大数据技术14:FlinkCDC数据变更捕获
前言:Flink CDC是Flink社区开发的flink-cdc-connectors 组件,这是⼀个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
https://github.com/ververica/flink-cdc-connectors
一、CDC 概述
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC 技术的应用场景非常广泛:
- 数据同步:用于备份,容灾;
- 数据分发:一个数据源分发给多个下游系统;
- 数据采集:面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
-
基于查询的 CDC:
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
-
基于日志的 CDC:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
对比常见的开源 CDC 方案,我们可以发现:

-
对比增量同步能力,
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查询的方式是很难做到增量同步的。
- 对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
- 而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
-
在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- 但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
- 另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
二、Flink CDC
Flink CDC (CDC Connectors for Apache Flink)是 Apache Flink的一组 Source 连接器,支持从 MySQL,MariaDB, RDS MySQL,Aurora MySQL,PolarDB MySQL,PostgreSQL,Oracle,MongoDB,SqlServer,OceanBase,PolarDB-X,TiDB 等数据库中实时地读取存量历史数据和增量变更数据,用户既可以选择用户友好的 SQL API,也可以使用功能更为强大的 DataStream API。
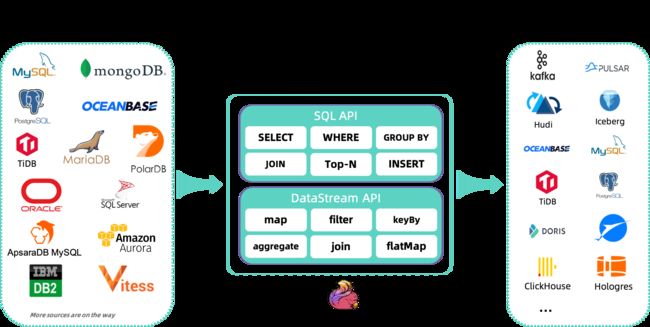
作为新一代的数据集成框架, Flink CDC 不仅可以替代传统的 DataX 和 Canal 工具做实时数据同步,将数据库的全量和增量数据一体化地同步到消息队列和数据仓库中;也可以用于实时数据集成,将数据库数据实时入湖入仓;同时还支持强大的数据加工能力,可以通过 SQL 对数据库数据做实时关联、打宽、聚合,并将物化结果写入到各种存储中。
相对于其他数据集成框架,Flink CDC 具有全增量一体化、无锁读取、并发读取、表结构变更自动同步、分布式架构等技术优势,在开源社区中非常受欢迎,成长迅速,文档完善[2],目前社区已有 44 位贡献者,4 位Maintainer,社区用户群超过 4000 人。
三、 Flink CDC特点和应用场景
Flink CDC(Change Data Capture,即数据变更抓取)是一个开源的数据库变更日志捕获和处理框架,它可以实时地从各种数据库(如MySQL、PostgreSQL、Oracle、MongoDB等)中捕获数据变更并将其转换为流式数据。Flink CDC 可以帮助实时应用程序实时地处理和分析这些流数据,从而实现数据同步、数据管道、实时分析和实时应用等功能。
3.1、Flink CDC特点
-
支持多种数据库类型:Flink CDC 支持多种数据库,如 MySQL、PostgreSQL、Oracle、MongoDB 等。
-
实时数据捕获:Flink CDC 能够实时捕获数据库中的数据变更,并将其转换为流式数据。
-
高性能:Flink CDC 基于 Flink 引擎,具有高性能的数据处理能力。
-
低延迟:Flink CDC 可以在毫秒级的延迟下处理大量的数据变更。
-
易集成:Flink CDC 与 Flink 生态系统紧密集成,可以方便地与其他 Flink 应用程序一起使用。
-
高可用性:Flink CDC 支持实时备份和恢复,确保数据的高可用性。
3.2、Flink CDC应用场景
-
实时数据同步:将数据从一个数据库实时同步到另一个数据库。
-
实时数据管道:构建实时数据处理管道,处理和分析数据库中的数据。
-
实时数据分析:实时分析数据库中的数据,提供实时的业务洞察。
-
实时应用:将数据库中的数据实时应用于实时应用程序,如实时报表、实时推荐等。
-
实时监控:实时监控数据库中的数据,检测异常和错误。
四、Flink CDC 优势
传统的cdc不足:
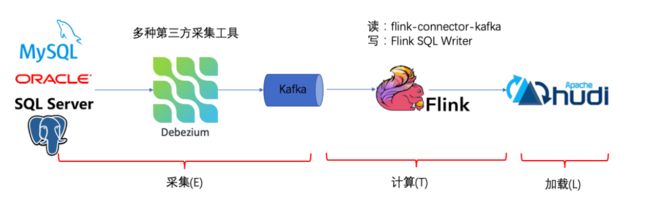
传统的基于 CDC 的 ETL 分析中,数据采集⼯具是必须的,国外⽤户常⽤ Debezium,国内⽤户常⽤阿⾥开源的 Canal,采集⼯具负责采集数据库的增量数据,⼀些采集⼯具也⽀持同步全量数据。采集到的数据⼀般输出到消息 中间件如 Kafka,然后 Flink 计算引擎再去消费这⼀部分数据写⼊到⽬的端,⽬的端可以是各种 DB,数据湖,实时 数仓和离线数仓。
注意,Flink 提供了 changelog-json format,可以将 changelog 数据写⼊离线数仓如 Hive / HDFS;对于实时数 仓,Flink ⽀持将 changelog 通过 upsert-kafka connector 直接写⼊ Kafka。
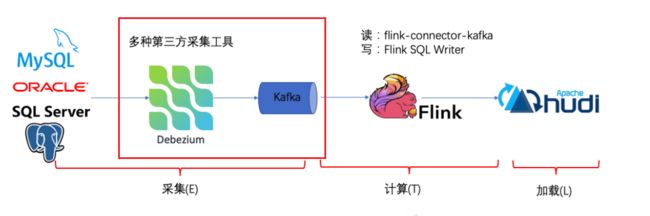
Flink CDC的基本理念就是去替换上图中红色线框内的采集组件和消息队列,从⽽简化传输链路,降低维护成本。同 时更少的组件也意味着数据时效性能够进⼀步提⾼。
五、Flink CDC采集方案
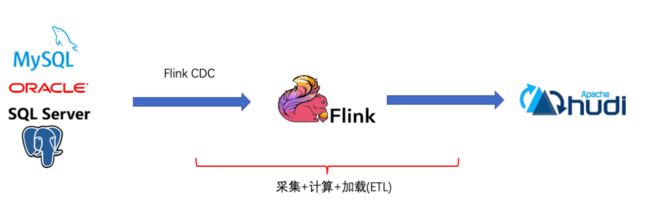
基于FlinkCDC,我们只需要通过⼀个 Flink SQL 作业就完成了 CDC 的数据采集,加⼯和同步,下⾯是⼀个例⼦:
--需求:同步MySQL的orders表到TiDB的orders表
--1、定义MySQL中orders表的cdc源表
CREATE TABLE mysql_orders (
id INT NOT NULL,
product_id BIGINT,
...
PRIMARY KEY(id)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xx',
'port' = '3306',
'username' = 'xx',
'password' = 'xx',
'database-name' = 'xx',
'table-name' = 'orders'
);
--2、创建TiDB结果表
CREATE TABLE tidb_orders(
id INT NOT NULL,
product_id BIGINT,
...
PRIMARY KEY(id)
)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/xx',
'table-name' = 'orders'
);
--3、从源表读取数据写⼊结果表
INSERT INTO tidb_orders
SELECT * FROM mysql_orders所以基于Flink CDC的⽅案是⼀个纯 SQL 作业,⼤⼤降低了降低了使⽤⻔槛。当然,我们也可以利⽤ Flink SQL 提 供的丰富语法进⾏数据清洗、分析、聚合,⽽不仅仅是简单的数据同步。利⽤ Flink SQL 双流 JOIN、维表 JOIN、 UDTF 语法可以⾮常容易地完成实时打宽,以及各种业务逻辑加⼯。
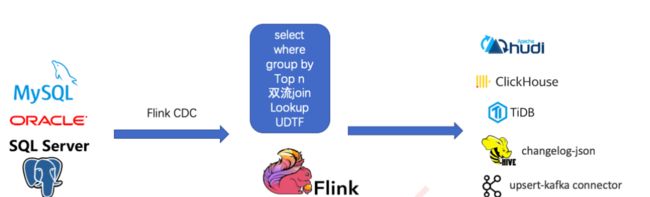
六、FlinkCDC在电商场景的应用
在很多的场景下,我们期望当数据库的数据发生变化时,一些依赖于数据库的存储中间件的数据也可以得到及时同步,比如同步数据到Kafka、Elasticsearch等数据仓库平台。在传统解决方案中,通常我们会在业务代码中进行同步或异步处理,当业务代码变更数据库时,同时将当前数据在中间件中也进行修改。
比如在电商场景下,订单下单后需要对商品减库存和加销量等,修改了商品名称需要同步搜索引擎中的当前商品的名称等,这些变更中间件的操作通常与业务代码耦合在一块,并且在各种处理逻辑中都可能存在同步数据操作,从而造成代码冗余严重,维护成本增高等;
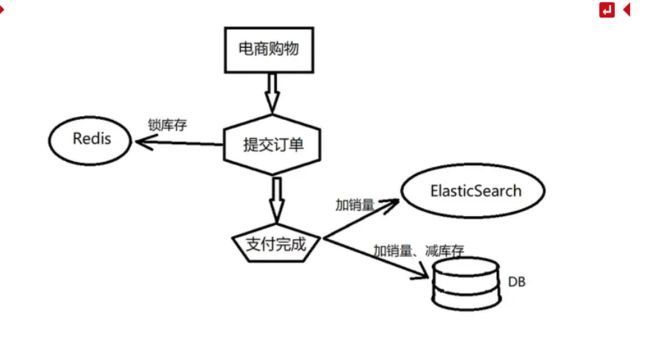
针对这一场景的优化方案,可以采用增量数据同步Flink CDC,助力程序员专注于业务代码,减少代码耦合度,降低代码冗余,并且不再需要去关心各种中间件的语法去实现数据同步,降低学习成本。
参考链接:
基于 Flink CDC 打造企业级实时数据集成方案
Flink CDC详细教程(介绍、原理、代码样例)
Flink CDC使用(数据采集CDC方案比较)-阿里云开发者社区
Flink CDC 2.4 正式发布,新增 Vitess 数据源,PostgreSQL 和 SQL Server CDC 连接器支持增量快照,升级 Debezium 版本-阿里云开发者社区