OpenAI发布AGI安全风险框架!董事会可随时叫停GPT-5等模型发布,奥特曼也得乖乖听话
OpenAI 再次强调模型安全性!AGI 安全团队 Preparedness 发布模型安全评估与监控框架!
这两天关注 AI 圈新闻的小伙伴们可能也有发现,近期的 OpenAI 可谓进行了一系列动作反复强调模型的“安全性”。
前有 OpenAI 安全系统(Safety Systems)负责人长文梳理针对 LLM 的对抗攻击类型与防御方法,后有 Ilya Sutskever 领衔的“超级对齐”团队(Superalignment)发布论文探索使用小模型监督对齐大模型,这些工作无一例外都在开头强调“伴随着模型正在逼近 AGI……”

而就在今天,OpenAI 又官宣了一项安全性工作,由 OpenAI 负责 AGI 安全性的新团队 Preparedness 推出了“Preparedness 框架”——一个负责对模型安全性进行评估与监控的系统文件,详细介绍了目前 OpenAI 针对模型安全评估监控的工作思路:

Preparedness 框架提出的背景
Preparedness 框架的提出主要基于 OpenAI 的两个判断:
(1)我们的系统正在逐渐逼近 AGI;
(2)目前针对前沿 AI 的风险研究还远远不足。


在这个背景下,OpenAI 针对不同风险构建了强大的“安全团队”,分别是负责大模型系统安全的 Safety Systems,负责大模型与人类价值观对齐的 Superalignment 以及直接对标模型风险监控的 Preparedness 团队。
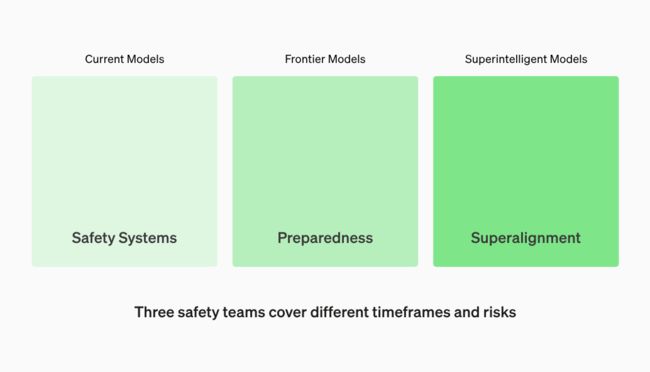
Preparedness 作为在十月份 OpenAI 新成立的团队,由 MIT 教授 Aleksander Madry 直接领导(OpenAI 组建安全 AGI 新团队!应对AI“潘多拉魔盒”),其目标旨在:
-
在现在以及未来,前沿的 AI 系统被滥用,它们会有多危险?
-
如何构建一个强大的框架来监控、评估、预测与防御前沿 AI 系统可能的风险?
-
如果前沿的 AI 系统被盗用,恶意行为者可能会如何使用它们?
Preparedness 内容
而今天发布的 Preparedness 框架主要目标在于通过评估与监测来确定何时以及如何进行 AI 大模型的开发与部署才能确保“安全”,“预备”框架主要包含:
-
实时监控与评估,建立模型风险检测与评估体系,跟踪模型风险水平,并对未来可能风险做出预测与预警;
-
挖掘与寻找 AGI 可能会带来的未知风险;
-
建立模型开发与部署的“安全红线”,确保仅有低风险模型才能部署,中风险模型才能继续研发,高风险模型进行必要调整;
-
开展实地工作,定期发布模型安全性评估综述与报告,协调相关团队贯彻安全性思想;
-
创建跨职能咨询小组,对突发安全风险进行紧急处理。
具体而言,在安全评估与检测之上,Preparedness 团队提到:“We bring a builder’s mindset to safety”,要将建筑师的思维带入到模型的安全评估之中,把模型安全视为一项科学与工程紧密结合的工作

此外,Preparedness 将以“计分卡”的形式,评估目前所有的前沿模型:

目前主要跟踪的风险有网络安全、CBRN(化学、生物、辐射、核威胁)、信仰以及模型自主性。
且OpenAI未来的模型:
-
必须确保高风险以下,模型才能继续研发;
-
必须确保中低风险以下,模型才能部署;
-
高风险模型需要进行必要调整并采取相应安全措施;

董事会有权随时阻止发布AI模型
OpenAI正在创建一个跨职能跨部门的安全咨询小组来审查所有报告并将其同时发送给领导层和董事会。虽然领导层是决策者,但董事会拥有推翻决定的权利。
这意味着董事会有权利随时阻止OpenAI发布他们认为对人类安全造成威胁的AI模型(假如GPT-5足够强大可能不会被发布),哪怕是Sam Altman也要听从董事会的安排(Sam Altman目前不在董事会席位)。
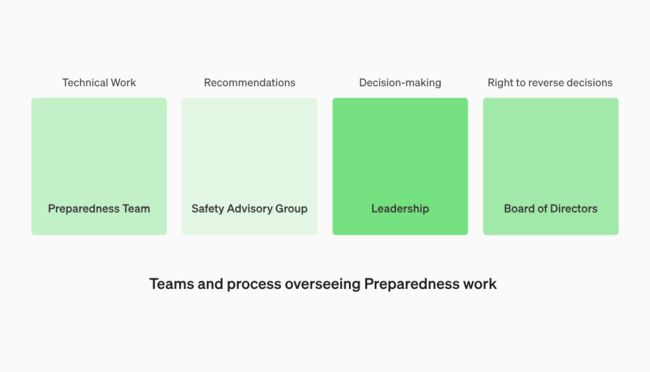
除了上述这些,预备框架还提到 Preparedness 团队将会定期进行安全演习,对紧急安全问题进行快速响应,与第三方审计团队合作,帮助评估前沿模型等等……
对于 OpenAI 最近反复强调的 Safty,除了暗自揣测一下 AGI 是否将来以外,许多网友却似乎并不对“安全”买账,不少网友都认为这种安全审查似乎只是为了避免“承担责任”:

甚至这样“严苛”的安全审查让大家联想起《1984》:
当然,还有网友非常接地气的吐槽:你们安全审查的连问 GPT 如何杀死一个进程都不敢说了……

另外有网友吐槽:这就是GPT写代码变得懒惰的原因吗?


还有网友认为安全措施既耗时又昂贵,会限制模型的能力,降低其对各种任务的效用。

当然,技术风险与技术进步似乎永远都处在一个博弈与"trade-off"的状态,到底是矫枉过正还是防患未然,可能只有时间能告诉我们答案。
最后,Preparedness 框架的全文链接如下:
https://cdn.openai.com/openai-preparedness-framework-beta.pdf
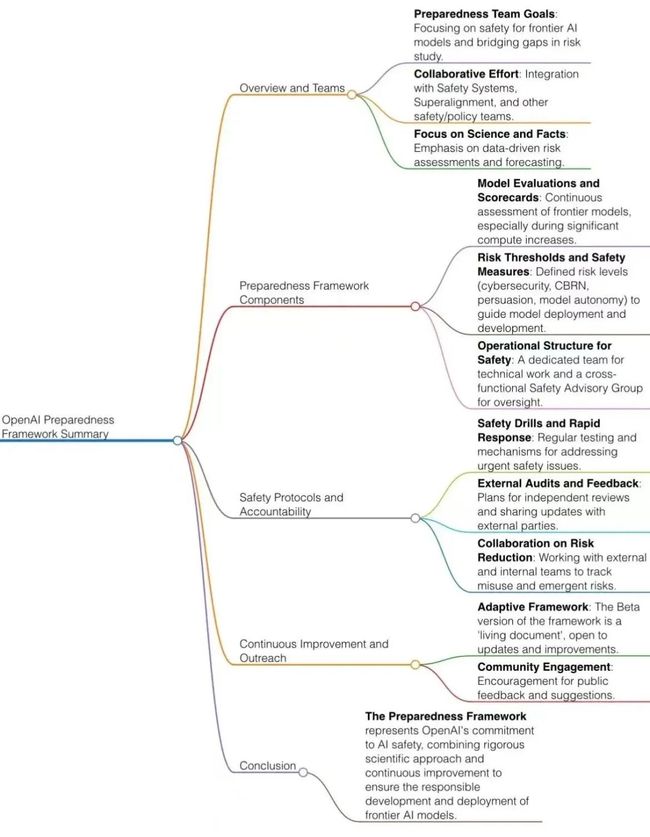
感兴趣的朋友也可以关注网友整理的思维导图~
最后插播一条消息,据The Information报道,为了应对明年的美国大选,OpenAI 改革了内容审核工作,主要是为了防止从 ChatGPT 等产品中根除虚假信息和攻击性内容的。

看来,OpenAI的AGI安全野心就算再大,还是要从这些内容审核的“小事”做起啊。