大数据机器学习:从理论到实战,探索学习率的调整策略
大数据机器学习:从理论到实战,探索学习率的调整策略
全文目录
- 大数据机器学习:从理论到实战,探索学习率的调整策略
- 一、引言
- 二、学习率基础
-
- 定义与解释
- 学习率与梯度下降
- 学习率对模型性能的影响
- 三、学习率调整策略
-
- 常量学习率
- 时间衰减
- 自适应学习率
-
- AdaGrad
- RMSprop
- Adam
- 四、学习率的代码实战
-
- 环境设置
- 数据和模型
- 常量学习率
- 时间衰减
- Adam优化器
- 五、学习率的最佳实践
-
- 学习率范围测试
- 循环学习率(Cyclical Learning Rates)
- 学习率热重启(Learning Rate Warm Restart)
- 梯度裁剪与学习率
- 使用预训练模型和微调学习率
- 六、总结
本文全面深入地探讨了机器学习和深度学习中的学习率概念,以及其在模型训练和优化中的关键作用。文章从学习率的基础理论出发,详细介绍了多种高级调整策略,并通过Python和PyTorch代码示例提供了实战经验。
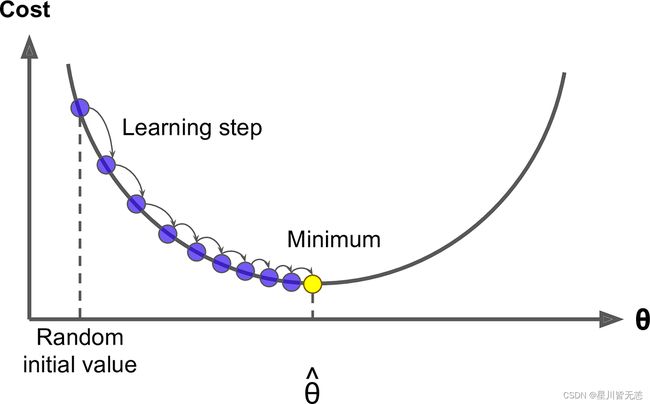
一、引言
学习率(Learning Rate)是机器学习和深度学习中一个至关重要的概念,它直接影响模型训练的效率和最终性能。简而言之,学习率控制着模型参数在训练过程中的更新幅度。一个合适的学习率能够在确保模型收敛的同时,提高训练效率。然而,学习率的选择并非易事;过高或过低的学习率都可能导致模型性能下降或者训练不稳定。
在传统的机器学习算法中,例如支持向量机(SVM)和随机森林(Random Forest),参数优化通常是通过解析方法或者贪心算法来完成的,因此学习率的概念相对较少涉及。但在涉及优化问题和梯度下降(Gradient Descent)的方法中,例如神经网络,学习率成了一个核心的调节因子。

学习率的选择对于模型性能有着显著影响。在实践中,不同类型的问题和数据集可能需要不同的学习率或者学习率调整策略。因此,了解如何合适地设置和调整学习率,是每一个机器学习从业者和研究者都需要掌握的基础知识。
这个领域的研究已经从简单的固定学习率扩展到了更为复杂和高级的自适应学习率算法,如 AdaGrad、RMSprop 和 Adam 等。这些算法试图在训练过程中动态地调整学习率,以适应模型和数据的特性,从而达到更好的优化效果。
综上所述,学习率不仅是一个基础概念,更是一个充满挑战和机会的研究方向,具有广泛的应用前景和深远的影响。在接下来的内容中,我们将深入探讨这一主题,从基础理论到高级算法,再到实际应用和最新研究进展。
二、学习率基础
学习率(Learning Rate)在优化算法,尤其是梯度下降和其变体中,扮演着至关重要的角色。它影响着模型训练的速度和稳定性,并且是实现模型优化的关键参数之一。本章将从定义与解释、学习率与梯度下降、以及学习率对模型性能的影响等几个方面,详细地介绍学习率的基础知识。
定义与解释
学习率通常用符号 (\alpha) 表示,并且是一个正实数。它用于控制优化算法在更新模型参数时的步长。具体地,给定一个损失函数 ( J(\theta) ),其中 ( \theta ) 是模型的参数集合,梯度下降算法通过以下公式来更新这些参数:

学习率与梯度下降
学习率在不同类型的梯度下降算法中有不同的应用和解释。最常见的三种梯度下降算法是:
- 批量梯度下降(Batch Gradient Descent)
- 随机梯度下降(Stochastic Gradient Descent, SGD)
- 小批量梯度下降(Mini-batch Gradient Descent)
在批量梯度下降中,学习率应用于整个数据集,用于计算损失函数的平均梯度。而在随机梯度下降和小批量梯度下降中,学习率应用于单个或一小批样本,用于更新模型参数。
随机梯度下降和小批量梯度下降由于其高度随机的性质,常常需要一个逐渐衰减的学习率,以帮助模型收敛。
学习率对模型性能的影响
选择合适的学习率是非常重要的,因为它会直接影响模型的训练速度和最终性能。具体来说:
- 过大的学习率:可能导致模型在最优解附近震荡,或者在极端情况下导致模型发散。
- 过小的学习率:虽然能够保证模型最终收敛,但是会大大降低模型训练的速度。有时,它甚至可能导致模型陷入局部最优解。
实验表明,不同的模型结构和不同的数据集通常需要不同的学习率设置。因此,实践中常常需要多次尝试和调整,或者使用自适应学习率算法。
综上,学习率是机器学习中一个基础但复杂的概念。它不仅影响模型训练的速度,还会影响模型的最终性能。因此,理解学习率的基础知识和它在不同情境下的应用,对于机器学习的实践和研究都是非常重要的。
三、学习率调整策略
学习率的调整策略是优化算法中一个重要的研究领域。合适的调整策略不仅能够加速模型的收敛速度,还能提高模型的泛化性能。在深度学习中,由于模型通常包含大量的参数和复杂的结构,选择和调整学习率变得尤为关键。本章将详细介绍几种常用的学习率调整策略,从传统方法到现代自适应方法。
常量学习率
最简单的学习率调整策略就是使用一个固定的学习率。这是最早期梯度下降算法中常用的方法。虽然实现简单,但常量学习率往往不能适应训练动态,可能导致模型过早地陷入局部最优或者在全局最优点附近震荡。
时间衰减
时间衰减策略是一种非常直观的调整方法。在这种策略中,学习率随着训练迭代次数的增加而逐渐减小。公式表示为:

自适应学习率
自适应学习率算法试图根据模型的训练状态动态调整学习率。以下是一些广泛应用的自适应学习率算法:
AdaGrad

RMSprop

Adam

综上,学习率调整策略不仅影响模型训练的速度,还决定了模型的收敛性和泛化能力。选择合适的学习率调整策略是优化算法成功应用的关键之一。
四、学习率的代码实战
在实际应用中,理论知识是不够的,还需要具体的代码实现来实验和验证各种学习率调整策略的效果。本节将使用Python和PyTorch来展示如何实现前文提到的几种学习率调整策略,并在一个简单的模型上进行测试。
环境设置
首先,确保你已经安装了PyTorch。如果没有,可以使用以下命令进行安装:
pip install torch
数据和模型
为了方便演示,我们使用一个简单的线性回归模型和生成的模拟数据。
import torch
import torch.nn as nn
import torch.optim as optim
# 生成模拟数据
x = torch.rand(100, 1) * 10 # shape=(100, 1)
y = 2 * x + 3 + torch.randn(100, 1) # y = 2x + 3 + noise
# 线性回归模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
model = LinearRegression()
常量学习率
使用固定的学习率进行优化。
# 使用SGD优化器和常数学习率
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(100):
outputs = model(x)
loss = nn.MSELoss()(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
在这里,我们使用了常量学习率0.01,并没有进行任何调整。
时间衰减
应用时间衰减调整学习率。
# 初始化参数
lr = 0.1
gamma = 0.1
decay_rate = 0.95
# 使用SGD优化器
optimizer = optim.SGD(model.parameters(), lr=lr)
# 训练模型
for epoch in range(100):
outputs = model(x)
loss = nn.MSELoss()(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新学习率
lr = lr * decay_rate
for param_group in optimizer.param_groups:
param_group['lr'] = lr
print(f'Epoch {epoch+1}, Learning Rate: {lr}, Loss: {loss.item()}')
这里我们使用了一个简单的时间衰减策略,每个epoch后将学习率乘以0.95。
Adam优化器
使用自适应学习率的Adam优化器。
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(100):
outputs = model(x)
loss = nn.MSELoss()(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
Adam优化器会自动调整学习率,因此我们不需要手动进行调整。
在这几个例子中,你可以明显看到学习率调整策略如何影响模型的训练过程。选择适当的学习率和调整策略是实现高效训练的关键。这些代码示例提供了一个出发点,但在实际应用中,通常需要根据具体问题进行更多的调整和优化。
五、学习率的最佳实践
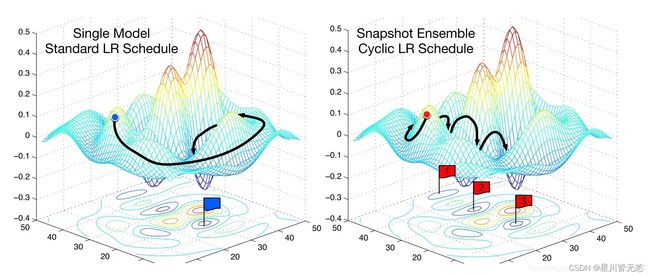
在深度学习中,选择合适的学习率和调整策略对模型性能有着巨大的影响。本节将探讨一些学习率的最佳实践,每个主题后都会提供具体的例子来增加理解。
学习率范围测试
定义: 学习率范围测试是一种经验性方法,用于找出模型训练中较优的学习率范围。
例子: 你可以从一个非常小的学习率(如0.0001)开始,每个mini-batch或epoch后逐渐增加,观察模型的损失函数如何变化。当损失函数开始不再下降或开始上升时,就可以找出一个合适的学习率范围。
循环学习率(Cyclical Learning Rates)
定义: 循环学习率是一种策略,其中学习率会在一个预定义的范围内周期性地变化。
例子: 你可以设置学习率在0.001和0.1之间循环,周期为10个epochs。这种方法有时能更快地收敛,尤其是当你不确定具体哪个学习率值是最佳选择时。
学习率热重启(Learning Rate Warm Restart)
定义: 在每次达到预设的训练周期后,将学习率重置为较高的值,以重新“激活”模型的训练。
例子: 假设你设置了一个周期为20个epochs的学习率衰减策略,每次衰减到较低的值后,你可以在第21个epoch将学习率重置为一个较高的值(如初始值的0.8倍)。
梯度裁剪与学习率
定义: 梯度裁剪是在优化过程中限制梯度的大小,以防止因学习率过大而导致的梯度爆炸。
例子: 在某些NLP模型或RNN模型中,由于梯度可能会变得非常大,因此采用梯度裁剪和较小的学习率通常更为稳妥。
使用预训练模型和微调学习率
定义: 当使用预训练模型(如VGG、ResNet等)时,微调学习率是非常关键的。通常,预训练模型的顶层(或自定义层)会使用更高的学习率,而底层会使用较低的学习率。
例子: 如果你在一个图像分类任务中使用预训练的ResNet模型,可以为新添加的全连接层设置较高的学习率(如0.001),而对于预训练模型的其他层则可以设置较低的学习率(如0.0001)。
总体而言,学习率的选择和调整需要根据具体的应用场景和模型需求来进行。这些最佳实践提供了一些通用的指导方针,但最重要的还是通过不断的实验和调整来找到最适合你模型和数据的策略。
六、总结
学习率不仅是机器学习和深度学习中的一个基础概念,而且是模型优化过程中至关重要的因素。尽管其背后的数学原理相对直观,但如何在实践中有效地应用和调整学习率却是一个充满挑战的问题。本文从学习率的基础知识出发,深入探讨了各种调整策略,并通过代码实战和最佳实践为读者提供了全面的指导。
- 自适应优化与全局最优:虽然像Adam这样的自适应学习率方法在很多情况下表现出色,但它们不一定总是能找到全局最优解。在某些需要精确优化的应用中(如生成模型),更加保守的手动调整学习率或者更复杂的调度策略可能会更有效。
- 复杂性与鲁棒性的权衡:更复杂的学习率调整策略(如循环学习率、学习率热重启)虽然能带来更快的收敛,但同时也增加了模型过拟合的风险。因此,在使用这些高级策略时,配合其他正则化技术(如Dropout、权重衰减)是非常重要的。
- 数据依赖性:学习率的最佳设定和调整策略高度依赖于具体的数据分布。例如,在处理不平衡数据集时,较低的学习率可能更有助于模型学习到少数类的特征。
- 模型复杂性与学习率:对于更复杂的模型(如深层网络或者Transformer结构),通常需要更精细的学习率调控。这不仅因为复杂模型有更多的参数,还因为它们的优化面通常更为复杂和崎岖。
通过深入地理解学习率和其在不同场景下的应用,我们不仅可以更高效地训练模型,还能在模型优化的过程中获得更多关于数据和模型结构的洞见。总之,掌握学习率的各个方面是任何希望在机器学习领域取得成功的研究者或工程师必须面对的挑战之一。