ELK(九)—logstash
目录
- 简介
- 安装部署
-
-
- 测试
-
- 配置详解
- 编写配置文件
-
- 连接elasticsearch
- 将数据推送到elasticsearch中。
简介
Logstash 是一个开源的服务器端数据处理管道,由 Elastic 公司维护和开发。它被设计用于从不同来源收集、处理和转发数据,以供 Elasticsearch 进行存储和检索。
以下是 Logstash 的主要特点和功能:
-
数据收集:Logstash 支持从各种来源收集数据,包括日志文件、数据库、消息队列、网络流量等。它具有丰富的插件生态系统,可以轻松地集成到多种数据源。
-
数据处理:Logstash 允许用户对收集到的数据进行处理和转换。通过配置不同的过滤器,可以执行各种任务,如解析结构化数据、过滤不需要的信息、标准化字段等。
-
数据输出:处理后的数据可以发送到各种目标,其中最常见的目标是 Elasticsearch,用于存储和检索数据。此外,Logstash 还支持输出到其他存储后端,如文件、消息队列、关系型数据库等。
-
插件生态系统:Logstash 的强大之处在于其插件生态系统。用户可以根据需要选择合适的输入、过滤器和输出插件,以满足特定的数据处理和集成需求。
-
可扩展性:Logstash 是可扩展的,可以通过添加自定义插件或使用现有的插件进行扩展。这使得 Logstash 适用于不同规模和类型的数据处理工作负载。
-
配置简单:Logstash 的配置文件采用简单的文本格式,易于理解和维护。用户可以根据需要编写配置文件,定义数据流的输入、过滤和输出。
-
日志监控和管理:Logstash 提供了用于监控和管理的工具和接口。用户可以使用 Kibana 可视化工具对 Logstash 进行监控,并查看其性能指标和运行状态。
整个 ELK(Elasticsearch、Logstash、Kibana)堆栈通常一起使用,以实现从数据收集到存储、分析和可视化的完整数据处理流程。Logstash 在这个堆栈中的角色是作为数据处理引擎,负责处理和传递数据到 Elasticsearch,而 Kibana 提供了强大的可视化和查询工具。
安装部署
下载安装包
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.11.1-linux-x86_64.tar.gz
解压
tar -xvf logstash-8.11.1-linux-x86_64.tar.gz
重命名
mv logstash-8.11.1/ logstash
测试
简单示例
./logstash -e 'input { stdin { } } output { stdout {} }'
./logstash:这是启动 Logstash 的命令。前提是你在 Logstash 的安装目录中,这个命令会在当前目录下寻找logstash可执行文件。
-e:这个参数允许你在命令行中直接指定 Logstash 的配置,而不必使用配置文件。后面跟着的是包含 Logstash 配置的字符串。
'input { stdin { } } output { stdout {} }':这个字符串是 Logstash 的配置,分为三个部分:
input { stdin { } }:定义了一个输入插件,使用stdin插件从标准输入接收数据。
filter { }:这里没有定义过滤器,表示不对输入数据进行过滤。
output { stdout {} }:定义了一个输出插件,使用stdout插件将处理后的数据输出到标准输出。所以,这个 Logstash 配置的作用是从标准输入接收数据,不对数据进行过滤,然后将处理后的数据输出到标准输出。这对于在命令行中手动输入数据、测试 Logstash 配置或查看处理结果非常有用。
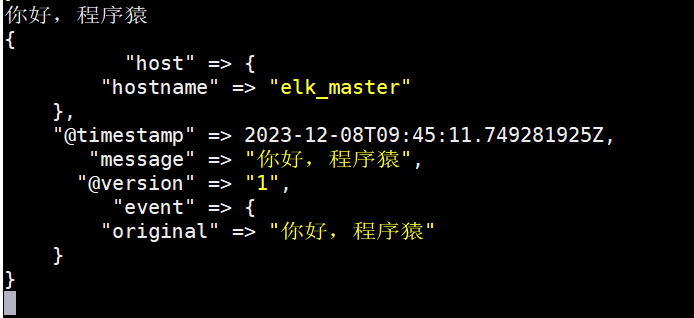
我们在控制台输入 你好,程序猿,马上就能看到它的输出信息
配置详解
Logstash 的配置文件主要由三个部分组成:input、filter 和 output。每个部分负责不同的任务,用于定义数据的输入、处理和输出。
input { #输入
stdin { ... } #标准输入
}
filter { #过滤,对数据进行分割、截取等处理
...
}
output { #输出
stdout { ... } #标准输出
}
以下是对 Logstash 配置文件中 input、filter 和 output 部分的简要详解:
Input(输入):
input { stdin { # 配置参数 } }
stdin:此输入插件从标准输入接收数据。这对于在命令行中手动输入数据进行测试非常有用。
配置参数:stdin 插件本身不需要太多的配置参数。它主要用于从标准输入读取数据。
Filter(过滤):
filter { # 过滤器插件 }
过滤器插件:在 filter 部分,可以配置一个或多个过滤器插件,用于对输入的数据进行处理和转换。这些过滤器可以执行各种任务,如解析结构化数据、截取字段、添加标签等。
例子:例如,可以使用
grok过滤器解析日志中的特定字段,使用mutate过滤器修改字段值,或者使用其他过滤器执行数据转换操作。Output(输出):
output { stdout { # 配置参数 } }
stdout:此输出插件将处理后的数据输出到标准输出。这对于在命令行中查看 Logstash 处理后的数据非常有用,用于调试和测试。
配置参数:stdout 插件通常不需要太多的配置参数。它用于在控制台上显示处理后的数据。
配置文件中还可以包含其他的 input、filter 和 output 部分,以根据需求定义多个输入来源、多个过滤器和多个输出目标。整个配置文件定义了数据的整个处理流程。
编写配置文件
在“/opt/elk/logstash”下创建hmiyuan-pipeline.conf
input {
file {
path => "/opt/elk/logs/test.log"
start_position => "beginning"
}
}
filter {
mutate {
split => {"message"=>"|"}
}
}
output {
stdout { codec => rubydebug }
}
启动
./bin/logstash -f ./hmiyuan-pipeline.conf
插入数据
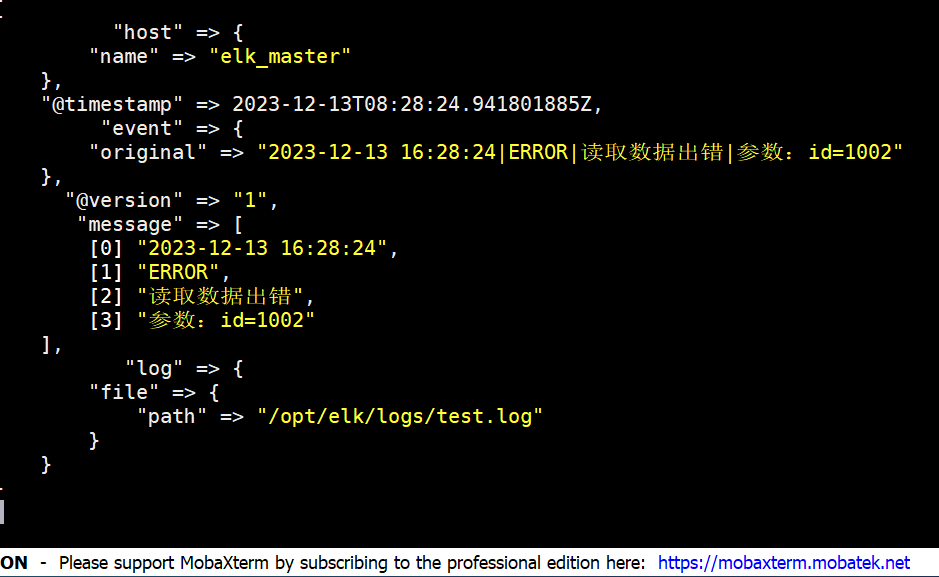
echo "2023-12-13 16:28:24|ERROR|读取数据出错|参 :i=1002" >> //opt/elk/logs/test.log
然后我们就可以看到logstash就会捕获到刚刚我们插入的数据,同时我们的数据也被分割了
连接elasticsearch
更改配置文件,将我们日志记录输出到Elasticsearch中。

向配置文件中的日志追加数据
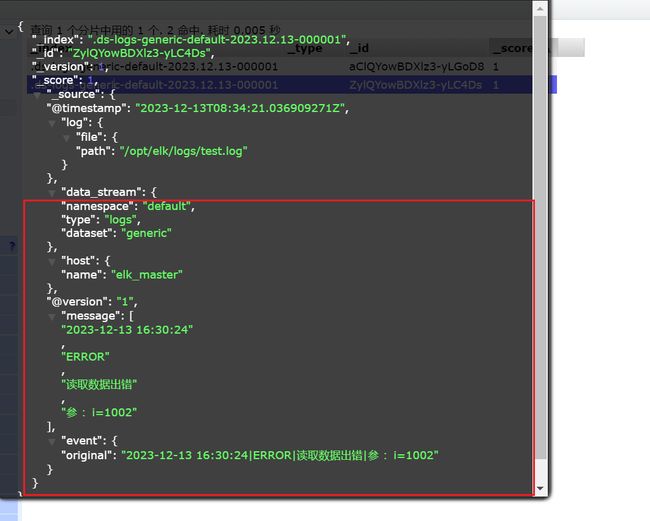
echo "2023-12-13 16:30:24|ERROR|读取数据出错|参 :i=1002" >> //opt/elk/logs/test.log
echo "2023-12-13 16:31:24|ERROR|读取数据出错|参 :i=1002" >> //opt/elk/logs/test.log
最后登录elasticsearch-head界面查看,如果成功的话,就可以查看到插入的数据了。
将数据推送到elasticsearch中。
input {
file {
path => "/opt/logs/*.log"
start_position => "beginning"
sincedb_path => "/dev/null"
exclude => "*.gz"
}
}
filter {
mutate {
split => {"message"=>"|"}
}
}
output {
elasticsearch {
hosts => ["192.168.150.190:9200"]
index => "logs_index"
}
}
配置文件说明:
input: 指定输入源,logstash会从输入源读取数据。
file:输入源为文件。
path:文件路径,* 是通配符,用于匹配文件路径中的任意字符序列。
start_position: 设定为 “beginning”,表示从文件的开头开始读取数据。
sincedb_path: 指定了 sincedb 文件的路径,但这里设置为 /dev/null,意味着不使用 sincedb 文件来跟踪已读取的文件位置。
exclude:排除以 .gz 结尾的文件。
output:指定输出源,logstash会把数据处理成elasticsearch识别的数据发送给elasticsearch。
hosts:elasticsearch 应用地址
index:指定索引,会在elasticsearch中创建
启动
./bin/logstash -f ./hmiyuan-pipeline.conf