elk:filebeat
elk:filebeat日志收集工具和logstash相同
filebeat是一个轻量级的日志收集工具,所使用的系统资源比logstash部署和启动时使用的资源要小的多。
filebeat可以运行在非java环境,他可以代替logstash在非java环境上收集日志。
filebeat无法实现数据的过滤,一般是结果logstash的数据过滤功能一块使用。
filebeat收集的数据可以发往多个主机,远程收集
mysql
systemctl stop firewalld
setenforce 0
logstash:
tar -xf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64 filebeat
vim /etc/logstash/logstash.yml (可以不改/etc/logstash/conf.d)
![]()
所有
yum install ntpdate -y
ntpdate ntp.aliyun.com
date
logstash:
yum -y install nginx
systemctl restart nginx
vim /etc/nginx/nginx.conf
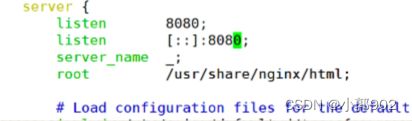
vim /var/www/html/index.html
this is httpd
cd /usr/share/nginx/html
this is nginx/index.html
cd /var/log/nginx
ll
chmod 777 access.log error.log
cd /opt
cd filebeat/
cp filebeat.yml filebear.yml.bak
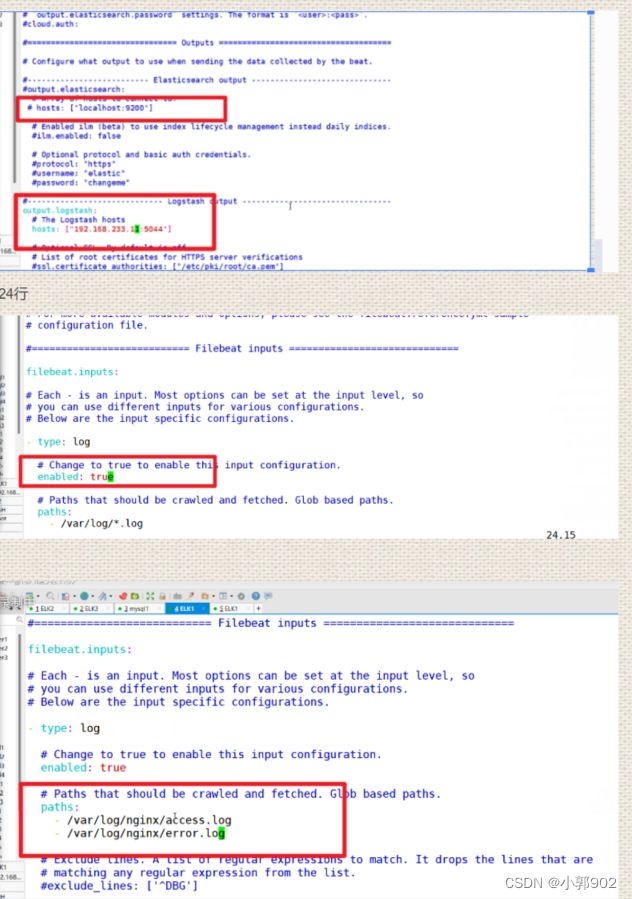
vim filebeat.yml
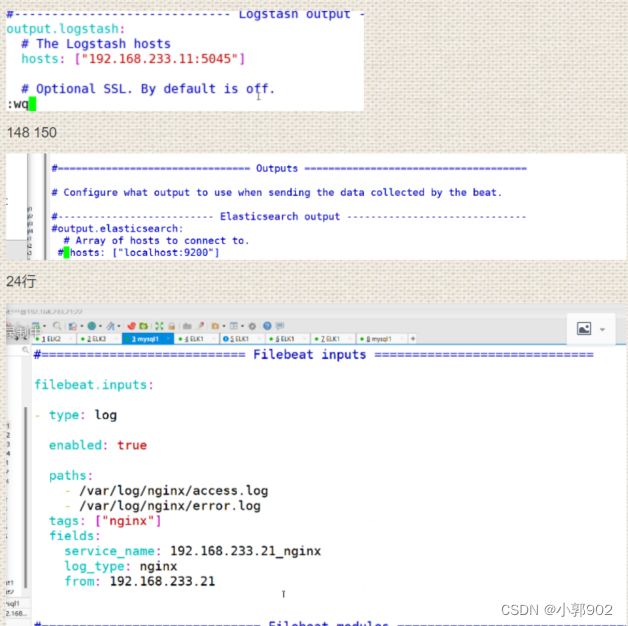
148行,150行
161行,163行
cd /opt
mkdir log
cd /etc/logstash/conf.d
vim file_nginx.conf
input {
beats { port => "5044" }
}
output {
if "nginx" in [tags] {
elasticsearch {
hosts => [ "192.168.233.12:9200","192.168.233.13:9200" ]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
wq!
cd /opt/filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
##
nohup 表示在后台记录执行命令的过程
./filebeat 运行文件
-e 使用标准输出的同时禁用syslog文件输出
-c 指定配置文件
> filebeat 执行过程输出到filebeat.out这个文件当中
& 后台运行
##
cd /opt/filebeat
tail -f filebeat.out
cd /opt/log
ls
logstash -f file_nginx.conf --path.data /opt/test1 &
测试访问:192.168.233.11:8080
192.168.233.11:8080/test
logstash收集日志的过程:
input()
filter(过滤)
output(发送es实例)
本地收集:
远程收集,远程收集多个日志,
mysql1:
vim /etc/my.cnf
general_log =ON
general_log_file=/usr/local/mysql/data/mysql_general.log
systemctl restart mysqld
cd /usr/local/mysql/data/
创建一个库,新建一个表
cd /usr/local/mysql/data
cat mysql_general.log
yum -y install nginx
yum -y install httpd
vim /etc/nginx/nginx.conf

systemctl restart nginx
systemctl restart httpd
vim /var/www/html/index.html
this is httpd
vim /usr/share/nginx/html/index.html
this is nginx
cd /opt
把filebeat拖进去
tar -xf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64 filebeat
cd filebeat/
cp filebeat.yml filebeat.yml.bak
vim filebeat.yml
161行,163行
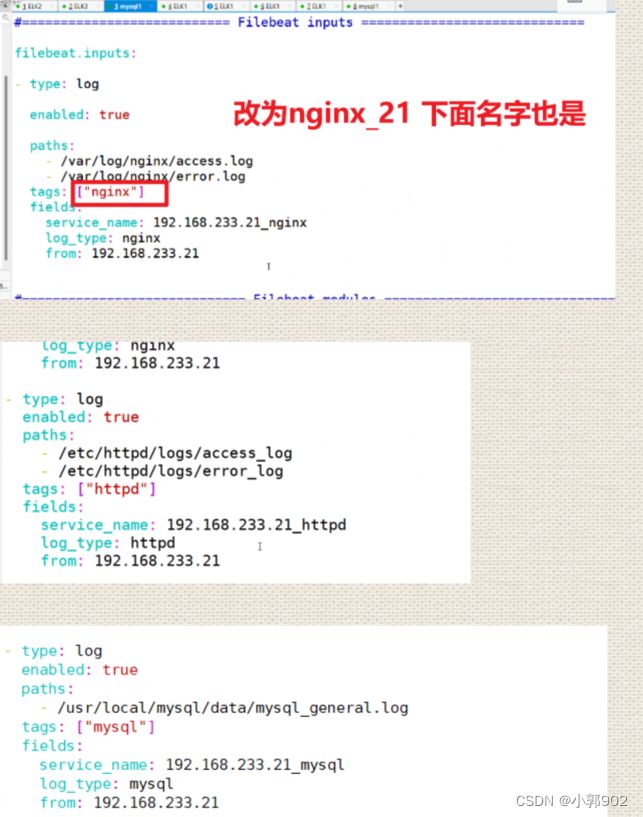

paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
tags: ["nginx_18"]
fields:
service_name: 192.168.66.18_nginx
log_type: nginx
from: 192.168.66.18
- type: log
enabled: true
paths:
- /etc/httpd/logs/access_log
- /etc/httpd/logs/error_log
tags: ["httpd_18"]
fields:
service_name: 192.168.66.18_httpd
log_type: httpd
from: 192.168.66.18
- type: log
enabled: true
paths:
- /usr/local/mysql/data/mysql_general.log
tags: ["mysql_18"]
fields:
service_name: 192.168.66.18_mysqld
log_type: mysql
from: 192.168.66.18
cd /var/log/nginx
chmod 777 access.log error.log
cd /etc/httpd/logs
chmod 777 access_log error_log
cd /usr/local/mysql/data
chmod 777 mysql_general.log
elk:
cd /opt/log
vim nhm_18.conf
input {
beats { port => "5045" }
}
output {
if "nginx_18" in [tags] {
elasticsearch {
hosts => ["192.168.66.15:9200","192.168.66.16:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
if "httpd_18" in [tags] {
elasticsearch {
hosts => ["192.168.66.15:9200","192.168.66.16:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
if "mysql_18" in [tags] {
elasticsearch {
hosts => ["192.168.66.15:9200","192.168.66.16:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
wq!
mysql:
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
elk
logstash -f nhm_21.conf --path.data /opt/test2 &
##lofgstash 可以使用任意端口,只有没被占用都可以使用,推荐1024之后开始
logstash 性能上的优化:logstash启动是在jvm虚拟机当中其中,启动一次至少要占500M内存。
elk
vim logstash.yml
41行
pipeline.workers:2
##logstash的工作线程,默认值就是cpu数,4 2 8 4 给一半即可 2核2G
45行
pipeline.bash.size:125
##一次性能够批量处理检索事件的大小 125条数。200
50行
pipeline.batch.delay:50
##查询更新的延迟,50毫秒,也可以自行调整 15 10 也要看机器性能