Flink join(流流)详解(一)
本文基于flink 1.11进行测试。
前言
这里所说的join是两个或者多个流的join,涉及流批join的内容或者批批join会另写一篇文章专门说。
Flink的join按照窗口类型分可以分为:Tumbling Window Join、Sliding Window Join和Session Window Join。
按join类型分可以分为join和intervalJoin。前者类似RDBMS中的内连接,interval join使用一个公共键连接两个流的元素(我们现在称它们为A和B),其中流B的元素的时间戳与流A中元素的时间戳之间存在相对时间间隔。
inner join示意图:

interval join示意图:

本文会用到
- Flink1.11 事件时间(event time)、watermark、watermarkstrategy使用详细案例文章的知识。
- Flink window function及常用窗口算子文章的知识。
代码
创建用于join的两个数据源
package it.kenn.source;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import scala.Tuple3;
import java.util.Random;
public class ForJoinSource1 implements SourceFunction> {
boolean flag = true;
@Override
public void run(SourceContext> ctx) throws Exception {
Random random = new Random();
while (flag) {
int randInt = random.nextInt(100);
ctx.collect(new Tuple3<>("S" + randInt, System.currentTimeMillis(), random.nextDouble() * 1000));
Thread.sleep(30);
}
}
@Override
public void cancel() {
flag = false;
}
}
//-----------------------------------------------------------------------------------
package it.kenn.source;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import scala.Tuple3;
import java.util.Random;
public class ForJoinSource2 implements SourceFunction> {
boolean flag = true;
@Override
public void run(SourceContext> ctx) throws Exception {
Random random = new Random();
while (flag) {
int randInt = random.nextInt(110);
ctx.collect(new Tuple3<>("S" + randInt, System.currentTimeMillis(), random.nextDouble() * 1000));
Thread.sleep(20);
}
}
@Override
public void cancel() {
flag = false;
}
}
测试主程序
package it.kenn.join;
import it.kenn.source.ForJoinSource1;
import it.kenn.source.ForJoinSource2;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import scala.Tuple3;
import java.time.Duration;
/**
* 测试join
*/
//测试主程序
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamStreamJoinTest joinTest = new StreamStreamJoinTest();
//设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream> source30 = env.addSource(new ForJoinSource1())
//指定时间戳和watermark规则,注意要指定两个:forBoundedOutOfOrderness指定watermark生成策略,withTimestampAssigner指定那个字段是事件时间
.assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ofMillis(10)).withTimestampAssigner((e, ts) -> e._2()));
DataStream> source20 = env.addSource(new ForJoinSource2())
.assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ofMillis(10)).withTimestampAssigner((e, ts) -> e._2()));
DataStream> tumbJoinedStream = joinTest.tumbJoin(source20, source30);
DataStream> slidingJoinStream = joinTest.slidingJoin(source20, source30);
DataStream> intervalJoinStream = joinTest.intervalJoin(source20, source30);
//对不同join进行测试
tumbJoinedStream.print();
env.execute();
}
inner Tumbling Window Join代码测试
/**
* inner Tumbling Window Join
*
* @param source20
* @param source30
* @return
*/
public DataStream> tumbJoin(DataStream> source20, DataStream> source30) {
DataStream> joinedStream = source20.join(source30)
.where(e -> e._1().split("-")[1])//左流要join的字段
.equalTo(e -> e._1().split("-")[1])//右侧流要join的字段
.window(TumblingEventTimeWindows.of(Time.milliseconds(50)))//指定窗口类型和窗口大小
//join函数,这里说是join但是跟数据库的join有一些区别,比如下面的逻辑并没有取两个流中的数据,而是比较两个流中数据的大小,只返回某个流中的数据
.apply(new JoinFunction, Tuple3, Tuple3>() {
@Override
public Tuple3 join(Tuple3 left, Tuple3 right) throws Exception {
return left._3() > right._3() ? left : right;
}
});
return joinedStream;
} 下图是tumble window join的示意图,但是下面join结果有些歧义,像是笛卡尔积。其实只要在join的时候加上where条件就不可能会产生下面笛卡尔积的情况了。
下图还有一个信息点,在最后一个窗口的时候,只有橙色流中有数据,绿色流中并没有数据,那么这个窗口的计算不会被触发。

sliding Join 测试
/**
* sliding Join 测试
*
* @param source20
* @param source30
* @return
*/
public DataStream> slidingJoin(DataStream> source20, DataStream> source30) {
DataStream> joinedStream = source20.join(source30)
.where(e -> e._1().split("-")[1])//左流要join的字段
.equalTo(e -> e._1().split("-")[1])//右侧流要join的字段
.window(SlidingEventTimeWindows.of(Time.milliseconds(50), Time.milliseconds(30)))//指定窗口类型和窗口大小
.apply(new JoinFunction, Tuple3, Tuple3>() {
@Override
public Tuple3 join(Tuple3 left, Tuple3 right) throws Exception {
return left._3() > right._3() ? left : right;
}
});
return joinedStream;
} sliding join示意图:
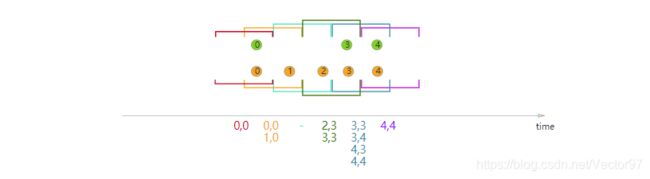
interval join有一个需要注意的特点:有些事件可能在一个滑动窗口中没有被join但是在另外一个滑动窗口中去呗join了。比如上图橙色2号事件,在蓝色窗口中没有与绿色流join,但是在后面的绿色窗口中却与绿色3号join了。
Session Window Join测试
这种方式用到的场景好像不太多,如果哪天我用到了会在这里补上笔记的。
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream orangeStream = ...
DataStream greenStream = ...
orangeStream.join(greenStream)
.where()
.equalTo()
//指定Gap大小
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
}); session window join示意图:

上图是session window示意图。可以看到他的原理是通过两个流的间隔时间划分的窗口,这种窗口的数量非常不稳定。如果流中event间隔一直小于指定的GAP,那么窗口会一直不触发。换句话说,这种窗口的触发相比其他窗口而言比较被动,完全是数据驱动的触发,而不是时间驱动的触发。
interval Join 测试
/**
* interval Join 测试
*
* @param source20
* @param source30
* @return
*/
public DataStream> intervalJoin(DataStream> source20, DataStream> source30) {
SingleOutputStreamOperator> intervalJoinedStream = source20.keyBy(e -> e._1().split("-")[1])
.intervalJoin(source30.keyBy(e -> e._1().split("-")[1]))
.between(Time.milliseconds(-12), Time.milliseconds(9))
//默认情况下上面的between条件是包含边界的,如果不希望包含边界可以使用下面两个方法去除
.lowerBoundExclusive()
.upperBoundExclusive()
.process(new ProcessJoinFunction, Tuple3, Tuple3>() {
@Override
public void processElement(Tuple3 left, Tuple3 right, Context ctx, Collector> out) throws Exception {
out.collect(left._3() > right._3() ? left : right);
}
});
return intervalJoinedStream;
} interval join示意图:

上图是interval join示意图。之前遇到过一个场景。假设绿色流和黄色流是两组人的运动轨迹。在黄色2位置,某人进了一家餐馆,求跟黄色2号事件前后5分钟同时进入这家餐馆的绿色事件,使用interval join就很合适。
还有一点需要注意,在上面注释也写明了,图中也画出来了,默认情况下between是包含边界的,如果要去掉边界,需要使用上面两个函数去除边界,当然可以根据情况只去除一个边界。