五分钟上手爬虫:五分钟入门beautifulsoup
一、简介
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度
beautifulsoup相比于用正则表达式简单太多,兼容性更强,操作难度更低
二、掌握重要的功能
1.beautifulsoup解析器解析页面
# 使用自带的html.parser解析页面响应结果
soup = BeautifulSoup(html_doc, 'html.parser')
# 使用lxml HTML解析器解析页面响应结果
soup = BeautifulSoup(html_doc, 'lxml')
# 使用lxml XML解析器解析页面响应结果
soup = BeautifulSoup(html_doc, 'xml')
# 使用html5lib解析页面响应结果
soup = BeautifulSoup(html_doc, 'html5lib')
| 解析器 | 使用方法 | 优势 | 劣势 |
| Python标准库 | BeautifulSoup(markup, ‘html.parser’) | python内置的标准库,执行速度适中 | Python3.2.2之前的版本容错能力差 |
| lxml HTML解析器 | BeautifulSoup(markup, ‘lxml’) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(markup ‘xml’) | 速度快,唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, ‘html5lib’) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢,不依赖外部拓展 |
2.搜索文档树
最重要的一步还是如何定位到自己想要的那部分资源然后进行获取
find(name, attrs, recursive, string, **kwargs):获取匹配的第一个标签;find_all(name, attrs, recursive, string, limit, **kwargs) :返回结果是值包含一个元素的列表;
name:是根据标签的名称进行匹配,name的值相当于过滤条件,可以是一个具体的标签名,多个标签名组成的列表,或者是一个正在表达式,甚至是函数方法等等。attrs:是根据标签的属性进行匹配。recursive:是否递归搜索,默认为True,会搜索当前tag的所有子孙节点,设置为False,则只搜索儿子节点。string:是根据标签的文本内容去匹配。limit:设置查询的结果数量。kwargs:也是根据标签的属性进行匹配,与attrs的区别在于写法不一样,且属性的key不能是保留字,也不能与其他参数名相同。
name属性详解:
# 查找所有的标签
soup.find_all(name="p") # 可以简写成 soup.find_all("p")
# 查找所有的标签或者标签
soup.find_all(name={'a', 'link'}) # 可以简写成 soup.find_all(['a', 'link'])
# 查找所有以t开头的标签
soup.find_all(name=re.compile("^t")) # 可以简写成 soup.find_all(re.compile("^t")),例如td,tr
attrs属性详解:
# 查找所有style属性值的标签
soup.find_all(attrs={"style": "padding: 8px; border: 1px solid rgb(221, 221, 221); text-align: left; font-size: 12px; font-weight: bold; border-colng:8px 8px 8px 8px;"})
# 查找所有id属性值为id_attr1或者id_attr2的标签
soup.find_all(attrs={'id': ['id_attr1', 'id_attr2']})
# 查找id属性值中含有id_的所有标签
soup.find_all(attrs={'id':re.compiles('id_')})这里一般是提取较为重要的点,可以通过尝试找到共同的属性值然后筛选出目标内容
strings属性详解:
# 查找标签的value是'提交'的所有标签集合
#需要注意的是这里返回标签的值,如果需要获取到对应的标签,可以使用previous_element属性来获得
soup.find_all(string='提交')
# 查找标签的value是'提交'的所有标签
[value.previous_element for value in soup.find_all(string='提交')]
# 查找value是'上一页'或者'下一页'的所有value值
soup.find_all(string=['上一页','下一页'])
# 查找value中存在'页'的所有value值
soup.find_all(string=re.compile('页'))三、基本操作演示
1.beautifulsoup的安装
pip install beautifulsoup42. 理解基本爬虫所需的网页资源
URL,Cookie和User-Agent
URL 代表着是统一资源定位符,其实就是网页的网址
Cookie通常用于存储和识别用户的会话信息,以实现跟踪和个性化功能,相当于你电脑网页的身份证
User-Agent其实就是你的浏览器信息。是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识
获取方式:网页端f12进入网页检查
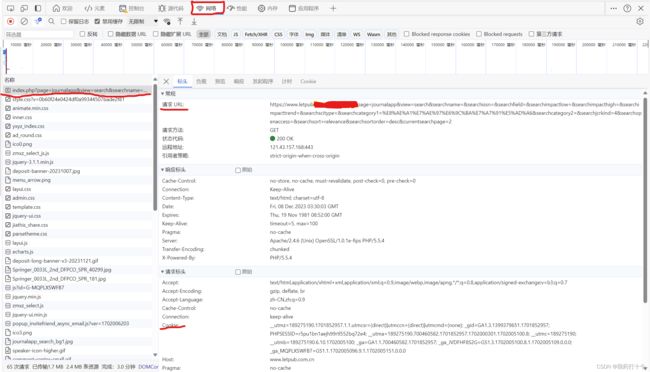

3.导入所需要的库
import requests
from bs4 import BeautifulSoup4. 填入所找到的网页资源
header={#填空
'User-Agent': '',
'Cookie' : ''
}
url = ''#填空5.连接网页并解析
response = requests.get(url=url, headers=header)
soup = BeautifulSoup(response.text, 'html.parser')6.根据html的标签内容进行筛选
可以获取标签上的元素,例如herf,也可以获取标签内的文本元素,例如
元素
element_tags = soup.find_all()#填空
#single_tags = single_soup.find_all('td', style="padding: 8px; border: 1px solid rgb(221, 221, 221); text-align: left; font-size: 12px; font-weight: bold; border-colng:8px 8px 8px 8px;")
out = [element[] for element in element_tags]#[]里面进行填空,是用来获取结果上的指定元素,例如 里面的href
out = [element.text for element in element_tags]#用来获取结果上的文本,例如小羊肖恩里面的小羊肖恩
里面的href
out = [element.text for element in element_tags]#用来获取结果上的文本,例如小羊肖恩里面的小羊肖恩
四、完整代码展示
爬取可分为一级爬取和多级爬取,一级爬取则是只爬取当前页面的内容,多级爬取是爬取当前页面下的多个链接下另一个网页的内容(一般是带有页码数)
一级爬取:
import requests
from bs4 import BeautifulSoup
header={#填空
'User-Agent': '',
'Cookie' : ''
}
url = ''#填空
if __name__ in '__main__':
response = requests.get(url=url, headers=header)
soup = BeautifulSoup(response.text, 'html.parser')
element_tags = soup.find_all()#填空
out = [element[] for element in element_tags]#[]里面进行填空,是用来获取结果上的指定元素,例如里面的href
out = [element.text for element in element_tags]#用来获取结果上的文本,例如小羊肖恩里面的小羊肖恩
多级爬取:
import requests
from bs4 import BeautifulSoup
header={
'User-Agent': '',
'Cookie' : ''
}
for page in range(1,2):
print(page)
url = ''+ str(page) +''#多级爬取一般有页数,可以通过找到管理page的那个选项进行遍历
response = requests.get(url=url, headers=header)
soup = BeautifulSoup(response.text, 'html.parser')
a_tags = soup.find_all()#soup.find_all('a', style='color:#0099FF; font-size:12px; font-weight:bold; text-decoration:underline;')
hrefs = [a['href'] for a in a_tags]
# Print the extracted hrefs
for href in hrefs:
single_href = ''#这里是对二级页面进行操作,例如'https://www.let.com.cn/' + href[1:]
single_response = requests.get(url=single_href,headers=header)
# 代码是查看当前状态码,看看是否连接成功print(single_response.status_code)
single_soup = BeautifulSoup(single_response.text, 'html.parser')
# print(single_response.text)
single_tags = single_soup.find_all()#进一步解析获取第二个页面的内容
五、常见问题
1.有可能有小伙伴输出的内容为空,原因是定位不精准,没有找到符合解析的内容
2.如果出现requests.exceptions.ChunkedEncodingError报错
则查看建议的报错解决办法解决报错:requests.exceptions.ChunkedEncodingError-CSDN博客
详细请看官方文档Beautiful Soup 文档 — Beautiful Soup 4.4.0 文档 (beautiful-soup-4.readthedocs.io)
希望这篇博文对你有所帮助!!!