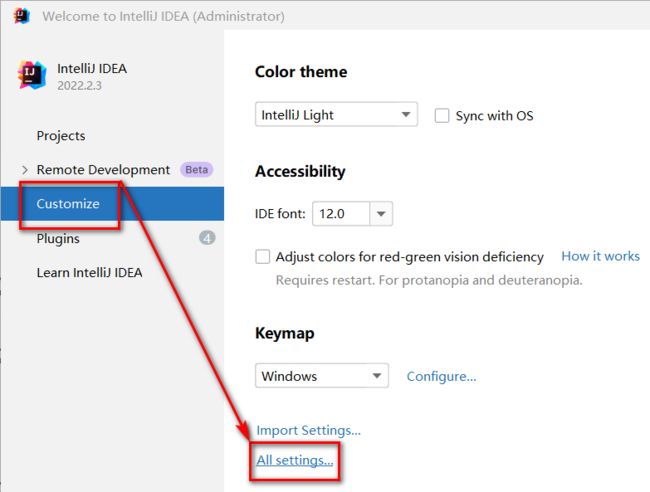
找到 Build,Execution,Eeployment下的Application Servers ,找到+号

选择Tomcat Server

选择tomcat的安装目录
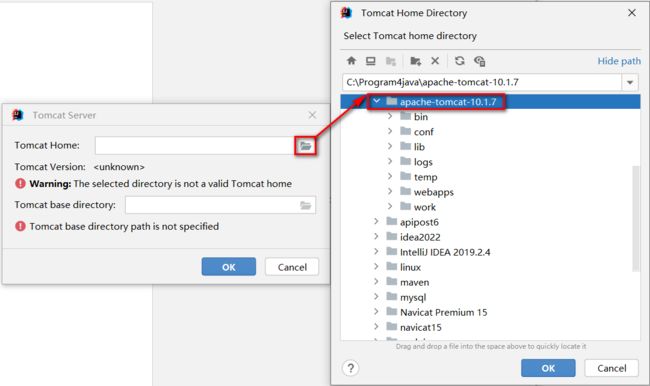
点击ok

关联完毕

2.6.2 IDEA创建web工程
推荐先创建一个空项目,这样可以在一个空项目下同时存在多个modules,不用后续来回切换之前的项目,当然也可以忽略此步直接创建web项目

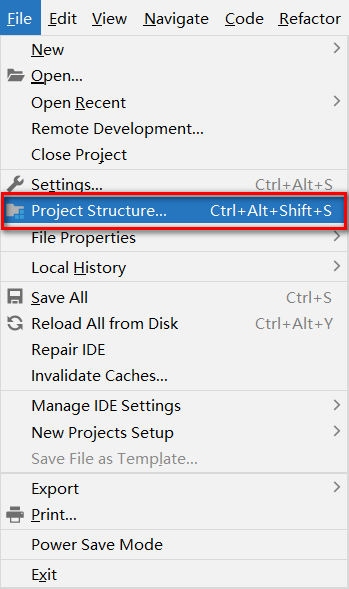
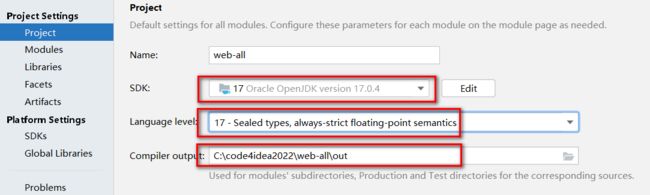
检查项目的SDK,语法版本,以及项目编译后的输出目录
先创建一个普通的JAVA项目

检查各项信息是否填写有误
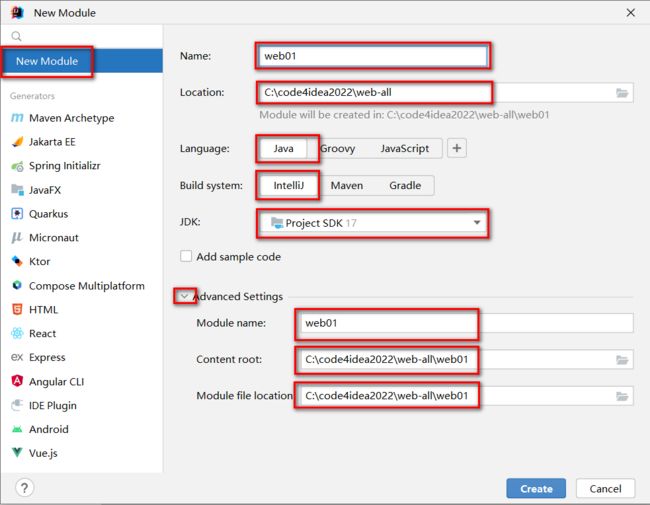
创建完毕后,为项目添加Tomcat依赖



选择modules,添加 framework support
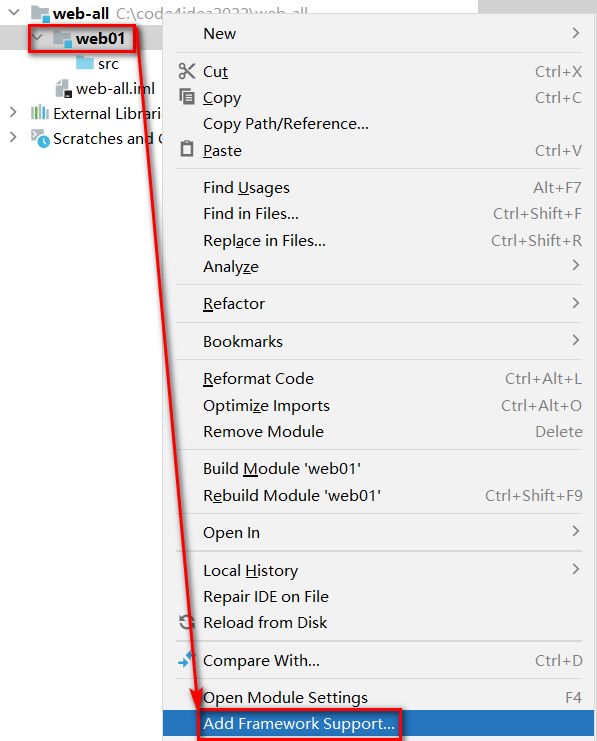
选择Web Application 注意Version,勾选 Create web.xml
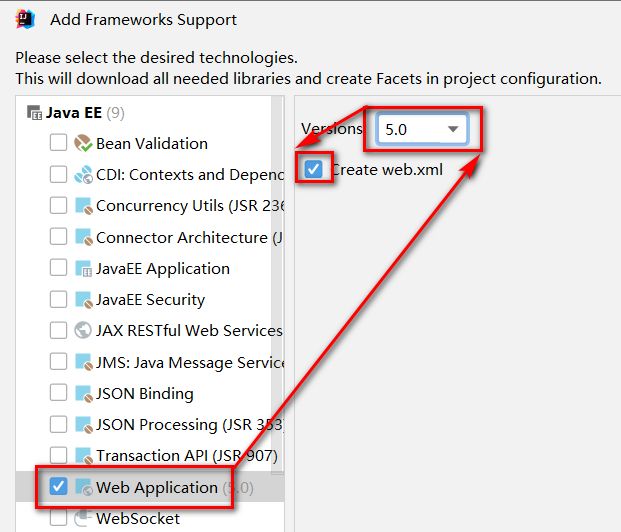
删除index.jsp ,替换为 index.html


处理配置文件
- 在工程下创建resources目录,专门用于存放配置文件(都放在src下也行,单独存放可以尽量避免文件集中存放造成的混乱)
- 标记目录为资源目录,不标记的话则该目录不参与编译

- 标记完成后,显示效果如下

处理依赖jar包问题
- 在WEB-INF下创建lib目录
- 必须在WEB-INF下,且目录名必须叫lib!!!
- 复制jar文件进入lib目录

- 将lib目录添加为当前项目的依赖,后续可以用maven统一解决


- 环境级别推荐选择module 级别,降低对其他项目的影响,name可以空着不写
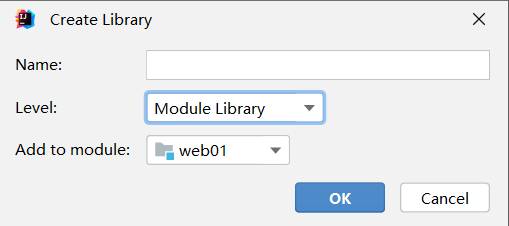
- 查看当前项目有那些环境依赖

- 在此位置,可以通过-号解除依赖

2.6.3 IDEA部署-运行web项目
检查idea是否识别modules为web项目并存在将项目构建成发布结构的配置
- 就是检查工程目录下,web目录有没有特殊的识别标记
- 以及artifacts下,有没有对应 _war_exploded,如果没有,就点击+号添加

点击向下箭头,出现 Edit Configurations选项

出现运行配置界面
点击+号,添加本地tomcat服务器
因为IDEA 只关联了一个Tomcat,红色部分就只有一个Tomcat可选

选择Deployment,通过+添加要部署到Tomcat中的artifact
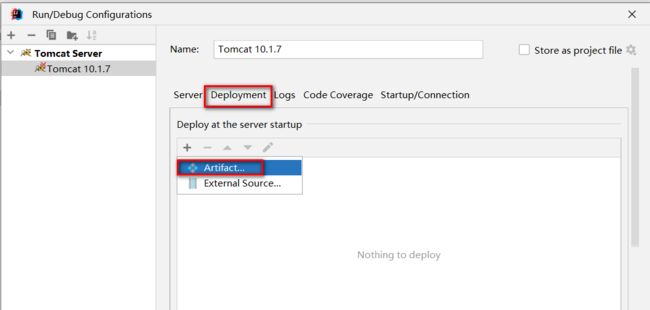
applicationContext中是默认的项目上下文路径,也就是url中需要输入的路径,这里可以自己定义,可以和工程名称不一样,也可以不写,但是要保留/,我们这里暂时就用默认的

点击apply 应用后,回到Server部分. After Launch是配置启动成功后,是否默认自动打开浏览器并输入URL中的地址,HTTP port是Http连接器目前占用的端口号

点击OK后,启动项目,访问测试
- 绿色箭头是正常运行模式
- "小虫子"是debug运行模式

- 点击后,查看日志状态是否有异常

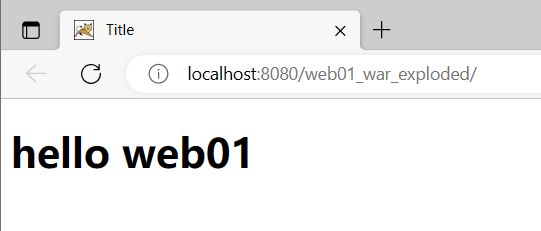
- 浏览器自动打开并自动访问了index.html欢迎页
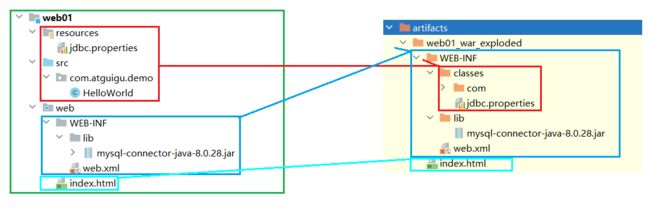
工程结构和可以发布的项目结构之间的目录对应关系
IDEA部署并运行项目的原理
- idea并没有直接进将编译好的项目放入tomcat的webapps中
- idea根据关联的tomcat,创建了一个tomcat副本,将项目部署到了这个副本中
- idea的tomcat副本在C:\用户\当前用户\AppData\Local\JetBrains\IntelliJIdea2022.2\tomcat\中
- idea的tomcat副本并不是一个完整的tomcat,副本里只是准备了和当前项目相关的配置文件而已
- idea启动tomcat时,是让本地tomcat程序按照tomcat副本里的配置文件运行
- idea的tomcat副本部署项目的模式是通过conf/Catalina/localhost/*.xml配置文件的形式实现项目部署的

3. HTTP协议
3.1 HTTP简介

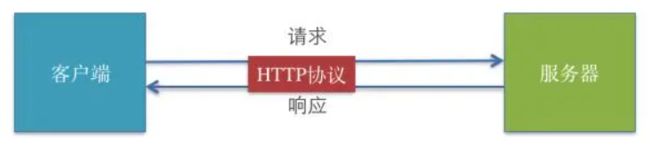
HTTP 超文本传输协议 (HTTP-Hyper Text transfer protocol),是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过十几年的使用与发展,得到不断地完善和扩展。它是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。客户端与服务端通信时传输的内容我们称之为报文。HTTP协议就是规定报文的格式。HTTP就是一个通信规则,这个规则规定了客户端发送给服务器的报文格式,也规定了服务器发送给客户端的报文格式。实际我们要学习的就是这两种报文。客户端发送给服务器的称为"请求报文",服务器发送给客户端的称为"响应报文"。
3.1.1 发展历程
HTTP/0.9
- 蒂姆伯纳斯李是一位英国计算机科学家,也是万维网的发明者。他在 1989 年创建了单行 HTTP 协议。它只是返回一个网页。这个协议在 1991 年被命名为 HTTP/0.9。
HTTP/1.0
- 1996 年,HTTP/1.0 发布。该规范是显著扩大,并且支持三种请求方法:GET,Head,和POST。
- HTTP/1.0 相对于 HTTP/0.9 的改进如下:
- 每个请求都附加了 HTTP 版本。
- 在响应开始时发送状态代码。
- 请求和响应都包含 HTTP 报文头。
- 内容类型能够传输 HTML 文件以外的文档。
- 但是,HTTP/1.0 不是官方标准。
HTTP/1.1
-
HTTP 的第一个标准化版本 HTTP/1.1 ( RFC 2068 ) 于 1997 年初发布,支持七种请求方法:OPTIONS,GET,HEAD,POST,PUT,DELETE,和TRACE
-
HTTP/1.1 是 HTTP 1.0 的增强:
-
虚拟主机允许从单个 IP 地址提供多个域。
-
持久连接和流水线连接允许 Web 浏览器通过单个持久连接发送多个请求。
-
缓存支持节省了带宽并使响应速度更快。
-
-
HTTP/1.1 在接下来的 15 年左右将非常稳定。
-
在此期间,出现了 HTTPS(安全超文本传输协议)。它是使用 SSL/TLS 进行安全加密通信的 HTTP 的安全版本。
HTTP/2
- 由IETF在2015年发布。HTTP/2旨在提高Web性能,减少延迟,增加安全性,使Web应用更加快速、高效和可靠。
- 多路复用:HTTP/2 允许同时发送多个请求和响应,而不是像 HTTP/1.1 一样只能一个一个地处理。这样可以减少延迟,提高效率,提高网络吞吐量。
- 二进制传输:HTTP/2 使用二进制协议,与 HTTP/1.1 使用的文本协议不同。二进制协议可以更快地解析,更有效地传输数据,减少了传输过程中的开销和延迟。
- 头部压缩:HTTP/2 使用 HPACK 算法对 HTTP 头部进行压缩,减少了头部传输的数据量,从而减少了网络延迟。
- 服务器推送:HTTP/2 支持服务器推送,允许服务器在客户端请求之前推送资源,以提高性能。
- 改进的安全性:HTTP/2 默认使用 TLS(Transport Layer Security)加密传输数据,提高了安全性。
- 兼容 HTTP/1.1:HTTP/2 可以与 HTTP/1.1 共存,服务器可以同时支持 HTTP/1.1 和 HTTP/2。如果客户端不支持 HTTP/2,服务器可以回退到 HTTP/1.1。
HTTP/3
-
于 2021 年 5 月 27 日发布 , HTTP/3 是一种新的、快速、可靠且安全的协议,适用于所有形式的设备。 HTTP/3 没有使用 TCP,而是使用谷歌在 2012 年开发的新协议 QUIC
-
HTTP/3 是继 HTTP/1.1 和 HTTP/2之后的第三次重大修订。
-
HTTP/3 带来了革命性的变化,以提高 Web 性能和安全性。设置 HTTP/3 网站需要服务器和浏览器支持。
-
目前,谷歌云、Cloudflare和Fastly支持 HTTP/3。Chrome、Firefox、Edge、Opera 和一些移动浏览器支持 HTTP/3。
3.1.2 HTTP协议的会话方式
浏览器与服务器之间的通信过程要经历四个步骤

- 浏览器与WEB服务器的连接过程是短暂的,每次连接只处理一个请求和响应。对每一个页面的访问,浏览器与WEB服务器都要建立一次单独的连接。
- 浏览器到WEB服务器之间的所有通讯都是完全独立分开的请求和响应对。
3.1.3 HTTP1.0和HTTP1.1的区别
在HTTP1.0版本中,浏览器请求一个带有图片的网页,会由于下载图片而与服务器之间开启一个新的连接;但在HTTP1.1版本中,允许浏览器在拿到当前请求对应的全部资源后再断开连接,提高了效率。

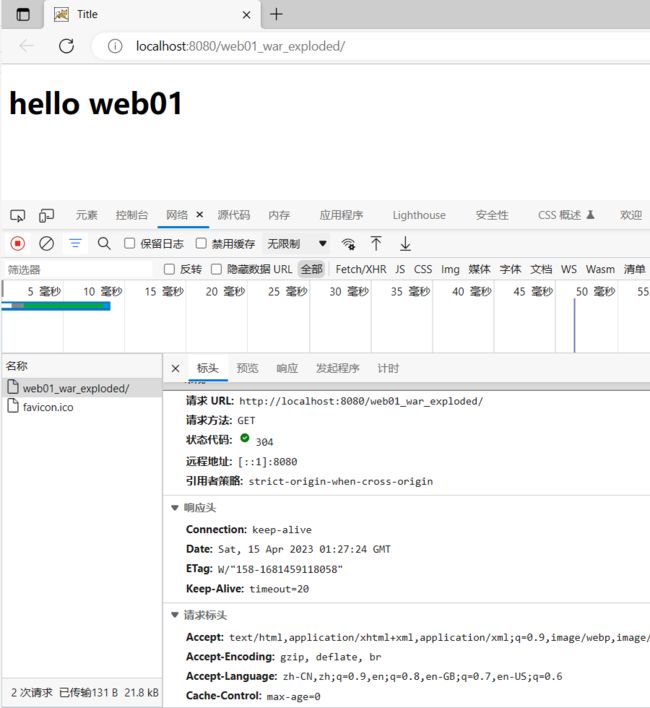
3.1.4 在浏览器中通过F12工具抓取请求响应报文包
几乎所有的PC端浏览器都支持了F12开发者工具,只不过不同的浏览器工具显示的窗口有差异
3.2 请求和响应报文
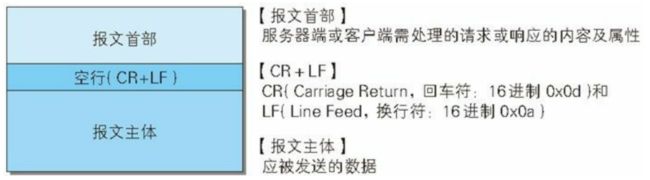
3.2.1 报文的格式
主体上分为报文首部和报文主体,中间空行隔开
报文部首可以继续细分为 “行” 和 “头”
3.2.2 请求报文
客户端发给服务端的报文
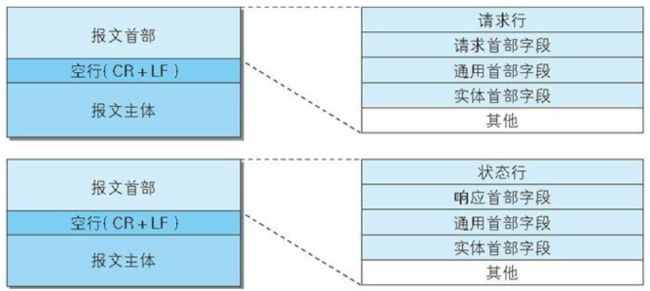
- 请求报文格式
- 请求首行(请求行); GET/POST 资源路径?参数 HTTP/1.1
- 请求头信息(请求头);
- 空行;
- 请求体;POST请求才有请求体
浏览器 f12 网络下查看请求数据包
form表单发送GET请求特点
1、由于请求参数在请求首行中已经携带了,所以没有请求体,也没有请求空行
2、请求参数拼接在url地址中,地址栏可见[url?name1=value1&name2=value2],不安全
3、由于参数在地址栏中携带,所以由大小限制[地址栏数据大小一般限制为4k],只能携带纯文本
4、get请求参数只能上传文本数据
5、没有请求体。所以封装和解析都快,效率高, 浏览器默认提交的请求都是get请求比如:地址栏输入回车,超链接,表单默认的提交方式
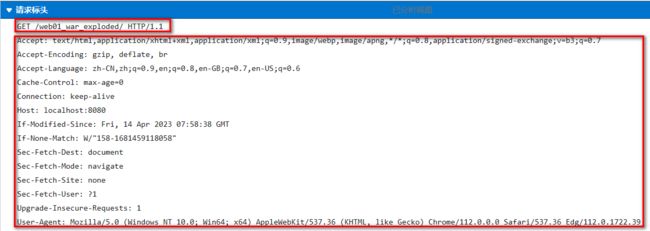
查看GET请求行,请求头,请求体
- 请求行组成部分
- 请求方式 GET
- 访问服务器的资源路径?参数1=值1&参数2=值2 … …
- 协议及版本 HTTP/1.1
GET /05_web_tomcat/login_success.html?username=admin&password=123213 HTTP/1.1
- 请求头
-主机虚拟地址
Host: localhost:8080
-长连接
Connection: keep-alive
-请求协议的自动升级[http的请求,服务器却是https的,浏览器自动会将请求协议升级为https的]
Upgrade-Insecure-Requests: 1
- 用户系统信息
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36
- 浏览器支持的文件类型
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
- 当前页面的上一个页面的路径[当前页面通过哪个页面跳转过来的]: 可以通过此路径跳转回上一个页面, 广告计费,防止盗链
Referer: http://localhost:8080/05_web_tomcat/login.html
- 浏览器支持的压缩格式
Accept-Encoding: gzip, deflate, br
- 浏览器支持的语言
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
-
请求空行
-
请求体
- GET请求数据不放在请求体
form表单发送post请求特点
1、POST请求有请求体,而GET请求没有请求体。
2、post请求数据在请求体中携带,请求体数据大小没有限制,可以用来上传所有内容[文件、文本]
3、只能使用post请求上传文件
4、post请求报文多了和请求体相关的配置[请求头]
5、地址栏参数不可见,相对安全
6、post效率比get低
- POST请求要求将form标签的method的属性设置为post

查看post的请求行 请求头 请求体
- 请求行组成部分
- 请求方式 POST
- 访问服务器的资源路径?参数1=值1&参数2=值2 … …
- 协议及版本 HTTP/1.1
POST /05_web_tomcat/login_success.html HTTP/1.1
- 请求头
Host: localhost:8080
Connection: keep-alive
Content-Length: 31 -请求体内容的长度
Cache-Control: max-age=0 -无缓存
Origin: http://localhost:8080
Upgrade-Insecure-Requests: 1 -协议的自动升级
Content-Type: application/x-www-form-urlencoded -请求体内容类型[服务器根据类型解析请求体参数]
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://localhost:8080/05_web_tomcat/login.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
Cookie:JSESSIONID-
-
请求空行
-
请求体:浏览器提交给服务器的数据
username=admin&password=1232131
3.2.3 响应报文
响应报文格式
- 响应首行(响应行); 协议/版本 状态码 状态码描述
- 响应头信息(响应头);
- 空行;
- 响应体;
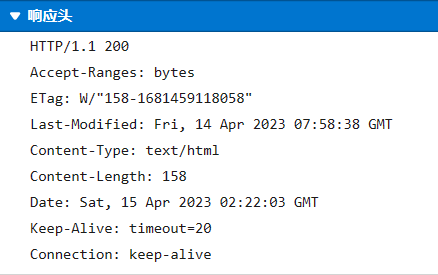

- 响应行组成部分
- 协议及版本 HTTP/1.1
- 响应状态码 200
- 状态描述 OK (缺省)
HTTP/1.1 200 OK
说明:响应协议为HTTP1.1,响应状态码为200,表示请求成功;
- 响应头
Server: Apache-Coyote/1.1 服务器的版本信息
Accept-Ranges: bytes
ETag: W/"157-1534126125811"
Last-Modified: Mon, 13 Aug 2018 02:08:45 GMT
Content-Type: text/html 响应体数据的类型[浏览器根据类型解析响应体数据]
Content-Length: 157 响应体内容的字节数
Date: Mon, 13 Aug 2018 02:47:57 GMT 响应的时间,这可能会有8小时的时区差
- 响应体
DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title heretitle>
head>
<body>
恭喜你,登录成功了...
body>
html>
响应状态码:响应码对浏览器来说很重要,它告诉浏览器响应的结果。比较有代表性的响应码如下:
- 200: 请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
- 302: 重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location指定新请求的URL地址;
- 304: 使用了本地缓存
- 404: 请求的资源没有找到,说明客户端错误的请求了不存在的资源;
- 405: 请求的方式不允许
- 500: 请求资源找到了,但服务器内部出现了错误;
更多的响应状态码
| 状态码 | 状态码英文描述 | 中文含义 |
|---|---|---|
| 1** | ||
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 2** | ||
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 3** | ||
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 4** | ||
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 5** | ||
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |