python连接oracle
文章目录
- 下载最新的oracle
- 安装oracle
- oracle中新特性cdb
-
- 日常操作
-
- 查看数据库是否为CDB
- 查看当前的容器
- 查看CDB中的PDB信息
- 启动和关闭已创建好的PDB数据库
- 安装python
- 安装cx_Oracle
- 测试连接
- Executing SQL statements
-
- SQL Queries
-
- 重要
- Fetch Methods
- Closing Cursors
连接Oracle需要安装cx_Oracle和oracle客户端
下载最新的oracle
https://www.oracle.com/database/technologies/oracle-database-software-downloads.html#19c
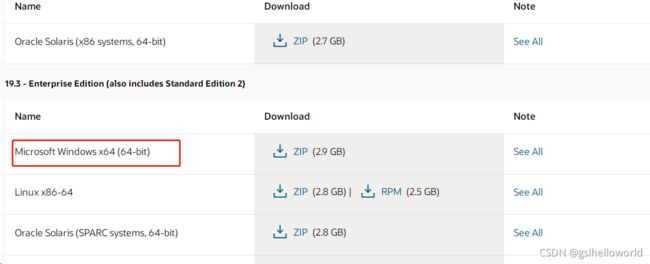
安装oracle



耐心等待几十分钟,直接跳到100%。

用户名:sys
oracle中新特性cdb
Oracle 12C 后引入了CDB与PDB的新特性,在ORACLE 12C数据库引入的多租用户环境(Multitenant Environment)中,允许一个数据库容器(CDB)承载多个可插拔数据库(PDB)。CDB全称为Container Database,中文翻译为数据库容器,PDB全称为Pluggable Database,即可插拔数据库。在ORACLE 12C之前,实例与数据库是一对一或多对一关系(RAC):即一个实例只能与一个数据库相关联,数据库可以被多个实例所加载。而实例与数据库不可能是一对多的关系。当进入ORACLE 12C后,实例与数据库可以是一对多的关系。下面是官方文档关于CDB与PDB的关系图。
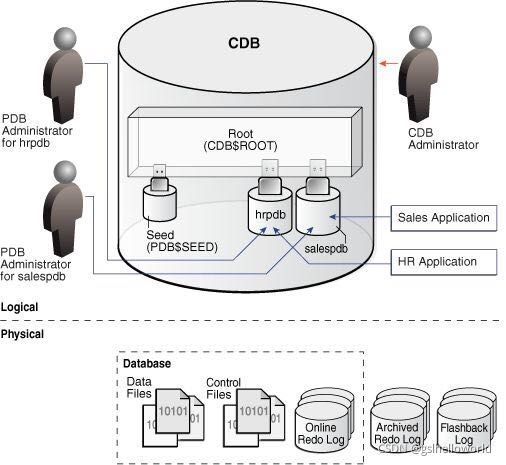
日常操作
查看数据库是否为CDB
[root@vastdata11 ~]# su - oracle
[oracle@vastdata11 ~]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.2.0 Production on Sat Jun 1 21:42:21 2019
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Advanced Analytics and Real Application Testing options
SQL> select name,cdb,open_mode,con_id from v$database;
NAME CDB OPEN_MODE CON_ID
------------------ ------ ---------------------------------------- ----------
CDB YES READ WRITE 0
查看当前的容器
SQL> show con_name;
CON_NAME
------------------------------
CDB$ROOT
SQL> select Sys_Context('Userenv', 'Con_Name') "current Container" from dual;
current Container
--------------------------------------------------------------------------------
CDB$ROOT
查看CDB中的PDB信息
SQL> select con_id, dbid, guid, name , open_mode from v$pdbs;
CON_ID DBID GUID NAME OPEN_MODE
---------- ---------- -------------------------------- -------------------------------------------------------------------------------- ----------
2 2481424270 8AEA7B521083444E801582CE4DF51945 PDB$SEED READ ONLY
3 3579770414 499D9DE8F99D45298FE6BFA28BC2ED08 ORCLPDB
启动和关闭已创建好的PDB数据库
http://blog.itpub.net/69902483/viewspace-2646510/
安装python
(myenv) PS C:\pythonprj> python
Python 3.9.7 (tags/v3.9.7:1016ef3, Aug 30 2021, 20:19:38) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> ^Z
安装cx_Oracle
(myenv) PS C:\pythonprj> pip install cx_Oracle
Collecting cx_Oracle
Downloading cx_Oracle-8.2.1-cp39-cp39-win_amd64.whl (213 kB)
|████████████████████████████████| 213 kB 262 kB/s
Installing collected packages: cx-Oracle
Successfully installed cx-Oracle-8.2.1
测试连接
import cx_Oracle
#连接数据库,下面括号里内容根据自己实际情况填写
conn = cx_Oracle.connect('用户名/密码@IP:端口号/SERVICE_NAME')
# 使用cursor()方法获取操作游标
cursor = conn.cursor()
#使用execute方法执行SQL语句
result=cursor.execute('Select member_id from member')
#使用fetchone()方法获取一条数据
#data=cursor.fetchone()
#获取所有数据
all_data=cursor.fetchall()
#获取部分数据,8条
#many_data=cursor.fetchmany(8)
print (all_data)
db.close()
Executing SQL statements
Executing SQL statements is the primary way in which a Python application communicates with Oracle Database. Statements are executed using the methods Cursor.execute() or Cursor.executemany(). Statements include queries, Data Manipulation Language (DML), and Data Definition Language (DDL). A few other specialty statements can also be executed.
PL/SQL statements are discussed in PL/SQL Execution. Other chapters contain information on specific data types and features. See Batch Statement Execution and Bulk Loading, Using CLOB and BLOB Data, Working with the JSON Data Type, and Working with XMLTYPE.
cx_Oracle can be used to execute individual statements, one at a time. It does not read SQL*Plus “.sql” files. To read SQL files, use a technique like the one in run_sql_script() in samples/sample_env.py
SQL Queries
Queries (statements beginning with SELECT or WITH) can only be executed using the method Cursor.execute(). Rows can then be iterated over, or can be fetched using one of the methods Cursor.fetchone(), Cursor.fetchmany() or Cursor.fetchall(). There is a default type mapping to Python types that can be optionally overridden.
重要
防止SQL注入
Interpolating or concatenating user data with SQL statements, for example cur.execute("SELECT * FROM mytab WHERE mycol = '" + myvar + "'"), is a security risk and impacts performance. Use bind variables instead. For example, cur.execute("SELECT * FROM mytab WHERE mycol = :mybv", mybv=myvar).
Fetch Methods
After Cursor.execute(), the cursor is returned as a convenience. This allows code to iterate over rows like:
cur = connection.cursor()
for row in cur.execute("select * from MyTable"):
print(row)
Rows can also be fetched one at a time using the method Cursor.fetchone():
cur = connection.cursor()
cur.execute("select * from MyTable")
while True:
row = cur.fetchone()
if row is None:
break
print(row)
If rows need to be processed in batches, the method Cursor.fetchmany() can be used. The size of the batch is controlled by the numRows parameter, which defaults to the value of Cursor.arraysize.
cur = connection.cursor()
cur.execute("select * from MyTable")
num_rows = 10
while True:
rows = cur.fetchmany(num_rows)
if not rows:
break
for row in rows:
print(row)
If all of the rows need to be fetched, and can be contained in memory, the method Cursor.fetchall() can be used.
cur = connection.cursor()
cur.execute("select * from MyTable")
rows = cur.fetchall()
for row in rows:
print(row)
The fetch methods return data as tuples. To return results as dictionaries, see Changing Query Results with Rowfactories.
Closing Cursors
A cursor may be used to execute multiple statements. Once it is no longer needed, it should be closed by calling close() in order to reclaim resources in the database. It will be closed automatically when the variable referencing it goes out of scope (and no further references are retained). One other way to control the lifetime of a cursor is to use a “with” block, which ensures that a cursor is closed once the block is completed. For example:
with connection.cursor() as cursor:
for row in cursor.execute("select * from MyTable"):
print(row)
This code ensures that, once the block is completed, the cursor is closed and resources have been reclaimed by the database. In addition, any attempt to use the variable cursor outside of the block will simply fail.