高效注意力机制集合-SE进阶版--更新SRM
近期论文针对SE注意力机制改进的论文逐渐出现,在此记录一下。具体有没有效果,建议各位自己尝试一下。也希望同学们能推荐一下轻量好用的注意力机制给我…
1.ECA-Net : Efficient Channel Attention for Deep Convolutional Neural Networks-CVPR2020
论文地址:https://arxiv.org/pdf/1910.03151.pdf
Github地址:https://github.com/BangguWu/ECANet
创新点:
将SENet中的两个先降维后升维的卷积,替换为更有效的连接方式,提高准确率的同时也减少了参数量。

代码:
import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
实验结果对比:

2.Gated Channel Transformation for Visual Recognition-CVPR2020
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Yang_Gated_Channel_Transformation_for_Visual_Recognition_CVPR_2020_paper.pdf
Github地址:https://github.com/z-x-yang/GCT
创新点:
作者指出,SENet存在的两个主要问题:
1.在CNN中应用SE模块时,模块数量有限制。SE主要在模块上应用(Res-Block或者Inception-Block),FC层无法在网络的所有层上应用。
2.由于FC层参数复杂,难以分析网络不同层间通道的关联性。
针对以上问题,提出GCT模块。主要包含:Global context embedding、Channel Normalization和Gating adaptation部分。使用L2 norm替代GAP的方式。有效降低

代码:
def forward(self, x, epsilon=1e-5):
# x: input features with shape [N,C,H,W]
# alpha, gamma, beta: embedding weight, gating weight,
# gating bias with shape [1,C,1,1]
embedding = (x.pow(2).sum((2,3), keepdim=True)
+ epsilon).pow(0.5) * self.alpha
norm = self.gamma / (embedding.pow(2).mean(dim=1,
keepdim=True) + epsilon).pow(0.5)
gate = 1. + torch.tanh(embedding * norm + self.beta)
return x * gate
部分实验结果:


3.DeepSquare: Boosting the Learning Power of Deep Convolutional Neural Networks with Elementwise Square Operators
论文地址:https://arxiv.org/ftp/arxiv/papers/1906/1906.04979.pdf
创新点:
主要用于手机端的轻量型平方注意力机制。作者设计了四种类型的轻量型逐点平方操作模块,分别为Square-Pooling,Square-Softmin,Square-Excitation,Square-Encoding。可以添加ResNet18、ResNet50、ShuffleNetV2上提升模型性能。实验结果表明:所提方法可以带来显著性的性能提升,媲美双线性池化、SE以及GE。所提高效模块尤其适合于手机端,比如采用配置Square-Pooling的ShuffleNetV2-0.5x可以取得1.45%的性能提升,推理耗时增加可忽略不计。

部分实验结果:
1.ResNet18

2.ResNet50

3.SHuffleNetV2

4.SRM : A Style-based Recalibration Module for Convolutional Neural Networks–CVPR2019
论文地址:https://arxiv.org/pdf/1903.10829.pdf
Github地址:https://github.com/hyunjaelee410/style-based-recalibration-module
受到风格迁移的启发,本文提出了一种基于style的重新校准模块(SRM),可以通过利用其style自适应地重新校准中间特征图。 SRM首先通过样式池从特征图的每个通道中提取样式信息,然后通过与通道无关的style集成来估计每个通道的重新校准权重。通过将各个style的相对重要性纳入特征图,SRM有效地增强了CNN的表示能力。重点是轻量级,引入的参数非常少,同时效果还优于SENet.。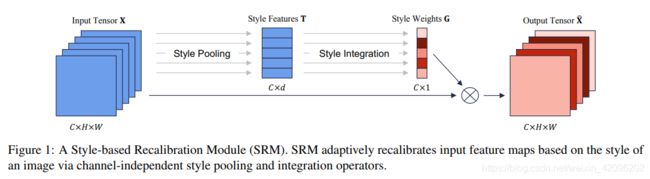
其中Style Pooling是avgpool和stdpool拼接,Style Intergration就是一个自适应加权融合
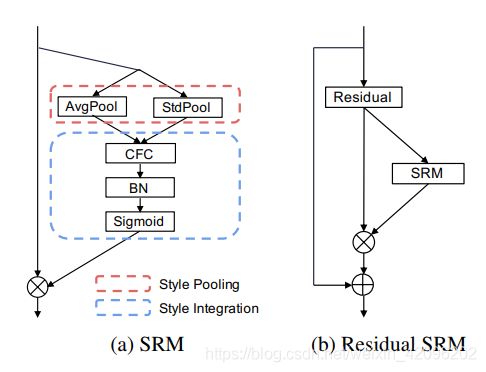
代码:
class SRMLayer(nn.Module):
def __init__(self, channel):
super(SRMLayer, self).__init__()
self.cfc = Parameter(torch.Tensor(channel, 2))
self.cfc.data.fill_(0)
self.bn = nn.BatchNorm2d(channel)
self.activation = nn.Sigmoid()
setattr(self.cfc, 'srm_param', True)
setattr(self.bn.weight, 'srm_param', True)
setattr(self.bn.bias, 'srm_param', True)
def _style_pooling(self, x, eps=1e-5):
N, C, _, _ = x.size()
channel_mean = x.view(N, C, -1).mean(dim=2, keepdim=True)
channel_var = x.view(N, C, -1).var(dim=2, keepdim=True) + eps
channel_std = channel_var.sqrt()
t = torch.cat((channel_mean, channel_std), dim=2)
return t
def _style_integration(self, t):
z = t * self.cfc[None, :, :] # B x C x 2
z = torch.sum(z, dim=2)[:, :, None, None] # B x C x 1 x 1
z_hat = self.bn(z)
g = self.activation(z_hat)
return g
def forward(self, x):
# B x C x 2
t = self._style_pooling(x)
# B x C x 1 x 1
g = self._style_integration(t)
return x * g
部分实验结果:

