Python获取去哪儿旅游数据并作可视化攻略
嗨喽,大家好呀~这里是爱看美女的茜茜呐

开发环境:
-
版 本: python 3.8
-
编辑器:pycharm
第三方库:
-
requests >>> pip install requests
-
parsel >>> pip install parsel
模块安装:
按住键盘 win + r, 输入cmd回车 打开命令行窗口, 在里面输入 pip install 模块名
更多精彩机密、教程,尽在下方,赶紧点击了解吧~
python源码、视频教程、插件安装教程、资料我都准备好了,直接在文末名片自取就可
需求分析
确定需要的数据
找数据真实来源
https://travel.qunar.com/travelbook/list.htm?order=hot_heat
静态数据
代码实现步骤
-
发送请求
-
获取数据
-
提取数据
-
保存数据
数据获取
导入模块
import requests # 发送请求 代码当中用来访问网站的模块
import parsel # 解析数据的模块
import csv
with open('攻略.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['title', 'date', 'days', 'photo_nums', 'fee', 'people', 'trip', 'view', 'love', 'comment', 'href'])
for page in range(1, 201):
url = f'https://travel.qunar.com/travelbook/list.htm?page={page}&order=hot_heat'
- 发送请求
response = requests.get(url=url)
- 获取数据
html_data = response.text
- 提取数据
# re / css / xpath
# css: ul.b_strategy_list > li
# xpath: //ul[@class="b_strategy_list "]/li
select = parsel.Selector(html_data)
lis = select.xpath('//ul[@class="b_strategy_list "]/li')
# 二次的数据提取
for li in lis:
# li.css('h2 > a::text').get()
title = li.xpath('./h2/a/text()').get()
date = li.xpath('./p[@class="user_info"]//span[@class="date"]/text()').get("")
days = li.xpath('./p[@class="user_info"]//span[@class="days"]/text()').get("")
photo_nums = li.xpath('./p[@class="user_info"]//span[@class="photo_nums"]/text()').get("")
fee = li.xpath('./p[@class="user_info"]//span[@class="fee"]/text()').get("")
people = li.xpath('./p[@class="user_info"]//span[@class="people"]/text()').get("")
trip = li.xpath('./p[@class="user_info"]//span[@class="trip"]/text()').get("")
view = li.xpath('./p[@class="user_info"]//span[@class="icon_view"]/span/text()').get("")
love = li.xpath('./p[@class="user_info"]//span[@class="icon_love"]/span/text()').get("")
comment = li.xpath('./p[@class="user_info"]//span[@class="icon_comment"]/span/text()').get("")
href = li.xpath('./h2/a/@href').get()
print(title, date, days, photo_nums, fee, people, trip, view, love, comment, href)
- 保存数据
with open('攻略.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([title, date, days, photo_nums, fee, people, trip, view, love, comment, href])
数据可视化
import pandas as pd
from pyecharts.commons.utils import JsCode
from pyecharts.charts import *
from pyecharts import options as opts
data = pd.read_csv('去哪儿_数分.csv')
data
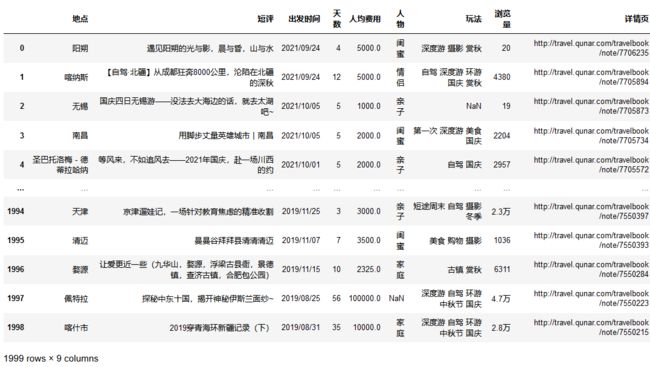
data.info()
data = data[~data['地点'].isin(['攻略'])]
data = data[~data['天数'].isin(['99+'])]
data
data.drop_duplicates(inplace=True)
data['人均费用'].fillna(0, inplace=True)
data['人物'].fillna('独自一人', inplace=True)
data['玩法'].fillna('没有', inplace=True)
data['天数'] = data['天数'].astype(int)
data = data[data['人均费用'].values>200]
data = data[data['天数']<=15]
data
data = data.reset_index(drop=True)
data
def Month(e):
m = str(e).split('/')[2]
if m=='01':
return '一月'
if m=='02':
return '二月'
if m=='03':
return '三月'
if m=='04':
return '四月'
if m=='05':
return '五月'
if m=='06':
return '六月'
if m=='07':
return '七月'
if m=='08':
return '八月'
if m=='09':
return '九月'
if m=='10':
return '十月'
if m=='11':
return '十一月'
if m=='12':
return '十二月'
data['旅行月份'] = data['出发时间'].apply(Month)
data['出发时间']=pd.to_datetime(data['出发时间'])
data
import re
def Look(e):
if '万' in e:
num1 = re.findall('(.*?)万',e)
return float(num1[0])*10000
else:
return float(e)
data['浏览次数'] = data['浏览量'].apply(Look)
data.drop(['浏览量'],axis = 1,inplace = True)
data['浏览次数'] = data['浏览次数'].astype(int)
data.head()
data1 = data
data1['地点'].value_counts().head(10)

loc = data1['地点'].value_counts().head(10).index.tolist()
print(loc)
loc_data = data1[data1['地点'].isin(loc)]
price_mean = round(loc_data['人均费用'].groupby(loc_data['地点']).mean(),1)
print(price_mean)
price_mean2 = [1630.1,1862.9,1697.9,1743.4,1482.4,1586.4,1897.0,1267.5,1973.8,1723.7]

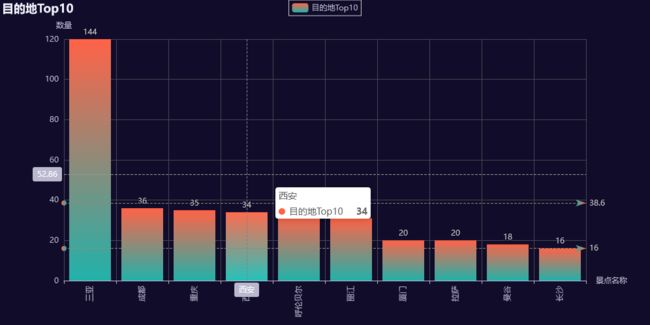
旅游胜地Top10及对应费用
m2 = data1['地点'].value_counts().head(10).index.tolist()
n2 = data1['地点'].value_counts().head(10).values.tolist()
bar=(
Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark'))
.add_xaxis(m2)
.add_yaxis(
'目的地Top10',
n2,
label_opts=opts.LabelOpts(is_show=True,position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='目的地Top10'),
xaxis_opts=opts.AxisOpts(name='景点名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90),
),
yaxis_opts=opts.AxisOpts(
name='数量',
min_=0,
max_=120.0,
splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average',name='均值'),
opts.MarkLineItem(type_='max',name='最大值'),
opts.MarkLineItem(type_='min',name='最小值'),
]
)
)
)
bar.render('1.html')
bar=(
Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark'))
.add_xaxis(loc)
.add_yaxis(
'人均费用',
price_mean2,
label_opts=opts.LabelOpts(is_show=True,position='top'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(
0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])
"""
)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='各景点人均费用'),
xaxis_opts=opts.AxisOpts(name='景点名称',
type_='category',
axislabel_opts=opts.LabelOpts(rotate=90),
),
yaxis_opts=opts.AxisOpts(
name='数量',
min_=0,
max_=2000.0,
splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))
),
tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')
)
.set_series_opts(
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='average',name='均值'),
opts.MarkLineItem(type_='max',name='最大值'),
opts.MarkLineItem(type_='min',name='最小值'),
]
)
)
)
bar.render('2.html')

data1['天数'].value_counts()
data1['旅行时长'] = data1['天数'].apply(lambda x:str(x) + '天')
data1
data1['人物'].value_counts()
m = data1['浏览次数'].sort_values(ascending=False).index[:].tolist()
data1 = data1.loc[m]
data1 = data1.reset_index(drop = True)
data1
data1['旅行月份'].value_counts()
word_list = []
for i in data1['玩法']:
s = re.split('\xa0',i)
word_list.append(s)
dict = {}
for j in range(len(word_list)):
for i in word_list[j]:
if i not in dict:
dict[i] = 1
else:
dict[i]+=1
#print(dict)
list = []
for item in dict.items():
list.append(item)
for i in range(1,len(list)):
for j in range(0,len(list)-1):
if list[j][1]<list[j+1][1]:
list[j],list[j+1] = list[j+1],list[j]
print(list)
data1['旅行月份'].value_counts()
m1 = data1['人物'].value_counts().index.tolist()
n1 = data1['人物'].value_counts().values.tolist()
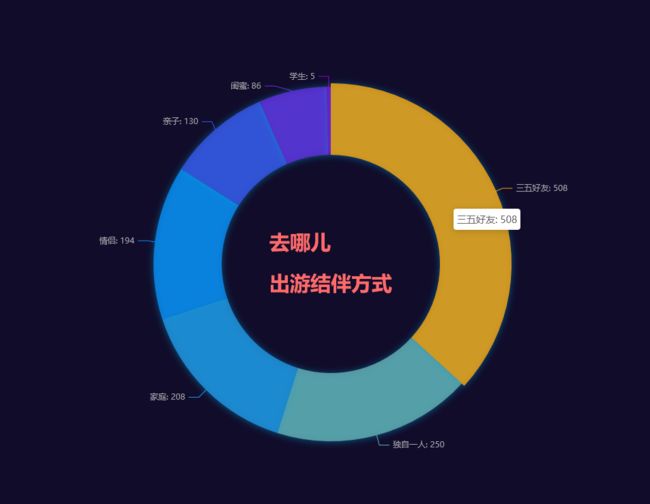
出游方式分析
pie = (Pie(init_opts=opts.InitOpts(theme='dark', width='1000px', height='800px'))
.add("", [z for z in zip(m1,n1)],
radius=["40%", "65%"])
.set_global_opts(title_opts=opts.TitleOpts(title="去哪儿\n\n出游结伴方式", pos_left='center', pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='#FF6A6A', font_size=30, font_weight='bold'),
),
visualmap_opts=opts.VisualMapOpts(is_show=False,
min_=38,
max_=641,
is_piecewise=False,
dimension=0,
range_color=['#9400D3', '#008afb', '#ffec4a', '#FFA500','#ce5777']),
legend_opts=opts.LegendOpts(is_show=False, pos_top='5%'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}", font_size=12),
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b}: {c}"),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(0,191,255,0.5)',
'shadowOffsetY': 1,
'opacity': 0.8
}
})
)
pie.render('3.html')
m3 = data1['出发时间'].value_counts().sort_index()[:]
m4 = m3['2021'].index
n4 = m3['2021'].values
m3['2021'].sort_values().tail(10)
出游时间分析
line = (
Line()
.add_xaxis(m4.tolist())
.add_yaxis('',n4.tolist())
)
line.render('4.html')

2021年的旅游时间曲线大约在五月一号起伏最大,原因肯定是因为假期调休延长至4天,为了调整自己生活及工作的状态,很多人利用这个假期去旅行放松自己。
出游玩法分析
m5 = []
n5 = []
for i in range(20):
m5.append(list[i][0])
n5.append(list[i][1])
m5.reverse()
m6 = m5
n5.reverse()
n6 = n5
bar = (
Bar(init_opts=opts.InitOpts(theme='dark', width='1000px',height ='500px'))
.add_xaxis(m6)
.add_yaxis('', n6)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='insideRight',
font_style='italic'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(1, 0, 0, 0,
[{
offset: 0,
color: 'rgb(255,99,71)'
}, {
offset: 1,
color: 'rgb(32,178,170)'
}])"""))
)
.set_global_opts(
title_opts=opts.TitleOpts(title="出游玩法分析"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
legend_opts=opts.LegendOpts(is_show=True))
.reversal_axis()
)
bar.render('5.html')
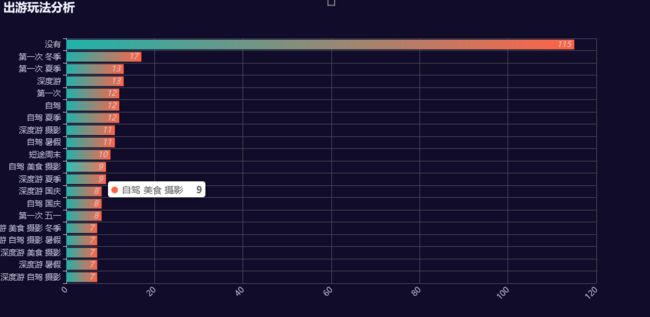
“摄影”和“美食”可谓与旅行息息相关,一次完整的旅行最不能缺的就是“摄影”,拍美食发到朋友圈、拍风景发到朋友圈、拍完美的自己发到朋友圈;
工作之后就没有了寒暑假,所以利用周末来一次短途旅行就成为了大多数人的首选。
m7 = data1['旅行时长'].value_counts().index.tolist()
n7 = data1['旅行时长'].value_counts().values.tolist()
data_day = data1['旅行时长'].value_counts().sort_values()
出游天数分析
bar = (
Bar(init_opts=opts.InitOpts(theme='dark', width='1000px',height ='500px'))
.add_xaxis(data_day.index.tolist())
.add_yaxis('',data_day.values.tolist())
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='insideRight',
font_style='italic'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(1, 0, 0, 0,
[{
offset: 0,
color: 'rgb(255,99,71)'
}, {
offset: 1,
color: 'rgb(32,178,170)'
}])"""))
)
.set_global_opts(
title_opts=opts.TitleOpts(title="旅行时长"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
legend_opts=opts.LegendOpts(is_show=True))
.reversal_axis()
)
bar.render('6.html')
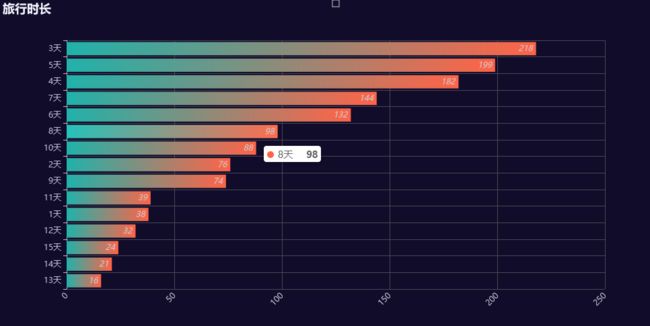
旅行时长主要分布在2-5天之间,3天最为普遍,太短会未尽兴致,太长又会花销太大,若有一份好的旅行计划,3天应该足够让你赏过一座城市的名胜,吃过大部分的特色美食,领略到这个城市的风情,也足够让你喜欢上这座城市。
data_mo = data1[((data1['旅行月份'] =='七月')|(data1['旅行月份'] =='八月'))&(data1['人物']=='三五好友')].drop(['旅行时长'],axis = 1)
data_mo.head(10)
data_mo2 = data1[((data1['人物'] =='情侣')|(data1['人物'] =='独自一人'))&(data1['旅行月份']=='十月')].drop(['旅行时长'],axis = 1)
data_mo2.head(10)
import jieba
import jieba.analyse
import re
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}【】'
def remove_fuhao(e):
short = re.sub(r"[%s]+" % punc, " ", e)
return short
def cut_word(text):
text = jieba.cut_for_search(str(text))
return ' '.join(text)
data2 = data1
data2['简介'] = data2['短评'].apply(remove_fuhao).apply(cut_word)
data2.head()
word = data2['简介'].values.tolist()
fb = open(r'.\travel_text.txt','w',encoding='utf-8')
for i in range(len(word)):
fb.write(word[i])
with open(r'.\travel_text.txt','r',encoding='utf-8')as f:
words = f.read()
f.close
jieba.analyse.set_stop_words(r'./stopwords.txt')
new_words = jieba.analyse.textrank(words, topK=30, withWeight=True)
print(new_words)
word1 = []
num1 = []
for i in range(len(new_words)):
word1.append(new_words[i][0])
num1.append(new_words[i][1])
短评词云分析
wordcloud= (
WordCloud()
.add('简介词云分析',[z for z in zip(word1,num1)],word_size_range=[25,80],shape = 'diamond')
)
wordcloud.render('7.html')

食”、“成都”、“自驾”是权重最高的三个词,事实确实如此,当我们计划到一个陌生城市游玩时,可能脑海里第一个想到的并不是当地有什么风景可看,而是有什么美食可吃,大概每个人都能算得上一个吃货吧;
自驾游也是当下火热的出游方式,随时都可以来一场说走就走的旅行。
data4 = data1.drop(['旅行时长','简介'],axis = 1)
data4
旅游景点推荐
k_list = []
the_list = []
keyword = input('请输入旅行月份:')
data5 = data4[data4['旅行月份'] == str(keyword)]
keyword1 = input('请输入结伴出游方式:')
data6 = data5[data5['人物'] == str(keyword1)]
price = int(input('请输入预期价格上限:'))
data7 = data6[data6['人均费用']<=price]
day1 = int(input('请输入旅行时长下限:'))
day2 = int(input('请输入旅行时长上限:'))
data8 = data7[(data7['天数']>=day1)&(data7['天数']<=day2)]
data8
综上述分析可得到一些结论:
-
个人认为性价比较高的旅游城市:三亚、成都。
-
旅游天数大多控制在2-5天内,不宜过多。
-
三五好友一起旅游是最令人们喜欢的出游方式。
-
“摄影”与“美食”已成为旅游的代名词。
-
避开旅游高峰期,三月和六月的周末短途旅行也是不错的选择。
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。

最后,宣传一下呀~更多源码、资料、素材、解答、交流皆点击下方名片获取呀