NLP论文阅读记录 - AAAI 23 | 02 SUMREN:总结有关新闻事件的报道演讲
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
-
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
-
- 2.1新闻摘要
- 2.2 以查询为中心的摘要
- 2.3 新闻归因
- 三.本文方法
-
- 3.1 SumREN 基准
-
- 3.1.1基准建设
- 3.1.2 统计
- 3.1.3 银牌训练数据生成
- 3.2 Models
-
- 3.2.1以查询为中心的摘要基线
- 3.2.2 基于管道的摘要框架
- 四 实验效果
-
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
-
- 人工评价
- 五 总结
前言

SUMREN: Summarizing Reported Speech about Events in News(23)
code
paper
0、论文摘要
新闻文章的主要目标是建立事件的事实记录,通常通过传达特定事件的细节(即 5W;有关该事件的人物、事件、地点、时间和原因)以及人们如何了解该事件来实现对此作出反应(即报告的陈述)。
然而,现有的新闻摘要工作几乎完全集中在事件细节上。
在这项工作中,我们提出了一项新颖的任务,即总结不同发言者对特定事件的反应(如他们报告的陈述所表达的那样)。
为此,我们创建了一个新的多文档摘要基准 SUMREN,其中包含从讨论 132 个事件的 633 篇新闻文章中获得的 745 份不同公众人物的报道陈述摘要。
我们为我们的任务提出了一种自动 silvertraining 数据生成方法,它可以帮助像 BART 这样的小型模型在此任务上实现 GPT-3 级别的性能。
最后,我们引入了一个基于管道的框架来总结报告的语音,我们凭经验证明该框架可以生成比基线以查询为中心的摘要方法更抽象和更真实的摘要。
一、Introduction
1.1目标问题
在新闻中,当记者通过直接引用第三方的言论(即直接引用)或解释他们所说的内容(即间接引用)来报道第三方的言论时,就会发生归因。报道的言论是追踪公众人物立场、观点和世界观的核心资源,使其引起新闻读者的普遍兴趣。例如,读者可能有兴趣了解拜登总统对 2022 年乌克兰危机的看法或疾病控制与预防中心关于新的 COVID-19 变种的最新指南。此外,报道的陈述涵盖了新闻文章中呈现的很大一部分信息——作为我们注释练习的一部分(稍后在第 3.1 节中描述),我们发现整个文章内容的 45% 与报道的陈述相对应。然而,当前的新闻摘要数据集,如 CNN-DM (Hermann et al. 2015)、Multi-News (Fabbri et al. 2019) 和 Timeline100 (Li et al. 2021) 在很大程度上忽视了对这些报道陈述的总结。
为了弥补这一差距,我们引入了新任务:总结有关新闻和事件中的事件的报道演讲。为此任务创建一个新的基准 SUMREN。形式上,给定一组与特定事件相关的新闻文章,任务是总结给定演讲者关于该事件的陈述(例如,“查克·舒默关于通过 2022 年通货膨胀削减法案说了些什么?”)。该任务的目的是向新闻读者提供各种公众人物对不同事件的反应。表 1 显示了 SUMREN 的一个示例,以及报告的陈述和相应的参考摘要。
总结新闻中报道的言论带来了一系列独特的挑战。与传统的新闻摘要数据集相反,在传统的新闻摘要数据集中,有关事件的最显着的信息通常在给定文章的前几句话中讨论,通常称为“引导偏差”(Jung)等人。 2019;朱等人。 2021),来自同一演讲者的演讲可能分散在整篇文章中。陈述可以分为多个句子(即“连续引用”),并且说话者通常通过其名义和代词提及来提及,需要对长期依赖性和可靠的共同引用解析进行建模。此外,从一组报告的陈述中生成简明摘要需要更高层次的抽象。这也得到了经验上的验证,因为我们发现 SUMREN 中的摘要比现有的新闻摘要数据集更加抽象,如表 2 所示。最后,事实一致性在报告的语音摘要中至关重要,因为错误引用或歪曲公众人物的陈述可能会导致错误引用或歪曲公众人物的陈述。会特别有害。

1.2相关的尝试
1.3本文贡献
为了解决上述挑战,我们提出了一种基于管道的方法来完成新闻文章中报道的言论的总结任务。
该管道首先涉及识别单个陈述和相应的本地说话者提及,
然后使用共指解析来全局解析说话者提及,将来自同一说话者的陈述分组在一起,
最后总结给定说话者提取的报告陈述。
我们假设,在基于管道的框架中,拥有可以识别相关上下文的显式提取组件有助于摘要模型更好地关注给定文章中的关键信息。
此外,我们引入了一种经济高效的方法来为报告的语音摘要任务生成训练数据。具体来说,我们利用大规模预训练语言模型,例如 GPT-3(Brown 等人,2020),为从自动报告的语音提取系统获得的语句生成银标准摘要。在此之前,最近的工作使用大型语言模型来创建训练数据(Schick 和 Sch utze 2021),尽管之前曾针对自然语言推理等判别任务进行过探索。我们证明,使用此类银标准数据进行训练可以帮助较小的语言模型(例如 BART(Lewis 等人,2020))在此任务上实现 GPT-3 级别的性能。
总之,我们的贡献如下:
• 引入一项新的挑战性任务,即总结有关新闻事件的报道演讲,并针对该任务发布第一个多文档摘要基准 SUMREN1。 SUMREN 包含 745 个实例,对 633 篇新闻文章进行了注释,讨论了 132 个事件,
• 凭经验证明可以利用大规模语言模型为报告语音摘要任务创建具有成本效益的银标准训练数据,
• 提出基于管道的报告语音摘要框架并表明它能够生成比以查询为中心的方法更加抽象的摘要,同时还提高了生成的摘要与源文档的事实一致性。
二.相关工作
2.1新闻摘要
现有文献和多个现有数据集对新闻文章的总结进行了广泛的研究。单文档摘要数据集包括 CNN/Daily Mail (Hermann et al. 2015)、News Room 语料库 (Grusky、Naaman 和 Artzi 2018) 和 XSum 数据集 (Narayan、Cohen 和 Lapata 2018)。法布里等人。 (2019) 引入了一个大型数据集 Multi-News,将新闻摘要扩展到多文档设置。时间线摘要(Steen and Markert 2019;Li et al. 2021)通过生成一系列重大新闻事件及其关键日期,为新闻摘要添加了时间方面的内容。另一条工作线围绕新闻标题生成(Banko、Mittal 和 Witbrock 2000),其中涉及为给定新闻报道生成代表性标题,并在单文档(Hayashi 和 Yanagimoto 2018)和多文档设置(Gu 等人)中进行了探索.2020)。然而,这些数据集都主要侧重于总结事件细节,而忽略了与这些事件相关的报道语音。
2.2 以查询为中心的摘要
以查询为中心的摘要 (QFS) 旨在生成一个摘要来回答有关源文档的特定查询。从概念上讲,报告的语音摘要对应于查询“X 对 Y 说了什么?”。先前的工作通过从网络上抓取参考摘要或使用伪启发式方法来获取参考摘要,从而构建大规模 QFS 数据集。例如,WikiSum(Liu et al. 2018)和AQuaMuSe(Kulkarni et al. 2020)直接从维基百科文章中提取段落作为参考摘要。另一方面,手动注释的 QFS 数据集很小 – DUC 2006 和 2007 (Dang 2005) 仅包含最多 50 个示例。 QMSum(Zhong et al. 2021b)专注于总结会议对话记录,与我们的工作最相似。然而,QMSum 记录包含大量非正式对话,不包含像 SUMREN 中报告的陈述那样的重点信息内容。
由于 QFS 数据集通常仅包含源摘要对,因此大多数先前的工作要么使用端到端方法(Vig et al. 2022;Xu 和 Lapata 2022),要么遵循两步提取然后抽象的框架(Xu 和 Lapata 2021) ; Vig et al. 2022),训练提取器以识别与 ROUGE 分数方面的参考摘要相似的文本范围。相反,SUMREN 还额外提供了相应的相关内容,即本例中的报告陈述,用于注释摘要。因此,我们提出的基于管道的方法可以利用它来构建和评估独立于参考摘要的提取组件,同时仍然确保生成的摘要在事实一致性方面具有高输入保真度。
2.3 新闻归因
归因已通过多个可用数据集进行了深入研究。埃尔森和麦基翁 (2010);张和刘(2021)与说话者一起研究直接引语的归因。帕莱蒂(2012);帕雷蒂等人。 (2013)通过包括间接配额来扩展这一概念系统蒸发散并创建 PARC3 语料库。最近,PolNeAR(Newell、Margolin 和 Ruths 2018)的创建是为了通过将召回率加倍并改进注释器间一致性来改进 PARC3。然而,所有这些工作都仅涉及识别归因,并且不会汇总特定发言人的摘录陈述以帮助完成下游任务。新闻中引用的更直接用途包括意见挖掘(Balahur 等人,2009)和情绪分析(Balahur 等人,2013)。相比之下,我们提出的任务涉及归因来识别新闻文章中报道的陈述,然后对这些陈述进行汇总和总结,以传达对新闻事件的反应。
三.本文方法
3.1 SumREN 基准
SumREN 基准测试旨在协助开发和评估所报告的语音摘要任务的模型。在本节中,我们描述了报告语音摘要的任务、基准构建过程以及所构建数据集的统计数据。给定一组有关特定事件和演讲者姓名的新闻文章,目标是为源内容中演讲者的陈述生成简洁的摘要。
3.1.1基准建设
我们基准构建过程的第一步涉及收集讨论大量事件的新闻语料库。我们根据所讨论的事件拆分新闻文章,并从每组新闻文章中提取所有报道的声明以及每个声明的发言人。最后,对同一发言者的每组发言进行总结。
新闻语料库获取
我们首先确定了2013-2021年间在维基百科和其他来源中提到的132个重大新闻事件的列表。然后,我们收集了讨论这些事件的新闻文章列表,并保留了出现在Common Crawl (CC) news中的文章。2我们最终得到了与132个主要事件对应的633篇新闻文章。
报告语句注释
为了注释报告的语句和说话者,我们使用了Amazon Mechanical Turk,并为每个HIT收集了三个注释。注释任务仅限于英语国家的注释者,并且他们通过了相应任务的定制资格测试-报告语句跨度选择或说话人识别总的来说,参加测试的注释者中有12%是合格的。此外,我们还阻止了每个任务花费少于指定秒数或始终提供低质量注释的垃圾邮件发送者。对于报告的语句跨度选择任务,向注释者提供新闻文章的一个片段,并要求注释者突出显示包含报告语句的跨度。来自同一说话人的连续句子被认为是同一陈述句的部分。在收集了注释之后,我们将特定讲话者关于每个事件的报告语句(和相关文章)分组。
摘要生成
对于摘要生成,我们依靠专家注释器,因为这是一项更具挑战性的任务,因此不太适合 MTurk。为每个报告语句簇创建了由两个不同注释者生成的两个参考摘要。下面提供了注释指南的删节版本,图 1 显示了注释过程的演练示例。
步骤 1:确定给定陈述中的显着跨度。 • 步骤 2:将相似的显着跨度(讨论事件的相关方面)分组在一起,并将它们组合成一个
单句;如果需要的话可以使用释义。 • 步骤3:将这些句子组合成摘要。
3.1.2 统计
我们的基准测试总共有 745 个示例,训练/开发/测试比例分别为 235/104/406。平均而言,摘要长度为 57 个单词,每个摘要来自 5.3 条报告陈述。 57% 的示例有一篇来源新闻文章,26% 有 2 篇来源文章,其余 17% 有 3-5 篇来源文章。平均源组合长度为 2,065 个单词。总体而言,新闻语料库包含 633 篇文章,总共包含来自 3,725 位独特发言者的 10,762 条报道陈述。此外,我们观察到,与现有的摘要数据集相比,我们的基准中的摘要相对更加抽象。表 2 显示了新颖的 n 元语法的百分比,其中 SUMREN 包含相当高的新颖的三元语法和 4 元语法。为了解释这种相对较高的抽象性以及生成的差异,我们基准测试中的每个示例都有两个参考摘要。
3.1.3 银牌训练数据生成
考虑到与注释语句和编写摘要相关的成本,我们自动为我们的任务生成大规模银标准训练数据。具体来说,我们利用 GPT-3(Brown 等人,2020)自动生成所报告报表的抽象银标准摘要。这可以通过提示来实现(Liu et al. 2021a),其中涉及将任务分解为指令(或“提示”),然后将其与作为上下文的输入一起提供给模型。在我们的场景中,输入将是报告的陈述,并且通过我们在第 4.2 节中构建和描述的报告的语音系统自动识别说话者,提示将是“总结 <说话者> 所说的内容:”。与黄金标准数据集类似,在提示 GPT-3 生成摘要之前,将与同一说话人对应的语句分组在一起。总的来说,我们为白银训练集生成了 10,457 个示例。
3.2 Models
3.2.1以查询为中心的摘要基线
我们提出的任务需要生成所报告陈述的摘要,并给出一组新闻文章和演讲者姓名作为输入。为了利用现有模型,我们的报告语音摘要任务可以作为以查询为中心的摘要来处理——通过根据查询生成给定文本的摘要。具体来说,给定说话者的姓名,相应的查询可以表述为:“总结<说话者>所说的内容。”。接下来,我们探索多种以查询为中心的摘要方法,如下所述。
• GR-SUM(Wan 2008)使用无监督的基于图的提取方法,其中每个源句子被视为一个节点。4 它使用随机游走算法根据邻接权重和主题相关向量对输入句子进行排序每个节点。
• RelReg(Vig 等人,2022)使用两步过程。首先,使用回归模型来提取输入中与输入查询相关的连续范围。然后,提取的上下文与查询一起传递到 BART 模型以生成摘要。回归模型和 BART 模型均在 QMSum(Zhong 等人,2021a)上进行训练,QMSum 是一个以查询为中心的会议摘要数据集。 • SegEnc(Vig et al. 2022)是一种端到端生成模型,它首先将源文档分割成重叠的文本段。然后,每个片段都与输入查询连接,并由 Transformer 编码器独立编码。然后将编码片段连接成向量序列并输入 Transformer 解码器以生成摘要。该模型在 WikiSum 数据集(Liu et al. 2018)上进行预训练,并在 QMSum 数据集(Zhong et al. 2021b)上进行微调。
• GPT-3:除了这些基线之外,我们还探索直接提供源新闻文章作为GPT3 的输入并使用查询作为提示。
3.2.2 基于管道的摘要框架
我们利用基于管道的方法来总结报告的语音。拟议的管道涉及三个主要步骤; (1) 从给定的一组新闻文章中提取报道的陈述及其发言人,(2) 将来自同一发言人的陈述分组在一起,以及 (3) 为每组报道的陈述生成摘要。
报道的语音提取:给定一组新闻文章和发言人,我们的目标是识别所有报道的陈述以及相应的发言人。为此,我们构建了一个跨度标记系统,该系统利用基于 Transformer 的编码器来识别语句的跨度和相应的说话者。该模型使用 PolNeAR 语料库(Newell、Margolin 和 Ruths 2018)进行训练,该语料库提供带注释的三元组:源(即说话者)、提示(即表明归因存在的单词)和内容(即说话者所做的陈述) )用于新闻中的陈述。
给定长度为 T 的输入段落,我们使用 BERT 编码器来学习输入序列的隐藏维度 D 的表示 H ∈ RT XD。然后,我们添加一个二元分类头来识别输入段落是否包含报告的语句,并添加一个 BIO 序列标记头来识别语句和说话者的跨度。二元分类 ycls 和 token 标签 Y 跨度 i ∈ RK 概率计算如下:
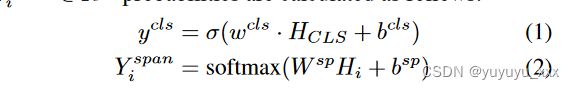
其中 wcls ∈ RD 和 W sp ∈ RK×D 是权重,bcls 和 bsp 是偏置项,K 是 BIO 标签的总数,HCLS 和 Hi 分别表示 CLS 令牌和第 i 个令牌的表示。最后,通过使用联合损失来训练模型,该模型具有多任务学习目标,该联合损失执行分类(二元交叉熵(BCE))和序列标记头(交叉熵(CE))损失的加权和。
![]()
其中 ycls 和 ˆ ycls 分别对应于预测和真实分类标签,Y sp 和 ˆ Y sp 分别表示预测和真实标记标签,α 和 β 是可调超参数。5
说话人共指分辨率
为了对演讲者的陈述进行分组,我们需要执行共指解析,因为演讲者可以通过不同的名义词(例如,拜登、乔·拜登、乔·R·拜登)和代词(例如,他)来提及。为了实现这一目标,我们利用现有的信息提取系统(Li et al. 2020),并使用 Lai、Bui 和 Kim(2022)的共同参考分辨率对其进行更新。正如我们稍后所展示的,使用共同引用解析大大增加了特定发言者报告的陈述的覆盖范围。
摘要生成:
给定演讲者的一组报告陈述,我们的目标是生成陈述的简明摘要。提取给定发言者的报告陈述的摘要生成过程类似于单文档摘要。报告的语句在作为 BART(Lewis 等人,2020)模型的输入传递之前被连接起来。在 CNN-DailyMail(Hermann 等人,2015)上训练的摘要模型首先在零样本设置中使用。然后该模型经过银级训练和金级微调,其详细信息在第 5.1 节中提供。
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
我们探索了两种微调基本摘要生成模型的方法:白银训练和黄金微调。在白银训练期间,模型根据白银标准训练数据进行微调。对于黄金微调,我们使用黄金数据添加第二个微调步骤。为了进行评估,我们使用 ROUGE(Lin 2004),并根据开发集上的 ROUGE-L 性能选择最佳模型。6 我们还报告了 BertScore(Zhang* 等人,2020),它利用了 BERT 的预训练上下文嵌入并进行匹配通过余弦相似度计算候选句子和参考句子中的单词。与测量源摘要和生成摘要之间的词汇相似性的 ROUGE 不同,BertScore 能够捕获语义相似性。
4.4评估指标
4.5 实验结果
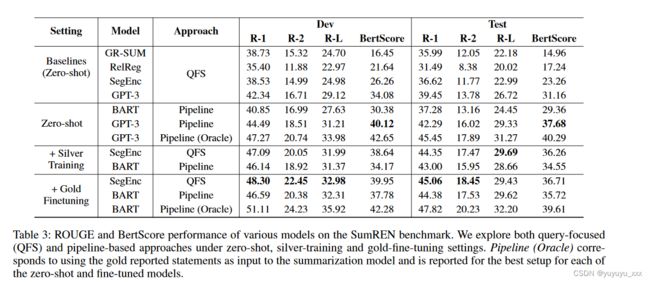
表 3 将我们提出的基于管道的方法的性能与 QFS 基线进行了比较,无论是否使用我们的白银和黄金数据进行微调。对于基线,GPT-3 表现最好,证明选择使用它是合理的用于生成银标准训练数据。我们发现,使用白银训练数据进行微调可以显着提高以查询为中心的 SegEnc 和基于管道的 BART 的性能,甚至在 ROUGE 方面优于 GPT-3。最后,我们看到模型通过对黄金人工注释训练数据进行微调进一步受益。我们还发现,使用管道方法(首先提取报告的语句,然后将其传递给 GPT-3)比将原始文章传递给 GPT-3 获得更好的分数。然而,与使用黄金数据进行微调的较小模型(SegEnc 和 BART)相比,GPT-3 的 ROUGE 分数相对较低。我们假设这可能归因于 GPT-3 生成更抽象的摘要(如表 8 所示),从而导致能够捕获语义相似性的指标得分更高。在零样本设置中,基于管道的模型大大优于以查询为中心的基线,显示了显式提取报告语句的好处。然而,在白银训练和黄金微调设置中,SegEnc 模型始终优于基于管道的模型,这表明有可能在端到端方法中隐式识别报告的语句。然而,当使用 oracle 报告的语句时,BART 超越了 SegEnc——这意味着采用更好的报告语音和共同引用解析系统将大大改善基于管道的方法。
报告的语音提取性能
接下来,我们分析所提出的报告语音提取组件的性能,以确定需要改进的领域。我们将我们的跨度标记方法与语义角色标签 (SRL) 基线进行比较,以识别报告的语句和相应的说话者,并使用提取的跨度的字符级偏移 F1 分数进行评估。 SRL 输出句子的动词谓词-论元结构,例如谁对谁做了什么。给定一个段落作为输入,我们过滤掉与一组预定义的暗示归因(例如,说,相信,否认)的线索相匹配的动词谓词,并将这些句子识别为包含报告的陈述。 7 包含 ARG-1 的句子谓词被视为报告语句,并且 ARG-0(代理)对应的跨度被用作说话人。
如表 4 所示,我们提出的跨度标记模型优于 SRL,特别是在召回率方面,这确保了摘要步骤更好地覆盖信息。我们还发现,将共同参考分辨率纳入说话人识别中可以显着提高召回率,但精度几乎相同或略低。表 5 根据 SRL 基线衡量了所提出的说话人提取跨度标记方法的性能。我们报告了字符串精确匹配和 F1 分数,这两者都常用于提取式问答(Rajpurkar et al. 2016)。我们发现,使用共指消解时,识别给定报告陈述的说话者的不同方法的性能显着提高。这对于正确地将同一发言者的发言分组在一起至关重要。
参数高效与直接微调除了完整的微调方法之外,我们还探索利用参数高效的微调方法来直接对小规模黄金训练数据进行微调。我们使用 LORA(Hu et al. 2021),这是一种高效的微调技术,可将可训练的低秩分解矩阵注入到预训练模型的各层中。表6比较了三种不同微调策略的性能,即Full FT(白银训练+黄金微调)、Gold FT(直接黄金微调)和PE FT(参数高效黄金微调)。我们发现,从 Full FT 显着优于 Gold FT 的事实可以看出,合并银标准训练数据的好处。我们还观察到,带有 LORA 的 PE FT 仅微调 0.3% 的模型参数,可以实现与 Full FT 相当的性能,同时也始终优于 Gold FT。这表明参数有效的微调是
对于我们基于管道的报告语音摘要框架有效,未来的工作可能受益于更好的 PE 方法(Liu 等人,2021b)。生成摘要的抽象性和真实性我们研究了使用白银和黄金数据进行微调对生成摘要的抽象性和真实性的影响。一般来说,摘要的抽象性和事实一致性与源输入之间存在权衡(Dreyer et al. 2021)。因此,任何抽象摘要系统的目标都是生成更多抽象摘要,同时保持与来源的高度事实一致性。对于抽象性,我们通过新颖的 n 元语法(uni、bi 和 tri-gram)的百分比以及 MINT(生成文本的词汇独立性度量)(Dreyer 等人,2021)来衡量它,这是根据生成的摘要的 n 元语法精度和最长公共子序列长度。如表 8 所示,我们发现零样本设置中的模型更具提取性,并且生成的摘要的抽象性通过白银训练和黄金微调显着增加。此外,我们注意到基于管道的方法比 QFS 方法更加抽象,这表明合并显式语句提取组件有助于摘要模型专注于将所选语句解释和合成到摘要中。为了真实性,我们使用 FactCC (Kry ́ sci ́ nski et al. 2020),Pagnoni、Balachandran 和 Tsvetkov(2021)表明,这与人类事实性标签最相关。此外,实体精度(Nan et al. 2021)是根据生成的摘要中存在于黄金报告报表中的命名实体的百分比计算的。在表 9 中,我们观察到,虽然我们提出的基于管道的方法比 QFS 基线更加抽象,但它仍然保持较高的实体精度和略高的 FactCC 分数。正如预期的那样,我们看到使用黄金(oracle)语句作为汇总步骤的输入提高了事实一致性分数。
人工评价
我们还对使用 GPT-3 通过基于管道和 QFS 方法生成的摘要进行了人体研究。我们选择 GPT-3 摘要,因为它们在 Rouge-L、BertScore 和抽象性方面始终保持高分。注释者收到摘要以及真实报告的陈述,并被要求以 1-3 的等级评估事实一致性、信息性和连贯性8。事实一致性的评价包括寻找摘要中主要或次要的事实错误,信息性是指摘要如何很好地表达了所报道的陈述的要点,连贯性主要是检查摘要是否具有良好的流畅性和事实是否以一致的方式呈现。逻辑顺序。这些注释是通过 MTurk 众包的。表 10 显示了人体研究的结果。我们发现,基于管道的方法的摘要与真实报告的陈述具有更好的事实一致性,并且信息量略有提高。与最近对大型语言模型摘要质量的观察(Goyal、Li 和 Durrett 2022;Zhang 等人 2023)相一致,我们发现基于这两种方法(均来自 GPT-3)的摘要非常好。相干。
五 总结
在这项工作中,我们引入了一项新的挑战性任务,即总结新闻中报道的言论,并发布 SUMREN 以促进该方向的更多研究。我们提出了一个基于管道的框架来总结报告的陈述,并表明所提出的方法可以生成比 QFS 更真实和抽象的摘要。未来的工作包括通过利用实体链接和合并字符级特征来实现说话者共同参考解析,从而提高报告的语音提取性能。另一个方向是通过在生成过程中添加更明确的控制来提高报告报表中显着跨度的覆盖范围。