一文解决,anaconda创建虚拟环境,python模型打包,c++程序调用py文件,调用程序编写全流程。
前言
Python是一种更适用于数据分析与计算的一种语言,在软件开发方面,尤其是界面开发可能稍有欠缺,QT是一种跨平台的C++图形用户界面程序开发框架,在VS开发工具中可以集成QT,直接在VS中进行界面开发,程序编写。最近的研究同时使用到Python和C++两种语言,因此,接口互通至关重要。以下将详细介绍C++程序调用Python模型的各个流程。
注:Python模型建立主要使用的是Anaconda中的jupyter notebook模块编写(python37版本),VS使用2015版本,QT也是2015版本。
正文
由于在使用python时可能需要下载很多功能模块包,而且再使用C++调用这些模型时,并不一定需那么多的安装包,因此,在进行打包之前最好的方法就是创建一个新的虚拟环境(并且这个环境可以根据需要创建不同版本,因为python程序在每个版本间不兼容,需要重新将程序在创建好的虚拟环境里重新运行一遍,在运行时需要哪个包直接安装即可,此时虚拟环境中就会只有我们需要的安装包,大大减少了打包的内存)。接下来就是在虚拟环境中打包,编写py文件,然后使用c++程序调用等步骤,具体实现方法接下来一一介绍
01-创建虚拟环境
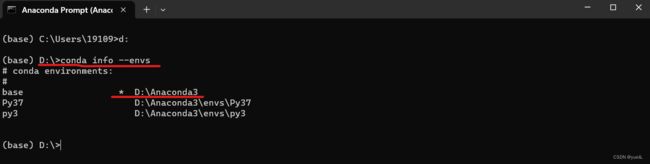
查询虚拟环境
我这里使用的是Anaconda3,python版本使用的是3.9版本,首先这里可以通过 conda inof --envs命令 查询已经安装的虚拟环境,因为我的Anaconda安装在D盘,因此习惯先切换到D盘进行查询。执行命令之后,可以得到已安装的虚拟环境,其中带*号的表示当前虚拟环境
注:下方输入命令的界面为Anaconda Prompt (安装Anaconda3之后,会有一个这样的程序)
创建虚拟环境
在命令行输入 conda create --name py3 python=3.7 命令即可,我这边将虚拟环境命名为py3,当显示创建完成之后,就可以在安装的Anaconda的envs文件下查询到已经创建的虚拟环境


切换虚拟环境
当创建之后,直接通过Anaconda Prompt程序输入Jupyter Notebook之后,在选择环境那里并没有自己创建的环境,需要进行环境激活,输入conda activate py3可以切换到所创建环境,如下图所示,可以看出当前虚拟环境已经变成py3。

接着,在当前环境下,使用 conda install ipykernel 安装程序包,然后再输入 python -m ipykernel install --name py3 命令即可完成激活。再次使用Jupyter Notebook打开时便可以选择所需的虚拟环境。
至此,完成虚拟环境创建任务。
02-Python模型导出和使用
导出模型
因为在使用C++程序调用之前,是需要先将模型建立完毕的,也就是模型已经训练好的,因此,我们没有必要在需要调用的.py文件中继续将模型训练,只需要通过下面的命令导出pkl文件即可,这就是已经训练好的模型,等需要的时候,在.py文件中导入。执行下方代码。便可得到.pkl模型文件
import joblib # 导入包
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X,y1,test_size=0.3,random_state=2023)
# 训练数据
gbdt = GradientBoostingRegressor(learning_rate=0.0409, max_depth=4, n_estimators=500, random_state=2023)
# 拟合数据
gbdt.fit(X_train,y_train)
# 导出模型pkl文件
joblib.dump(gbdt,'../pkl/Pred.pkl')使用模型
下面是模型的使用方法,由于现在的.pkl文件已经是训练好的模型,因此可以直接导入数据用于计算。方法如下方代码所示。执行代码之后,得到的y_pred就是经过训练后的YP_Pred_102.pkl模型文件的预测结果,使用非常方便。
import joblib # 导入包
# 获取文件
pkl_file = '../pkl/Pred.pkl'
# 下载模型
gbdt=joblib.load(pkl_file)
# 进行预测,其中X_pred代表待预测的数据集
y_pred= gbdt.predict(X_pred)03-建立py文件
py文件就是我们用于与C++程序连接的主要文件,它既是用于python打包的的文件,又是用于在C++程序中调用的文件。这个文件里主要包含两部分内容:
(1)、需要使用的数据包,直接导入即可(下面有程序指导)。
(2)、定义几个需要的函数,这个函数用于在C++程序中调用,并且数据处理、pkl文件导入、模型计算,都在这个函数里实现。(程序如下所示)
代码最上方代码 %%writefile hello_C++.py,可以将.ipynb文件转化为.py文件(因为在Anaconda中建立的python文件默认是.ipynb文件格式,后面打包需要使用.py文件)我们下方就是我们所需要py文件,该文件命名为hello_C++文件,导入所需要的包,然后还有建立的函数Pred(),当使用C++程序调用hello_C++文件后,再进行函数Pred()的调用,就可以将数据导入函数中,执行函数里的所有程序,得到计算结果。
#%%writefile hello_C++.py
import pandas as pd
import numpy as np
import math
#from sklearn.externals import joblib
import joblib
from joblib import load
import encodings
import codecs
import warnings
import geatpy as ea
warnings.filterwarnings("ignore", category=DeprecationWarning)
# 这里仅是一个函数,如果还需要其他模型计算,需要建立其他函数
def Pred(Paralist):
X1=Paralist[0]
X2=Paralist[1]
X3=Paralist[2]
X4 =Paralist[3]
X5 =Paralist[4]
....... # 特殊原因,近展示部分代码。过程相似
X_pred_dict = {'A':[X1],'B':[X2],'C':[X3],
'D':[X4],'E':[X5],...}
order=[ 'A','B', 'C','D', 'E',...]
X_pred=pd.DataFrame(data=X_pred_dict)
X_pred=X_pred[order]
X_pred=X_pred.apply(pd.to_numeric,axis=0)
X_pred['A'] = pd.to_numeric(X_pred['A'],errors='coerce')
X_pred['B'] = pd.to_numeric(X_pred['B'],errors='coerce')
X_pred['C'] = pd.to_numeric(X_pred['C'],errors='coerce')
X_pred['D'] = pd.to_numeric(X_pred['D'],errors='coerce')
X_pred['E'] = pd.to_numeric(X_pred['E'],errors='coerce')
......
if st_product_no== 101 :
pkl_file='./pkl/Pred.pkl'
......
else:
pkl_file='./pkl/.pkl'
gbdt=joblib.load(pkl_file)
y_pred= gbdt.predict(X_pred)
return y_pred04-py文件打包
前期准备
首先需要查看你是否已经安装支持打包的安装包pyinstaller查看方式下图所示,因为习惯于将安装包安装在D盘,先经过切换之后,再输入pyinstaller,如果和下图一样,证明已经安装程序包。否则,输入 pip install pyinstaller 进行安装即可。

文件打包
(1)、首先将前面建立的.py文件复制之后,放到前期所建立的虚拟环境中(这里就是你需要在哪个虚拟环境打包,就放在哪个虚拟环境下),如下图所示,我这里放在虚拟环境py3中,无论哪个环境,都要放在Scripts文件下。

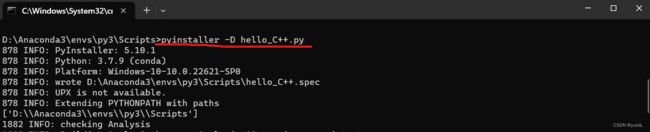
(2)、接着进行导报,打包时,首先进入刚才放入.py文件的目录下,然后点击文件框,输入cmd命令,进入dos界面,接着输入 pyinstaller -D hello_C++.py 命令,点击回车,开始打包,时间有些长。打包完成之后,会显示打包成功。如下图所示

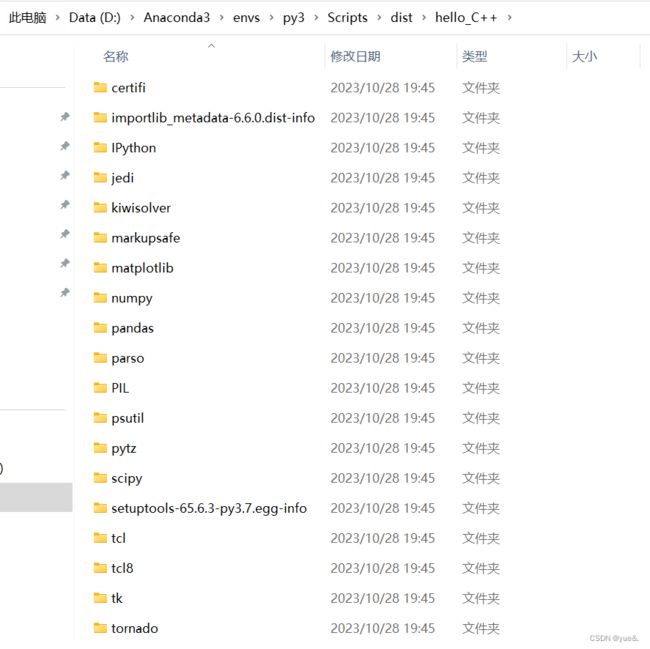
(3)、打包结束之后,可以在同级目录中看到出现dist和build两个文件夹,dist文件夹中就是所需要的打包完成文件。文件中包含了很多文件,如下图所示,其中打包后dist文件夹下默认文件名为library.zip,需要改成Python37.zip(可以先复制一份,再将其改成你自己的虚拟环境的Python版本号)。


(4)、注意:前面所有的都已经打包完成,随后,需要将前面创建的py文件放入dist文件下,才能用于后期调用
使用方法
(1)、首先将上述dist文件下的所有文件都复制下来,放入C++程序的Debug或者Release文件下,用于调试或者现场使用(主要用于没有安装Python程序的现场)。
(2)、然后,也是最重要的一点,pkl文件需要在你所需要的目录下,才能被.py文件程序调用,因此,也需要将pkl文件夹放在合适的位置。
上述步骤完成之后,剩下的就是在C++程序中进行调用py文件,调用函数等程序编写。
05-调用程序编写
路径初始化
可以在运行时选择当前路径还是现场,两者均可使用,主要用到Py_Initialize()进行初始化。
if (path_deploy == "local")
{
Py_SetPythonHome(L"d://Anaconda3//envs//py3");
}
else
{
Py_SetPythonHome((wchar_t*)(L"python37"));
}
try
{
Py_Initialize();//使用python之前,要调用Py_Initialize();这个函数进行初始化
}
catch (...)
{
system("pause");
}
if (!Py_IsInitialized())
{
sys_state = "Py_Initialize fail";
console_WFC_thread->error("Py_Initialize失败");
emit sys_state_update_link("1 Py_Initialize fail");
return 0;
}
else
{
sys_state = "Py_Initialize success";
console_WFC_thread->info("Py_Initialize()成功[HDGL_SYSTEM_Init]");
emit sys_state_update_link("0 Py_Initialize success");
}
PyRun_SimpleString("import sys");
PyRun_SimpleString("sys.path.append('./')");//这一步很重要,修改Python路径文件和函数调用
使用过程的详细代码如下所示,主要用到一些API,都是写好的,直接调用即可。
float test()
{
PyObject * pModule = NULL;// 声明变量
PyObject * pFunc = NULL;// 声明变量
pModule = PyImport_ImportModule("hello_C++");//这里是要调用的文件名
if (pModule == NULL || PyErr_Occurred())
{
PyErr_Print();
cout << "用户包导入错误" << endl;
system("pause");
}
pFunc = PyObject_GetAttrString(pModule, "Pred");//这里是要调用的函数名
PyObject* pLists = PyList_New(0);
PyObject* pArgs = PyTuple_New(1);
PyList_Append(pLists, Py_BuildValue("f", A)); // 这里传入的都是数据
PyList_Append(pLists, Py_BuildValue("f", B));
PyList_Append(pLists, Py_BuildValue("f", C));
PyList_Append(pLists, Py_BuildValue("f", D));
PyList_Append(pLists, Py_BuildValue("f", E));
......
PyTuple_SetItem(pArgs, 0, pLists);
PyObject* pRet = PyEval_CallObject(pFunc, pArgs);
float Pred ;
//获取结果
PyArg_Parse(pRet, "f", &Pred);//转换返回类型
return Pred;
}总结
花了几天时间,将每个流程都详细介绍了一遍,可能每个人遇到的情况不同,具体情况具体分析,有需要的话,可以评论区讨论。