Oracle的学习心得和知识总结(三十)| OLTP 应用程序的合成工作负载生成器Lauca论文翻译及学习
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Lauca论文地址链接,点击前往
7、TPGenerator: Lauca git仓库,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 )
OLTP 应用程序的合成工作负载生成器Lauca论文翻译及学习
- 文章快速说明索引
- 摘要
- I. INTRODUCTION
- II. PRELIMINARIES
-
- A. 问题定义
- B. 工作负载特征
- C. Lauca 概述
- III. DATABASE GENERATION
- IV. TRANSACTION LOGIC
-
- A. 直观的观点
- B. 事务逻辑的定义
- C. 提取算法
- V. DATA ACCESS DISTRIBUTION
-
- A. 倾斜的数据访问分布
- B. 动态数据访问分布
- C. 连续数据访问分布
- VI. WORKLOAD GENERATION
- VII. DISCUSSION AND ANALYSIS
- VIII. EXPERIMENTS
- IX. RELATED WORK
- X. CONCLUSION
- REFERENCES

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!
学习内容:(详见目录)
1、OLTP 应用程序的合成工作负载生成器Lauca论文翻译及学习
学习时间:
2023年11月19日 09:56:18
学习产出:
1、OLTP 应用程序的合成工作负载生成器Lauca论文翻译及学习
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();
version
-----------------------------------------------------------------------------
PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)
postgres=#
#-----------------------------------------------------------------------------#
SQL> select * from v$version;
BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0
Version 19.3.0.0.0
SQL>
#-----------------------------------------------------------------------------#
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)
mysql>
摘要
Lauca:生成面向应用程序的合成工作负载。它是第一个用于 OLTP 应用程序的合成工作负载生成器,可生成与特定应用程序的实际工作负载相比具有高度相似性能指标的合成工作负载。
合成工作负载对于数据库系统的性能评估至关重要。在评估特定应用程序的数据库性能时,合成工作负载与实际应用程序工作负载之间的相似性决定了评估结果的可信度。然而,目前用于性能评估的工作负载很难与目标应用具有相同的工作负载特征,从而导致评估结果不准确。为了解决这个问题,我们提出了一种工作负载复制器(Lauca),它可以为特定应用程序生成具有高度相似性能指标的合成工作负载。据我们所知,Lauca 是第一个面向应用程序的事务性工作负载生成器。通过对面向应用的合成工作负载生成问题的认真研究,提出了联机事务处理(OLTP)应用的关键工作负载特征(事务逻辑和数据访问分布),并提出了新的工作负载表征和生成算法,保证了合成工作负载的高保真度。我们使用 TPC-C、SmallBank 的工作负载以及 MySQL 和 PostgreSQL 数据库上的微基准进行了广泛的实验,实验结果表明 Lauca 始终生成高质量的合成工作负载。
索引术语 — 性能评估、合成工作负载、OLTP 应用程序
I. INTRODUCTION
性能评估对于数据库管理系统(DBMS)的开发至关重要。面向应用的数据库性能评估 是 指对数据库系统针对特定应用的能力进行评估[1]。应用场景包括:
数据库选择。DBMS是应用程序的基础支撑系统,因此应用程序开发人员需要为其目标工作负载选择一个性能令人满意的合适系统。利用根据实际应用工作负载构建的测试工作负载来评估候选DBMS是一种有效的手段。
PoC 测试。对于数据库厂商,尤其是一些新兴的数据库厂商,在向应用公司推销产品时,PoC(概念验证)测试是必不可少的。构建与对方应用尽可能相似的测试工作负载,是PoC结论最有力的保证。
面向应用的性能优化。一般我们可以发现,对于应用公司来说,在线工作负载下,数据库性能并没有达到预期;但对于数据库厂商来说,由于缺乏理想的评估工作负载,开发人员无法重现优化过程中的性能问题。
目前,评估数据库性能的方法主要有3种。评估工作负载分别是 真实在线工作负载、标准基准测试工作负载和合成工作负载。然而,由于以下缺陷,现有方法对于面向应用的数据库性能评估并不是最佳的:
数据隐私问题:出于隐私考虑,数据库供应商通常无法从客户那里获取真实的在线工作负载来评估系统性能。事实上,对于公司自己的测试人员来说,数据隐私保护也很麻烦。因此,必须使用模拟工作负载来完成评估。
Application oblivious:人们可以使用标准基准来评估数据库性能,而不会出现数据隐私问题。然而,标准基准是为通用评估而设计的,其工作量过于笼统,无法模拟特定应用,从而产生不准确的评估结果。
最近有一些关于为在线分析处理 (OLAP) 应用程序生成面向应用程序的合成工作负载的工作 [4]、[5]。然而,对于 OLTP 应用程序来说,这仍然是一个尚未探索的领域,正是这一差距激发了这项工作。
在本文中,我们提出了 Lauca,一种用于面向应用程序的数据库性能评估的事务工作负载生成器。基本目标是 Lauca 生成的合成工作负载尽可能与真实应用程序工作负载相似,以便 Lauca 评估的性能指标包含更多信息。为了实现这一目标,我们定义了OLTP应用程序的关键工作负载特征,即事务逻辑和数据访问分布,它们决定了OLTP应用程序在数据库系统上的关键运行时行为,包括事务冲突强度、死锁可能性、分布式事务比率和缓存命中率。首次提出事务逻辑,捕捉潜在业务逻辑,进行精细的工作负载模拟;从偏度、动态性和连续性的角度描述数据访问分布,以保证合成工作负载的真实性。
为了解决数据隐私问题,Lauca设计隔离生产环境和评估环境,如图1所示,其中涉及真实应用数据的组件由数据所有者在生产环境中执行。
- 通过分析工作负载轨迹,我们可以提取目标应用程序工作负载的事务逻辑和数据访问分布,用于生成用于评估目的的合成工作负载
- 从真实数据库实例中提取数据库模式和数据特征,以生成评估侧的合成数据库
据我们所知,Lauca 是第一个用于面向应用程序的数据库性能评估的事务工作负载生成器。大量的实验结果表明,我们提出的事务逻辑和数据访问分布可以有效地表征OLTP应用程序的工作负载,并且Lauca生成的合成工作负载与真实应用程序工作负载之间的性能指标偏差始终小于10%。

II. PRELIMINARIES
A. 问题定义
在给出正式的问题定义之前,我们列举了面向应用的数据库性能评估的自然要求如下:
保真度:评估工作负载应与实际应用程序工作负载高度相似。通过评估获得的性能指标(例如吞吐量、延迟、各种物理资源的利用率等)预计与在真实应用程序环境中运行的相同。评估工作负载和实际应用程序工作负载之间的相似性是通过 性能指标的偏差 来衡量的。偏差越小,相似度越高。
Sheltering:数据隐私保护是商业应用的基本要求,因此真实数据和工作负载一般不能直接用于数据库性能测试。
可扩展性:目标应用可能具有巨大的数据规模和高请求并发/吞吐量。它要求工作负载生成工具集可扩展到多个节点,并且可以支持并行数据库和工作负载生成。
延伸:有时,我们需要扩展当前的应用程序工作负载,以衡量预期规模的合成工作负载下的数据库性能。由于本文针对事务性工作负载,因此主要扩展方向是请求并发度和请求吞吐量。
基于这些需求,我们在下面的 Def.1 中提出了面向应用的合成工作负载生成问题。
定义1:面向应用程序的合成工作负载生成:生成与目标应用程序工作负载高度相似的合成工作负载,这不仅需要在数据库的性能指标上有很小的偏差,而且还需要保证保密、可伸缩性和扩展的属性。
B. 工作负载特征
为了使合成工作负载和真实应用程序工作负载在同一数据库系统上具有相同的执行成本,从而具有相同的性能指标,我们必须分析在合成工作负载生成过程中哪些工作负载特征需要我们关注和控制。
请注意,我们的工作是在某个数据库系统上模拟特定应用程序的工作负载,一些因素是固定的,例如数据库模式、事务模板、DBMS 的实现机制等。事务模板 transaction template由多个带有符号参数的SQL操作组成,有时还包含条件分支和循环结构。我们通过实例化transaction模板中的符号参数来生成合成工作负载。

从图2可以看出,数据库系统主要分为三部分,即SQL层、事务层和存储层。
- 由于我们关注的是通常不涉及查询优化的事务性工作负载,因此合成工作负载的生成策略对 SQL 层的执行成本影响很小
- 但在事务层,工作负载生成策略对并发控制模块的执行成本有显着影响。对于独立的数据库系统来说,这里可能受影响的主要工作负载特征是事务冲突强度和死锁可能性。如果是分布式数据库系统,还需要关注对分布式事务比例的影响
- 日志量是 日志记录和恢复 性能的主要决定因素[27]。它是由事务模板W、数据特征D和数据库引擎设计决定的。由于W、D和数据库引擎是固定的,因此日志量是固定的。
- 索引和缓冲区管理是存储层
Storage Layer中的两个主要模块[26]。当数据库模式H和事务模板W固定时,索引访问的执行成本与工作负载特征的数据访问分布和数据特征的数据分布高度相关。不同的生成策略可能会导致不同的缓存命中率和索引维护成本。缓冲区管理中的缓存命中率对工作负载生成策略非常敏感,这也应被视为一个关键的工作负载特征。索引维护成本与缓存命中率、争用、B树中的树变化、散列中的容量扩展等密切相关。这些因素由工作负载特征W捕获。此外,数据之间的逻辑局部性或物理局部性都会影响性能 ,例如 I/O 成本。然而,物理位置可能与逻辑位置不一致。例如,Hash和Heap中逻辑访问分布局部性和物理存储局部性相关性不高;B树的局部依赖性locality dependency受动态插入或删除的影响
为了确保合成工作负载和实际应用程序工作负载在这四个数据库站点database-site工作负载特征上保持一致,我们定义和操作两个应用程序端工作负载特征,即事务逻辑和数据访问分布transaction logic and data access distribution。
- 事务逻辑描述了SQL参数和返回项之间的关系,是目标应用程序潜在业务逻辑的表示。潜在的业务逻辑,例如事务中不同SQL操作访问的数据项在一定概率上满足一定的相关性,通常无法一眼看出,需要通过分析工作负载轨迹来获取。事务逻辑对事务冲突强度、死锁可能性和分布式事务比率有很大影响。有关事务逻辑的技术细节可在第四节中找到。
- 数据访问分布用来表征SQL操作对数据项的访问分布。我们分析工作负载跟踪以获得数据访问分布,即 SQL 参数的数据分布,用于工作负载生成期间的参数实例化。数据访问分布对事务冲突强度、死锁可能性和缓存命中率有很大影响。第五节介绍了有关数据访问分布的所有细节。
尽管在某些数据库实现中,事务层和存储层可以合并在一起,但影响数据库性能的因素仍然与我们之前的分析一致。表1总结了数据库端工作负载特征和应用程序端工作负载特征之间的对应关系。

C. Lauca 概述
Lauca的基础设施可以分为两种类型的组件,它们运行在生产环境或评估环境中,如图1所示。下面,我们将从合成数据库生成和合成工作负载生成简要描述Lauca的工作流程。
数据库生成。Database Generator的输入主要由两部分组成:数据库模式和数据特征。由于数据特征比较繁琐并且需要从真实数据库中获取,因此我们提供了数据特征提取器,它可以帮助我们通过使用简单的 SQL 查询自动获取这些信息。在Lauca中,我们只关注测试数据库的一些基本数据特征(例如列域),因为合成工作负载的工作负载特征是影响数据库性能的关键因素。技术细节可参见第三节。
工作负载生成。目标应用程序的事务模板是工作负载生成器的输入之一。在用具体的值实例化事务模板中的所有符号参数之后,我们可以得到一个可以在测试数据库上运行的具体事务。为了保证合成工作负载与真实应用工作负载的相似性,工作负载生成器中的参数实例化满足事务逻辑分析器和数据访问分布分析器分别提取的事务逻辑和数据访问分布。
- 事务逻辑分析器的输入是短时间(例如十分钟)的大工作量轨迹,其中包含每个SQL操作的所有参数和返回项。
- 数据访问分布分析器的输入是长时间(例如,完整工作负载周期)轻工作负载跟踪,其中仅包含关键SQL参数。
- 工作负载跟踪可以由应用程序客户端或数据库服务器记录。相关技术细节可参见第六节。
III. DATABASE GENERATION
生成测试数据库实际上就是生成表,同时满足主/外键约束,以及非键列的一些数据特征,例如类型、表大小和基数大小。虽然我们的参数实例化与生成的数据密切相关,但 Lauca 通过保证事务的执行语义而不是数据的相似性来模拟 OLTP 应用程序。数据库生成所需的所有数据特征与 Touchstone [5] 相同。

不失一般性,我们假设主/外键列是整数。主键是记录的标识符,一般没有物理意义,所以我们不需要考虑这些键列的数据特征。我们简单地顺序生成主键,并在引用的主键域内随机生成外键,这样可以保证主键的唯一性和外键的引用完整性。在生成键列之前,有三个步骤确定键列的域,示例如图3所示:
- 首先,如果主键只包含一个列,则域为[1,s],其中s为表大小(如图3中的①)。
- 然后,通过引用主键列的域确定外键列的域(如图3中的②)。
- 第三步,确定复合主键中非外键列的域,例如列
T.t2(如图3中的③)。最常见和最合理的情况是复合主键中只有一个非外键列。该列的定义域为:

其中 dfk 是复合主键中的一个外键列的定义域。
- 其他情况的处理也类似。由于级联引用,第二步和第三步可能需要执行多次。
随机列生成器包含随机索引生成器和值转换器,用于生成非键列的值,同时满足所需的数据特征,特别是唯一值的基数。随机索引生成器的输出是从 1 到 n 的整数,其中 n 是列基数column cardinality。给定一个索引,转换器确定性地将其映射到列域中的值。我们根据列的数据类型采用不同的转换器。对于数字类型,例如整数,我们只需选择一个线性函数,将索引统一映射到列域。对于字符串类型,例如varchar,有一些随机预生成的种子字符串,满足长度要求。我们首先根据输入索引选择一个种子字符串,例如第 (i%k)th 个种子字符串,其中 i 是索引,k 是所有种子字符串的数量。然后我们将索引和选定的种子字符串连接起来作为输出值。
综上所述,各个表的生成是相互独立的。并且对于每个表,我们可以通过为每个线程分配主键范围来实现多个节点上的多个线程并行数据生成。
IV. TRANSACTION LOGIC
本文提出的 事务逻辑 并不是工作[6]中谓词逻辑的扩展,而是OLTP应用程序潜在业务逻辑的表示。在本节中,我们首先通过一个具体的例子来直观地解释为什么事务逻辑很重要;然后我们明确给出事务逻辑的形式化定义;最后,我们介绍如何从工作负载跟踪中有效地提取事务逻辑。
A. 直观的观点
下面是一个示例transaction模板(简称TT),用于说明transaction逻辑的必要性。
Start Transaction
update S set s3 = s3 + ? where s1 = ?;
update T set t3 = t3 + ? where t1 = ? and t2 = ?;
select r2, r3 from R where r1 = ?;
update R set r2 = r2 - ? where r1 = ?;
Commit
TT中的表可以参考图3。r2、r3、s3和t3是双类型非键列。现在假设我们部署了一个分布式数据库,表R、S、T都是按主键进行哈希分区的。当生成基于 TT 的合成工作负载时,我们通常使用给定数据分布生成的随机值来实例化 SQL 参数。然而,此类合成工作负载与实际应用程序工作负载之间可能存在显着的性能差异。真实的工作负载通常在谓词中的参数之间具有相关性以承诺业务逻辑。
例如,谓词“s1 = ?”和“t1 = ?”中的参数实际上有很高的概率(例如 99%)相同。因此,TT中前两次SQL操作并不会带来很多分布式事务。但在合成工作负载中,上述两个参数是随机生成的,并且它们很可能不同,这将导致严重的分布式事务。众所周知,分布式事务的比例对数据库性能有着至关重要的影响[7]。不仅如此,TT 中最后两个 SQL 操作的谓词参数,即“r1 = ?”,在实际工作负载中始终相同,因此实际上不存在死锁。然而,这两个参数在合成工作负载的生成过程中可能会不同,从而可能导致死锁。死锁的发生会严重影响数据库的性能。通过这个例子可以直观地看出,目标应用的潜在业务逻辑,即我们提出的事务逻辑,是合成工作负载生成的重要工作负载特征,必须保证与真实应用工作负载一致。
B. 事务逻辑的定义
实际应用的工作负载差异很大,潜在的业务逻辑更难以描绘。因此,事务逻辑的定义必须跳出应用业务的角度。我们可以使用 事务结构信息 transaction structure information 和 参数依赖信息 parameter dependency information 来定义事务逻辑。分支和循环是事务中常见的结构。每个分支被执行的概率以及循环操作被执行的平均次数对transaction执行成本有重要影响。这些都需要在transaction结构信息中进行描述。
事务模板中SQL参数和返回项之间的关系决定了SQL操作之间隐藏的语义。在对现有 OLTP 基准工作负载和实际应用程序工作负载进行调查后,我们关心四种类型的关系。
- 首先,“平等关系”
‘equal relationship是最常见的。例如,两个SQL参数在一定概率下相等。 - 其次,“包容关系”
inclusive relationship也很熟悉。由于 SQL 结果集可能是一组元组,因此 SQL 参数的值可能是前一个返回项的返回值中的元素。 - 第三,“线性关系”
linear relationship是对等关系的补充和延伸,具有更强的表达能力。 - 第四,对于谓词“col between p1 and p2”和“col≥p1 and col≤p2”提出了
between relationship,其中p2与p1之间存在between关系。为了简化问题,我们只考虑当前参数和前一个参数(或返回项)之间的关系(即依赖关系)。
现在我们在下面的Def.2中给出事务逻辑的正式定义。让我们从一些术语开始。Oi表示transaction模板中的第ith个操作; pi,j (分别是 ri,j )是 Oi 的第 jth个参数(分别是 return item),其中 i 和 j 都从 1 开始计数。我们使用缩写ER、IR、LR和BR分别表示相等关系、包含关系、线性关系和between关系。
定义2:事务逻辑:对于transaction模板来说,transaction逻辑由transaction结构信息和参数依赖信息组成,具体为:
• Transaction structure:
#1 Execution probability of each branch in the branch structures. 分支结构中每个分支的执行概率
#2 Average numbers of executions for operations in the loop structures. 循环结构中操作的平均执行次数
• Parameter dependencies for each parameter pi,j :
$1 [pi,l, pi,j , BR, ∆]
$2 A list of dep-item, where dep-item ∈ {
[pm,n, pi,j , ER, ξ], [pm,n, pi,j , LR, ξ, (a, b)],
[rx,y, pi,j , ER, ξ], [rx,y, pi,j , LR, ξ, (a, b)],
[rx,y, pi,j , IR, ξ] };
m ≤ i; x < i; and if m = i, then n < j.
$3 A list of [pi,j , LR, ξ, (a, b)], where Oi must be an operation in the loop structure.

注意,如果参数pi,j有依赖项$1,那么依赖项$2和$3都不需要存在,因为pi,j可以用(pi,l +∆)表示,其中∆是从工作量跟踪中计算的平均增量。在依赖项中,ξ为对应依赖项满足的概率;(a, b)是表示线性关系的两个系数。例如在章节IV-A中,TT中参数p2,2的依赖项$2包括[p1,2, p2,2, ER, 99%],参数p4,2有依赖项[p3,1, p4,2, ER, 100%]。而且,由于循环结构中的操作通常会执行多次,因此在循环执行过程中,我们需要考虑这些操作中SQL参数的变化。依赖关系 $3 用于表示循环操作的连续运行中相同参数的值之间的线性关系。例如,[pi,j, LR, 90%,(2,1)]表示有90%的概率pi,j在当前循环执行中的值是(2 * v + 1),其中v是前一次循环执行中pi,j的值。如果一个参数不在循环结构中的操作中,它只能有依赖项$1或依赖项$2。
C. 提取算法
事务逻辑是应用程序业务逻辑的体现,因此一般不会随着时间的推移而频繁变化。因此,事务逻辑的提取不需要长时间的工作负载痕迹。由于各个transaction模板的transaction逻辑分析是相互独立的,因此针对单个transaction模板引入以下提取算法。我们的提取算法由六个步骤组成。输入是一个transaction模板和K个transaction实例对应的工作负载轨迹。
步骤1:结构信息。通过遍历工作负载轨迹,我们可以统计事务模板中每个操作的执行次数,并用它来计算每个分支的执行概率以及循环操作的平均执行次数。
步骤 2:识别 BR。首先,我们识别事务模板中满足关系的所有参数对
步骤 3:收集 ER 和 IR 的统计数据。对于transaction模板中的每个参数 pi,j,我们遍历其之前的参数 pm,n (resp 返回项 rx,y),并统计其中
[
步骤4:收集LR的统计数据。LR仅涉及数字类型参数和返回项,并且返回项必须来自基于主键过滤的操作。由于计算LR的系数(a,b)需要两个transaction实例,因此我们从K个transaction实例中随机选择N组transaction实例(每组两个)。然后我们根据 N 组transaction实例计算每对(即
步骤5:通过权衡确定ER、IR和LR。利用步骤 3-4 中获得的统计数据,我们可以轻松构建每个参数 pi,j 的依赖关系 $2 。然而,每个参数可能存在很多依赖关系,有些参数的概率可能很小(即 ξ),因此我们需要在这些依赖关系之间进行权衡trade-off,以消除噪声并减轻后续计算。我们选择最重要的依赖项,例如那些概率较高的依赖项,并确保所选依赖项的概率之和小于 1。我们更倾向于保留ER,在实验部分我们可以发现ER比IR和LR重要得多。
步骤6:构造LR for循环结构。对于循环结构中多次运行的操作,我们使用依赖项$3来表征参数的变化。通过遍历工作负载跟踪,可以对循环结构中的每个 SQL 参数计算连续运行中的值变化。系数(a,b)的计算与步骤4类似。然后根据统计数据,我们构造依赖关系$3并与依赖关系$2独立维护。假设有一个示例依赖关系 [p5,3, LR, 90%, (1, 1)],它表示在循环执行期间 p5,3 相对于上次运行的值增加 1 的概率为 90%。
需要注意的是,如果步骤3-4遇到循环结构中的操作,则仅使用第一次执行的跟踪数据。我们的提取算法的复杂度主要由步骤 3-4 决定,即 O(KV2+NV2)。并且在实际评估中,K和N可以设置为数万,V可能为数十或数百,因此transaction逻辑的提取非常快。在我们的实验中,我们发现当 K = 104 和 N = 104 时,transaction逻辑的提取通常只需要几秒钟。
V. DATA ACCESS DISTRIBUTION
数据访问分布长期以来被认为是一个重要的应用程序工作负载特征[8]。在本节中,我们将介绍如何表征和操纵合成工作负载生成的数据访问分布的偏度(第 V-A 节)、动态性(第 V-B 节)和连续性(第 V-C 节)。
A. 倾斜的数据访问分布
正如第 II-C 节中所介绍的,合成工作负载的生成实际上是事务模板中符号参数的实例化。因此,合成工作负载的数据访问分布是由这些实例化参数的值决定的。我们对数据访问分布的分析只需要包含 关键参数 的轻型工作负载跟踪,这些参数用于索引 SQL 操作中涉及的数据。在下面的内容中,我们将介绍用于描述数据访问偏度的 S-Dist,数据访问偏度对数据库性能有严重影响。

在不失一般性的前提下,我们假设对于 OLTP 应用程序工作负载,决定数据访问分布的谓词形式可以表示为 "col op para"。我们使用从工作负载跟踪中提取的高频项high frequency items(HFI)和直方图统计histogram statistics(HS)来表示每个参数的 S-Dist。
直方图是一种常用的密度估计统计方法,在 Oracle、MySQL 和 PostgreSQL 等行业数据库中被广泛用于表示数据分布统计。在 S-Dist 中,HFI 记录出现频率最高的 H 最热数据项(即具体参数值)。
列域被平均划分为 I 个区间,然后统计每个区间内除 HFI 参数外的其他参数的频率和奇偶性,以获得 HS。频率和卡方数 frequency and cardinality 这两个统计量用于准确描述区间的访问偏度。例如,虽然某个区间的频率不是很高,但该区间的卡入度却非常小,那么该区间的参数值仍然会导致较高的冲突。图4是S-Dist的示例。在本例中,H和I均为5,对应的列是域为[0, 2000]的整数。在HFI中,最热门的项目是57,频率为0.17;在HS的第一个区间,有20个唯一参数值,总访问频率为0.08。
S-Dist 的 HFI 中的数据项来自真实数据库上运行的工作负载跟踪。然而,第三部分生成的合成数据库中的数据通常与真实数据库中的数据完全不同。例如,图4中HFI中的真实数据57可能不存在于我们的合成数据库中。
因此,在使用S-Dist实例化符号参数之前,我们需要首先对HFI进行数据转换。假设我们示例的列生成器是index = ranInt[1, 400], value = index * 5,其中 400 是列基数。
- 首先,我们使用列生成器重新生成 HFI 中的数据项,如图 5 所示,例如,数据项 57 被替换为 195。
- 然后,我们根据高频项的频率和所有区间计算累积概率数组(图 5 中的
cumu prob)。 - 最后,我们使用随机生成器生成 0 到 1 之间的值,这些值可以映射到累积概率数组并用于选择适当的参数值来填充谓词。
在图5中,有两个参数生成示例。这样,我们就可以很容易地确保生成的参数符合期望的频率分布。参数生成的复杂度为 O(log(H+I)),主要由累积概率数组上的二分搜索决定。

另外,为了控制每个区间上所生成参数的基数,我们重新定义了一个随机索引生成器用于参数生成,即index = 向下取整( ranInt[0, cdni) / cdni * cdnavg )+ minIdxi,其中cdni为目标区间上所生成参数的期望基数,cdnavg为每个区间的平均基数,minIdxi为目标区间的最小索引。值转换器保持不变。在图5中,区间2的随机索引生成器为index = 向下取整( ranInt[0,50) / 50 * 80) + 161,其中cdn2 = 50, cdnavg = 400/5 = 80, minIdx2 = 80 * 2 + 1 = 161。
尽管上面示例中的参数是整数类型,但我们的方法是通用的。对于非键列对应的所有数值参数,S-Dist 的表示和参数生成完全相同。对于关键列上的参数,存在细微差别。由于我们的合成数据库中的主键是顺序生成的,因此合成数据库中的键列的域可能与真实数据库中的不同。因此,在对S-Dist进行统计时,我们利用真实数据库中关键列的域来划分区间并构建HS。但在合成工作负载生成过程中,我们使用合成数据库中关键列的域来支持参数生成。对于字符串类型的参数,最大的区别在于我们如何划分区间。构造HS时,对于字符串类型参数,通过h%I计算其所属区间,其中h为参数的哈希码。参数生成与数字类型类似,并注意参数生成的值转换器与合成数据库生成的值转换器一致。
B. 动态数据访问分布
S-Dist可以很好地描述整个工作负载周期中数据访问分布的偏度。然而,如果数据访问分布是动态变化的,S-Dist 就不准确甚至完全错误。让我们举一个简单的例子。假设有一个包含 103 条记录的表,工作负载的周期为 103 秒。在第 i 秒内,工作负载的所有数据库请求仅访问表中的第 i 条记录。假设这段时间数据库的吞吐量是稳定的。这时候如果用S-Dist来表达整个数据访问过程,我们实际上发现没有热点数据,而且数据访问分布非常均匀。显然,这与事实相差甚远。对于根据这个S-Dist生成的合成工作负载,数据库上的事务冲突强度必须远低于真实工作负载的强度。因此,在本节中,我们提出 D-Dist 来表征数据访问分布的动态性和偏度。
为了捕捉这种动态,我们根据日志时间戳将参数的工作负载轨迹划分为多个等长的时间窗口。对于任何时间窗口中的参数迹线,我们生成其单独的S-Dist,并且整个参数迹线的D-Dist被定义为S-Dist列表。假设整个工作负载周期为1天,时间窗口大小为1秒,则该参数的D-Dist由24*3600=86400个S-Dist构成。在合成工作负载的生成过程中,我们使用与生成时间相对应的 S-Dist 来实例化符号参数。另外,对于数值参数,时间窗口内使用的数据范围可能比列域小得多。为了提高HS的准确性,在统计时可以根据当前窗口的数据范围来划分区间。当然,在生成参数时还需要使用每个区间对应的索引范围。

C. 连续数据访问分布
在某些应用中,数据的热度与时间密切相关,具体表现为在一段时间内数据可能被持续访问。我们称之为数据访问分布的连续性。例如,对于在线外卖应用来说,早上通常会频繁点包子,而下午最喜欢的可能是咖啡。此前,D-Dist 被定义为捕获时间窗口内数据访问的偏度,而忽略连续时间窗口之间数据访问的连续性。当使用它来生成合成工作负载时,连续时间窗口之间访问的数据可能完全不同,这导致缓存命中率较低。因此,我们提出 C-Dist 来表征数据访问分布的连续性、动态性和偏度。
我们为C-Dist引入重复率的概念来描述基于D-Dist的数据访问的连续性。统计时,统计当前时间窗口内高频项与前一时间窗口内高频项的重复率,以及所有区间的参数重复率。图 6 继续图 4 中的示例,添加了 HFI 和 HS 的重复率。在此示例中,我们可以看到 HFI 的重复率为 0.6,即保留了前一个时间窗口中的 3 个高频项。HS 中五个间隔的重复率为:0、0.33、0.5、0.46 和 0.56。假设cdn1为15,则区间1内有15*0.33≈5个参数在前一个时间窗口中出现过。
为了保证C-Dist中的重复率,我们需要预先生成每个时间窗口的候选参数。
在Alg.1,我们列出了候选参数的详细生成过程:
- 在第 1-2 行中,我们生成满足预期重复率的所有高频项。
- 在第3-10行中,我们遍历前一个时间窗口内的所有参数,并为每个区间选择重复的参数,直到满足该区间上的重复率。
- 第6行,根据参数的值推导参数的索引,从而识别出其在当前时间窗口内所属的区间号。如果索引不在当前时间窗口的索引域内,则忽略该参数。对于字符串类型的参数,例如“296#dgtckuy”,由“#”字符分割的值的前面部分就是我们需要的索引。
- 最后,在第 11-13 行中,我们生成添加到每个间隔的随机参数,以达到基数要求。基于这些候选参数,我们的参数生成机制仍然与图5一致。现在对于某个区间,我们只需要随机选择一个候选参数作为输出。
最后但并非最不重要的一点是,如果在合成工作负载生成过程中在线生成候选参数,则工作负载生成器,即Lauca,可能会成为性能瓶颈,从而影响评估结果的正确性。因此,我们可以离线生成所有时间窗口的候选参数并将其存储在磁盘上,然后在生成合成工作负载时根据需要读取它们。

VI. WORKLOAD GENERATION
给定每个事务模板的事务逻辑和每个参数的数据访问分布,图1中的工作负载生成器负责生成满足所需配置的合成工作负载。同时,在分布式环境中高效生成高并发/吞吐量的合成工作负载也是我们工作负载生成器的基本要求。现在我们将从线程模型、事务执行和参数实例化三个层面来展示工作负载生成的细节。
线程模型。用户可以配置多个测试节点来部署工作负载生成器以及每个节点上的测试线程数,以模拟并发情况。对于每个测试线程,我们建立一个单独的数据库连接。Lauca 支持两种不同的测试线程调用事务的执行模型:循环中无等待和固定吞吐量。通过 no-await-in-loop 设置,所有测试线程都会重复发出事务,而在请求之间没有任何思考时间。在固定吞吐量设置中,用户可以指定固定请求吞吐量或吞吐量比例因子。如果指定了吞吐量比例因子,我们将比例因子与从工作负载跟踪中获得的每个时间窗口的吞吐量相乘,以获得目标吞吐量。测试线程通过控制事务请求之间的思考时间来实现所需的吞吐量。当所需的吞吐量超过当前测试线程可以达到的最大吞吐量时,执行模型退化为 no-await-in-loop。不同的执行模型使我们能够构建扩展的合成工作负载。
事务执行。测试线程根据从工作负载跟踪中提取的事务比例来调用不同类型的事务。并且transaction比例随着时间窗口定期调整。事务执行过程中,会根据其事务逻辑的结构信息来判断是否需要执行分支结构中的操作,以及循环结构中操作的执行次数。对于特定SQL操作的执行,我们首先将所有符号参数一一实例化,然后将带有具体参数值的操作发送到测试数据库。操作执行后,结果集和参数将维持在中间状态,以便在同一事务实例内的后续操作中生成其他参数。
参数实例化。在实例化参数时,我们首先保证事务逻辑的一致性,然后保证合成工作负载的数据访问分布。对于一个参数,情况1:如果只有$1的依赖关系,则可以直接根据增量Δ和相关的较小参数来计算该参数的值。情况 2:如果只有 $2 依赖项,我们首先尝试通过根据概率随机选择依赖项来实例化参数。当没有选择依赖项时,我们使用数据访问分布来实例化该参数。情况3:如果同时存在依赖关系$2和$3,则相应的操作必须在循环结构中。对于第一次循环执行,我们仍然根据依赖项 $2 和数据访问分布实例化参数(如情况 2)。对于非第一次循环执行,我们首先尝试根据概率使用依赖项 $3 实例化参数。如果未选择依赖项 $3,则使用依赖项 $2 和数据访问分布来实例化该参数。
总体而言,所有测试线程的事务执行和参数实例化都是相互独立的,因此我们的工作负载生成器可以部署在多个节点上,以有效生成高并发/吞吐量的合成工作负载,同时满足所需的工作负载特征和配置。
VII. DISCUSSION AND ANALYSIS
对并发控制机制的敏感性。并发控制确保事务并发执行时数据库的一致性。不同的隔离级别通过在性能和数据完整性之间进行权衡来解决不同类型的冲突,如表 II 所示。

W-W 冲突必须在任何隔离级别解决。对于RC来说,在单版本模式下,可能会遇到短R-W冲突,而在多版本模式下,可以通过使用先前版本的数据来避免这种冲突。对于RR来说,事务读取的数据直到事务结束才可以修改,并且容易出现长R-W冲突。SI以多版本的方式实现。它可以通过对事务使用两个时间戳来避免读写冲突。SR 检查范围读取和其他写入之间所有可能的冲突,以避免幻象,如果工作负载包含大量范围读写冲突,幻象会极大地降低性能。隔离级别与冲突密切相关,而悲观或乐观实施并发控制只会影响处理冲突的成本。Lauca 定义事务逻辑并提取数据访问分布,以从实际工作负载中捕获工作负载冲突。因此Lauca适用于不同并发控制协议和隔离级别下的数据库评估。
数据保护。由于我们将生产环境与生成(评估)环境隔离,测试人员无法接触真实数据和工作负载跟踪。仅暴露数据统计和工作负载描述信息。为了进一步保护模式,我们允许对表、列和事务模板的名称进行匿名化;我们可以在表中插入嘈杂的列,例如 bool、int 或 char 类型的列,这些列不会对 I/O 造成太大影响;列域可以更改。对于跟踪保护,我们仅使用事务模板内的参数依赖关系。但目前,如果对我们生成的数据进行逆向工程,我们无法保证隐藏所有敏感信息。
事务逻辑的限制。定义 2 中的事务逻辑旨在支持对现实世界应用程序中常见工作负载的抽象。当前我们的工作还存在不足。首先,定义的参数依赖关系不完整,无法表示复杂的依赖关系,例如二次函数。其次,目前只考虑两个数据项之间的关系,没有考虑更多数据项之间的关系。第三,不同关系的重要性可能差别很大,这已经被量化了。这些问题有待今后工作中解决。
选择窗口大小和间隔数。时间窗口大小的设置取决于目标工作负载变化的频率。如果工作负载频繁变化,则窗口大小应设置为较小的值,否则应设置为较大的值。我们建议将时间窗口大小设置为 1 秒,以便甚至可以捕获秒级的工作负载变化。直方图广泛应用于Oracle、MySQL、PostgreSQL等行业数据库中表示数据分布统计。
VIII. EXPERIMENTS
环境:我们在两个集中式数据库(即 MySQL(v5.7.24)和 PostgreSQL(v10.4))和一个分布式数据库(即 TiDB(v5.0.0))上评估 Lauca。我们在两台独立的服务器上部署实验,其中一台用于客户端,另一台用于 MySQL 和 PostgreSQL 的数据库服务。每台服务器均配备 2 个 Intel Xean Silver 4110 @ 2.1 GHz CPU、120 GB 内存、由 RAID-5 配置的 4 TB HDD 磁盘和 4 GB RAID 缓存。我们将 TiDB 部署在一个 5 节点集群上,其中包含 3 台 TiKV 服务器、1 台 PD 服务器和 1 台监控服务器,用于演示工作负载的分布式特性。每台 TiKV 服务器都有一个 8 个 Intel Cascadelake 6248R @ 3.0 GHz CPU 和 16 GB RAM。所有服务器均使用千兆以太网连接。
工作量:整个实验使用了两个标准基准: TPC-C [10] 和 SmallBank [1]。TPC-C 是使用最广泛的工业级 OLTP 基准之一。它涉及九个表和五种类型的事务,模拟复杂 OLTP 应用程序中的活动。SmallBank 抽象了银行应用中的操作,包括三个表和六种事务。SmallBank 的所有事务都对少量图元执行简单的读取和更新操作。我们使用 OLTP-Bench [12](一种可扩展的 DBMS 基准测试平台)生成 TPC-C 和 SmallBank 的工作负载,作为实际工作负载进行比较。OLTP-Bench 记录工作负载轨迹,并将其作为生成合成工作负载的 Lauca 输入。顺便提一下,OLTPBench 的原始 TPC-C 实现人为地将测试线程与仓库绑定,这大大减少了数据库上生成的工作负载的冲突。我们在实验中取消了这种额外的绑定,使工作负载更加实用。雅虎云服务基准(YCSB)[9] 是一组代表大规模网络应用的工作负载。我们在 YCSB 的基础上构建了微型基准工作负载,用于模拟对倾斜度、动态性和连续性进行细粒度控制的工作负载。
设置:在事务逻辑提取中,事务实例的数量K和事务实例的分组数量N均设置为104。对于数据访问分布提取,HFI中的项目数H和HS中的间隔数I均设置为50,时间窗口大小设置为1秒。
A. 合成工作负载的保真度
合成工作负载与真实应用工作负载之间的相似性称为工作负载保真度,是设计 Lauca 时最重要的目标。其衡量标准是在同一数据库系统上运行合成工作负载和真实应用工作负载所获得的性能偏差。

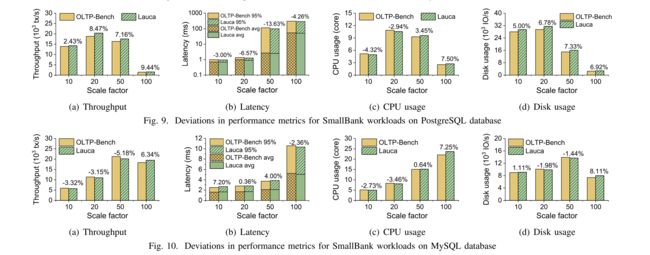
图 7-10 显示了在不同比例因子 (SF) 下,Lauca 生成的合成工作负载与 OLTP-Bench 生成的实际工作负载之间的性能偏差。数据库请求的并发度与比例因子相同。 我们分别在 PostgreSQL 和 SmallBank 上执行 TPC-C 和 SmallBank 工作负载。 在图 7(a)、8(a)、9(a) 和 10(a) 中,我们展示了真实工作负载和合成工作负载的执行吞吐量。 从结果中我们可以看出,这两个工作负载的吞吐量非常相似,其中最大偏差低至图9(a)中的9.44%。
对于平均延迟和95%延迟,图7(b)、8(b)、9(b)和10(b)中的合成工作负载与实际工作负载非常接近,图7(b)中的最大偏差仅为8.99%。在图7©-7(d)、8©-8(d)、9©-9(d)和10©-10(d)中,我们报告了这两种工作负载的CPU和磁盘使用情况。结果表明,在PostgreSQL和MySQL数据库上执行合成工作负载和实际工作负载的资源消耗是一致的,这进一步验证了Lauca生成的合成工作负载的高保真度。
B. 探索事务逻辑
模拟应用程序工作负载的事务逻辑是Lauca的一个重要特性。在本节中,我们将演示事务逻辑对事务语义、事务冲突强度、死锁可能性和合成工作负载的分布式事务比率的影响。本节中的所有实验均在 MySQL 数据库上运行,工作负载取自 TPC-C 基准测试。比例因子和请求并发数均为20。虽然事务逻辑由结构信息和参数依赖信息组成,但其中结构信息(例如循环执行次数)对性能的影响比较明显,因此这里主要探讨参数依赖信息对数据库性能的影响。

使用包括所有五种事务类型的 TPC-C 工作负载,我们研究事务逻辑如何影响合成工作负载的事务语义。图 11 显示了 OLTP-Bench 和 Lauca 分别生成的真实工作负载和合成工作负载的吞吐量。transaction吞吐量分为两部分:成功吞吐量和失败吞吐量。成功吞吐量是指成功执行事务的吞吐量,失败吞吐量是指失败事务的吞吐量。在图11中,当我们使用事务逻辑中的所有信息(All-On)时,Lauca呈现出与真实工作负载非常相似的性能;当我们关闭参数依赖信息(Dep-Off)时,事务失败急剧增加,成功吞吐量远小于OLTP-Bench。这是因为NewOrder事务中的插入操作不满足主/外约束,导致大量事务回滚。并且由于没有产生新的订单,Delivery transaction也无法成功执行。总体而言,事务逻辑可以有效确保合成工作负载的事务语义与真实工作负载一致。
为了进一步探讨事务逻辑对其他方面的影响,在图12中,我们只保留了TPC-C工作负载中能够成功执行的三类事务,即Payment、OrderStatus、StockLevel。我们在图 12 中展示了 OLTP-Bench 和 Lauca 生成的工作负载的事务吞吐量、延迟和死锁吞吐量。Lauca 有五组实验结果,它们是通过关闭事务逻辑的不同部分获得的。请注意,这里的延迟是成功执行事务的平均延迟,不包括失败的事务。从结果中我们可以看到,当我们关闭等参数依赖(Equ-Off)时,吞吐量明显下降,延迟明显增加,并且出现大量死锁。延迟增加表明锁等待时间更多,事务冲突更密集。出现这些现象是因为支付transaction中存在三对涉及同一条记录的读写操作。当我们关闭等参数依赖时,对同一条记录的读写操作很可能会变成在不同的记录上,这大大增加了事务冲突和死锁的可能性,特别是当这些记录位于小表中时。当我们关闭参数之间的依赖关系(Bet-Off)时,延迟会急剧增加,并且吞吐量非常低。这是因为StockLevel transaction中的扫描操作会涉及大量数据,通常只需要访问20条左右的记录。当我们同时关闭 equal 和 Between 依赖时,由于 C-Dist 的作用,扫描操作不会读取大量数据,因此 Dep-Off、Equ&Bet-Off 和 EquOff 的性能指标类似。总体而言,结果证实,操纵事务逻辑可以使合成工作负载具有与真实工作负载相同的事务冲突强度、死锁可能性和扫描数据量。
分布式事务比例对数据库性能有显着影响[7]、[12]、[13]。为了准确获得评估工作负载的分布式事务比率,我们假设数据在五个节点上按仓库ID进行哈希分区,并从应用站点统计工作负载的分布式事务比率。图 19 显示了 OLTP-Bench 和 Lauca 生成的工作负载的分布式事务比率。由于 OrderStatus 和 StockLevel 是只读事务,因此图 19 中使用的工作负载仅是 Payment 事务。从结果可以看出,当我们关闭参数依赖信息(DepOff)时,分发transaction比例急剧增加。这是因为此时Payment transaction中四次写操作的Warehouse ID参数是随机生成的,因此很有可能成为分布式事务。总体而言,事务逻辑的控制可以保证在分布式环境中合成工作负载和真实工作负载具有相同的分布式事务比例。
C. 探索数据访问分布
本节演示了所提出的数据访问分布(即 S-Dist、D-Dist 和 C-Dist)描述数据访问的偏度、动态和连续性的能力。由于现有基准工作负载的数据访问分布通常既不是动态的也不是连续的,因此我们基于 YCSB 构建评估工作负载。本节所有实验均在MySQL数据库上进行,测试表来自YCSB。测试表大小为106,数据库请求并发数为20。

图 14 中的评估工作负载只有一种类型的事务。该事务由五对读写操作组成,每对读写操作先读取一条记录,然后更新它。扩展YCSB工作负载运行时间为90秒,分为三个阶段,每个阶段的数据请求在随机选择的103条记录内。第一阶段,数据访问分布为参数s=1的Zipf分布;第二阶段仍然是Zipf分布,但参数s = 1.2;第三阶段是均匀分布。图14(a)-14©分别显示了YCSB和Lauca生成的工作负载的事务吞吐量、延迟和死锁吞吐量的动态变化。Lauca有两组结果,分别对应S-Dist和DDist。从结果可以看出,使用D-Dist时,Lauca生成的合成工作负载与YCSB生成的真实工作负载在吞吐量、延迟和死锁上动态一致,表明D-Dist可以很好地刻画工作负载的动态。同时D-Dist在每个时间窗口都用S-Dist来表示,这也说明S-Dist可以很好地刻画工作负载的偏度。但全局S-Dist效果不佳(图14中的灰线),它是针对整个工作负载时间定义的,没有考虑工作负载的动态变化。

图 15 中的评估工作负载是 YCSB 的单行更新事务,运行 100 秒,时间窗口为 1 秒。每个时间窗口内的数据请求基于103条随机记录,每个时间窗口选择的记录与前一个窗口有50%的重合度。MySQL的Innodb缓冲池大小设置为16MB。图 15 显示了 YCSB 和 Lauca 生成的工作负载的吞吐量和 Innodb 缓冲池读取增量。Innodb buffer pool reads是InnoDB无法从缓冲池满足的逻辑读取次数,而必须直接从磁盘读取。从结果可以看出,D-Dist的磁盘访问量明显高于YCSB,但吞吐量较低。这是因为D-Dist无法捕捉数据访问分布的连续性,导致每个时间窗口的数据请求几乎完全不同,缓存命中率较低。CDist的性能与YCSB一致,这表明C-Dist可以很好地表征数据访问的连续性。
D. 工作负载的分布式特征

在图 17 中,我们通过比较 OLTP-Bench 和 Lauca 在分布式数据库 TiDB 上的性能,展示了 TPC-C 和 SmallBank 上的性能偏差。对于不同的 SF,TPC-C 和 Smallbank 上 T P S 的偏差小于 5%,Latency 的偏差小于 7%。
我们在 TPCC 上呈现资源消耗的偏差,并在 TiDB 上统计分布式事务消耗的网络。CPU、磁盘和网络的资源消耗偏差均小于 4%,如图 18 所示。分布式事务比率已被证明对分布式数据库性能有显着影响[?]、[?]、[?]。我们通过在三个 TiKV 节点上运行 TPC-C 工作负载来检查 TiDB 上的分布式事务比率,其中数据根据仓库 ID 进行哈希分区。如果一笔交易中的数据涉及多个节点,则该transaction被视为分布式事务。图19分别统计了OLTP-Bench和Lauca生成的应用侧工作负载的分布式事务。由于 OrderStatus 和 StockLevel 事务是只读事务,因此图 19 中使用的工作负载仅为 Payment 事务。TiDB 上的所有事务都是分布式的,跨节点=1(非分布式)的偏差为 0%。对比OLTP-Bench和Lauca的结果,跨两个节点和三个节点的分布式事务比例偏差分别仅为6%和2.9%。总体而言,事务逻辑的控制可以有效保证合成工作负载与真实工作负载之间的网络消耗和分布式事务比率的相似性。
E. 暴露数据库中的微操作

我们通过图 16 中的 CPU 上和 CPU 外火焰图来研究 DB 性能,以显示基于复杂的 TPC-C 工作负载的 MySQL 代码路径的 CPU 周期消耗,每个矩形代表一个堆栈帧。堆栈配置文件总体沿 x 轴对齐,按字母顺序排序,堆栈深度沿 y 轴对齐,表示自下而上的调用结构。CPU上火焰图或CPU外火焰图中火焰的宽度代表其入栈的占用频率。
On-CPU 图表显示线程在 CPU 上运行的时间,off-CPU 图表显示线程等待 CPU 的时间,这可能会被 I/O、锁、计时器等阻塞。CPU 上和 CPU 外火焰图的合并是 MySQL 代码路径在 CPU 上执行的线程的完整状态。
通过比较图16(a)和16©中来自OLTP-Bench的真实工作负载的火焰图与图16(b)和16(d)中Lauca生成的工作负载的火焰图,我们发现真实工作负载与生成的工作负载之间的火焰图相似,对执行轨迹采样20秒。微观执行状态证实了Lauca具有完善的仿真能力。
F.劳卡的表现
在本节中,我们使用 TPC-C 工作负载跟踪来研究 Lauca 中组件的性能。

图20展示了不同K/N大小下事务逻辑提取的执行时间和内存消耗。从结果可以看出,当K和N均为10000时,事务逻辑的提取时间仅为2.1秒,内存消耗为1.1GB。随着K和N的增加,执行时间和内存消耗几乎呈线性增加。第VIII-A节中的实验都是在K和N设置为104时进行的,并且已经证明了生成的工作负载的高保真度。总体而言,Lauca 中的事务逻辑提取非常高效,可以在几秒钟内完成,同时保证合成工作负载的保真度。
图 21 显示了不同时间长度的工作负载跟踪的 C-Dist 提取的执行时间和内存消耗。从结果中我们可以看出,在内存消耗恒定的情况下,C-Dist 的提取时间与工作负载轨迹量呈线性关系。这是因为CDist是基于窗口的数据访问分布,每个时间窗口的工作负载痕迹在处理后可以从内存中移除。在图 21 中,对于时间长度为 10000 秒的 TPC-C 工作负载跟踪(事务吞吐量为 3610.3,日志量为 33.8 GB),C-Dist 的提取时间为 678.7 秒,内存消耗为 1.2 GB。由于实际评估中的最大工作负载周期一般为一天,结果表明Lauca可以有效支持高吞吐量工作负载的性能评估。
G. 展示数据保护
Lauca已被证明具有完美的仿真能力,如图7-10所示,性能偏差小于10%。为了进一步覆盖敏感信息,我们有额外的源数据保护方法,包括插入噪声数据、匿名化和模糊域大小。这里我们以Lauca为基准,与那些额外的保护方法相结合。在图 22 中,我们显示了它们在吞吐量、延迟、CPU 和磁盘 I/O 方面的性能波动比,通过将 SF 从 10 更改为 100 来比较它们在 TPC-C 工作负载上的模拟能力。

我们为表多插入 10% 的整数类型列以覆盖表结构,即 Column + 10%; 我们对表/列名称进行匿名化以隐藏语义,即匿名化;我们将域大小随机扩展8%-12%以屏蔽域信息,即Fuzzy。对于吞吐量而言,数据保护导致与 Lauca 最多 4.05% 的性能偏差,由 Column + 10% 产生;对于延迟,最严重的偏差为7.42%,仍然是Column+10%造成的;对于CPU和磁盘I/O,其与Lauca的性能偏差不超过4%。在这三种方法中,插入新列(噪声数据)对我们的模拟结果影响更大,因为它可能需要访问额外的更多数据。但是我们可以在表中插入较小的 bool 或 char 类型列而不是整数类型列,这样可以减少噪声数据的访问量。尽管所有方法都可能对模拟结果产生负面影响,但如果需要严格的数据保护,与Lauca的偏差限制在8%以内。
IX. RELATED WORK
不同应用领域有多种数据库性能评估基准。对于 OLAP 应用程序,TPC-H、TPC-DS 和 SSB [14] 是常用的基准,具有定义的标准数据库模式和测试查询。评估数据库系统事务处理能力的基准有TPC-C、TPC-E和SmallBank[10]。此外,CH-benCHmark[15]和HTAPBench[16]可以为混合事务/分析处理(HTAP)系统提供统一的评估。此外,YCSB[11]通常用于测量云服务系统的吞吐量,其工作负载简单但需要高可扩展性。然而,这些标准基准测试的评估工作负载是对一类应用程序的抽象,因此它们过于笼统,无法评估特定应用程序的数据库性能。
为了获得目标应用程序的详细工作负载,工作负载跟踪重放是一种可选方法。Microsoft SQL Server 配备了两个工具,即 SQL Server Profiler [17] 和 SQL Server Distributed Replay [2],用于根据 SQL 跟踪重现生产工作负载。Oracle 数据库重放 [3]、[18] 使用户能够在对性能影响最小的情况下记录生产系统上的工作负载跟踪,然后重放具有与实际工作负载相同的并发性和工作负载特征的完整生产工作负载。由于数据隐私问题,工作负载重放很难应用于实际的数据库性能评估,因为它需要真实的数据库状态和原始工作负载跟踪[3]。此外,工作负载扩展(例如扩展并发)也是当前重放技术难以解决的问题。
那么工作负载模拟是必要且紧迫的。有工作负载感知数据和查询生成器 [4]、[5]、[19]、[20] 用于 OLAP 应用程序的数据库性能评估。这些工作的输入通常包括数据库模式、基本数据特征和查询树中间结果的大小规范。输出是合成数据库实例和实例化测试查询,符合指定的数据和工作负载特征。对于 OLAP 应用程序,有数据库扩展工作 [21]、[22],它们可以扩展/缩小给定的数据库实例,支持特定于应用程序的数据库基准测试。工作负载分析器[23]、[24]旨在研究和更好地理解应用程序工作负载,但两者都不能生成合成工作负载。
有用于数据库性能基准测试的工作负载生成器 [25]、[28]。[25]提出了一种工作负载生成器,用于模拟现实的硬件资源消耗状态。NoWog [28] 引入了一种工作负载描述语言,用于生成对 NoSQL 数据库进行基准测试的合成工作负载。这些工作[25]、[28]都不能用来模拟实际OLTP应用的各种工作负载,以进行面向应用的数据库性能评估。
X. CONCLUSION
在本文中,我们提出了 Lauca,一种用于面向应用程序的数据库性能评估的事务工作负载生成器。Lauca使用事务逻辑来描述目标应用程序潜在的业务逻辑,并使用数据访问分布来表征访问的偏度、动态性和连续性。我们对各种工作负载和流行数据库的结果表明,Lauca 始终如一地生成高质量的合成工作负载。未来的工作重点是改进事务逻辑的定义并提出新型数据访问分布以覆盖更多应用程序工作负载。
REFERENCES
[1] M. I. Seltzer, D. Krinsky, K. A. Smith, and X. Zhang, “The case for application-specific benchmarking,” in HotOS, 1999, pp. 102–109.
[2] SQL Server Distributed Replay, https://docs.microsoft.com/en-us/sql/tools/distributed-replay/sql-server-distributed-replay?view=sql-server-2017.
[3] L. Galanis, S. Buranawatanachoke, R. Colle, B. Dageville, K. Dias,J. Klein, S. Papadomanolakis, L. L. Tan, V. Venkataramani, Y. Wang,et al., “Oracle database replay,” in SIGMOD, 2008, pp. 1159–1170.
[4] E. Lo, N. Cheng, W. W. K. Lin, W. Hon, and B. Choi, “Mybenchmark:generating databases for query workloads,” in VLDBJ, 2014, pp. 895–913.
[5] Y. Li, R. Zhang, X. Yang, Z. Zhang, and A. Zhou, “Touchstone:Generating enormous query-aware test databases,” in USENIX ATC,2018, pp. 575–586.
[6] A. J. Bonner and M. Kifer, “A logic for programming database trans-actions,” in Logics for Databases and Information Systems, 1998, pp.117–166.
[7] Q. Lin, P. Chang, G. Chen, B. C. Ooi, K. Tan, and Z. Wang, “Towards a non-2pc transaction management in distributed database systems,” in SIGMOD, 2006, pp. 1659–1674.
[8] D. E. Difallah, A. Pavlo, C. Curino, and P. Cudre-Mauroux, “Oltp-bench: An extensible testbed for benchmarking relational databases,” in PVLDB, 2013, pp. 277–288.
[9] TPC-C benchmark, http://www.tpc.org/tpcc/.
[10] M. Alomari, M. Cahill, A. Fekete, and U. Rohm, “The cost of serial-izability on platforms that use snapshot isolation,” in ICDE, 2008, pp.576–585.
[11] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears,“Benchmarking cloud serving systems with ycsb,” in SoCC, 2010, pp.143–154.
[12] R. Harding, D. Van Aken, A. Pavlo, and M. Stonebraker, “An evaluation of distributed concurrency control,” in PVLDB, 2017, pp. 553–564.
[13] C. Curino, E. Jones, Y. Zhang, and S. Madden, “Schism: a workload-driven approach to database replication and partitioning,” in PVLDB,2010, pp. 48–57.
[14] P. E. O’Neil, E. J. O’Neil, X. Chen, and S. Revilak, “The star schema benchmark and augmented fact table indexing,” in TPCTC, 2009, pp.237–252.
[15] R. Cole, F. Funke, L. Giakoumakis, W. Guy, A. Kemper, S. Krompass,H. Kuno, R. Nambiar, T. Neumann, M. Poess, et al., “The mixed workload ch-benchmark,” in DBTest, 2011, pp. 8.
[16] F. Coelho, J. Paulo, R. Vilac¸a, J. Pereira, and R. Oliveira, “Htapbench: Hybrid transactional and analytical processing benchmark,” in ICPE, 2017, pp. 293–304.
[17] SQL Server Profiler, https://docs.microsoft.com/en-us/sql/tools/sql-server-profiler/sql-server-profiler?view=sql-server-2017.
[18] Y. Wang, S. Buranawatanachoke, R. Colle, K. Dias, L. Galanis, S. Papadomanolakis, and U. Shaft, “Real application testing with database replay,” in DBTest, 2009, pp. 8.
[19] C. Binnig, D. Kossmann, E. Lo, and M. T. ¨Ozsu, “Qagen: generating query-aware test databases,” in SIGMOD, 2007, pp. 341–352.
[20] A. Arasu, R. Kaushik, and J. Li, “Data generation using declarative constraints,” in SIGMOD, 2011, pp. 685–696.
[21] Y. Tay, B. T. Dai, D. T. Wang, E. Y. Sun, Y. Lin, and Y. Lin, “Upsizer: Synthetically scaling an empirical relational database,” in Information Systems, 2013, pp. 1168–1183.
[22] J. Zhang and Y. Tay, “Dscaler: Synthetically scaling a given relational database,” in PVLDB, 2016, pp. 1671–1682.
[23] P. S. Yu, M.-S. Chen, H.-U. Heiss, and S. Lee, “On workload characterization of relational database environments,” in IEEE Transactions on Software Engineering, 1992, pp. 347–355.
[24] Q. T. Tran, K. Morfonios, and N. Polyzotis, “Oracle workload intelligence,” in SIGMOD, 2015, pp. 1669–1681.
[25] H. J. Jeong and S. H. Lee, “A workload generator for database system benchmarks,” in iiWAS, 2005, pp. 813–822.
[26] H. Garcia-Molina, J. Ullman, J. Widom, “Database system implementation,” 2005, pp. 672.
[27] S. Harizopoulos, D. Abadi, S. Madden, M. Stonebraker “OLTP through the looking glass, and what we found there,” 2018, pp. 409–439.
[28] P. Ameri, N. Schlitter, J. Meyer, and A. Streit, “Nowog: a workload generator for database performance benchmarking,” in DASC/PiCom/DataCom/CyberSciTech, 2016, pp. 666–673.