《strstr()、strtok()、strerror()》函数讲解,全网最细干货!
文章目录
- strstr
-
- 第一种情况:
- 第二种情况:
- 第三种情况:
- 拓展:
- strtok
-
- 干货
- strerror
strstr
请先看函数标准:
头文件:# include


这个函数是字符串查找函数,意思是:在str1字符串中找str2字符串第一次出现的位置,如果没有找到str2,返回的是一个char*的空指针,如果找到了多个str2,则返回的是第一次str2出现的位置!!!
函数参数分析
char strstr 表示返回的一个指针*
char str1 表示目标空间的地址*
char str2 表示源空间的地址*
下面,我们实现一下函数功能,结合代码进行讲解:
第一种情况:
当str1字符串中包含了一次str2的字符串
#include 
当在str1中找到str2时,就会返回出现的str2字符串处地址。
第二种情况:
当str1中不包含str2字符串时

就会返回一个空指针!!!
第三种情况:
当str1中多次出现str2字符串时

返回的是第一次出现str2字符串处的地址!
strstr()函数的模拟实现
#include 拓展:
另外再给大家拓展两个函数:strchr() strrchr()
strchr()函数是**:假如说,在一个字符串中寻找字符b出现的位置,那么寻找的就是b第一次出现的位置,找到了就返回这个位置处的地址,没找到就i返回NULL**,上代码
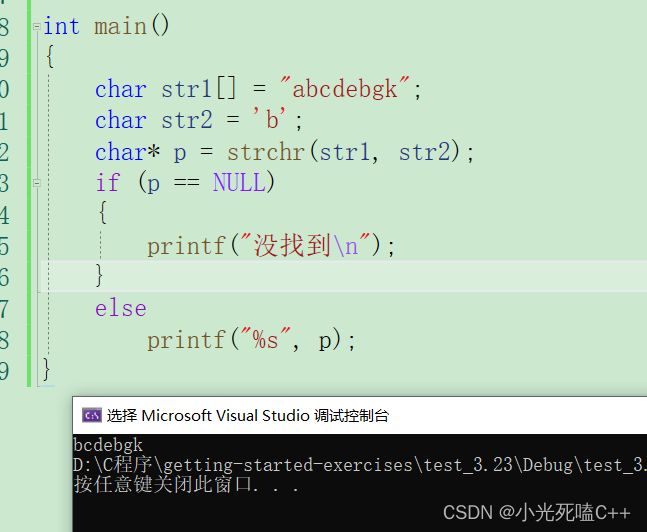
strrchr()函数是:与函数strchr()一样,也是在字符串中寻找字符,但是,它找到的是最后一次出现字符的位置,返回的是最后一次出现字符位置出的地址!上代码

strtok
下面给大家介绍一个函数,这个函数用起来可能有点古怪,下面请先看文件:


strtok()分割函数:
头文件:stdio.h
delimiters 表示参数是个字符串,定义了用作分隔符的字符集合
str 表示参数是一个字符串,它包含了由0个或多个由delimiters字符串中一个或多个分隔符分割的标记 !
意思就是是:delimiters 中的字符串就是被str中的某些字符切割开来的。
下面请看讲解:
比如有这样一个数组:
int main()
{
char str[] = "test.zbc/fgh@jkl";//假设这样一个字符串
char delimiters[] = "./@";//str中的字符串就是被这些字符给分开的。
}
干货
1、strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
什么意思呢?就是比如说在 "test . zbc/ fgh @ jkl"字符串中,当开始遍历字符串时,遍历完test时,就遇到了我们的分隔符,所以就把test当做一个标记。就把标记后面的一个 . 直接改成‘\0’,并且返回这个标记的指针,就是t的地址。还有就是,一般我们只是切割一下,但是并不想改变源字符串,所以把源字符串拷贝到另一个数组中。对另一个数组进行操作!
2、strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
3、strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
因为我们刚才已经查到 . 这个位置了,所以这个位置就会被保存,当下一次开始查找的时候,第一个参数传NULL,直接就从从==.==这个位置开始查找,所以在进行函数的第二次调用,第三次调用时,第一个参数就不要再传字符了,直接传空指针就行了。
下面用代码为大家解释:
int main()
{
char arr[] = "test.zbc/fgh@jkl";
char str[30] = { 0 };
strcpy(str, arr);
const char* p = "./@";
char * pc = strtok(str, p);
printf("%s\n", pc);
pc = strtok(NULL , p);
printf("%s\n", pc);
pc = strtok(NULL, p);
printf("%s\n", pc);
return 0;
}

但是看着有一些死板,如果这个分隔符很多,字符串很长的话,一直在后面调用strtok函数么,下面我们对这个代码进行优化!
int main()
{
char arr[] = "test.zbc/fgh@jkl";
char str[30] = { 0 };
strcpy(str, arr);
const char* p = "./@";
char* pc = NULL;
for (pc = strtok(str, p); pc != NULL; pc = strtok(NULL, p))//直接写成for循环的条件
{
printf("%s\n", pc);
}
return 0;
}
strerror
函数功能:返回错误码的错误信息
头文件:#include


我们可以看到它的接受参数是int errnum,它是在调用的时候传过去一个错误码数字,然后把这个数字转化成对应的错误信息,因为错误信息是个字符串,所以它的返回类型是char* 的,他把这个错误码的首字符地址给返回过去了。
下面实现一下这个代码:
int main()
{
char* ret = strerror(0);
printf("%s\n", ret);
ret = strerror(1);
printf("%s\n", ret);
ret = strerror(2);
printf("%s\n", ret);
ret = strerror(3);
printf("%s", ret);
return 0;
}

那这个函数就是这么用的么,其实并不然,这只是一个简单的演示,其实,C语言的库函数在调用失败的时候,会将一个错误码放在一个叫:errno的变量中,当我们想知道调用库函数的时候发生了什么错误信息,就可以将errno中的错误码翻译成错误信息:
下面代码演示一下:
#include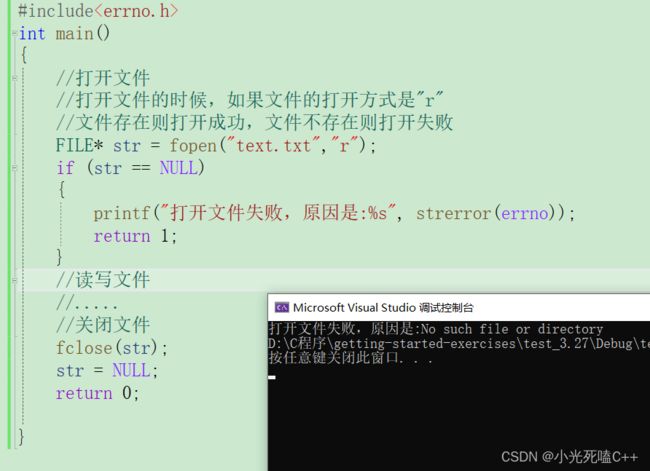
打开失败,因为在我们当前路径下面是没有text.txt的文件的

下面我们在当前路径里面创建一个text.txt的文件

看,现在就打开成功了!!!
还有要注意的一点是errno:
假如我们写了两个库函数:
库函数1 和库函数2,如果库函数1调用失败的话,如果不进行检查的话,库函数1的失败原因会存储到errno中,但是如果库函数2调用成功的话,会把errno中的错误信息给覆盖掉的!!!
关于errno这个函数就只是存储错误信息而已,方便以后在调用函数出错时查看错误信息,当然打印错误信息的函数我不得不再提一个,那就是perror 这个函数,这个函数更加直接:

他就自动在后面加上了错误信息!!!