基于YOLOv8的结核病预测系统设计与实现
一、项目背景
本系统的目的是通过痰液图像来检测出结核杆菌的携带者,及时采取治疗措施,在病情早期对其进行相关治疗减少结核病的传播。程序使用的样本是经过染色处理可以使得结核杆菌在显微镜拍摄的医学图像,通过检测医学图像中的结核杆菌诊断检测该样本的所属者是否患有结核病;为了减少医生的工作量,我们通过构建准确的目标检测模型辅助医生进行检测工作,只需将显微镜拍摄的医学图像交给计算机,让计算机自动预测图像中是否含有结合杆菌,并将预测结果呈现给医生,为医生诊断病情提供决策依据,缩短诊断病情的时间,提高病情诊断准确率。
该项目使用深度学习主流框架PyTorch和目标检测领域的主流检测算法YoloV8实现,通过后端Flask以及前端Vue2搭建Web端系统,实现结核病智能诊断平台的设计与开发。
在保证模型准确率的前提下,我们进行了web页面的设计,用户只需将所要预测的图片上传,并稍等片刻就可以看到某样本的预测结果,只需对有异常的样本进行二次分析即可。实现了即使是不懂医学的用户也可以对样本轻松地进行预测,从真正意义上减轻了医务工作人员的压力。
将此技术应用于目前的医疗检测产品中能够满足真实的结核病检测需求,实现“AI+医疗”,为产业赋能。
二、实现思路
2.1 算法原理
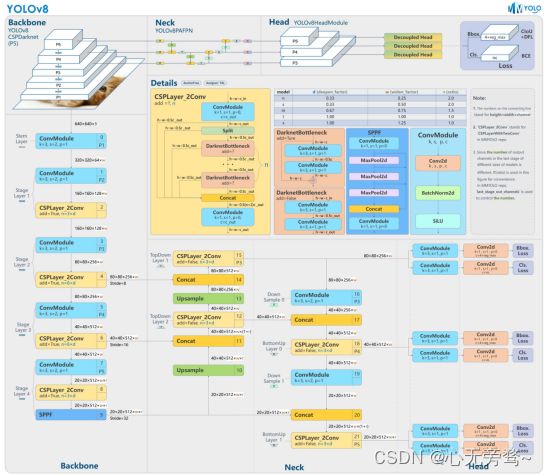
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
具体到 YOLOv8 算法,其核心特性和改动可以归结为如下:
- 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
- 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
- Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
- Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过 Ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 Ultralytics 这个词,原因是 Ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。
YOLOv8的算法原理可以概括为以下几个步骤:
- 分割图片:YOLOv8首先将输入图片分割为a×a个grid,每个grid的大小相等。不同于之前的滑窗法让每个框只能识别出一个物体,且要求这个物体必须在这个框之内,YOLOv8只要求物体的中心落在这个grid中,这使得算法不需要设计非常大的框来框住占用较多像素块的目标。
- 基于grid生成bounding box:每个grid都预测出B个bounding box,每个bounding box包含5个值,分别是物体的中心位置(x,y)、高(h)、宽(w)以及这次预测的置信度。每个grid还要负责预测这个框中的物体是什么类别的,这里的类别用one-hot编码表示。
- 损失函数的设计:YOLOv8的损失函数由两部分构成,一部分是坐标预测的损失,也就是预测出的bounding box中心位置和大小的损失;另一部分是类别预测的损失,也就是预测出的物体类别的损失。
- 预测阶段:在预测阶段,YOLOv8将输入的图片经过一次神经网络的前向传播,就可以得到每个grid预测的bounding box和类别概率,然后通过非极大值抑制(NMS)算法去除多余的框,得到最终的预测结果。
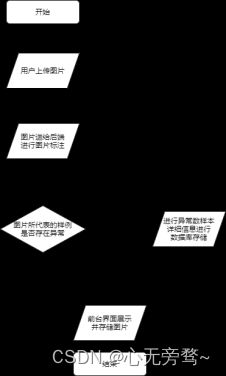
2.2 程序流程图
三、系统设计与实现
3.1 系统设计
系统设计主要使用Vue和Flask技术,在电脑本地建立了前端项目主要包含src文件夹(用于存储图片、logo、以及网页样式等信息)、public文件夹(用于存储web页面骨架)需要首先创建front-end文件夹,并将前端项目代码放进去。后端采用的是python flask框架,创建的文件夹core下用于存储端主模块以及预处理数据集模块、预测模块、model文件夹用于存储训练模型的权重。这样前端发出POST请求时,会对上传的图像进行处理。需要先创建back-end文件夹,将后端代码放进去。
3.2 数据集获取
在Automated laboratory diagnostics上搜集了一些显微镜拍摄的结核杆菌图像。该数据集全部与结核有关,取自痰液样本。它包含1265个痰液图像以及3734个细菌的边界框。XML文件包含图像的边界框详细信息。

3.3 模型设计
模型设计方面,我首先采用的是最主流的深度学习框架PyTorch,检测算法模型采用的是最新的YOLOv8。YOLOv8和YOLOv5是同一个作者,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身。
YOLOv8的网络结构设计,在暂时不考虑Head情况下,对比YOLOv5和YOLOv8的yaml配置文件可以发现改动较小:
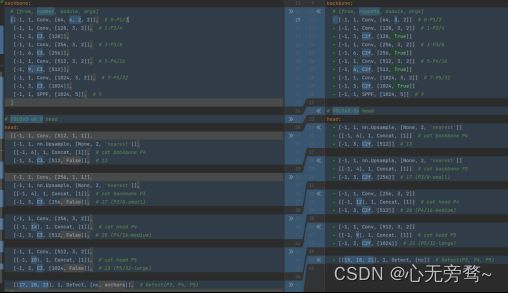
左侧为 YOLOv5-s,右侧为 YOLOv8-s。
骨干网络和 Neck 的具体变化为:
- 第一个卷积层的 kernel 从 6x6 变成了 3x3
- 所有的 C3 模块换成 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作
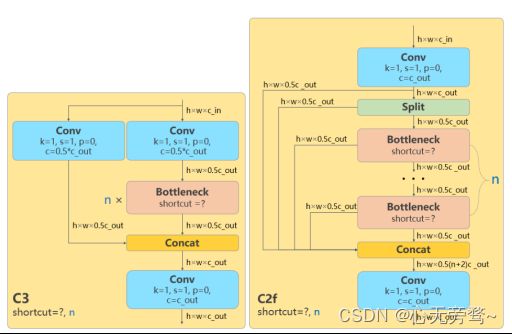
- 去掉了 Neck 模块中的 2 个卷积连接层
- Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
- 查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型。
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:
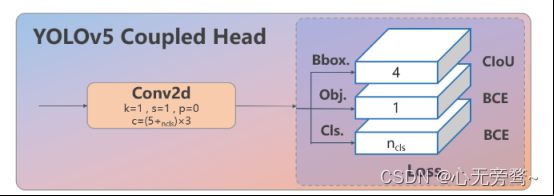
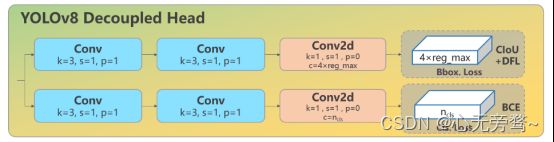
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
3.4 模型评估与优化
YOLOv8 和 YOLOv5 之间的综合比较:
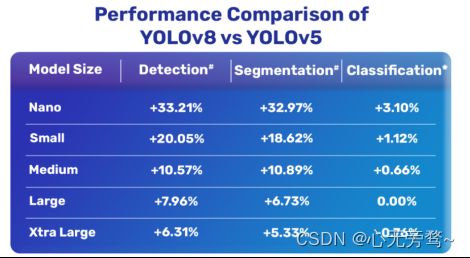
YOLOv8 和 YOLOv5 目标检测模型对比:

模型优化(增加SE注意力模块):
Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。这个结构是2017 ILSVR竞赛的冠军,top5的错误率达到了2.251%,比2016年的第一名还要低25%,可谓提升巨大。
SE是指"Squeeze-and-Excitation",是一种用于增强卷积神经网络(CNN)的注意力机制。SE网络结构由Jie Hu等人在2018年提出,其核心思想是在卷积神经网络中引入一个全局的注意力机制,以自适应地学习每个通道的重要性。
SE网络通过两个步骤来实现注意力机制:压缩和激励。在压缩步骤中,SE网络会对每个通道的特征图进行全局池化,将其压缩成一个标量。在激励步骤中,SE网络会通过一个全连接层,将压缩后的特征向量转换为一个权重向量,用于对每个通道的特征图进行加权。
通过引入SE模块,CNN可以自适应地学习每个通道的重要性,从而提高模型的表现能力。SE网络在多个图像分类任务中取得了很好的效果,并被广泛应用于各种视觉任务中。

yaml文件如下:
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, SEAttention, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, SEAttention, [256]] # 17 (P5/32-large)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, SEAttention, [512]] # 21 (P5/32-large)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 24 (P5/32-large)
- [-1, 1, SEAttention, [1024]] # 25 (P5/32-large)
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
SE注意力模=模块代码如下:
3.import numpy as np
4.import torch
5.from torch import nn
6.from torch.nn import init
7.
8.
9.class SEAttention(nn.Module):
10.
11. def __init__(self, channel=512,reduction=16):
12. super().__init__()
13. self.avg_pool = nn.AdaptiveAvgPool2d(1)
14. self.fc = nn.Sequential(
15. nn.Linear(channel, channel // reduction, bias=False),
16. nn.ReLU(inplace=True),
17. nn.Linear(channel // reduction, channel, bias=False),
18. nn.Sigmoid()
19. )
20.
21.
22. def init_weights(self):
23. for m in self.modules():
24. if isinstance(m, nn.Conv2d):
25. init.kaiming_normal_(m.weight, mode='fan_out')
26. if m.bias is not None:
27. init.constant_(m.bias, 0)
28. elif isinstance(m, nn.BatchNorm2d):
29. init.constant_(m.weight, 1)
30. init.constant_(m.bias, 0)
31. elif isinstance(m, nn.Linear):
32. init.normal_(m.weight, std=0.001)
33. if m.bias is not None:
34. init.constant_(m.bias, 0)
35.
36. def forward(self, x):
37. b, c, _, _ = x.size()
38. y = self.avg_pool(x).view(b, c)
39. y = self.fc(y).view(b, c, 1, 1)
40. return x * y.expand_as(x)
41.###################### SENet #### end ###############################
将以上代码加入加入ultralytics/nn/attention/attention.py中,然后修改tasks.py文件。
函数def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)进行修改:
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3,SEAttention):
c1, c2 = ch[f], args[0]
改进后的网络结构图如下:
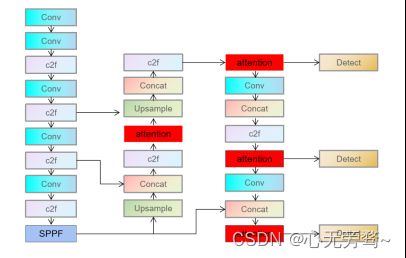
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件。
各损失函数作用说明:
- 定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
- 分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
- 动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
Yolov8原结构训练结果如下图:
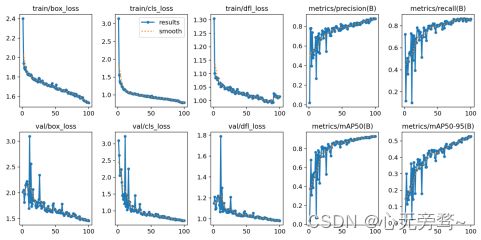
Yolov8增加SE模块训练结果如下图:

通过上面的训练结果图我们可以清楚的发现,改进后的yolov8无论是精度还是召回率方面,都比原结构有较大的提升。
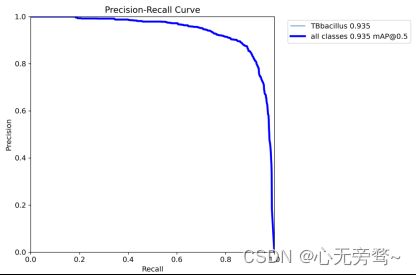
我们通常用PR曲线来体现精确率和召回率的关系,本次大作业训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。[email protected]:表示阈值大于0.5的平均mAP,可以看到本文模型两类目标检测的[email protected]已经达到了0.93以上,平均值为0.935,结果还是很不错的。
四、系统测试
Web系统界面:
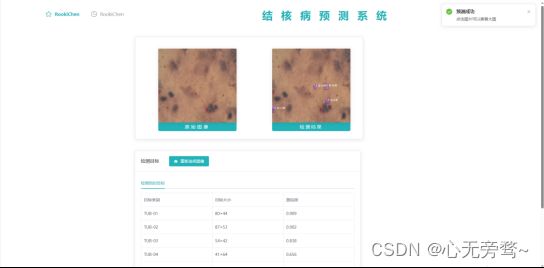
预测结果:

Qt界面检测软件:

章节回顾
文章目录
- 一、项目背景
- 二、实现思路
-
- 2.1 算法原理
- 2.2 程序流程图
- 三、系统设计与实现
-
- 3.1 系统设计
- 3.2 数据集获取
-
- 3.3 模型设计
- 3.4 模型评估与优化
- 四、系统测试