微软官宣放出一个「小模型」,仅2.7B参数,击败Llama2和Gemini Nano 2
就在前一阵谷歌深夜炸弹直接对标 GPT-4 放出 Gemini 之后,微软这两天也紧锣密鼓进行了一系列动作。尽管时间日趋圣诞假期,但是两家巨头硬碰硬的军备竞赛丝毫没有停止的意思。
就在昨日,微软官宣放出一个“小模型” Phi-2,这个 Phi-2 仅有 27 亿的参数(注意不是 27 B),但却在参数规模小于 13B 的模型中达到了最先进性能,利用微软在模型扩展与训练数据管理方面的创新,Phi-2 的性能可以直接匹敌参数量超过其 25 倍的模型!

要说 Phi-2,其最大的亮点就在于“小模型”+“高性能”,27 亿的参数量在现在成千上万亿参数的模型中显得格外亮眼,“模型小”将直接支持 Phi-2 可以在笔记本电脑、手机等移动设备上运行。
同时,划重点,“小模型”也可以支持科研人员在不需要昂贵计算设备的情况下在各个相关领域进行科学研究(妈妈再也不用担心实验室没有显卡啦)。
如下图所示,在BBH、常识推理、语言理解、数学、代码等多个领域,2.7B 的 Phi-2 都展现了超过 13B 的 Llama-2 与 7B 的 Mistral 的性能。甚至对比参数量相差近 25 倍的 70B Llama-2,在多个领域 Phi-2 都展现了接近甚至超越 Llama-2 的能力。

而直接对标 Gemini Nano 2,哪怕参数量比 Gemini 少了五个亿,但是 Phi-2 也近乎全线优于 Gemini Nano 2。

此外,在发布会中,微软 CEO 甚至对谷歌贴脸放大——什么?听说在谷歌的演示视频里 Gemini Ultra 可以解决物理问题,不好意思,我 2.7B 的模型 Phi-2 也可以。

而如果更进一步向 Phi-2 输入错误的解题步骤与答案,Phi-2 也可以识别出错误并予以纠正。

Phi-2 是微软之前调整的“微软喜欢小模型(SLM)”战略的产物,在今年 6 月,微软发布了一篇 “All You Need”格式的论文:《Textbooks Are All You Need》,使用了一种更加类似“编写高质量教科书让模型快速学习”的思想,使用高质量的教科书级的数据训练得到了仅仅 1.3 B 的“小模型” Phi-1,在多个评测数据集中取得了极高的正确率。

延续这条“以数据为中心”的思路,微软陆续发布了 Ocra、Phi-1.5 等等在应用“数据管理”等技术训练的“小模型”,而 Phi-2 也正是这条技术进路的接续之作。
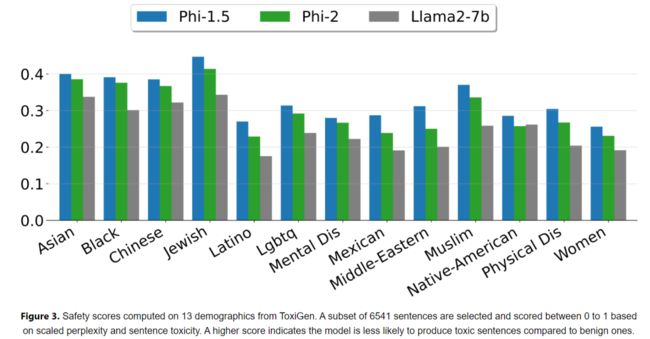
作为一个“小模型”,Phi-2 在 96 个 A100 GPU 上训练了 14 天,且没有使用 RLHF 进行对齐。但是,由于良好的数据质量与数据管理,Phi-2 在毒性方面仍然领先不少其他经过 RLHF 的模型。
击败Gemini Ultra
除了 Phi-2 微软 cue 了谷歌 Gemini 以外,微软针对谷歌 Gemini 发布时所说的在“在 MMLU 基准测试中取得 SOTA”也展开了反击。在 Gemini 发布时,曾称 Gemini Ultra 以 90% 的正确率在大规模多任务语言理解数据集中击败 GPT-4 取得 SOTA。
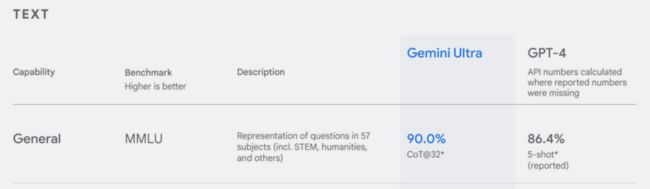
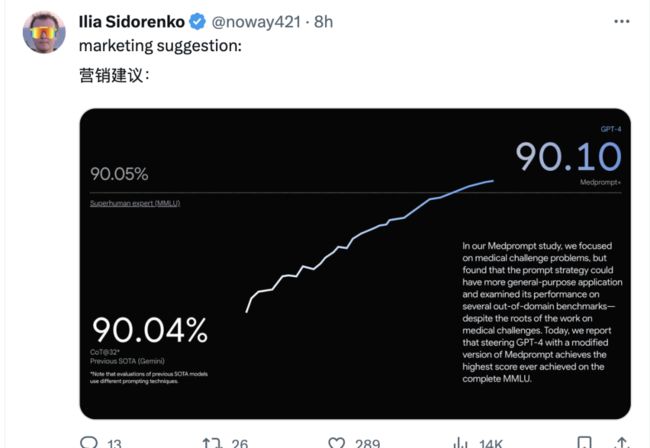
但是微软这两天反击称谷歌在发布信息时存在误导,Gemini Ultra 使用了更加复杂的 Prompt 形式,而如果仅仅使用标准的 Prompt,Gemini Ultra 的表现将比 GPT-4 差,而如果,GPT-4 使用前两天微软刚刚提出的 Medprompt 方法,那么就会击败 Gemini 获得一个新 SOTA:

当然,emmmm 不过这个 90.1% 的新 SOTA 似乎有为了 SOTA 而 SOTA 之嫌,以 0.06% 的“巨大优势”击败谷歌(手动狗头)。
除了 MMLU,微软还发布了其他基准测试的结果,使用简单的 Prompt 与 Gemini Ultra 的性能进行比较,GPT-4 也显著优于 Gemini Ultra:
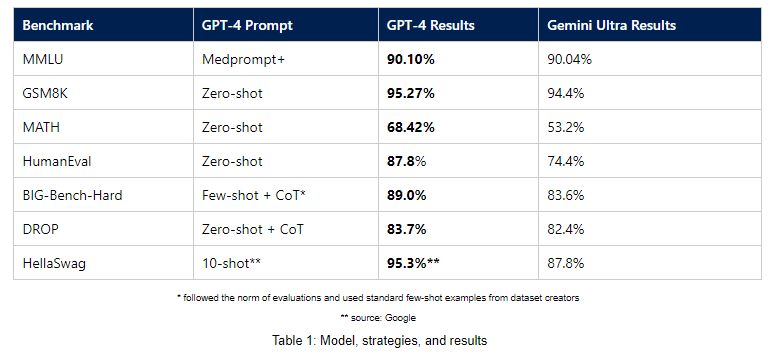
在这其中,微软使用的新的 Prompt 策略 Medprompt,最初是专为医疗垂直领域设计的 Prompt,通过集成“动态示例选择”,“自生成 CoT”以及“选择随机集成”方法,在医疗领域的多个数据集中取得了 SOTA。
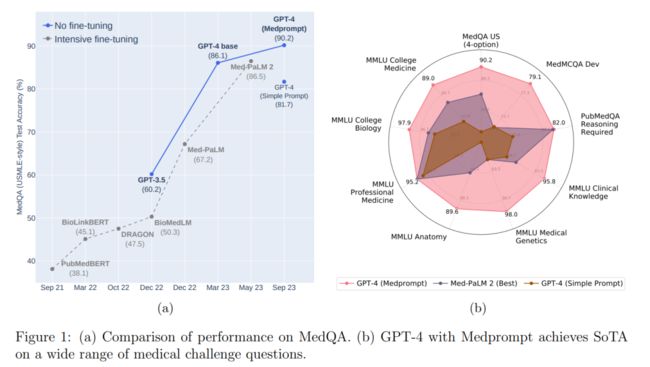
而其中,动态示例选择在于对于每个问题,选择之前收集得到的类似示例为模型提供上下文,而自生成 CoT 则从之前的训练数据中自动生成 CoT Prompt 加强模型的推理能力。最后选择随机集成以多数投票的方式选择最佳答案。
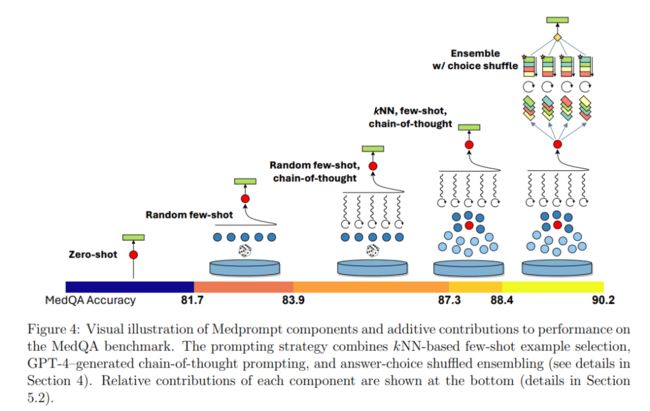
在应用中,微软的研究人员逐渐发现这套思路不仅仅局限于医疗领域中,也适用于更加通用的任务之中,因此对标 Gemini Ultra 进行了一系列实验取得了良好的效果。

看着这世界 AI 的两大巨头你来我往高手过招,你对标我我嘲讽你,对我们吃瓜群众来说倒也不失一场好戏,至于谷歌和微软在这场类似苏联和美国登月竞赛的对拼中谁能走的更远?大模型技术又能被他们推向什么样的高度,且就让我们静静等待吧!