Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
超越幻觉:通过幻觉感知直接偏好优化增强 LVLM
上海人工智能实验室
Abstract
近年来,多模态大语言模型取得了显着的进步,但它们仍然面临着一个被称为“幻觉问题”的常见问题,即模型生成的文本描述包含图像中不准确或不存在的内容。为了解决这个问题,本文引入了一种新颖的策略:幻觉感知直接偏好优化(HA-DPO)。我们的方法将幻觉问题视为一个独特的偏好选择问题,其中模型经过训练,在出现同一图像的两个响应(一个是准确的,一个是幻觉的)时支持非幻觉响应。本文还提出了一种构建幻觉样本对的有效流程,以确保高质量、风格一致的样本对,从而实现稳定的 HA-DPO 训练。我们将该策略应用于两个主流的多模态模型,结果表明幻觉问题显着减少,模型的泛化能力得到增强。借助 HA-DPO,MiniGPT-4 模型展现了显着的进步:POPE 准确率从 51.13% 提高到 85.66%(绝对改进 34.5%),MME 得分从 968.58 升级到 1365.76(相对改进 41%)。代码、模型和数据集将公开。
一、简介
得益于对图像文本对的广泛无监督预训练以及对高质量数据的细致微调,大型视觉语言模型(LVLM)在同步视觉和文本特征方面取得了实质性进展。这一进展赋予这些模型遵循多模态指令的能力[5,17,36,40],从而在一系列多模态任务中取得了重大成就。然而,即使是最先进的 LVLM 也无法避免普遍存在的“幻觉”问题。这种现象(模型的输出包含虚构信息,例如不存在的对象或不正确的类别、属性或关系)是一个严峻的挑战[8,13,15,30,35,39]。这些幻觉的细节不仅会损害用户体验,还会误导用户,可能引发严重后果。例如,医疗诊断中的不准确描述可能会导致误诊,给患者带来不可预见的伤害。
研究人员已经开展了一系列研究,以减轻多模态模型中的幻觉问题。目前主流的解决方案大致可分为两类:第一类,如图1a所示,涉及构建幻觉相关数据集,并采用监督微调(SFT)来提高模型的指令跟踪能力,同时减轻幻觉现象[5 、 15、 36]。该方法虽然在一定程度上减少了幻觉,但需要高质量且多样化的微调数据,需要较高的标注成本和训练开销。第二种,如图1b所示,将模型幻觉的消除视为对模型输入的后处理操作,使用现有的工具或模型(例如分词器和检测模型)来检查和修改句子中的幻觉内容[39 ]。这种方法在某些情况下不需要额外的数据和训练,除非事后幻觉处理需要定制模型[34]。然而,这种方法的有效性受到现有模型和工具的限制,并且随着附加后处理工具和模型的结合,其时间成本也会增加。
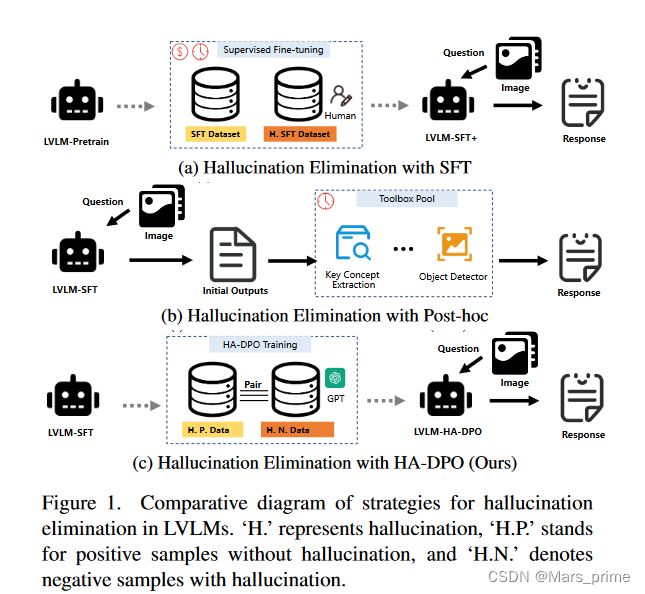
图 1. LVLM 消除幻觉策略的比较图。 ‘H.’代表幻觉,‘H.P.’代表无幻觉的阳性样本,‘H.N.’代表有幻觉的阴性样本。
SFT 方法虽然有益,但缺乏算法优化和定制幻觉处理的灵活性。这也对数据建设和模型训练成本提出了很高的要求。另一方面,事后方法的性能完全取决于可用的工具集。相比之下,本文将模型幻觉消除视为模型偏好,该模型偏向于无幻觉输出。按照这种方法,我们将多模式幻觉消除任务解耦为偏好优化问题。我们预计多模态模型将在训练过程中表现出偏好约束,从而导致对无幻觉输出的偏见。 RLHF 和 DPO 是最近提出的两种策略,用于解决大型语言模型中的偏好问题。鉴于DPO方法的轻量级性质和高效训练,本文对其进行扩展,提出一种对幻觉敏感的多模态DPO策略,从而定制和增强多模态模型的幻觉消除能力。
在我们对多模式幻觉评估的分析过程中,我们发现了当前幻觉评估系统中的几个缺陷。首先,他们将类别限制为各种研究中预定义的类别[13,28,33],将这些类别之外的任何内容视为错误。此外,他们需要构建同义词集,以防止同义词(例如“摩托车”)被错误分类为幻觉。此外,他们将注意力集中在特定范围,例如目标和对象属性的存在,而忽略了更广泛的背景。针对这些缺点,我们提出了一种更直观、更全面的评估方法,不局限于固定的类别和范围,可以直接测量幻觉的比例。
总之,我们做出以下贡献:
1.我们提出了 HA-DPO 策略,这是一种专门为对抗大型多模态模型中的幻觉而设计的新颖范式,如图 1c 所示。此外,我们还开发了一种构建风格一致的幻觉样本对的方法,确保 HA-DPO 训练的稳定性。
2. 我们引入了句子级幻觉比率(SHR),这是一种用于评估 LVLM 中幻觉的直观且全面的指标。
3. 通过对流行模型的广泛实验,我们证明了我们方法的有效性,显示幻觉显着减少,模型的总体性能显着增强。
2. Related Work 相关工作
2.1. Hallucination in LLMs LLM 中的幻觉
大型语言模型 (LLM) 中的幻觉是指模型生成与事实相冲突的响应的实例 [14,27,37]。尼克等人。 [20]指出LLM幻觉与预训练数据中的噪声显着相关。根据[6],人工生成的预训练数据也可能表现出幻觉。除了预训练数据引入的噪声之外,[24] 发现如果模型缺乏先验知识,SFT 过程可能会引入幻觉。 [10]发现一些模型往往在不考虑答案有效性的情况下支持用户,导致阿谀奉承。针对噪声预训练数据带来的幻觉,Falcon[25]通过强大的互联网数据清理策略极大地增强了LLM的能力。 LLaMA2 [31]通过提高高质量数据源的采样率来降低数据噪声。至于 SFT 期间的幻觉缓解,LIMA [38] 建议降低 SFT 数据量,以使用“少量但精炼”的数据来提高性能。 Phi [7, 12] 提供了教科书级别的微调数据,优于具有更大数据集的其他 LVLM。 RLHF(人类反馈强化学习)是消除幻觉的另一种有效方法。 GPT4 通过学习人类反馈,将 TruthfulQA 的准确性从 30% 提高到 60% [22]。
2.2. LVLM 中的幻觉
LVLM继承了LLM的幻觉问题,由于两种不同模态空间(语言和图像)之间的错位,幻觉问题更加严重。 POPE [13] 发现了 LVLM 中的物体存在幻觉问题。结果显示,LVLM 出现严重幻觉,许多 LVLM 无法辨别。 LRV [15] 创建了大量带有丰富注释的 QA 对,并使用 GPT4 对 LVLM 答案进行评分。 NOPE [18] 检查了 10 个高级 LVLM 在视觉问题中检测不存在物体的能力,结果表明它们都容易产生物体幻觉。
为了减轻幻觉,大多数方法都采取提高 SFT 数据质量的方法。 VIGC [32]提出了一个视觉指令校正模块,通过迭代输入更新减轻长序列生成幻觉,确保连续的图像内容聚焦。 LRV[15]构建了大量的SFT数据来减少SFT阶段带来的幻觉。 InstructBLIP [5]通过利用大量的公共高质量数据集确保了SFT的优越性。此外,RL(强化学习)方法也被应用于LVLM中的幻觉缓解。 LLaVA-RLHF [30] 是第一个将 RLHF 应用于 LVLM 以减少 LVLM 幻觉的人。 [8]应用了DPO(直接偏好优化)[26],与RLHF [4]相比,它跳过奖励模型学习来消除幻觉,仅使用不偏好的数据进行优化。首选数据的缺乏使得“好的”策略学习变得复杂,并且存在模型过度开发的风险[2,4,21,23]。不同的是,我们的框架将高质量、无人参与、风格一致的正负数据引入到 DPO 框架中,与之前的方法相比,增强了数据质量和强化学习策略。
2.3.人类偏好学习
如今先进的 LVLM 利用 SFT 模型,并通过人类偏好学习 [22,24,31] 得到增强,从而产生有效、安全和诚实的模型。 RLHF(人类反馈强化学习)[19,24,41]是学习人类偏好最成功的实践。 RLHF 可以分为三步方法:模型监督微调、开发基于人类偏好的奖励模型以及利用奖励模型反馈优化 LVLM [29]。同样,InstructGPT 基于 GPT3 [3],利用人类偏好数据进行 RL 优化。白等人。 [1] 旨在通过更新的强化学习政策来增强人类偏好学习。 DPO提出直接绕过奖励模型学习和学习策略[26]。 GPT4 通过广泛的数据处理强调人类偏好的一致性 [22]。就人类偏好学习在 LVLM 中的应用而言,当前的方法采用 RLHF 或 DPO 来消除模型幻觉,尽管在 RL 策略和人类偏好数据应用方面存在一些局限性 [8, 30]。
3. 我们的方法
在这项工作中,我们引入了一种新颖的方法,即幻觉感知直接偏好优化(HA-DPO),旨在限制模型对没有幻觉的输出的偏好。主要目标是促进非幻觉产出。考虑到利用经典 RLHF 方法约束模型偏好时数据构建和模型训练过程固有的复杂性,我们选择直接偏好优化(DPO)。 DPO 是一种更简单、更高效且无需 RL 的方法,是我们的基本策略。我们将该策略扩展到多模态领域,旨在消除幻觉,从而提高多模态模型输出的真实性和精度。
如图 2 所示,我们通过三个主要步骤构建风格一致的幻觉数据集:1 描述生成、2 幻觉检测和纠正以及 3 风格一致的数据增强。该数据集随后用于 HADPO 模型的训练。使用这种方法训练的模型表明,在涉及详细描述和对话的任务中,幻觉现象显着减少。
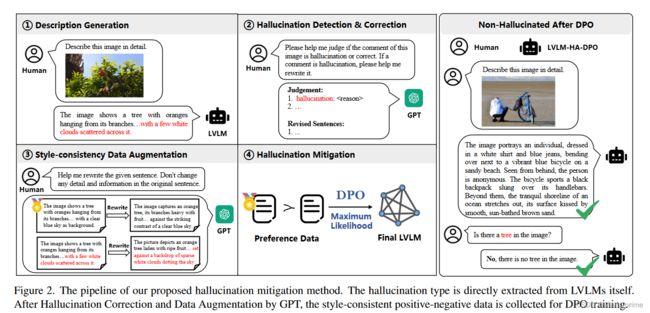
图 2.我们提出的幻觉缓解方法的流程。幻觉类型直接从 LVLM 本身提取。经过 GPT 的幻觉校正和数据增强后,收集风格一致的正负数据用于 DPO 训练。
3.1.多模态幻觉感知 DPO
我们将幻觉的消除表述为偏好选择问题,其中结合风格一致的数据集进行偏好学习。这鼓励模型支持非幻觉的积极反应 ypos 并拒绝幻觉的消极反应 yneg。在 DPO [26] 的基础上,我们将 DPO 扩展为多模态版本 HA-DPO,这确保优化的多模态模型表现出对非幻觉输出的偏好。
在人类偏好学习阶段,训练奖励模型(表示为 r),以确保模型输出非幻觉响应 ypos 和拒绝幻觉响应 yneg 的倾向。该奖励模型能够为不同的响应 y 分配分数,从而准确地反映人类的偏好。一旦获得奖励模型 r,它就用于提供反馈以指导额外的微调阶段,该阶段学习由人类偏好引导的策略模型 πθ。
HA-DPO 基于 DPO 框架,规避了隐式奖励模型学习的需要,直接优化策略模型 πref 如下:
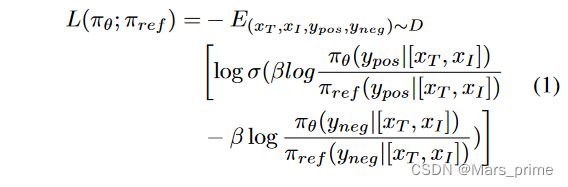
在等式中。 1,xT和xI分别表示输入到模型的文本和图像提示,[]表示特征串联。符号 πref 和 πθ 分别代表参考模型和策略模型。 D 表示风格一致的幻觉数据集。该目标同时学习奖励和策略模型,使奖励模型偏向于选择积极响应 ypos 和拒绝消极响应 yneg。
方程中的训练目标。 1 消除了显式奖励模型学习的需要,而是直接优化策略模型。奖励模型由 r 隐式表示,由下式给出:
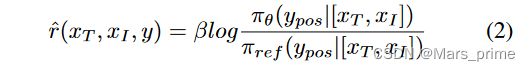
等式。图2是隐式奖励模型表示。目标 1 最大化正非幻觉样本 ypos 和负幻觉样本 yneg 之间的奖励裕度 ˆ r(xT , xI , ypos) − ˆ r(xT , xI , yneg) 。此外,它增加了正非幻觉样本 ypos 的对数似然性,并降低了负幻觉样本 yneg 的对数似然性,从而引导模型偏向于非幻觉样本而不是幻觉样本。
3.2.具有风格一致性的数据集构建
本文提出的HA-DPO方法需要正负样本对。具体来说,对于给定的图像,正输出是没有幻觉的详细描述 ypos。相反,负输出是包含幻觉的详细描述 yneg。
3.2.1 数据来源
本文使用视觉基因组(VG)数据集[11]构建幻觉样本。 VG数据集包含丰富的注释信息。每张图像包含多个区域边界框,每个区域边界框对应一个详细描述。这些注释可以充分涵盖与图像相关的各种详细信息:不同的目标、属性、关系等,不受特定类别和范围的限制。
3.2.2 幻觉样本对的生成。
如图2所示,基于具有详细注释信息的视觉基因组图像,我们提出以下数据构建过程:初始描述生成。我们从 VG 数据集中随机选择图像,并使用 LVLM 生成相应的详细描述。 GPT-4 幻觉检测和纠正。接下来,将模型生成的描述和原始图像的所有标注信息输入到GPT-4中,并提供详细的提示模板,使GPT-4能够检查生成的描述中是否存在幻觉。如果存在幻觉,则需要提供无幻觉的正确描述。这样,我们就可以获得图像对应的正响应和负响应。事实上,当多模态模型提供详细的图像描述时,幻觉几乎总是发生。风格一致的数据增强。为了保证正负例句风格的一致性,获取更多的样本,我们使用GPT-4对上一步得到的正负样本进行重写,保证正负样本不变。通过上述步骤,我们可以获得高质量的正样本(x,ypos)和负样本(x,yneg)对进行HA-DPO训练。
3.3.风格一致性分析
直观上,高质量且风格一致的数据对于 HA-DPO 的高效稳定训练至关重要。我们将在下文中进行详细分析。图 3(a) 显示我们首先使用多模态模型生成详细的图像描述。我们发现只有少数反应完全不存在幻觉。然而,根据公式1,HA-DPO训练需要相等的正负样本对(x,ypos)和(x,yneg)。为此,我们利用GPT-4去除幻觉内容,生成完全没有幻觉的阳性样本响应,如图3-(b)的分布所示。虽然我们现在有成对的正负样本,但当前幻觉负样本和非幻觉正样本的分布明显不同。这种分布差异并非源于幻觉的存在或不存在,而是因为当前的负样本来自模型生成,而正样本来自 GPT-4 重写,这意味着它们源自不同的风格模型。这种分布差异会误导HA-DPO认为它是需要学习的幻觉偏好目标,导致HA-DPO训练直接失败。
在统计上,我们比较了图 4 中正样本和负样本的对数似然 log π(y|xT , xI ) 的分布。图 4a 和图 4b 分别表示没有风格一致性和有风格一致性的数据的对数似然。可以看出,GPT-4直接修改否定响应会导致正负数据分布不一致,这是训练不稳定的主要原因。相反,风格一致性的正面和负面数据显示出很少的不一致。我们还在图 4c 中比较了有或没有风格一致性数据时奖励边际 rθ(xT , xI , ypos) − rθ(xT , xI , yneg) 的学习状态。在没有风格一致性控制的情况下,与使用风格一致的数据相比,奖励模型很快学会了如何根据风格的差异来区分正样本和负样本,而不是产生幻觉,从而导致模型失败。
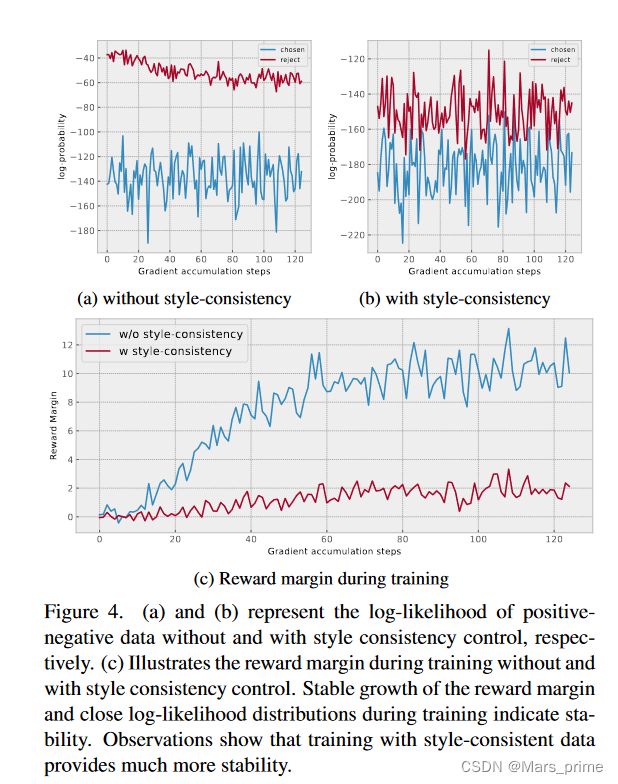
图 4. (a) 和 (b) 分别表示没有和有风格一致性控制的正负数据的对数似然。 (c) 说明了在没有和有风格一致性控制的情况下训练期间的奖励裕度。训练期间奖励裕度的稳定增长和接近的对数似然分布表明稳定性。观察表明,使用风格一致的数据进行训练可提供更高的稳定性。
除此之外,我们从目标1梯度优化的角度验证了正负分布的错位会导致训练不稳定。通过推导目标1的优化目标,我们可以得到:
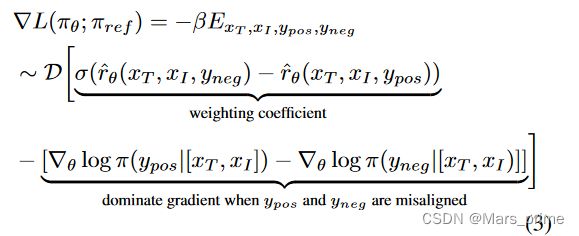
优化梯度可以分为两部分。第一部分是奖励模型r表示的权重系数,它可以在奖励模型估计错误时引导模型回到正确的轨道。第二部分是增加 ypos 的对数似然并减少 yneg 的对数似然。 [26]经验证明,奖励模型的权重因子对于训练的稳定性非常关键。如果没有权重因子,模型很容易失败。从方程。从图3可以看出,当正样本ypos和负样本yneg的分布不对齐时,梯度中的后一项变得非常大,从而主导梯度,导致权重因子无法稳定训练。我们在图5中比较了没有风格一致性控制和有风格一致性控制的训练数据之间的训练梯度。使用风格一致数据训练期间的梯度更加稳定,这进一步验证了风格一致性控制在稳定偏好方面的有效性。学习。
4. 实验
4.1。数据与评估
训练数据:基于VG数据集[11],我们过滤掉目标过多或过少以及注释信息不足的图像,并随机选择2000张图像。按照方法部分中的步骤,我们生成了风格一致的正样本和负样本。在幻觉数据集构建阶段,我们使用 GPT-4 进行了 3 次重写,最终得到了总共 2,000 张图像,以及相应的 6,000 个非幻觉回复和 6,000 个幻觉回复。
用 POPE 进行评估。 POPE 数据集是大型多模态模型中幻觉的主流评估数据集,包含三种类型的 9,000 个问题。问题仅限于图像中是否存在固定类别(80 个 COCO 类别)的目标,答案为是/否。准确性是根据模型的答案和真实结果计算的。虽然这可以让我们深入了解模型的幻觉能力,但它首先是基于类别的,没有考虑对象属性或相对关系。
SHR评估:针对POPE的局限性,我们提出了一种新的评估指标,称为“句子级幻觉比率”(SHR),旨在量化多模态人工智能模型中句子级的幻觉程度。这些描述或响应通常包含多模态模型的多个句子,这些句子生成给定图像的详细描述。 SHR 衡量的是出现幻觉的句子占回答中句子总数的比例。
SHR 的正式定义为: SHR = PN i=1 hi PN i=1 si 其中 N 是图像总数,si 是第 i 个图像的响应中的句子数量,hi 是数量同一反应中的句子会产生幻觉。 SHR 的计算方式为所有反应中产生幻觉的句子的总比例。
具体来说,我们从VG中随机选择200张图像作为评估集(val)。 hi 的确定是由 GPT-4 根据模型的输出结果和当前图像对应的 VG 注释来确定的。
4.2.实施细节
迷你GPT-4。我们使用LoRA [9]对语言模型参数进行微调,其中LoRA线性层的维度(等级)设置为256。我们对语言模型中的qproj和kproj进行微调,其他参数固定。学习率设置为1e−4,使用余弦调度器进行学习率调整。预热比率设置为0.03,预热轮数为100。批量大小设置为1。HA-DPO中的超参数β设置为0.1。使用 4×A100 进行 1K 步训练(约 1-2 小时)。
指导BLIP。使用LoRA对语言模型的参数进行微调,LoRA等级设置为256。对语言模型中的qproj,kproj,vproj,oproj,toq,tokv,toout进行微调。使用余弦学习率调度器将学习率设置为 1e−5。批量大小设置为 4。HA-DPO 中的超参数 β 设置为 0.1。使用 4×A100 进行 512 个步骤的训练。