【Git】Git基本操作

文章目录
- Git 是什么
- Git 的优点
- Git 安装
-
- Linux Ubuntu
- Linux CentOs
- Windows
- Git 基本操作
-
- 1. 创建 Git 本地仓库
- 2. 配置 Git
- 3. Git工作区、暂存区和版本库
- 4. 添加文件
- 5. 查看 .git 文件
- 6. 修改文件
- 7. 版本回退
Git 是什么
Git是一个免费的、开源的分布式版本控制系统,可以快速高效地处理从小型到大型的各种项目。它采用分布式方式,避免中心服务器的单点故障,保障系统的高可用性和稳定性。Git可以作为一种过渡方案来替代BitKeeper,帮助管理Linux内核开发等。总之,Git是一种高效、灵活的版本控制系统,适用于各种规模的项目,是开发人员和管理人员的得力工具。
假设我们在公司中,老板让我们完成一个项目的项目规划书,当我们花了三天写出来这个项目规划书之后,我们就将这个规划书给老板看,但是老板看了之后呢,觉得不满意,让你回去做修改。你又花了一天的时间在上次规划书的基础上对项目规划书做出了修改,你又交给了老板,让老板看修改的是否满意,但是老板还是不同意,又让你回去做出修改,于是你又花了一天的时间在上个规划书的基础上做出修改,这次你将修改后的规划书交给老板看,老板觉得还是不满意,并且说:“我觉得你第二次的项目书写的还不错,就使用第二次的为最终的项目规划书吧。”听到这,你脑子一晕,顿时想把这个项目规划书甩到老板的脸上说:“你耍我呢?”。
那么如何避免上面发生的问题呢?其实我们只需要将每次做出的修改的原稿给保存下来,当修改的时候我们不修改原稿,而是重新拿一个稿子,在之前规划书的基础上进行修改,这样就能够保存每次修改之后的规划书,当老板需要哪一份的时候,我们只需要拿出那个版本的原稿就行了。而我们的 Git 的作用就是这样的。
为了能够更⽅便我们管理这些不同版本的⽂件,便有了版本控制器。所谓的版本控制器,就是能让你了解到⼀个⽂件的历史,以及它的发展过程的系统。通俗的讲就是⼀个可以记录⼯程的每⼀次改动和版本迭代的⼀个管理系统,同时也⽅便多⼈协同作业。
⽬前最主流的版本控制器就是 Git。Git 可以控制电脑上所有格式的⽂件,例如doc、excel、dwg、dgn、rvt等等。对于我们开发⼈员来说,Git最重要的就是可以帮助我们管理软件开发项⽬中的源代码⽂件。
Git 的优点
- 分布式版本控制系统:Git是一个分布式版本控制系统,与传统的中央仓库版本控制系统不同。每个开发人员都可以在自己的本地仓库中进行版本控制,无需依赖中央仓库。这使得版本控制更加灵活,提高了团队协作的效率。
- 高效的性能:Git在版本控制方面具有高效的性能,能够快速地完成各种操作,如提交、查看历史记录、合并分支等。这使得开发人员能够更加专注于编码工作,而不是频繁地切换到版本控制工具。
- 强大的分支管理:Git提供了强大的分支管理功能,可以方便地创建、切换、合并分支。这使得团队协作更加方便,不同开发人员可以同时处理不同的功能分支,提高了开发效率。
- 回滚和撤销操作:Git提供了回滚和撤销操作功能,可以轻松地恢复到以前的版本或者撤销错误的操作。这使得开发人员能够更加放心地进行代码修改,减少了因为误操作而带来的损失。
- 跨平台支持:Git可以在各种操作系统上运行,包括Windows、Linux和Mac等。这使得开发人员可以在不同的平台上进行协作,提高了团队协作的效率。
- 强大的社区支持:Git是一个开源项目,拥有庞大的社区支持。开发人员可以轻松地找到相关的资料和解决方案,快速解决问题。同时,社区中还有很多开源项目和工具可以使用,进一步提高了开发效率。
注意事项:
还需要再明确⼀点,所有的版本控制系统,Git 也不例外,其实只能跟踪⽂本⽂件的改动,⽐如 TXT ⽂件,⽹⻚,所有的程序代码等等。版本控制系统可以告诉你每次的改动,⽐如在第5⾏加了⼀个单词 “Linux”,在第8⾏删了⼀个单词 “Windows”。
⽽图⽚、视频这些⼆进制⽂件,虽然也能由版本控制系统管理,但没法跟踪⽂件的变化,只能把⼆进制⽂件每次改动串起来,也就是只知道图⽚从100KB改成了120KB,但到底改了啥,版本控制系统不知道,也没法知道。
Git 安装
Linux Ubuntu
首先使用 git 命令,看是否已经下载 Git。
如果出现的是下面的页面,表示的是已经下载了 Git。

而出现了 Command 'git' not found, but can be installed with: 则表示未安装 Git。这时就需要使用 apt install git 命令来下载 Git。
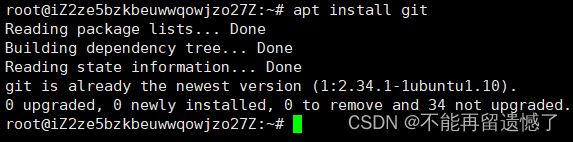
因为我这里之前下载过了,所以我是用上面的命令并没有真正下载。
当我们下载 Git 了之后,可以使用 git --version 查看自己的 Git 版本。

Linux CentOs
Linux CentOs 的查看和下载其实和 Ubuntu 差不多,只是下载 Git 的时候,CntOs 需要使用 yum 包管理器,所以就需要使用 yum install git 命令来下载。
Windows
Windows 下载的话大家就去看看这个视频。
https://www.bilibili.com/video/BV1hf4y1W7yT/?p=3&vd_source=b57c3f3e8a7507d4af7322c28f05fdbc
Git 基本操作

1. 创建 Git 本地仓库
仓库是进⾏版本控制的⼀个⽂件⽬录。我们要想对⽂件进⾏版本控制,就必须先创建⼀个仓库出来。
创建一个 Git 本地仓库的命令是 git init,命令要在文件目录下执行。
先使用 mkdir gitcode 创建一个文件目录,作为我们的 Git 本地仓库。

使用 mkdir 创建一个文件目录之后,创建的只是一个普通的文件目录,那么如何让他成为一个 Git 本地仓库呢?我们需要使用 git init 命令来创建一个 Git 本地仓库。
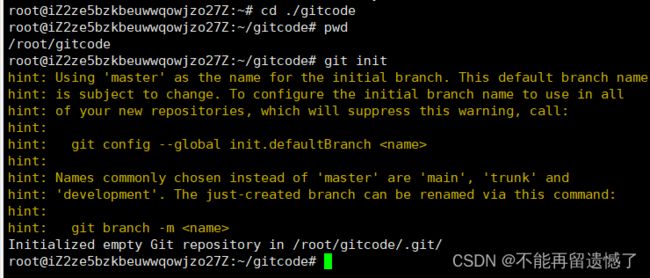
创建完成 Git 本地仓库之后,可以发现当前文件目录下出现了一个 .git 隐藏文件目录。

.git ⽬录是 Git 来跟踪管理仓库的,不要⼿动修改这个⽬录⾥⾯的⽂件,不然改乱了,就把 Git 仓库给破坏了。
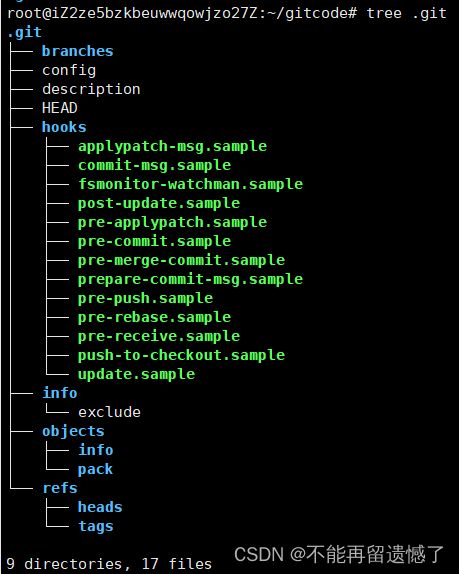
然后我们使用 tree .git命令,可以查看 .git 文件的目录结构。

这里每个结构是干什么的,我们现在先不管,后面会为大家介绍。
2. 配置 Git
在创建完成 Git 本地仓库之后,我们还需要对这个仓库进行配置,不然后面的操作可能就会出现问题,这点是非常重要的。
在这里我们主要配置的就是 用户名称 和 e-mail地址 。
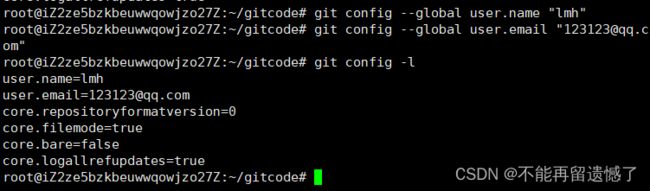
配置 Git 本地仓库的 用户名称 和 e-mail 地址需要用到 git config user.name "Your Name" 命令和 git config user.email "Your email"命令。

那么我们如何看到自己修改的配置呢?可以使用 git config -l 查看当前 Git 仓库的配置。

但是如果我们想要删除之前修改的配置该怎么做呢?可以使用 git config --unset user.name来删除某个配置。

这里我们删除配置了之后,虽然查看配置的时候,前面删除的配置项还可以看到,但是实际上我们不能够使用这些配置了。这是因为:
- 使用git config -l命令。这个命令会列出所有的Git配置项,包括那些已经被删除的配置项。这是因为Git配置是持久化的,即使你删除了某个配置项,它仍然会保留在.git/config文件中,只是不再被Git使用。
使用 git config user.name "Your Name" 命令配置的只是当前的 Git 本地仓库,但是我们本地可以有多个 Git 本地仓库,如果我们想要让设置的配置在本地所有 Git 仓库都生效的话,就需要在命令中添加 --global 选项。
如果我们使用的是 --global 选项修改的 Git 配置的话,在删除该配置的时候,也需要加上 --global 配置,否则就无法删除成功。
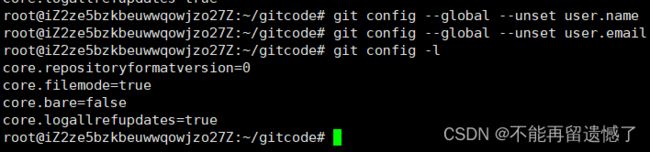
并且可以发现:跟不加 --global 配置不同,加上 --global 配置之后,删除配置,我们无法查看到删除的配置了。
3. Git工作区、暂存区和版本库

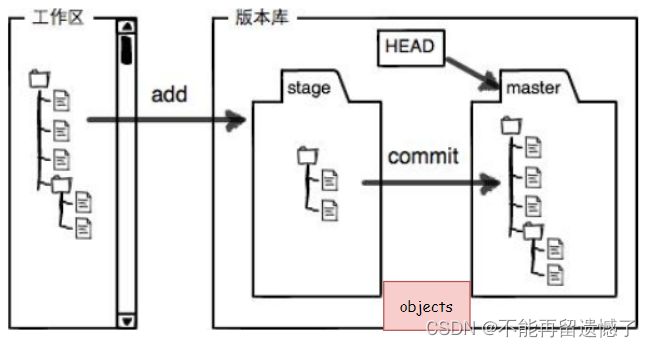
Git本地仓库包括三个主要区域:工作区、暂存区和版本库。
- 工作区(Working Directory):工作区是平时存放项目代码的地方,也就是你克隆项目到本地后,项目所在的文件夹目录。你在工作区中对代码进行的修改、新增、删除等操作,都需要经过Git的处理才能被记录。
- 暂存区(Stage/Index):暂存区用于临时存放你的改动,事实上只是一个文件,保存即将提交到文件列表信息。当你使用git add .命令时,会将本地所有新增、变更、删除过的文件的情况存入暂存区中。这个区域的存在是为了让你在提交前,能够再次确认和审查你的改动。
- 版本库(Repository):版本库用于安全存放数据的位置,这里面有你提交到所有版本的数据。当你使用git commit –m “本次操作描述”命令时,会将添加到暂存区的修改的文件提交到本地仓库中。在版本库中,HEAD指针会指向最新放入仓库的版本。你可以随时回退到任何一个历史版本,或者比较不同版本之间的差异。
工作区通常在我们 Git 本地仓库除 .git 文件目录之外的其他文件目录和文件;暂存区则是在 .git 文件目录下的 index 文件(.git/index),我们把暂存区也叫做索引(index);我们的 .git 文件目录则是版本库。
在创建 Git 版本库时,Git 会为我们⾃动创建⼀个唯⼀的 master 分⽀,以及指向 master 的⼀个指针叫 HEAD。(分⽀和HEAD的概念后⾯再说)
但是我们使用 tree .git 命令的时候为什么没有看见 index 文件呢?
这是因为这个 Git 本地仓库是我们新创建的,还没有 add 和 commit,所以也就没生成 index 文件。
当对⼯作区修改(或新增)的⽂件执⾏ git add 命令时,暂存区⽬录树的⽂件索引会被更新。
当执⾏提交操作 git commit 时,master 分⽀会做相应的更新,可以简单理解为暂存区的⽬录树才会被真正写到版本库中。
通过新建或粘贴进⽬录的⽂件,并不能称之为向仓库中新增⽂件,⽽只是在⼯作区新增了⽂件。必须要通过使⽤ git add 和 git commit 命令才能将⽂件添加到仓库中进⾏管理!!!
4. 添加文件
当我们在工作区完成修改之后,需要使用 git add [file1] [file2]命令将修改的文件添加进去暂存区中。

git add 后面可以有多个参数,也就是 git add [file1] [file2]... 一次 add 多个文件,git add 不仅可以支持参数为文件,参数也可以是目录;使用 git add . 是将当前目录下所有修改过的文件添加进暂存区中。
git commit 使用的时候需要加上 -m 选项以及此次 commit 的描述,这部分内容是绝对不可以省略的,并要好好描述,因为这是⽤来记录你的提交细节,是给我们⼈看的。如果我们不加 ReadMe 文件名的话,就是使用 git commit -m "描述" 的话,意思就是将暂存区中所有的内容提交到本地仓库中。

commit 之后出现的日志会显示出我们本次提交的描述以及提交了多少个文件,和文件中插入或者减少了多少行内容。
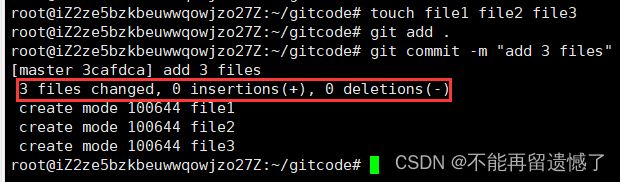
这次我们没在文件中写入数据,所以这里的插入就是0。
使用 git log 可以查看历史提交记录。
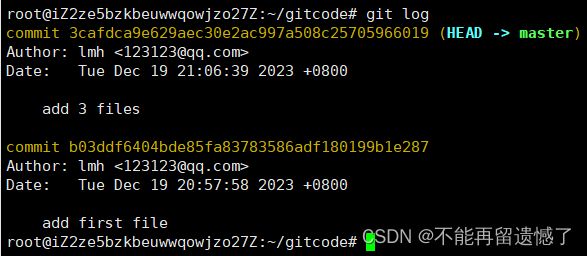
git log 显示的内容是时间由据现在由近及远的顺序。
(Head -> master)表示 Head 指针指向的 master 文件中的位置。
如果我们觉得 git log 显示的数据看的不是很方便,我们可以添加 --pretty=oneline 选项,使得显示的数据更加美观。

这里的 3cafdca9e629aec30e2ac997a508c25705966019 是 commit id,它不是由简单的 1、2、3 得来的,而是经过了哈希计算得来的哈希值。
5. 查看 .git 文件

当我们进行了 add 和 commit 操作之后,就会发现,跟之前的 .git 文件不同,这里新出现了 index(暂存区)和 objects 文件/文件夹。
HEAD 就是我们默认指向的 master 分支的指针:



objects 为 Git 的对象库,⾥⾯包含了创建的各种版本库对象及内容。当执⾏ git add 命令时,暂存区的⽬录树被更新,同时⼯作区修改(或新增)的⽂件内容被写⼊到对象库中的⼀个新的对象中,就位于 “.git/objects” ⽬录下。
objects 文件夹中的每个 object 文件都是工作区每次修改的文件内容,也就是说,其实实际数据是存放在 object 文件中的,而暂存区(索引)和 master 中存放的只是对应的每个 object 文件的索引。当使用 add 操作将工作区中修改的内容提交到暂存区中的时候,在暂存区中会生成一个 object 文件和对应的索引文件,object 文件中存放的是 add 的文件中的内容,而索引文件中存放的是对应的 object 文件的索引;当使用 commit 操作之后,也是讲暂存区中存在的索引文件提交到 master 文件中而已。
而通过观察 commit id 和 .git/objects 文件可以发现其实 commit id 可以分为两个娃部分:其前2位是⽂件夹名称,后38位是⽂件名称。
3cafdca9e629aec30e2ac997a508c25705966019

找到这个⽂件之后,⼀般不能直接看到⾥⾯是什么,该类⽂件是经过 sha (安全哈希算法)加密过的⽂件,但是我们可以使⽤ git cat-file 命令来查看版本库对象的内容。
使用 git cat-file 需要加上 -p 选项。

查看这个文件之后,会出现我们前面设置的 用户名称 和 用户邮件地址,以及 tree,那么这个 tree 是什么意思呢?我们继续看 tree 中的 commit id。
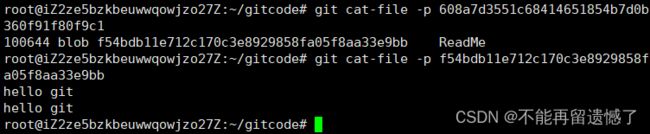
这个 tree 对象表示提交时的项目状态(即文件和目录的布局)。tree 对象并不包含实际的项目数据,只包含文件和目录的元数据。它基本上就是一个指向实际文件的符号链接。
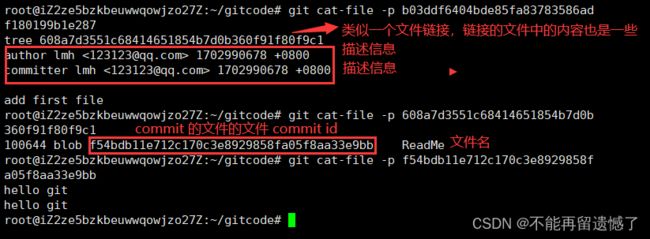
这个是我们第一次提交的,根据 commit id 观察出来的内容,而通过第二次 commit id 我们可以观察出额外的信息。

parent 部分显示的是该 commit 的父 commit。一个 commit 有多个父 commit 的情况叫做 merge commit。一个标准的提交(不是 merge commit)只有一个父 commit,那就是它前一次的提交。通过跟踪这些父 commit,你可以回溯到历史上的任意提交,这是 Git 版本控制的核心功能之一。
要想将工作区中修改的文件提交到版本库中,需要经过 add 操作和 commit 操作,先将修改的文件添加到暂存区,然后在添加到版本库中才可以,如果少了 add 操作,是无法完成提交的。

这里只有 file4 被添加进了版本库中,而 file5 由于没有 add,所以并没有最终添加到版本库中。

6. 修改文件
当我们对文件做了修改的话,需要重新使用 add 操作和 commit 操作,将修改的文件添加进版本库中。
什么是修改?⽐如你新增了⼀⾏,这就是⼀个修改,删除了⼀⾏,也是⼀个修改,更改了某些字符,也是⼀个修改,删了⼀些⼜加了⼀些,也是⼀个修改,甚⾄创建⼀个新⽂件,也算⼀个修改。
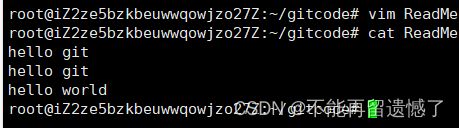
此时,仓库中的 ReadMe 和我们⼯作区的ReadMe是不同的,如何查看当前仓库的状态呢? git status 命令⽤于查看在你上次提交之后是否有对⽂件进⾏再次修改。

使用 git status 显示出来的数据表示 ReadMe 文件被修改,并且当前文件等待被 add。
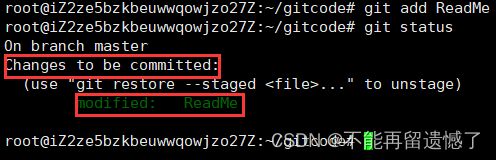
使用 add 之后再查看仓库状态可以看到 ReadMe 文件被修改,并且这个文件等待被 commit。

当修改文件之后,我们又如何查看我们修改的内容吗?当然可以,虽然我们可以直接查看文件中的内容,然后对比差异,但是如果文件修改的内容较多且间隔时间较长,我们又该如何区别呢?
git diff [file] 命令⽤来显⽰暂存区和⼯作区⽂件的差异,显⽰的格式正是Unix通⽤的diff格式。也可以使⽤ git diff HEAD -- [file] 命令来查看版本库和⼯作区⽂件的区别。

- diff --git a/ReadMe b/ReadMe:这行表示正在查看ReadMe文件在两个不同版本之间的差异。
- index 6b15c4f…7945298 100644:这行提供了有关文件的元数据。index 6b15c4f…7945298表示原始版本的文件内容由SHA-1哈希值6b15c4f标识,而新版本的文件内容由7945298标识。100644是文件的权限模式,表示这是一个普通文件。
- — a/ReadMe:这行表示原始版本的文件是ReadMe,位于a/目录下。
- +++ b/ReadMe:这行表示新版本的文件是ReadMe,位于b/目录下。
- @@ -1,3 +1,4 @@:这行表示差异的开始。-1,3表示原始文件的开始到第3行(不包括第3行),而+1,4表示新文件的开始到第4行(不包括第4行)。
- hello git、hello git、hello world:这些行显示了原始文件的内容。
- +hello world:这行表示在新文件中添加了“hello world”这一行。
7. 版本回退
前面说了 Git 能够管理文件的历史版本,这也是版本控制器的重要能力,就相当于我们前面的项目规划书,就类似前面的项目规划书,因为版本的管理,已经存在了三个版本的规划书,老板说让你在第二个版本的基础上进行修改,那么这时候你只需要拿出第二个版本的规划书的原稿就可以了。
如果只是回退工作区中的文件的话,可以直接用 git checkout [fikeName]来回退。

那么在 Git 中使用 git reset 命令用于版本的回退。git reset 命令语法格式为: git reset [--soft | --mixed | --hard] [HEAD]。
- –mixed 为默认选项,使⽤时可以不⽤带该参数。该参数将暂存区的内容退回为指定提交版本内容,工作区⽂件保持不变。
- –soft 参数对于工作区和暂存区的内容都不变,只是将版本库回退到某个指定版本。
- –hard 参数将暂存区与工作区都退回到指定版本。切记工作区有未提交的代码时不要⽤这个命令,因为工作区会回滚,你没有提交的代码就再也找不回了,所以使⽤该参数前⼀定要慎重。
- HEAD 说明:
-
- 可直接写成 commit id,表⽰指定退回的版本
-
- HEAD 表⽰当前版本
-
- HEAD^ 上⼀个版本
-
- HEAD^^ 上上⼀个版本
-
- 以此类推…
- 可以使用 〜 数字表示:
-
- HEAD~0 表⽰当前版本
-
- HEAD~1 上⼀个版本
-
- HEAD^2 上上⼀个版本
-
- 以此类推…
我们先准备下数据:


假设我们现在需要将该文件恢复到第二次提交的情况,那么就需要更改工作区、暂存区和版本库中的数据,那么就需要用到 --hard 选项。
通过观察test1文件中的内容和 git log --pretty=oneline 显示的数据我们可以看到当前 test1 的版本已经回到了第二次的版本了。

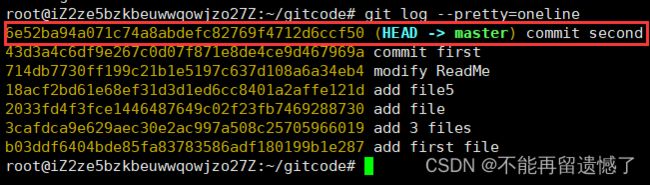
如果我们现在又想回到第三个版本的话,该怎么办呢?前面说了 git reset 命令后面的参数可以是 commit id,所以我们就可以将后面的参数改为第三次提交的 commit id。
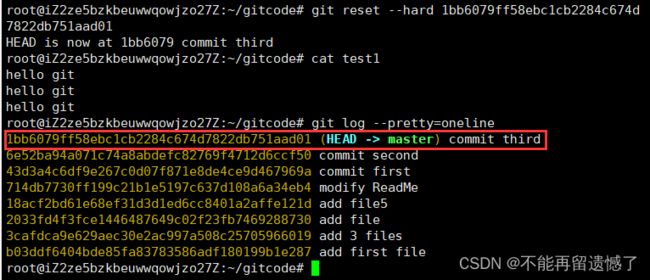
虽然我们可以使用 commit id 回退到指定的版本,但是如果我们因为工作时间太长,不能够直接从终端找到 commit id 或者 commit id 丢失了之后的话,别着急,我们可以使用 git reflog 补救一下,该命令⽤来记录本地的每⼀次命令。
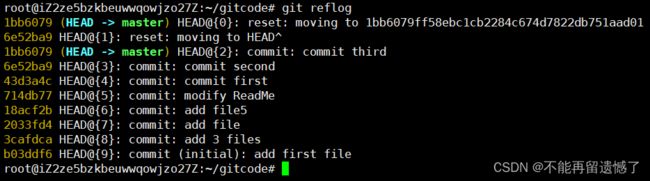
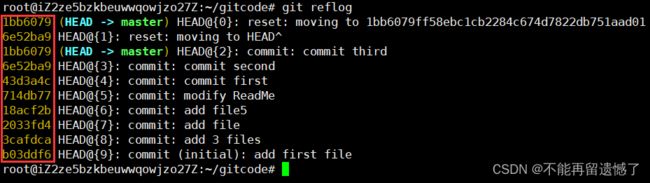
这里并没有出现前面类似的 commit id ,而是出现了 1bb6079 这样的数字,那么这是什么呢?这其实是 commit id 中的一部分,通过 commit id 的这一部分是可以回到指定的版本的。
值得说的是,Git 的版本回退速度⾮常快,因为 Git 在内部有个指向当前分⽀(此处是master)的 HEAD 指针, refs/heads/master 文件⾥保存当前 master 分⽀的最新 commit id 。当我们在回退版本的时候,Git 仅仅是给 refs/heads/master 中存储⼀个特定的version,可以简单理解成如下⽰意图:
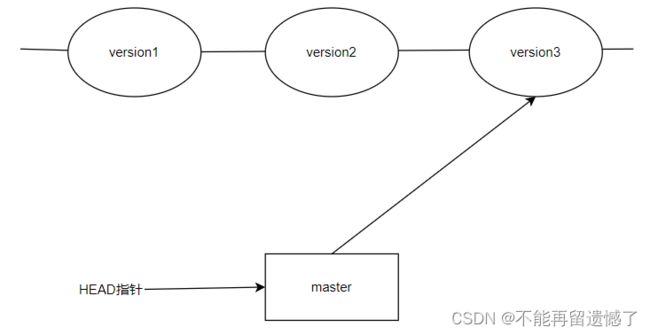
当需要回退的时候,只需要更改 .git/refs/heads/master 中存储的 version 版本就可以了。

使用 git reset 的前提是,在 commit 之后没有使用 push 操作将本地仓库的文件提交到远程仓库中,如果已经 push 将本地仓库的文件提交到远程仓库的话,再使用 git reset 的话,远程仓库的文件是没有修改的,而如果有远程仓库的话,我们最终看的还是远程仓库的文件,所以使用 git reset 的前提是没有将本地仓库的文件 push 到远程仓库之前。