Matlab数据统计与分析
1.前言
概率分布是概率论和统计学中描述随机变量取值规律的概率模型。它是一个函数,将随机变量的每一个可能取值映射到一个非负实数,表示该取值出现的概率。
概率分布主要有两种类型:离散概率分布和连续概率分布。
离散概率分布是指随机变量取值是离散的,例如投掷骰子的结果(1-6)、抛硬币的结果(正面或反面)等。离散概率分布可以用概率质量函数(Probability Mass Function, PMF)来描述,PMF是一个非负实数函数,其自变量是离散随机变量的取值,函数值是该取值出现的概率。
连续概率分布是指随机变量取值是连续的,例如人的身高、体重、考试成绩等。连续概率分布可以用概率密度函数(Probability Density Function, PDF)来描述,PDF是一个非负实数函数,其自变量是连续随机变量的取值,函数值在该取值附近的概率密度。对于连续概率分布,我们通常关心的是其在某个区间内的概率,而不是某一个具体的取值。
常见的离散概率分布有:伯努利分布、二项分布、泊松分布等;常见的连续概率分布有:正态分布、均匀分布、指数分布、卡方分布等。
2.基本统计量
(1)均值
clear
warning off %不显示警告
x=[1 2 3;4 5 6;7 8 9];
y=mean(x)%整个矩阵求均值
y1=mean(x(2,:))%求第二行的均值
y2=mean(x,1)%按列求均值。默认值也可以y2=mean(x)
y3=mean(x,2)%按行求均值
y4=mean(x,3)%矩阵本身
(2)中位数
median
此 MATLAB 函数 返回 A 的中位数值。 如果 A 为向量,则 median(A) 返回 A 的中位数
值。 如果 A 为非空矩阵,则 median(A) 将 A 的各列视为向量,并返回中位数值的行向量。
clear
x=[1 5 6 9 5 6 5 4 7 9];
sort(x)
median(x)
(3)方差
clear
x=[1 5 6 9 5 6 5 4 7 9];
x1=var(x)%方差
x2=sqrt(x1)%标准差(4)峰度
正态分布的峰度值为0。
若峰度值大于0,则数据分布较正态分布更为陡峭,即呈现出尖峰形态;
若峰度值小于0,则数据分布较正态分布更为平坦,即呈现出扁峰形态。
峰度的绝对值越大,表示数据分布形态与正态分布的差异程度越大。
峰度在数据分析中有实际应用价值,例如在信号处理中,峰度可以用于分析异常信号,如齿轮副中的划痕、振动信号中破坏性尖峰的概率等。
clear
x=[1 5 6 9 5 6 5 4 7 9];
kurtosis(x) 
(5)偏度
偏度的取值范围为(-∞,+∞)
当偏度<0时,概率分布图左偏。
当偏度=0时,表示数据相对均匀的分布在平均值两侧,不一定是绝对的对称分布。
当偏度>0时,概率分布图右偏
clear
x=[1 5 6 9 5 6 5 4 7 9];
skewness(x)
3.常见概率分布函数
| 分布类型 | 正太分布 | 指数分布 | 泊松分布 |  分布 分布 |
韦布尔分布 |  分布 分布 |
t分布 | F分布 |
| 命令 | norm | exp | poiss | beta | weib | chi2 | t | F |
分布命令字符 表1
| 函数类型 | 概率密度 | 概率分布 | 逆概率分布 | 均值与方差 | 随机数生成 |
| 命令 | cdf | inv | stat | rnd |
函数命令字符 表2
normpdf
- 正态概率密度函数
此 MATLAB 函数 返回标准正态分布的概率密度函数 (pdf),在 x 中的值处计算函数值。
语法
y = normpdf(x)
y = normpdf(x,mu)
y = normpdf(x,mu,sigma)
输入参数
x - 用于计算 pdf 的值
标量值 | 标量值组成的数组
mu - 均值
0 (默认值) | 标量值 | 标量值组成的数组
sigma - 标准差
1 (默认值) | 正标量值 | 正标量值组成的数组
输出参数
y - pdf 值
标量值 | 标量值组成的数组
例如-画出正态分布 N(0,1) 和 N(0,4) 的概率密度函数图形进行比较
x=-6:0.01:6;%创建数组
y=normpdf(x);%根据x给的值输出新的值y,默认均值为0,方差为1
z=normpdf(x,0,2);%根据x给的值输出新的值z,均值为0,方差为4,标准差2
plot(x,y,x,z)%画图做对比
normrnd
正态随机数,r = normrnd(mu,sigma,m,n)生成mxn的随机矩阵,且all数服从均值为mu,标准差为sigma的正太分布。可以说有点类似rand
mu为平均数,sigma为标准差,m是行,n是列。
例如
clear
x=normrnd(0,1,10000,1);%均值为0,标准差为1,10000x1的随机数组
hist(x,50)%直方图绘画,分五十等分
注意:由于是随机数组,所以结果不一定和上面的图片一致,只要大致形状像正太分布就行。
接下来我们尝试以下10000x3的数组会是什么效果
clear
x=normrnd(3,2,10000,3);%均值为3,方差为2
hist(x,50)
看不清?放大细节看看
 chi2pdf
chi2pdf
卡方分布,只有一个参数,即自由度v。
clear
x=0:0.01:12;
y=chi2pdf(x,3);%自由度为3
plot(x,y)

chi2rnd
clear
x=chi2rnd(5,10000,1);%自由度为5的10000x1数组
hist(x,50) 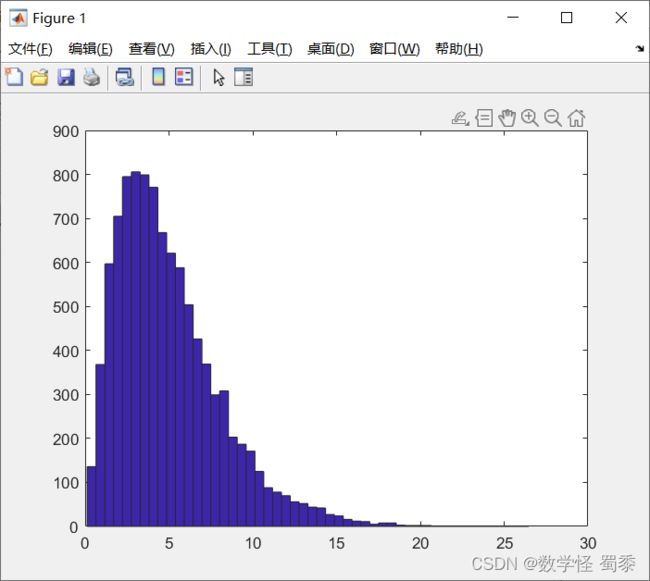
normcdf
概率分布p = normcdf(x,mu,sigma)
x - 用于计算 cdf 的值
标量值 | 标量值组成的数组
mu - 均值
0 (默认值) | 标量值 | 标量值组成的数组
sigma - 标准差

例如当mu=10,sigma=2时,计算P{8 [muHat,sigmaHat] = normfit(x) [muHat,sigmaHat,muCI,sigmaCI] = normfit(x) 此命令在显著性水平alpha(默认值为0.05,可以不设置)下估计数据x的参数. 返回的值muhat为均值 sigmahat为标准差 muci为均值的波动范围(置性区间) sigmaci为标准差的波动范围(置性区间) 例如某一组中学生的身高数据如下,计算他们的均值和标准差以及置性区间 摘要: 显著性水平(Significance Level)是指在假设检验中,研究者设定的一个阈值,用于判断观察到的效应是否具有统计学意义。通常用希腊字母α表示。显著性水平的取值范围在0到1之间,最常用的显著性水平为0.05和0.01。 在假设检验中,如果观察到的效应大于或等于显著性水平,那么我们拒绝原假设,认为研究结果具有统计学意义。如果观察到的效应小于显著性水平,那么我们无法拒绝原假设,认为研究结果不具有统计学意义。 例如,如果我们设定的显著性水平为0.05,那么当观察到的效应大于或等于0.05时,我们拒绝原假设;当观察到的效应小于0.05时,我们无法拒绝原假设。 显著性水平的选择取决于研究者的风险偏好和对结果的期望。较高的显著性水平意味着需要更大的效应才能拒绝原假设,因此可能会漏掉一些真实效应;较低的显著性水平则意味着更容易拒绝原假设,但同时也可能增加假阳性错误的风险。 最后,其他分布参数估计 前提:服从正态分布的情况下使用 已知标准差的前提,用来检验均值。 [h ,p,ci]= ztest(x,m,sigma,alpha,tail) x为已知数据,m为假设的均值数据,sigma为已知的标准差。 输出的参数: 119 117 115 116 112 121 115 122 116 118 109 112 119 112 117 113 114 109 109 118 未知标准差的前提,用来检验均值。 [h,p,ci]= ttest(x,m,alpha,tail) x为已知数据,m为假设的均值数据 输出的参数: 例如下面这组数据是某个月份的油价,用z检验油价均值是否等于128。 118 119 115 122 118 121 120 122 128 116 120 123 121 119 117 119 128 126 118 125
4.正态分布参数估计
[muHat,sigmaHat,muCI,sigmaCI] = normfit(x,alpha)clear
x=[167 179 168 170 173 175 165 169 177 176];%10个学生的身高
[a,b,c,d]=normfit(x)
5.假设检验
z检验
clear
x=[119 117 115 116 112 121 115 122 116 118 109 112 119 112 117 113 114 109 109 118];
[h,p,ci]=ztest(x,115,4)%默认tail=0,alpha=0.05.

t检验
clear
x=[118 119 115 122 118 121 120 122 128 116 120 123 121 119 117 119 128 126 118 125];
[h,p,ci]=ttest(x,128)
