ClickHouse初级 - 第八章 用户行为分析实际案例
文章目录
-
- 一、架构
- 二、宽表准备
- 三、事件分析
- 四、漏斗分析
- 五、路径分析
- 六、总结
前段时间基于ClickHouse实现了面向系统会员的数据洞察分析包括了事件分析、漏斗分析、路径分析。这里简单介绍一下具体的实现。
一、架构
这里先看一个简单的功能的架构,核心功能就是ClickHouse来实现分析查询。

- 上图中的行为数据一般是来自于埋点平台通过Kafka集成到ClickHouse的。
- 标签和人群数据一般是来自我们的标签系统,如离线标签一般是基于Spark计算完然后同步到ClickHouse 中。
- 这里我们不关心数据是如何进入的ClickHouse的,要做的就是如何来实现所需要的各种查询。
二、宽表准备
#1、线上集群使用副本模式
CREATE TABLE ads_user_event_analysis on cluster '{cluster}'
(
`user_id` Int64,
`event_name` String DEFAULT '',
`event_time` DateTime DEFAULT now(),
`city` String DEFAULT '',
`sex` String DEFAULT ''
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/default/ads_user_event_analysis/{shard}', '{replica}')
ORDER BY user_id
SETTINGS index_granularity = 8192
#2、本地使用docker搭建采用MergeTree引擎
CREATE TABLE ads_user_event_analysis
(
`user_id` Int64,
`event_name` String DEFAULT '',
`event_time` DateTime DEFAULT now(),
`city` String DEFAULT '',
`sex` String DEFAULT ''
)
ENGINE = MergeTree()
ORDER BY user_id
SETTINGS index_granularity = 8192
- event_name代表了用户具体的行为,如购买、下单、点击等等。
- event_time代表了事件发生的时间。
- city、sex则是用户相关的属性,这里尽量可以清洗到一张大宽表中,这样可以减少ClickHouse SQL中关联的查询。(join查询在ck中性能比较低)
三、事件分析
首先我们先来看看如何实现事件分析。

其实就是在页面配置图中的各种指标,这里展示出了一种比较简单的配置,如:
- 选择事件为下单的总次数,性别为女,并按城市分组展示事件时间范围是近一个月的情况,SQL实现如下:
insert into ads_user_event_analysis values(1,'下单','2022-11-01 01:00:40','南京','女')
insert into ads_user_event_analysis values(1,'下单','2022-11-01 01:01:40','南京','女')
insert into ads_user_event_analysis values(2,'下单','2022-11-02 02:00:40','南京','男')
insert into ads_user_event_analysis values(3,'下单','2022-11-03 03:00:40','南京','男')
insert into ads_user_event_analysis values(4,'下单','2022-11-04 04:00:40','南京','男')
insert into ads_user_event_analysis values(5,'下单','2022-11-01 01:00:40','北京','女')
insert into ads_user_event_analysis values(5,'下单','2022-11-02 04:00:40','北京','女')
insert into ads_user_event_analysis values(6,'下单','2022-11-03 03:00:40','北京','男')
insert into ads_user_event_analysis values(7,'下单','2022-11-03 02:00:40','北京','男')
--总次数
SELECT
count(1) AS cnt,
city
FROM ads_user_event_analysis
WHERE (event_name = '下单') AND (sex = '女') AND
(toDate(event_time) >= '2022-11-01') AND (toDate(event_time) <= '2022-11-30')
GROUP BY city
ORDER BY city ASC
--总用户数
SELECT count(distinct user_id) as cnt,city
FROM ads_user_event_analysis
where event_name='下单' and sex='男' and toDate(event_time)>='2022-11-01' and toDate(event_time)<='2022-11-08'
group by city
order by city
--窗口函数,可以加个序号,有必要的时候可以限制返回条数。
SELECT count(distinct user_id) as cnt,city, dense_rank() over(order by city) as rn
FROM ads_user_event_analysis
where event_name='下单' and sex='男' and toDate(event_time)>='2022-11-01' and toDate(event_time)<='2022-11-08'
group by city
order by city
- 如果设计的复杂点,页面可以一次性选择多个事件,条件筛选也可以分为对单个事件的筛选,和对选择所有事件的全局筛选。如果你想看到每天的事件分析情况,SQL还可以在对天进行分组,获取到每天的情况。只不过我们需要设计好和前端对接的JSON数据格式,以方便可视化的展示,这块也是个不小的工作。
- 需要注意的是上面的条件筛选其实需要分多个种类:包含标签和人群相关的条件,比如只针对打上某个标签的用户来分析。
四、漏斗分析
漏斗分析也是很常见的一种分析,可以直观的感受到每一步的转换流失情况。
而在ClickHouse也是提供了对应的函数,一起来看下如何实现吧。

- 和事件分析不同的是,需要先基于不同事件名称配置一个漏斗如登录->加购->购买。
- 配置窗口期,如7天则代表了一个用户只要在7天内完成了漏斗中的步骤就会被视为完成漏斗
- 条件筛选维度选择时间范围和事件分析一致。
数据准备和漏斗SQL实现:
insert into ads_user_event_analysis values(1,'登录','2022-11-01 01:00:40','南京','女')
insert into ads_user_event_analysis values(2,'登录','2022-11-01 01:01:40','南京','女')
insert into ads_user_event_analysis values(3,'登录','2022-11-01 02:00:40','南京','男')
insert into ads_user_event_analysis values(4,'登录','2022-11-01 03:00:40','南京','男')
insert into ads_user_event_analysis values(5,'登录','2022-11-01 04:00:40','南京','男')
insert into ads_user_event_analysis values(2,'加购','2022-11-02 01:00:40','南京','女')
insert into ads_user_event_analysis values(3,'加购','2022-11-02 04:00:40','南京','男')
insert into ads_user_event_analysis values(4,'加购','2022-11-02 04:00:40','南京','男')
insert into ads_user_event_analysis values(3,'购买','2022-11-03 03:00:40','南京','男')
insert into ads_user_event_analysis values(4,'购买','2022-11-03 02:00:40','南京','男')
-- 最终SQL如下:
select *,
neighbor(user_count, -1) AS prev_user_count,
if (prev_user_count = 0, -1, round(user_count / prev_user_count * 100, 3)) AS conv_rate_percent
from (
SELECT level_index,count(1) as user_count
FROM
(
SELECT user_id,
arrayWithConstant(level, 1) levels,
arrayJoin(arrayEnumerate( levels )) level_index
FROM (
SELECT
user_id,
windowFunnel(864000)(
event_time,
event_name = '登录',
event_name = '加购',
event_name = '购买'
) AS level
FROM (
SELECT event_time, event_name , user_id as user_id
FROM ads_user_event_analysis
WHERE toDate(event_time) >= '2022-11-01' and toDate(event_time)<='2022-11-30' and event_name in('登录','加购','购买')
)
GROUP BY user_id)
)
group by level_index
ORDER BY
level_index
)
SQL结果就可以得到我们想要的:
漏斗顺序 当前步骤用户量 上一步步骤用户量 转化率
┌─level_index─┬─user_count─┬─prev_user_count─┬─conv_rate_percent─┐
│ 1 │ 5 │ 0 │ -1 │
│ 2 │ 3 │ 5 │ 60 │
│ 3 │ 2 │ 3 │ 66.667 │
└─────────────┴────────────┴─────────────────┴───────────────────┘
--如果需要按维度比如性别则SQL中group by新增字段即可
select *,
neighbor(user_count, -1) AS prev_user_count,
if (prev_user_count = 0, -1, round(user_count / prev_user_count * 100, 3)) AS conv_rate_percent
from (
SELECT level_index,count(1) as user_count ,sex
FROM
(
SELECT user_id,sex,
arrayWithConstant(level, 1) levels,
arrayJoin(arrayEnumerate( levels )) level_index
FROM (
SELECT
user_id,sex, windowFunnel(864000)(
event_time,
event_name = '登录',
event_name = '加购',
event_name = '购买'
) AS level
FROM (
SELECT event_time, event_name , user_id as user_id ,sex
FROM ads_user_event_analysis
WHERE toDate(event_time) >= '2022-11-01' and toDate(event_time)<='2022-11-30' and event_name in('登录','加购','购买')
)
GROUP BY sex,user_id)
)
group by sex,level_index
ORDER BY sex, level_index
)
┌─level_index─┬─user_count─┬─sex─┬─prev_user_count─┬─conv_rate_percent─┐
│ 1 │ 2 │ 女 │ 0 │ -1 │
│ 2 │ 1 │ 女 │ 2 │ 50 │
│ 1 │ 3 │ 男 │ 1 │ 300 │
│ 2 │ 2 │ 男 │ 3 │ 66.667 │
│ 3 │ 2 │ 男 │ 2 │ 100 │
└─────────────┴────────────┴─────┴─────────────────┴───────────────────┘
这里需要注意的是给前端的数据需要把level_index=1的 prev_user_count和conv_rate_percent调整一下.第一个步骤可以默认都是1或者100%
通过结果我们可以看到漏斗中每一步的人数,以及转化率。 上面的SQL中有几个函数说明:
1)arrayWithConstant:生成一个指定长度的数组
SELECT arrayWithConstant(3, 'level')
Query id: 016115fb-71af-4fda-983c-34c221cffc6f
┌─arrayWithConstant(3, 'level')─┐
│ ['level','level','level'] │
└───────────────────────────────┘
2)arrayEnumerate: 返回数组下标等同于 Hive中 ROW_NUMBER
3)arrayJoin:行转列
4)neighbor:获取某一列前后相邻的数据。
五、路径分析
路径分析较为复杂,看下整体流程
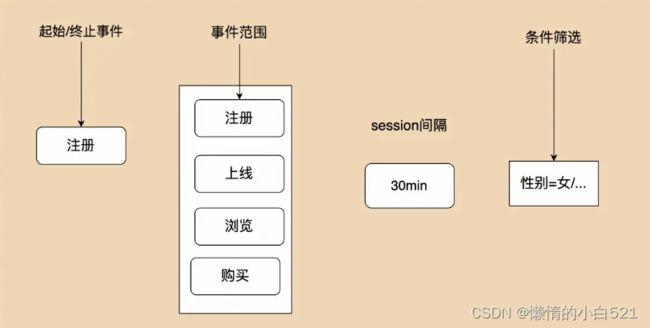
我们需要做的就是选择路径的起始或者终止事件,并且定义整个路径所有的事件范围。然后选择路径需要的session间隔。如果有条件筛选同样需要支持。
我们先准备相关的数据
insert into ads_user_event_analysis values(1,'注册','2022-11-01 01:00:40','南京','女')
insert into ads_user_event_analysis values(1,'上线','2022-11-01 01:01:40','南京','女')
insert into ads_user_event_analysis values(1,'浏览','2022-11-01 01:02:40','南京','女')
insert into ads_user_event_analysis values(1,'购买','2022-11-01 01:03:40','南京','女')
insert into ads_user_event_analysis values(2,'注册','2022-11-01 01:02:40','南京','男')
insert into ads_user_event_analysis values(2,'上线','2022-11-01 01:03:40','南京','男')
insert into ads_user_event_analysis values(2,'购买','2022-11-01 01:04:40','南京','男')
insert into ads_user_event_analysis values(2,'浏览','2022-11-01 01:00:45','南京','男')
可以看到两个用户的路径分别是
- 用户1:注册 -> 上线 -> 浏览 -> 购买
- 用户2: 注册 -> 上线 -> 购买 (最后一条数据不属于一个session了)
基于SQL实现:
select * from (
WITH toUInt32(
minIf(
event_time,
event_name = '注册'
)
) AS end_event_maxt,arrayCompact(
arraySort(
x ->
x.1,
arrayFilter(
x -> x.1 >= end_event_maxt,
groupArray((toUInt32(event_time), event_name))
)
)
) AS sorted_events,
arrayEnumerate(sorted_events) AS event_idxs,
arrayFilter(
(x, y, z) -> z.1 >= end_event_maxt
AND (
z.2 = '登录'
or y > '600'
),
event_idxs,
arrayDifference(sorted_events.1),
sorted_events
) AS gap_idxs,
arrayMap(x -> x, gap_idxs) AS gap_idxs_,
arrayMap(x -> if(has(gap_idxs_, x), 1, 0), event_idxs) AS gap_masks,
arraySplit((x, y) -> y, sorted_events, gap_masks) AS split_events
SELECT user_id,
arrayJoin(split_events) AS event_chain_,
arrayCompact(event_chain_.2) AS event_chain,
arrayStringConcat(
event_chain,
' -> '
) AS result_chain,
event_chain[1] AS page1,
event_chain[2] AS page2,
event_chain[3] AS page3,
event_chain[4] AS page4,
event_chain[5] AS page5 FROM (SELECT event_time, event_name , user_id as user_id
FROM ads_user_event_analysis
WHERE 1=1 and toDate(event_time) >= '2022-11-01' and toDate(event_time)<='2022-11-04'
and event_name in ('注册','上线','浏览','购买')) t group by user_id
) WHERE event_chain[1] = '注册'
┌─user_id─┬─event_chain_──────────────────────────────────────────────────────────────────────┬─event_chain───────────────────┬─result_chain─────────────────┬─page1─┬─page2─┬─page3─┬─page4─┬─page5─┐
│ 2 │ [(1667264560,'注册'),(1667264620,'上线'),(1667264680,'购买')] │ ['注册','上线','购买'] │ 注册 -> 上线 -> 购买 │ 注册 │ 上线 │ 购买 │ │ │
│ 1 │ [(1667264440,'注册'),(1667264500,'上线'),(1667264560,'浏览'),(1667264620,'购买')] │ ['注册','上线','浏览','购买'] │ 注册 -> 上线 -> 浏览 -> 购买 │ 注册 │ 上线 │ 浏览 │ 购买 │ │
└─────────┴───────────────────────────────────────────────────────────────────────────────────┴───────────────────────────────┴──────────────────────────────┴───────┴───────┴───────┴───────┴───────┘
上面我们已经获取到了每个用户的路径信息,但是仅仅这些在页面展示是不够的,还需要获取到每个路径有多少人,到下一个事件流转了多少人。这时候我们可以借助窗口函数来实现一个可以给前端交互使用的返回
SELECT arrayDistinct(groupArray([concat(page1, '_', toString(page1_cnt),'_',toString(page1_user))])) AS page1,
arrayDistinct(groupArray([concat(page2, '_', toString(page2_cnt),'_',toString(page2_user))])) AS page2,
arrayDistinct(groupArray([concat(page3, '_', toString(page3_cnt),'_',toString(page3_user))])) AS page3,
arrayDistinct(groupArray([concat(page4, '_', toString(page4_cnt),'_',toString(page4_user))])) AS page4,
arrayDistinct(groupArray([concat(page5, '_', toString(page5_cnt),'_',toString(page5_user))])) AS page5,
arrayDistinct(groupArray([concat(link1_2, '_', toString(link1_2_cnt),'_',toString(link1_2_user))])) AS link1_2,
arrayDistinct(groupArray([concat(link2_3, '_', toString(link2_3_cnt),'_',toString(link2_3_user))])) AS link2_3,
arrayDistinct(groupArray([concat(link3_4, '_', toString(link3_4_cnt),'_',toString(link3_4_user))])) AS link3_4,
arrayDistinct(groupArray([concat(link4_5, '_', toString(link4_5_cnt),'_',toString(link4_5_user))])) AS link4_5 FROM (
SELECT page1,sum(1) OVER (PARTITION BY page1) AS page1_cnt,count(distinct user_id) OVER (PARTITION BY page1) As page1_user,
page2,sum(1) OVER (PARTITION BY page2) AS page2_cnt,count(distinct user_id) OVER (PARTITION BY page2) As page2_user,
page3,sum(1) OVER (PARTITION BY page3) AS page3_cnt,count(distinct user_id) OVER (PARTITION BY page3) As page3_user,
page4,sum(1) OVER (PARTITION BY page4) AS page4_cnt,count(distinct user_id) OVER (PARTITION BY page4) As page4_user,
page5,sum(1) OVER (PARTITION BY page5) AS page5_cnt,count(distinct user_id) OVER (PARTITION BY page5) As page5_user,
concat(page1, '->', page2) AS link1_2,sum(1) OVER (PARTITION BY page1, page2) AS link1_2_cnt,count(distinct user_id) OVER (PARTITION BY page1, page2) AS link1_2_user,
concat(page2, '->', page3) AS link2_3,sum(1) OVER (PARTITION BY page2, page3) AS link2_3_cnt,count(distinct user_id) OVER (PARTITION BY page2, page3) AS link2_3_user,
concat(page3, '->', page4) AS link3_4,sum(1) OVER (PARTITION BY page3, page4) AS link3_4_cnt,count(distinct user_id) OVER (PARTITION BY page3, page4) AS link3_4_user,
concat(page4, '->', page5) AS link4_5,sum(1) OVER (PARTITION BY page4, page5) AS link4_5_cnt,count(distinct user_id) OVER (PARTITION BY page4, page5) AS link4_5_user FROM (
select * from (
WITH toUInt32(
minIf(
event_time,
event_name = '注册'
)
) AS end_event_maxt,arrayCompact(
arraySort(
x ->
x.1,
arrayFilter(
x -> x.1 >= end_event_maxt,
groupArray((toUInt32(event_time), event_name))
)
)
) AS sorted_events,
arrayEnumerate(sorted_events) AS event_idxs,
arrayFilter(
(x, y, z) -> z.1 >= end_event_maxt
AND (
z.2 = '登录'
or y > '600'
),
event_idxs,
arrayDifference(sorted_events.1),
sorted_events
) AS gap_idxs,
arrayMap(x -> x, gap_idxs) AS gap_idxs_,
arrayMap(x -> if(has(gap_idxs_, x), 1, 0), event_idxs) AS gap_masks,
arraySplit((x, y) -> y, sorted_events, gap_masks) AS split_events
SELECT user_id,
arrayJoin(split_events) AS event_chain_,
arrayCompact(event_chain_.2) AS event_chain,
arrayStringConcat(
event_chain,
' -> '
) AS result_chain,
event_chain[1] AS page1,
event_chain[2] AS page2,
event_chain[3] AS page3,
event_chain[4] AS page4,
event_chain[5] AS page5 FROM (SELECT event_time, event_name , user_id as user_id
FROM ads_user_event_analysis
WHERE 1=1 and toDate(event_time) >= '2022-11-01' and toDate(event_time)<='2022-11-04'
and event_name in ('注册','上线','浏览','购买')) t group by user_id
) WHERE event_chain[1] = '注册'
) AS t) AS t
┌─page1──────────┬─page2──────────┬─page3───────────────────────┬─page4───────────────────┬─page5──────┬─link1_2──────────────┬─link2_3─────────────────────────────────┬─link3_4─────────────────────────────┬─link4_5─────────────────────┐
│ [['注册_2_2']] │ [['上线_2_2']] │ [['购买_1_1'],['浏览_1_1']] │ [['_1_1'],['购买_1_1']] │ [['_2_2']] │ [['注册->上线_2_2']] │ [['上线->购买_1_1'],['上线->浏览_1_1']] │ [['购买->_1_1'],['浏览->购买_1_1']] │ [['->_1_1'],['购买->_1_1']] │
└────────────────┴��───────────────┴─────────────────────────────┴─────────────────────────┴────────────┴──────────────────────┴─────────────────────────────────────────┴─────────────────────────────────────┴─────────────────────────────┘
上面的结果中page数组代表了当前层级有哪些事件,link则维护了前后两个路径的关系。有了这些数据,大家就可以想办法展示到前端页面了。
六、总结
到此我们已经完成了基于ClickHouse最常见的的一些事件分析功能。最主要还是介绍了SQL的实现。其中缺少了标签画像相关的条件,这些内容则需要根据公司标签群组具体是表结构来实现SQL,最终可以通过in语句来将标签或者人群的数据当做条件。最后还有一大部分工作则是在前端交互的代码开发上,需要设计好返回的JSON。但是有了上面的基础,相信这些对你来说只是时间问题。
clickhouse常见用户行为分析案例如下:
- 事件分析
- 路径分析
- session分析
- 漏斗分析
- 留存分析
- …
借鉴地址
进一步案例sql查看