python-YoloV5模型目标检测实现CS2自瞄
文章目录
- 前言
- 一、下载YoloV5仓库
- 二、图片截取
-
- 1.使用PIL
- 2.使用mss
- 三、调用模型
- 四、自动瞄准函数
- 五、绑定热键
- 六、效果展示
- 七、写在最后
前言
在我的前几篇文章中,已经实现的基于Zynq 7010开发板实现的HID模拟鼠标。现在尝试通过YoloV5模型实现一个自动瞄准辅助。
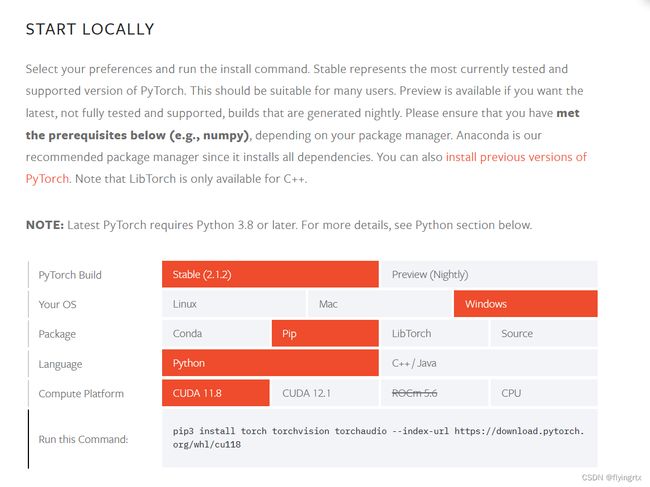
首先确保已经安装了pytorch,若没有可以前往pytorch官网进行安装,其官网提供了一键命令,非常方便
一、下载YoloV5仓库
前往yolov5的github项目仓库,克隆到本地
yolov5 github网址
git clone https://github.com/ultralytics/yolov5.git
安装其要求库
pip install -r requirements
下载后,可以先熟悉一下yolov5的使用方法,可参考其官方文档,我这里给出一个示例,后面的图片路径换成你自己的:
# 在终端中调用其detect.py
python detect.py --source ..\test.png
具体参数很多,这里不一一列出。可以在其文件夹run->exp**文件夹下查看结果:

首次运行后,会下载一个yolov5s.pt的权重文件在项目地址下
二、图片截取
我的想法是获取一个以准星为中心的一个矩形图片,例如640*640,下面介绍两种截图的方法。主要用到pyautogui(获取鼠标位置)、pillow(截图方案1)、mss(截图方案2)三个库。此外opencv、numpy等是必需的因为会在模型调用中用到。
1.使用PIL
import pyautogui
from PIL import ImageGrab, ImageShow
def screen_catch():
mouse_x, mouse_y = pyautogui.position()
box = (mouse_x - half_size, mouse_y - half_size, mouse_x + half_size, mouse_y + half_size)
screen_shot = ImageGrab.grab(box)
# ImageShow.show(screen_shot) # 显示图片
screen_shot_cv = cv2.cvtColor(np.array(screen_shot), cv2.COLOR_RGB2BGR) # 把PIL捕获的图片转换成opencv支持的格式
return screen_shot_cv
2.使用mss
from mss import mss
def screen_catch():
with mss() as sct:
mouse_x, mouse_y = pyautogui.position() # 获取鼠标当前位置
monitor = {"top": mouse_y - size // 2, "left": mouse_x - size // 2, "width":size, "height": size}
screenshot = sct.grab(monitor)
# 将截图数据转换为OpenCV格式
img = np.array(screenshot)
img = cv2.cvtColor(img, cv2.COLOR_RGBA2BGR)
return img
其实一开始我是使用PIL库的,然后发现其截图速度过慢,一张960*960大约需要50ms,换到mss库后截图时间下降到10ms左右
三、调用模型
现在编写一个函数,我希望调用这个函数时,自动截图并返回当前画面的模型检测结果
调用模型的部分主要参照yolov5文档即可
from models.common import DetectMultiBackend
from utils.general import (check_img_size, cv2, non_max_suppression)
from utils.torch_utils import select_device
from utils.plots import Annotator, colors, save_one_box
from utils.augmentations import letterbox
from pathlib import Path
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
# Load model
device = select_device('')
weights = ROOT / 'Yolov5ForCSGO/yolov5s.pt' # model.pt path(s)
data = ROOT / 'Yolov5ForCSGO/data/coco128.yaml' # dataset.yaml path
model = DetectMultiBackend(weights, device=device, dnn=False, data=data, fp16=False)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz=(size, size), s=stride) # check image size
bs = 1 # batch_size
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
def run(
imgsz=(size, size),
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
):
img0 = screen_catch() # 捕获原始图片
img = letterbox(img0, imgsz, stride=32, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
im = torch.from_numpy(img).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
pred = model(im, augment=augment, visualize=visualize)
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
for i, det in enumerate(pred): # per image
if len(det):
# 取消注释以实时显示检测结果
# annotator = Annotator(img0, line_width=3, example=str(names))
# im0 = annotator.result()
# for *xyxy, conf, cls in reversed(det):
# c = int(cls) # integer class
# label = names[c]
# annotator.box_label(xyxy, label, color=colors(c, True))
# cv2.imshow('the result', im0)
# cv2.waitKey(1) # 1 millisecond
return det
else:
print(f"无结果")
return None
四、自动瞄准函数
现在再编写一个函数,期望实现当调用这个函数时,auto_aim函数即可调用刚才的run函数获取模型检测值,然后根据检测值决定鼠标移动量,最后移动鼠标
def auto_aim():
result = run(
imgsz=(size, size)
)
if result is None:
return 0, 0
list_class = []
det = result
delta_x_final = 0
delta_y_final = 0
all_need = 99999
for *xyxy, conf, cls in reversed(det):
c = int(cls)
label = model.names[c]
list_class.append(label)
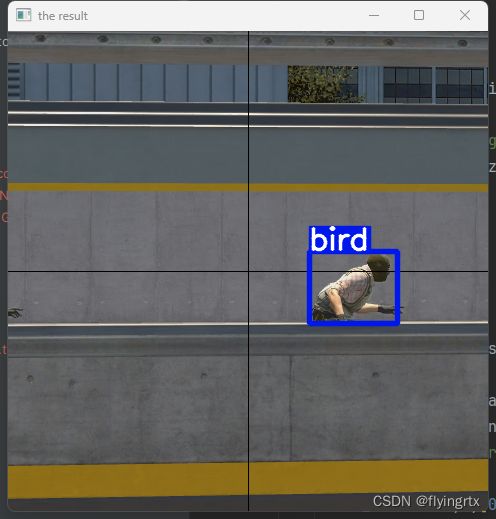
if label != 'person': # 可能会检测到其他物体、如鸟、火车等等,只对人进行瞄准
continue
delta_x, delta_y, all_need_move = delta_calculate_person(xyxy)
if all_need_move <= all_need:
delta_x_final = delta_x
delta_y_final = delta_y
all_need = all_need_move
move(delta_x_final, delta_y_final) # 此处的move鼠标移动我通过开发板实现,也可以用python的pynput、pyautogui等等库实现类似效果
return delta_x_final, delta_y_final
def delta_calculate_person(xyxy):
x_start = xyxy[0].item()
x_end = xyxy[2].item()
x_总长 = x_end - x_start
y_start = xyxy[1].item()
y_end = xyxy[3].item()
y_总长 = y_end - y_start
找头系数 = 0.1
if x_总长 <= 30 and y_总长 >= 100:
找头系数 = 0.1
delta_x = (int(x_start / 2 + x_end / 2) - half_size)
delta_y = int(y_start) - half_size + int(y_总长 * 找头系数)
all_need_move = abs(delta_x) + abs(delta_y)
return delta_x, delta_y,all_need_move
五、绑定热键
最后,尝试把自瞄函数绑定到一个按键上,按下按键即可完成瞄准操作,我通过python keyboard库实现绑定到alt键,这个选择很多,方便即可
if __name__ == '__main__':
import keyboard
keyboard.add_hotkey('alt', auto_aim)
keyboard.wait('esc+esc') # 不会同时按下esc+esc,即不会退出循环
六、效果展示
注:在此处训练场时,我在move后增加了一行代码,即瞄准后立即开枪,形成瞬狙效果。
七、写在最后
最后不得不说,yolov5s的模型其实无法很好适配cs2人物,蹲下后难以检测,对于苍蝇头CT探员更是难以辨别,因此若要加强该脚本,仍需针对CS2人物地图进行模型训练,目前尚不能很好运用于实战