【MYSQL】MYSQL 的学习教程(四)之索引失效场景
1. MySQL 索引失效原因
MySQL 索引失效原因:
- 查询条件包含 or,可能导致索引失效
- 隐式的类型转换,索引失效
- like 通配符 “%” 在关键词前面导致索引失效
- 在索引列上使用 MYSQL 的内置函数,索引失效
- 对索引列运算(如,
+、-、*、/),索引失效 - 索引字段上使用负向查询(
NOT、!=、<>、NOT IN、NOT LIKE)时,可能会导致索引失效 - 索引字段可以为 null,使用
is null,is not null,可能导致索引失效 - 违反了索引的最左匹配原则(联合索引,查询时的条件列不是联合索引中的第一个列,索引失效)
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效
- MYSQL 估计使用全表扫描要比使用索引快,则不使用索引
1.1 查询条件包含 or,可能导致索引失效
userId 有索引、age 没有索引:不走索引
select * from user where userId = '123' or age = 18
【解释】:即使它走了 userId 索引,但走到 age 查询条件时,它还得经历全表扫描,也就是需要三步:索引扫描 + 全表扫描 + 合并。如果一开始就进行全表扫描就完事了。MYSQL 优化器出于效率、成本考虑,遇见 or 条件,使索引失效,这样也合情合理
【注意】:如果 or 条件的列都加了索引,索引可能会走也可能不走
如果 or 条件不走索引,可考虑拆开两条 SQL 进行优化
【优化】:改成 UNION 或者 UNION ALL,分成多个 sql,走各自的索引
UNION 和 UNION ALL 的区别:
- 对重复结果的处理:UNION 会去掉重复记录,UNION ALL 不会
- 对排序的处理:UNION 会排序,UNION ALL 只是简单地将两个结果集合并
- 效率方面的区别:因为 UNION 会做去重和排序处理,因此效率比 UNION ALL 慢很多
1.2 隐式的类型转换,可能导致索引失效
MySQL 8.0 的官方文档规则描述了比较操作如何进行转换:
- 如果比较操作中的两个参数都是字符串,则将它们作为字符串进行比较
- 如果两个参数都是整数,则将它们作为整数进行比较
- …
- 在所有其他情况下,参数将作为浮点(双精度)数字进行比较。例如,字符串和数字操作数的比较是作为浮点数的比较进行的
num_int 字段是 int 类型,num_str 字段是 varchar 类型,且都建有各自的索引
# int 类型
SELECT * FROM `test1` WHERE num_int = 10000;
SELECT * FROM `test1` WHERE num_int = '10000';
# varchar 类型
SELECT * FROM `test1` WHERE num_str = 10000;
SELECT * FROM `test1` WHERE num_str = '10000';
在大数据量情况下,第一、二、四条 sql 执行时间相差无几;而第三条没有用上索引,所以执行时间较长
根据文档描述,我们知道第二、三条 sql 都发生了 隐式转换,”=“ 左右两边都会转换为浮点数再进行比较
第二条 sql:
SELECT * FROM `test1` WHERE num_int = '10000';
左边是 int 类型,只有值为 10000 的浮点数是 10000;右边是 varchar 类型的 '10000',那么转化为浮点数是 10000。两边的转换结果都是唯一确定的,所以不影响使用索引
第三条 sql:
SELECT * FROM `test1` WHERE num_str = 10000;
左边是 varchar 类型,不仅仅值为 '10000' 的浮点数是 10000,其他字符串也可以转换为 10000,比如:'10000a'、'010000'、'10000' 等等都能转为浮点数 10000;右边是 int 类型的,转化为浮点数 10000。由于 varchar 转化为浮点数并不唯一,所以,是无法使用索引的
总结
- 当操作符左右两边的数据类型不一致时,会发生隐式转换
- 当查询字段为数值类型时发生了隐式转换,那么对效率影响不大,但还是不推荐这么做
- 当查询字段为字符类型时发生了隐式转换,那么会导致索引失效,造成全表扫描效率极低
- 字符串转换为数值类型时,非数字开头的字符串会转化为 0,以数字开头的字符串会截取从第一个字符到第一个非数字内容为止的值为转化结果
所以,我们在写 SQL 时一定要养成良好的习惯,查询的字段是什么类型,等号右边的条件就写成对应的类型。特别当查询的字段是字符串时,等号右边的条件一定要用引号引起来标明这是一个字符串,否则会造成索引失效触发全表扫描
1.3 like 通配符,可能导致索引失效
select * from user where userId like ‘%123’
%在左边的时候:匹配字符串尾部的数据,由于尾部的数据是没有顺序的,所以不能按照索引的顺序查询,就用不到索引,就会使索引失效%在右边的时候:由于B+树的索引顺序,是按照首字母的大小进行排序,%号在右的匹配又是匹配首字母,所以可以在B+树上进行有序的查找,可以用到索引- 当首位都有
%时:这个是查询任意位置的字母满足条件即可,只有首字母是进行索引排序的,其他位置都是相对无序的,索引此时也是用不到索引的
问题:
既要 通配符在左边,且索引不失效
建立:覆盖索引
如:建立复合索引:(name, age)
select name
from test
where name like '%5'
1.4 在索引列上使用 MYSQL 的内置函数,索引失效
字段 create_time 建立索引
# 索引失效
select count(*) from tradelog where month(create_time) = 7;
# 索引生效
select count(*) from tradelog where create_time = '2018-7-1’
create_time 索引示意图(方框上面的数字就是 month() 函数对应的值):
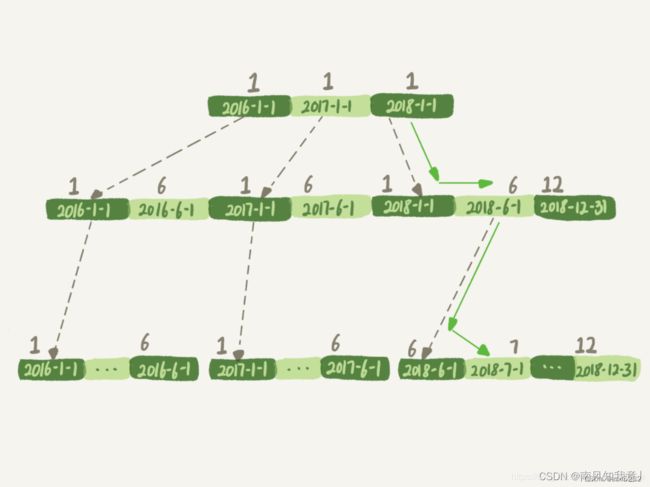
如果你的 sql 语句条件用的是 where create_time = '2018-7-1’ 的话,引擎就会按照上面绿色箭头的路线,快速定位到 create_time='2018-7-1’ 需要的结果
实际上,B+ 树提供的这个快速定位能力,来源于同一层兄弟节点的有序性
但是,如果计算 month() 函数的话,你会看到传入 7 的时候,在树的第一层就不知道该怎么办了
即:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能
1.5 对索引列运算(如,+、-、*、/),索引失效
同 1.4
1.6 索引字段上使用负向查询(NOT、!=、<>、NOT IN、NOT LIKE)时,可能会导致索引失效
这个也是跟 MYSQL 优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的话,它觉得不划算,不如直接不走索引
1.7 索引字段可以为 null,使用 is null, is not null,可能导致索引失效
- null 的列使索引/索引统计/值比较都更加复杂,对 MySQL 来说更难优化
- null 这种类型 MySQL 内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条件下,表中有较多空字段的时候,数据库的处理性能会降低很多
- null 值需要更多的存储空,无论是表还是索引中每行中的 null 的列都需要额外的空间来标识
- 对 null 的处理时候,只能采用
is null或is not null,而不能采用 in、<、<>、!=、not in 这些操作符号
1.8 违反了索引的最左匹配原则
MySQL 建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。在联合索引中,查询条件满足最左匹配原则时,索引才正常生效
复合索引 (name, age, pos)
# 情况一:索引生效
select name
from test
where name = 'zzc' and age = 22
# 情况二:索引失效
select name
from test
where age = 22 and pos = '11'
# 情况三:name 索引不失效,pos 索引失效
select name
from test
where name = 'zzc' and pos = '11'