从单体到微服务,腾讯文档微服务网关工程化的演进实践

导读
腾讯文档网关既承担着流量入口角色,又面临复杂的多适配逻辑,历经多次迭代后从单体演变为了微服务架构。本文是腾讯文档微服务网关工程化的演进实践总结,为你分享从 node Monorepo 微服务架构下使用 pnpm 与 Docker 构建的优化与思考。
目录
1 现有问题
2 工程化思考
3 优化过程
4 优化成果
5 总结
web-gateway 网关承担着文档前端的流量入口的角色,并且对文档前端这一复杂工程有很多适配性的逻辑与操作,比如编辑页的直出(SSR)与列表页重定向等操作。但在经历了好几次迭代,网关项目从原来的单体服务变成了目前微服务架构:
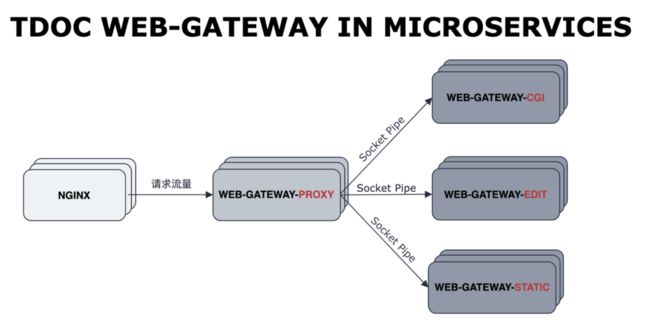
四个微服务是使用 Monorepo 在同一个仓库里面进行维护的,但由于项目的工程化结构并没有保持和微服务架构演进的同步,导致出现了网关服务没有使用 lock 文件锁住微服务的依赖树,进而出现因第三方依赖库的误升级而耗尽服务资源的问题。
因此,我们需要进一步解决网关现有的工程化问题,从而彻底解决资源耗尽问题。
01
现有问题
开始优化前,我们需要先明确现有问题。目前网关存在什么样的问题?
1.1 TL;DR
网关服务目前没法锁住具体包版本(@grpc/grpc-js 超过 1.8.x 对 TCP 端口处理有问题)使监控上报耗费过多资源导致网关服务不可用。
临时方案是强行 override 依赖包版本,即在构建阶段强行安装一次低版本的 @grpc/grpc-js 包来暂时解决问题。
长期优化方案是优化构建流程使用 lock 文件锁住依赖树,以达到所有依赖在可控范围内。
1.2 问题表现
在私有部署环境里面,由于资源不足导致网关服务和监控上报服务之间的连接出现断连,而它们之间的连接是通过 gRPC 协议进行连接的,底层使用了 @grpc/grpc-js 的代码,而这个包在 1.8.x 以上的版本添加了 retry 重连逻辑,而 retry 逻辑不够健壮会不断重试直到服务资源 CPU 100%,详细可以看对应的 issues:https://github.com/grpc/grpc-node/issues/2502
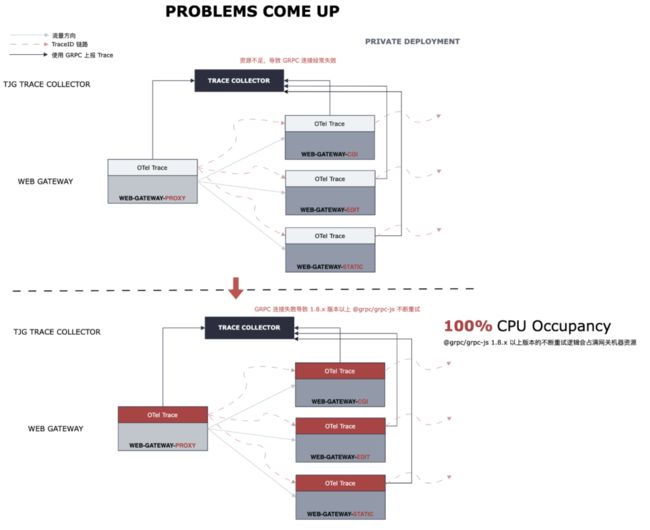
1.3 问题根源
根源在于目前网关构建流程没有使用 lock 文件锁住 npm 依赖,并且 @grpc/grpc-js 属于间接依赖,项目现有的工程化建设(npm + yarn)很难锁住间接依赖的版本,而依赖的版本号控制只锁定了主版本号。
1.4 为什么锁不住?
我这边以 proxy 服务为例子,分析具体包依赖的关系:
@svr/[email protected] /app
`-- @wgw/[email protected]
+-- @opentelemetry/[email protected]
| `-- @grpc/[email protected]
+-- @tencent/[email protected]
| `-- @grpc/[email protected] deduped
+-- @tencent/[email protected]
| +-- @tencent/[email protected]
| | +-- @tencent/[email protected]
| | | `-- @grpc/[email protected] deduped
| | `-- @tencent/[email protected]
| | `-- @tencent/[email protected]
| | `-- @tencent/[email protected]
| | `-- @grpc/[email protected]
| `-- @tencent/[email protected]
| `-- @tencent/[email protected]
| `-- @grpc/[email protected] deduped
`-- @tencent/[email protected]
`-- @tencent/[email protected]
`-- @tencent/[email protected] // ^0.5.2
`-- @grpc/[email protected] deduped
根目录的 @grpc/grpc-js 的依赖就是 1.9.5
可以从上面的依赖分析可以看到,npm 和 Yarn 都比较难实现完全锁住间接依赖的版本号。此外 @grpc/grpc-js 的上层依赖在管理包的时候,使用 ^ 来指定版本导致只会锁住包的 major version。
1.5 为什么没有使用 lock 文件?
我们分析完没有锁住版本的情况,我们来看下为什么项目之前没有使用 lock 文件。
首先先交代一下网关之前的工程化工具:yarn + lerna + npm workspace 来管理项目里面所有的服务和抽象代码的。
网关服务是一个基于 node 的多个微服务组成的,在打包为 Docker 镜像之前,需要将完整的 node_modules 打包进 Docker 镜像里面。
> tree -L 2 -I "node_modules"
.
├── lerna.json
├── package.json
├── packages -- 这里是四个微服务共用的包逻辑 @wgw/xxx
│ ├── deploy
│ ├── helpers
│ ├── middleware
│ ├── proto
│ ├── rpc
│ ├── tools
│ ├── types
│ └── utils
├── README.md
├── servers -- 四个微服务的服务入口 @svr/xxx
│ ├── cgi
│ ├── edit
│ ├── proxy
│ └── static
├── tsconfig.base.json
├── tsconfig.build.json
├── tsconfig.json
└── yarn.lock可以从上面的项目结构看到,@wgw 和 @svr 包都是在 workspace 下进行管理的。
@wgw/* 的包没有发布 npm 远程仓库,作为本地依赖被引入使用,且 @wgw/* 包之间存在相互依赖。

Docker 镜像打包的时候需要完整的 node_modules , 其中是不能存在类似软链接或者硬链接的文件指向,而软链接和硬链接刚好就是 workspace 实现的原理之一。此外,Yarn 在 workspace 管理的时候,存在依赖提升,因此之前的同学将 @wgw/* 使用 tarball 的形式,复制到 @svr/* 服务的 node_modules 下进行打包。

基于上面两点,@svr/* 在引入 @wgw/* 时存在递归路径需要处理(例如 @svr/proxy 依赖 @wgw/tools,@wgw/tools 依赖 @wgw/utils),需要有一个工具在安装的时候,将 @wgw/* 包的版本号转为真正的基于项目根目录的文件路径(如: file:../../packages/xxx 的路径),一般来说这个工具是能处理递归依赖的 npm 或者 Yarn。
而由于第二三点,tarball 的路径是动态写入的,Yarn 安装会报 Tarball is not in network and can not be located in cache 的错误,原因是动态写入的路径和 lock file 不匹配导致报错。

基于以上几点,使用了 npm install 避免 lock 文件对依赖进行了依赖处理。
可以看到这里打包步骤复杂化了,有没有工具或者构建流程的优化使得这个流程回归简洁呢?答案是有的,请看下面章节的优化过程。
1.6 确定优化方向
这里可以看到项目的依赖管理存在很大的问题,如果不彻底改进可能会对后面服务的稳定性产生影响,因此必须进行优化。
经过上面的分析,我们首先需要确定优化的方向:
Docker 镜像打包需要打包完整的 node_modules 且优化后项目启动入口文件不要有过多变化。
工程化工具需要解决间接依赖锁定版本问题,并能自定义依赖的具体版本。
02
工程化思考
由上面的问题分析过程,对此我有几点思考:
2.1 高内聚低耦合
工程师都很喜欢简单职责单一的代码,所以高内聚低耦合是很多模块的要求。大家在编写代码的时候,都倾向于抽象,将代码放在一个自治的地方(比如文件夹),里面的逻辑是独立易于理解的单一逻辑,避免一次性了解所有内容,这样在维护的过程中,可以在高层级的地方了解模块概述的职责,并只在涉及修改具体逻辑的时候才会深入模块了解细节。
但随着项目的不断发展,架构不断演进,代码的抽象会越来越多,如果仅有文件夹的方式来组织项目,那么项目的维护会变得不堪重负。
2.2 代码组织的极端
那怎么来组织代码呢?文件 + 文件夹的方式与每个模块为一个单独的仓库可以看作是组织方式的两种极端:

如果只用文件夹来管理,模块之间的边界是非常模糊的,在项目初期可能没有问题,但是大家开发为了方便肯定慢慢会退化成一些很混乱的引用方式,如果不采取某些方式来管理,维护性也会变得很差。

而另一个极端就是每个模块都是独立的仓库,特别是像 web-gateway 分开了四个微服务的形式,看起来是很适合每个服务都独立成一个仓库的,这样每个服务都是独立的仓库,就没有现在的种种构建流程问题。
但是需要考虑一个情况,当你将所有东西都独立成一个仓库来管理,很可能并不是在解决问题,而是用另一个问题来解决现在的问题。
因为当你将模块脱离网关项目的业务上下文,单个子模块很容易忽略某个代码在其他微服务中的作用,更有可能导致 bug 出现。并且当我们需要升级某个子包的时候,你需要管理所有引用到这个包的入口并进行升级,这是一个非常繁琐的操作。
另外拆分之后,流水线配置维护与镜像的维护都是成倍增加,维护成本也上升了。
个人认为每个项目都是独立的仓库更适合开源项目,而并不是很适合像文档这样以产品价值为导向的团队。
那有没有中间态的组织方式呢?于是我带着这个问题调研了一番。
2.3 pnpm workspace
试过了很多其它工具和方法,踩了很多坑,并基于上面的思考与调研分析,发现 pnpm workspace 方式很符合要求。
它能够将所有入口项目放在一个仓库里面进行管理,并且保持了各个包之间的边界隔离,相互之间引用是通过 npm 包引用的,无需担心上面两种极端情况对代码造成维护负担。
另外 pnpm 提供了很多的工具,比如 readPackage 和 afterAllResolved 两个依赖解析的钩子,能够完成间接依赖的锁定版本操作。因此决定引入 pnpm 来解决项目的问题。
03
优化过程
以下是网关工程化优化的过程的总结,这里总结了一些优化过程有意思和比较特殊的点,方便大家一起交流。
3.1 Docker 镜像构建
目前网关因为存在四个微服务且每个服务都存在多个环境(toc, 多个私有化环境等等),因此关于部署相关的脚本逻辑都放在 @wgw/deploy 这个包里面,当然也包括了 Dockerfile。

从上面可以得知,四个微服务只是逻辑上不同,项目的启动脚本和入口都是一样的。
并且从这里得知,其实 Docker 打包的时候的根目录,其实是在每个微服务各自的根目录下,而并非整个项目的根目录。
或许这里有同学有疑问为什么不直接在项目的根目录进行镜像的构建?
我的思考是,为了保证微服务上下文的独立,微服务即便是逻辑统一,也需要保证自身的上下文完整独立自治,而并非逻辑与构建流程进行分离,一旦分离,不利于后面持续的改进优化与微服务各自的细粒度优化,比如 proxy 服务后面改进为云原生网关,整个逻辑与其他微服务不同,只需要在自身的目录下添加 Dockfile 而不影响其他微服务。
3.2 Docker COPY 与 node_modules
其实这里的复杂性,很大程度就是由于 Monorepo + node 多个微服务 + Docker COPY 这几个因素加在一起,导致问题解决起来比较棘手。
问题的根源在于多个环境的不统一导致的,即 Docker 镜像内的目录与开发环境的目录环境不一致:

所以这里需要先统一环境。
由于项目的工程化换为了 pnpm,那么在各个微服务自身根目录的 node_modules 会存在指向根目录 node_modules 的软硬链接,并且对于 Monorepo 其他模块的引用,也是使用软链接的方式进行引用的。
由于软硬链接的存在,如果改变这些相对路径的指向,那么需要处理的路径逻辑过于复杂,因此我决定环境与开发环境的目录保持统一,一方面可以降低了打包的难度,另一方面降低了维护的心智负担。
那既然决定了保存原始目录结构,那么这里最简单的解法莫过于直接复制整个项目目录进 Docker 镜像里面。
COPY . .但是这样污染 Docker 微服务镜像,因为将很多不必要的代码都复制进镜像里面,比如其他微服务代码与未依赖的 package,此外 node_modules 也很冗余。
因此需要进一步的优化:也就是将 Docker 构建的根目录换为微服务自身的目录下,那怎么处理 monorepo 的依赖与根目录 node_modules 的依赖并只复制当前微服务的代码呢?我们可以采取 Docker 分阶段构建的写法:
FROM base AS topdep
WORKDIR /
RUN mkdir node_modules packages
COPY node_modules/ node_modules
COPY packages/ packages
FROM topdep as svr
WORKDIR /usr/app
COPY ["pnpm-*.yaml", ".npmrc", "./"]
COPY "servers/${APP}/" .这样的话可以保证服务入口只有当前微服务的代码,因为根据 APP 构建时参数进行选择性复制。
但是这样的做法还是不够完美,因为 packages 的复制会复制到本微服务没有依赖到的模块代码造成一定的污染,有没有更完美的方案呢?
3.3 Docker context
答案是存在的。
Docker 构建时是需要一个上下文的,这个上下文默认是当前目录,这样能够确保构建时的路径和元数据是一定的,而这个上下文我们是可以进行自定义的。
我们可以用过一个简单的命令来了解 Docker Context 的用法:
tar --exclude='node_modules' --exclude='.git' -cf - ../../ | docker build -f servers/proxy/Dockerfile.context - -t contextproxysvr通过上面这个命令可以得知,这个命令的含义是将 ../../ 即当前目录的父目录的父目录,忽略掉 node_modules 与 .git 目录,其他目录文件打包进 tarball 里面,而这个 tarball 不会形成一个实际文件,而是变成一个文件流传入到 Docker Context 中,形成 Docker 构建时的上下文。

注意这里的 TARBALL 文件流并不会生成实际的文件,而是通过流形式传入了 Docker Context。
3.4 pnpm-context.mjs
由上面我们可以得知 Docker Context 是可以自定义的,那么是否可以通过分析每个微服务的自身依赖,来自定义构建上下文以达到干净的镜像目录且与开发环境一致的目录呢?
此时我们借助 pnpm 的模块依赖分析能力,编写 .pnpm-context 脚本来达到目的:
// .... 这里只展示入口逻辑
async function main(cli) {
const projectPath = dirname(cli.dockerFile)
// https://pnpm.io/filtering
const [dependencyFiles, packageFiles, metaFiles] = await Promise.all([
getFilesFromPnpmSelector(`{${projectPath}}^...`, cli.root, {
extraPatterns: cli.extraPatterns
}),
getFilesFromPnpmSelector(`{${projectPath}}`, cli.root, {
// 本包目录下除了 Dockerfile 都复制
extraPatterns: cli.extraPatterns.concat([`!${cli.dockerFile}`])
}),
getMetafilesFromPnpmSelector(`{${projectPath}}...`, cli.root, {
extraPatterns: cli.extraPatterns
})
])
await withTmpDir(async (tmpdir) => {
await Promise.all([
fs.copyFile(cli.dockerFile, join(tmpdir, 'Dockerfile')),
copyFiles(dependencyFiles, join(tmpdir, 'deps')),
copyFiles(metaFiles, join(tmpdir, 'meta')),
copyFiles(packageFiles, join(tmpdir, 'pkg'))
])
const files = await getFiles(tmpdir)
if (cli.listFiles) {
for (const path of files) console.log(path)
} else {
await pipe(createTar({ gzip: true, cwd: tmpdir }, files), process.stdout)
}
})
}
// ...上面的目录会生成一个文件流传入到 Docker Context 中,这个文件流中只有三个目录:meta,deps,pkg。
meta 目录是存放项目工程化配置文件的,比如 pnpm-lock.yml,package.json 等等。
deps 目录是 Monorepo workspace 下本服务所依赖的模块。
pkg 目录是微服务自身的逻辑模块。
# 复制构建后的代码
COPY ./meta .
COPY ./deps .
COPY ./pkg .
RUN --mount=type=cache,id=pnpm-store,target=/root/pnpm-store\
pnpm config set store-dir /root/pnpm-store && pnpm install --filter "{${PACKAGE_PATH}}..."\
--frozen-lockfile\
--prod\
--ignore-scripts\
--unsafe-perm这样的话,通过自定义 context 与 Dockerfile 的配合,实现了 pnpm Monorepo 与 Docker 的镜像构建逻辑,并且保持了镜像的干净与一致性。
3.5 node-linker & package-import-method
pnpm 这个工具真的是非常贴心,从他们文档里面可以看出,pnpm 与 Docker 打包的情况他们也考虑了:https://pnpm.io/zh/npmrc#node-linker。
node-linker 这个参数,如果设置了 hoist,那么 pnpm 在下载的时候或者在 Docker 构建的时候会创建一个没有符号链接的 node_modules 便于打包进镜像里面。
但是这个参数却并不适合我们的项目,为什么?因为我们是一个使用 Monorepo 管理的 node 微服务项目,如果设置了这个参数,依赖管理模式就会回退为 npm 和 Yarn 类似的模式,不利于解决幽灵依赖的问题和 Docker 镜像内的依赖复制(项目层级与依赖层级一致问题)。
而 package-import-method https://pnpm.io/zh/npmrc#package-import-method 在我们的项目中需要设置为 copy:
package-import-method=copy也就是 pnpm 在下载包的时候,使用 copy 的方式从 pnpm-store 里面复制过来,一方面保证我们使用了 pnpm store 缓存,另一方面保证了我们的依赖层级和本地保持了一致,减少了很多运维层面的心智负担(比如不需要再担心开发环境和线上环境的项目层级与依赖层级问题)。
3.6 软链接与硬链接
软链接和硬链接在 pnpm 的底层原理中使用很广泛,那软链接和硬链接的区别是什么?又启发了我们用于项目优化的什么地方呢?
首先先说明一下它们的区别:

在 unix/linux 里面,文件存储最小单位是扇区(sector),8 个扇区组成一个 块(Block),而文件的内存储存在很多个块(block)中。而 inode 则是存储了关于文件的元数据包括文件数据 Block 的位置与链接数等等。
而这里的链接数与硬链接有关:

可以从上面知道,硬链接是一个完整的 inode 文件。

而软链接是一个指向某个 inode 的指针,也就是可理解为是一个快捷方式。
而这一特性正好启发了我优化的手段,因为改造之后,Docker 镜像里面的层级关系已经发生变化,而服务的启动脚本里面,有很多关于配置文件,入口文件等等一些重要文件的路径处理逻辑。改造之后可能需要花费大量的人力来验证逻辑中使用的路径有没有发生变化。有没有方式可以降低这里的验证成本呢?
我在项目入口的设置用到了这个特性。可以看下面这个图:

软链接是相当于源文件的一个快捷方式,所以在执行逻辑时还是按照原有文件位置进行依赖查找,这样能够不影响被软链后的文件执行逻辑。
这里使用软链接,将真实文件映射到原有位置,这样就达到了我们改造之后项目层级虽然发生了变化,但是入口文件的位置和启动脚本并不需要进行改动,改造与验证成本大幅度降低。验证阶段我们验证镜像服务能正确启动就没有问题,其他同学登录容器查看日志和入口文件与配置这些运维经验还继续适用。
04
优化成果
通过上面的优化,目前可以达到完全锁定任意包的指定版本,并且解决了以前潜在的很多问题,简化了构建流程。
4.1 幽灵依赖问题解决
这里顺带还解决了以前项目没有发现存在的问题,也就是幽灵依赖的问题。
之前通过 Yarn 和 npm 来管理依赖,存在依赖提升的问题,也就是类似下面的情况:
由于依赖被打平,B 依赖被提升到 node_modules 的一级目录
node_modules
├── [email protected]
├── [email protected]
└── [email protected]
└── node_modules
└── [email protected]
项目只引用了 A 和 C,但是如果代码里面写了引用 B 的代码,也是可以引用到的。
{
"dependencies": {
"A": "^1.0.0",
"C": "^1.0.0"
}
}危险性在于,如果有一天 B 依赖层级发生改变或者依赖关系发生变化,那么代码就会报错。但通过这次改造,消除了这个潜在问题。
4.2 .pnpmfile.mjs 彻底解决依赖(直接或间接)锁版本问题
pnpm 暴露了两个钩子函数帮助我们在生成 lock 文件之前,可以通过修改对应的 lock 文件生成结构从而达到锁定对应包版本的目的,具体可以看以下代码逻辑(有需要的同学可以直接拿我这个脚本来进行修改):
// 类型信息是我根据 pnpm 源码找到添加上去的, 可以帮助编写逻辑
/**
* @typedef PackageInfo
* @type {object}
* @property {string} name
* @property {string} version
* @property {string} description
* @property {string} main
* @property {object} scripts
* @property {string} author
* @property {string} license
* @property {object} dependencies
* @property {object} devDependencies
* @property {object} optionalDependencies
* @property {object} peerDependencies
*/
/**
* @typedef LockfileProjectSnapshot Map 类型都不是真正的 Map,只是对象
* @type {object}
* @property {Map} specifiers
* @property {Map} dependencies
* @property {Map} devDependencies
* @property {Map} optionalDependencies
* @property {object} dependenciesMeta
* @property {string} publishDirectory
*/
/**
* @typedef Lockfile Map 类型都不是真正的 Map,只是对象
* @type {object}
* @property {Map} importers 引包入口
* @property {string | number} lockfileVersion
* @property {LockfileProjectSnapshot} packages
*/
/**
* @typedef ReadPackageContext
* @type {object}
* @property {function} log
*/
/**
* Will be called after parse package dependencies
* @param {PackageInfo} pkg
* @param {ReadPackageContext} context
* @returns
*/
function readPackage(pkg, context) {
// 解决直接依赖版本
if (pkg && pkg.dependencies && pkg.dependencies['@grpc/grpc-js']) {
const grpcVersion = pkg.dependencies['@grpc/grpc-js']
if (compareVersion(grpcVersion, '1.7.3') >= 1) {
pkg.dependencies['@grpc/grpc-js'] = '1.7.3'
context.log(`Modifying the @grpc/grpc-js package(which greater than 1.7.3) to be version 1.7.3 in ${pkg.name}`)
}
}
return pkg
}
/**
* Will be called before preinstall to modify lockfile to lock package version
* @param {Lockfile} lockfile
* @param {ReadPackageContext} context
* @returns
*/
function afterAllResolved(lockfile, context) {
// 直接依赖从上面 readPackage 里面来解决
// 这里是解决间接依赖的问题
/**
* 以下逻辑:
* 1. 检查所有包生产依赖有没有依赖到 @grpc/grpc-js,如有则判断版本是否超过 1.7.3,
* 如超过则强行修改依赖为 1.7.3(因为不希望引到超过这个版本,超过这个版本会有 TCP 占用问题)
* 2. 检查包本身的信息是否是 @grpc/grpc-js 这个包,如果超过则删除
* 3. 添加 @grpc/grpc-js/1.7.3 版本的 entry 信息
*/
if (lockfile.packages) {
const allPackageNames = Object.keys(lockfile.packages)
for (const packageName of allPackageNames) {
const packageInfo = lockfile.packages[packageName]
const packageDependencies = packageInfo.dependencies
if (packageName.includes('@grpc/grpc-js')) {
const grpcVersionMatchRes = packageName.match(/\\d+\\.\\d+\\.\\d+/)
const grpcVersion = grpcVersionMatchRes[0]
if (compareVersion(grpcVersion, '1.7.3') >= 1) {
delete lockfile.packages[packageName]
}
}
if (packageDependencies && packageDependencies['@grpc/grpc-js'] !== undefined) {
packageGRPCDependencyVersion = packageDependencies['@grpc/grpc-js']
// 如果版本比 1.7.3 低则不修改, 如果高于 1.7.3 版本则修改为 1.7.3
if (compareVersion(packageGRPCDependencyVersion, '1.7.3') >= 1) {
packageDependencies['@grpc/grpc-js'] = '1.7.3'
}
}
}
// 给 packages 添加 @grpc/[email protected] 版本 entry
lockfile.packages['/@grpc/grpc-js/1.7.3'] = grpcLockInfoEntry('1.7.3')
}
context.log('Modifying the @grpc/grpc-js package(which greater than 1.7.3) to be version 1.7.3')
return lockfile
}
...
module.exports = {
hooks: {
readPackage,
afterAllResolved
}
} 这里验证过,readPackage 和 afterAllResolved 钩子都是在 preinstall 钩子之前执行的。

得知 readPackage 和 afterAllResolved 是拿到所有服务的依赖关系,生成了 lockfile,接着执行下载操作。这就是我们锁定间接依赖的包版本的原理啦。

05
总结
工程化也是项目不可忽视的一部分,如果发生变形,很容易造成项目维护成本的上升,使得项目越来越不可控。因此,及时修复与改进项目工程化建设是非常有必要的。
而改进项目工程化并非一件容易的事情,虽然从 Yarn + lerna 切换到 pnpm 是一个简单的事情,但过程中会因为其他因素与项目独特性造成了切换成本的急剧上升。最后,借 John D.Cook 博士的一句话来结束全文:Simple versus easy。
-End-
原创作者|张翔

你对项目工程化有什么看法?欢迎评论分享。我们将选取1则最有价值的评论,送出腾讯云开发者社区定制笔记本1个(见下图)。12月6日中午12点开奖。

欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)



