Linux IO模式之io_uring
1. 概述
作为科普性质的文章,在介绍 io_uring 之前,我们可以先整体看一下 linux 的 IO 模型大体有哪些类型。

图 1.1
从图 1.1 中可以看出,linux 的 IO 主要可以分为两个大类,而我们今天要介绍的 io_uring 就属于其中的 kernel IO 模型中的 async IO 模式的一种。
作为存储系统的开发者,高带宽和高 IOPS 是我们不断的性能追求,相比于通过 kernel bypass 的方式和硬件相结合来实现这种目标,kernel native IO 的方式似乎是一种更加友好通用的实现方式。
从 linux 的 IO 接口的发展看,async IO 是对于普通应用程序来说,实现高性能的必然选择,它通过异步方式来和 linux kernel 进行交互,减少了对用户态应用程序的阻塞过程,可以让应用程序有更多的机会去处理其他任务,提高了并发度。
名词解释:

2. io_uring 简介
从上面的分析中看出,io_uring 是 kernel natvie aio 的一种,它是 Linux Kernel 5.1 版本加入一个特性。通过设计 io_uring 这套全新的 aysnc IO 系统调用接口,让应用程序可以获得更高的性能,更好的兼容性。
2.1 libaio 的局限
在 io_uring 出现之前,主流的使用 kernel aio 模式的接口是使用 libaio 接口,这种接口存在着如下一些局限:
(1) 仅支持 direct IO。在采用 aysnc IO 的时候,只能使用 O_DIRECT,不能借助文件系统缓存来缓存当前的 IO 请求,还存在 size 对齐(直接操作磁盘,所有写入内存块数量必须是文件系统块大小的倍数,而且要与内存页大小对齐)等限制,这直接影响了 aio 在很多场景的使用。

图2.1
例如:从图 2.1 的流程看,例如 read 请求来说,direct IO 的模式会把从盘上读取的数据直接返回给了用户态的内存空间,不会在 kernel 中缓存,当存在多次重复读取的场景,每次都需要读盘,大大增加了 kernel 的负担。
(2) 仍然可能被阻塞。即使应用层主观上,希望系统层采用异步 IO,但是客观上,有时候还是可能会被阻塞。
(3) 拷贝开销大。每个 IO 提交需要拷贝 64+8 字节,每个 IO 完成需要拷贝 32 字节,总共 104 字节的拷贝。这个拷贝开销是否可以承受,和单次 IO 大小有关:如果需要发送的 IO 本身就很大,相较之下,这点消耗可以忽略,而在大量小 IO 的场景下,这样的拷贝影响比较大。
(4) API 不友好。每一个 IO 至少需要两次系统调用才能完成(submit 和 wait-for-completion),需要非常小心地使用完成事件以避免丢事件。
2.2 io_uring 的优势
io_uring 围绕高效进行设计,其设计了一对共享的 ring buffer 用于应用和内核之间的通信,通过该设计实现了如下的三个好处:
(1)避免在提交和完成事件中存在内存拷贝;
(2)避免了 libaio 中在提交和完成任务的时候系统调用过程;
(3)该队列采用了无锁的访问模式,通过内存屏障减少了竞争;
在共享的 ring buffer 设计中,针对提交队列(SQ),应用是 IO 提交的生产者(producer),内核是消费者(consumer);反过来,针对完成队列(CQ),内核是完成事件的生产者,应用是消费者。
另外,io_uring 还存在如下的优势:
(1)提交和完成不需要经过系统调用,而且减少了对用户态线程的阻塞;该部分的支持主要通过共享的 ring buffer 和设置 polling 模式来实现。
(2)支持 Block 层的 polling 模式
(3)支持 buffered IO,充分利用缓存,减少数据碰盘产生的系统延迟;
3. io_uring 的实现
名称解释:

用户态接口:
io_uring 的实现仅仅使用了三个用户态的系统调用接口:
(1)io_uring_setup:初始化一个新的 io_uring 上下文,内核通过一块和用户共享的内存区域进行消息的传递。
(2)io_uring_enter:提交任务以及收割任务。
(3)io_uring_register:注册用户态和内核态的共享 buffer。
使用前两个系统调用已经足够使用 io_uring 接口了。
3.1 初始化过程
要使用 io_uring 需要先进行实例的创建。通过调用 io_uring_setup()接口,在 kernel 中会创建一块内存区域,该内存区域分为三个部分,分别是 SQ,CQ,SQEs,如下图所示。

图 3.1
如上图所示,在 SQ,CQ 之间有一个叫做 SQEs 数组。该数组的目的是方便通过环形缓冲区提交内存上不连续的请求,即内核的响应请求的顺序是不确定的,导致在 SEQs 中插入新请求的位置可能是离散的。
SQ 和 CQ 中每个节点保存的都是 SQEs 数组的索引,而不是实际的请求,实际的请求只保存在 SQEs 数组中。这样在提交请求时,就可以批量提交一组 SQEs 上不连续的请求。

图3.2
另外,由于上面所述的内存区域都是由 kernel 进行分配的,用户程序是不能直接访问的,在进行初始化的时候,相关初始化接口会返回对应区域的 fd,应用程序通过该 fd 进行 mmap,实现和 kernel 的内存共享。在返回的相关参数中,会有对应三个区域在该共享内存中对应位置的描述,方便用户态程序的访问。
3.2 IO 提交和收割
在初始化完成之后,应用程序就可以使用这些队列来添加 IO 请求,即填充 SQE。当请求都加入 SQ 后,应用程序还需要某种方式告诉内核,生产的请求待消费,这就是提交 IO 请求。
IO 提交的做法是找到一个空闲的 SQE,根据请求设置 SQE,并将这个 SQE 的索引放到 SQ 中。SQ 是一个典型的 RingBuffer,有 head,tail 两个成员,如果 head == tail,意味着队列为空。SQE 设置完成后,需要修改 SQ 的 tail,以表示向 RingBuffer 中插入一个请求,当所有请求都加入 SQ 后,就可以使用相关接口 io_uring_enter()来提交 IO 请求。
io_uring 提供了 io_uring_enter 这个系统调用接口,用于通知内核 IO 请求的产生以及等待内核完成请求。为了在追求极致 IO 性能的场景下获得最高性能,io_uring 还支持了轮询模式,轮询模式有两种使用场景,一种是提交 IO 过程的轮询模式这是通过设置 IORING_SETUP_SQPOLL 来开启;另外一种是收割 IO 过程的轮询模式,通过设置 IORING_SETUP_IOPOLL 来开启。
3.2.1 提交 IO 的轮询机制
为了提升性能,内核提供了轮询的方式来提交 IO 请求,在初始化阶段通过设置 io_uring 的相关标志位 IORING_SETUP_SQPOLL 可以开启该机制。
在设置 IORING_SETUP_SQPOLL 模式下, 内核会额外启动一个内核线程,我们称作 SQ 线程。这个内核线程可以运行在某个指定的 core 上(通过 sq_thread_cpu 配置)。这个内核线程会不停的 Poll SQ,除非在一段时间内没有 Poll 到任何请求(通过 sq_thread_idle 配置),才会被挂起。
当程序在用户态设置完 SQE,并通过修改 SQ 的 tail 完成一次插入时,如果此时 SQ 线程处于唤醒状态,那么可以立刻捕获到这次提交,这样就避免了用户程序调用 io_uring_enter 这个系统调用。如果 SQ 线程处于休眠状态,则需要通过调用 io_uring_enter,并使用 IORING_ENTER_SQ_WAKEUP 参数,来唤醒 SQ 线程。用户态可以通过 sqring 的 flags 变量获取 SQ 线程的状态。
在提交 IO 的时候,如果出现了没有空闲的 SEQ entry 来提交新的请求的时候,应用程序不知道什么时候有空闲的情况,只能不断重试。为解决这种场景的问题,可以在调用 io_uring_enter 的时候设置 IORING_ENTER_SQ_WAIT 标志位,当提交新请求的时候,它会等到至少有一个新的 SQ entry 能使用的时候才返回。

图3.3
3.2.2 收割 IO 的轮询机制
在初始化实例时候通过设置 IORING_SETUP_IOPOLL 可以开启收割的轮询机制,这个功能让内核采用 Polling 的模式收割 Block 层的请求。
在轮询模式下,io_uring_enter 只负责把操作提交到内核的文件读写队列中。之后,用户需要多次调用 io_uring_enter 来轮询操作是否完成,通过主动轮询的模式,相对于等待中断信号的方式,可以提高收割的效率。
该种方式需要依靠打开文件的时候,设置为 O_DIRECT 的标记,该标记让应用程序调用 io_uring_enter 提交任务时,如下图所示的 io_read 直接调用内核的 Direct I/O 接口向设备队列提交任务。
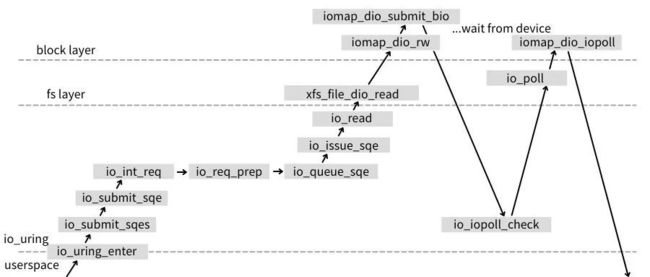
图3.4
从如上分析看,io_uring_enter 函数的功能主要是提交 IO、等待 IO 的完成或是同时执行两者功能,其具体的表现需要通过传入的参数来控制。
在 polling 模式下, 在设置了 IORING_ENTER_GETEVENTS 标志位,如果 min_complete 为非 0 的情况,那么 kernel 会只要有事件完成就会直接返回到应用;如果没有完成的事件,那么 kernel 会一直阻塞到有事件完成才会返回。
以上的执行过程都是在 IORING_SETUP_IOPOLL 模式执行的,如果是非 IORING_SETUP_IOPOLL 模式的情况下,没有设置 IORING_ENTER_GETEVENTS 标志位,应用程序只会检查 CQ ring 上是否有完成的事件,不会进入内核。设置了相应的标志位为 IORING_ENTER_GETEVENTS,那 kernel 会阻塞等到完成指定 min_complete 数量的事件才会返回。
3.2.3 轮询参数的配置
io_uring 大致可以分为默认、IOPOLL、SQPOLL、IOPOLL+SQPOLL 四种模式。可以根据操作是否需要轮询选择开启 IOPOLL。如果需要更高实时性、减少系统调用开销,可以考虑开启 SQPOLL。
只开启 IORING_SETUP_IOPOLL,会通过系统调用 io_uring_enter 提交任务和收割任务。
只开启 IORING_SETUP_SQPOL,无需任何系统调用即可提交、收割任务。内核线程在一段时间无操作后会休眠,可以通过 io_uring_enter 唤醒。
IORING_SETUP_IOPOLL 和 IORING_SETUP_SQPOLL 都开启,内核线程会同时对 io_uring 的队列和设备驱动队列做轮询。在这种情况下,用户态程序不需要调用 io_uring_enter 来触发内核的设备轮询了,只需要在用户态轮询完成事件队列即可。
3.3 buffer IO
每个 io_uring 都由一个轻量级的 io-wq 线程池支持,从而实现 Buffered I/O 的异步执行。对于 Buffered I/O 来说,文件的内容可能在 page cache 里,也可能需要从盘上读取。如果文件的内容已经在 page cache 中,这些内容可以直接在 io_uring_enter 的时候读取到,并在返回用户态时收割。否则,读写操作会在 workqueue 里执行。
如果没有在创建 io_uring 时指定 IORING_SETUP_IOPOLL 选项,io_uring 的操作就会放进 io-wq 中执行。
4. 结束语
io_uring 的接口虽然简单,但操作起来有些复杂,需要手动 mmap 来映射内存。可以看到,io_uring 是完全为性能而生的新一代 native async IO 模型,比 libaio 高级不少。通过全新的设计,共享内存,IO 过程不需要系统调用,由内核完成 IO 的提交, 以及 IO completion polling 机制,实现了高 IOPS,高 Bandwidth。相比 kernel bypass,这种 native 的方式显得友好一些。
附录:
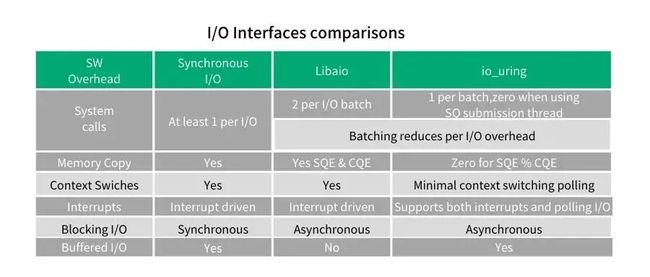
如下图所示,可以参照不同接口之间相关特性的支持情况,,做具体的对比分析。