Flink CDC 系列 - 同步 MySQL 分库分表,构建 Iceberg 实时数据湖
一、背景介绍
在 OLTP 系统中,为了解决单表数据量大的问题,通常采用分库分表的方式将单个大表进行拆分以提高系统的吞吐量。
但是为了方便数据分析,通常需要将分库分表拆分出的表在同步到数据仓库、数据湖时,再合并成一个大表。
这篇教程将展示如何使用 Flink CDC 构建实时数据湖来应对这种场景,本教程的演示基于 Docker,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE,你可以很方便地在自己的电脑上完成本教程的全部内容。
接下来将以数据从 MySQL 同步到 Iceberg[1] 为例展示整个流程,架构图如下所示:
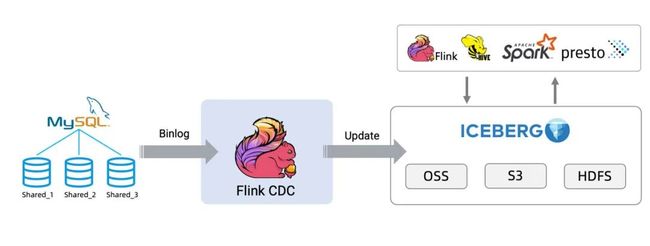
一、准备阶段 MySQL数据
1.2 准备数据
进入 MySQL 容器中:
创建两个不同的数据库,并在每个数据库中创建两个表,作为 user 表分库分表下拆分出的表。
CREATE DATABASE db_1;
USE db_1;
CREATE TABLE user_1 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234","[email protected]");
CREATE TABLE user_2 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_2 VALUES (120,"user_120","Shanghai","123567891234","[email protected]");CREATE DATABASE db_2;
USE db_2;
CREATE TABLE user_1 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234", NULL);
CREATE TABLE user_2 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_2 VALUES (220,"user_220","Shanghai","123567891234","[email protected]");二、在 Flink SQL CLI 中
使用 Flink DDL 创建表
1. Flink sql 开启 checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 来让 Iceberg 可以提交事务。并且,mysql-cdc 在 binlog 读取阶段开始前,需要等待一个完整的 checkpoint 来避免 binlog 记录乱序的情况。
-- 每隔 3 秒做一次 checkpointFlink SQL> SET execution.checkpointing.interval = 3s;
2. Flink sql 创建 MySQL 分库分表 source 表
创建 source 表 user_source 来捕获MySQL中所有 user 表的数据,在表的配置项 database-name , table-name 使用正则表达式来匹配这些表。并且,user_source 表也定义了 metadata 列来区分数据是来自哪个数据库和表。
Flink SQL> CREATE TABLE user_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'db_[0-9]+',
'table-name' = 'user_[0-9]+'
);3.Flink sql 创建 Iceberg sink 表
创建 sink 表 all_users_sink,用来将数据加载至 Iceberg 中。在这个 sink 表,考虑到不同的 MySQL 数据库表的 id 字段的值可能相同,我们定义了复合主键 (database_name, table_name, id)。
Flink SQL> CREATE TABLE all_users_sink (
database_name STRING,
table_name STRING,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED
) WITH (
'connector'='iceberg',
'catalog-name'='iceberg_catalog',
'catalog-type'='hadoop',
'warehouse'='file:///tmp/iceberg/warehouse',
'format-version'='2'
);
三、流式写入 Iceberg
1. 使用下面的 Flink SQL 语句将数据从 MySQL 写入 Iceberg 中:
Flink SQL> INSERT INTO all_users_sink select * from user_source;
上述命令将会启动一个流式作业,源源不断将 MySQL 数据库中的全量和增量数据同步到 Iceberg 中。在 Flink UI (http://localhost:8081/#/job/running)上可以看到这个运行的作业:

然后我们就可以使用如下的命令看到 Iceberg 中的写入的文件:
docker-compose exec sql-client tree /tmp/iceberg/warehouse/default_database/如下所示:
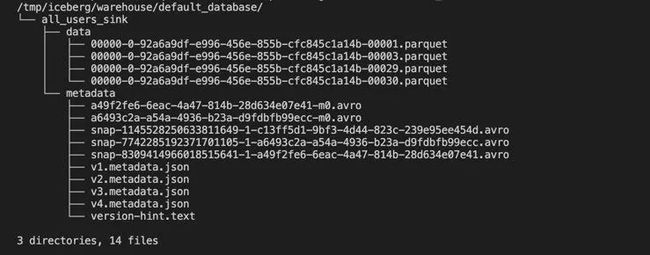
. 使用下面的 Flink SQL 语句查询表 all_users_sink 中的数据:
Flink SQL> SELECT * FROM all_users_sink;在 Flink SQL CLI 中我们可以看到如下查询结果:
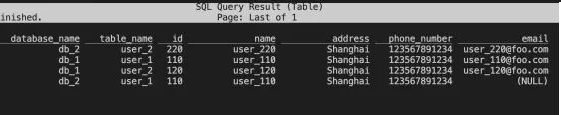
修改 MySQL 中表的数据,Iceberg 中的表 all_users_sink 中的数据也将实时更新:
在本文中,我们展示了如何使用 Flink CDC 同步 MySQL 分库分表的数据,快速构建 Icberg 实时数据湖。用户也可以同步其他数据库(Postgres/Oracle)的数据到 Hudi 等数据湖中。最后希望通过本文,能够帮助读者快速上手 Flink CDC 。