python爬虫 - 猿人学第十九题突破ja3指纹验证
前言
(来csdn做备份,某客园的审核机制太蛋疼...)
废话不多说,直接干,再来猿人学19题
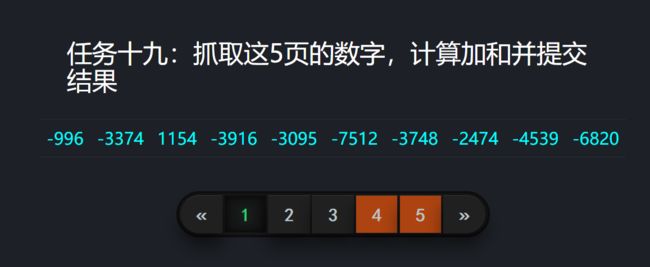
分析
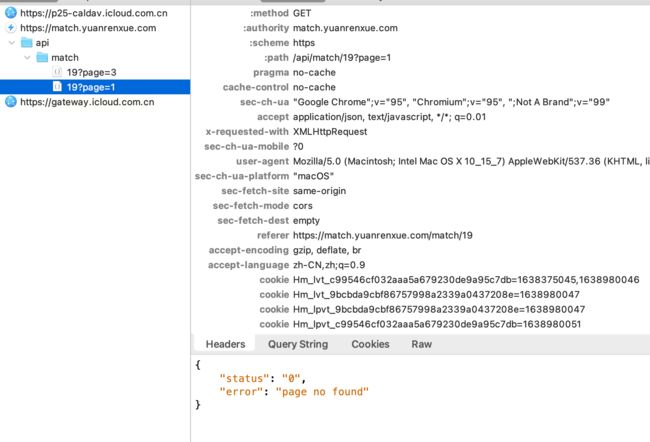
看了下,没有加密参数:

然后拿着接口直接请求:

有结果的,不会吧,这么简单?没有加密参数?这次这么草率?
用代码访问,唉,卧槽,就是他妈的不行,果然有猫腻

换requests:
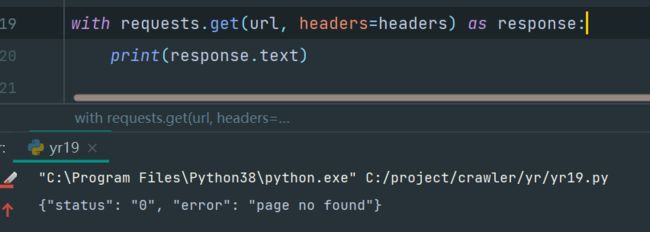
确实不行,
用postman看看,可以的

这他妈就很秀啊,上一次这种感觉还是http2.0的时候,但是上面我已经用了httpx了啊,也不行,说明就不是http2.0了。
这种无力感,接着又想到上次验证请求头,把请求头写死看看:

果然也不是,那肯定,相同的反爬策略应该不会再考一次,
好骚啊,就是无法正常返回结果,那他肯定验证了某个东西,怎么办,再看下,用curl呢:
也不行,我直接在浏览器的编辑脚本界面snippets里执行,发现可以有结果
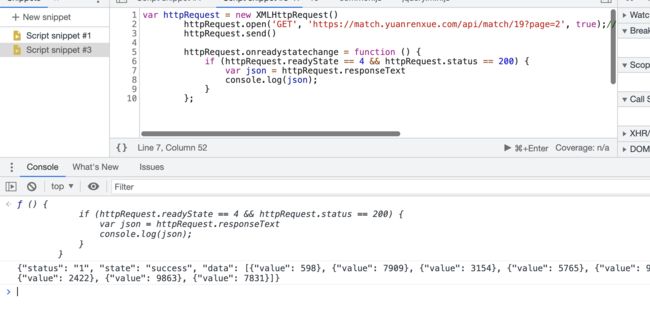
那就只有抓包看看了,当我打开charles抓包时,有这个提示:
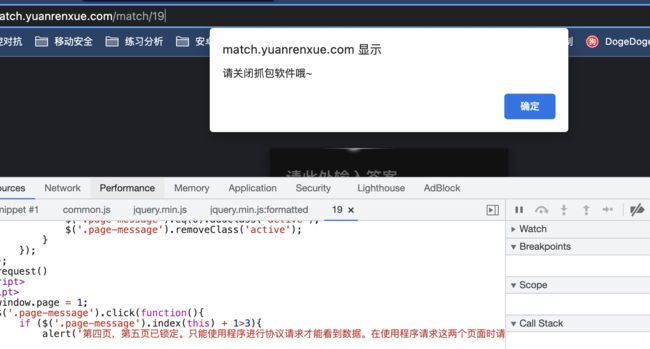
然后看抓包软件拿到的东西,这个问题,在抓包软件里终于复现了
那就看下到底它检测了什么东西,能够识别抓包工具和爬虫脚本了
后续我接着研究,发现这个网站好像针对性的对mac端做了检测,因为我windows端开抓包工具是可以抓到的:
charles:
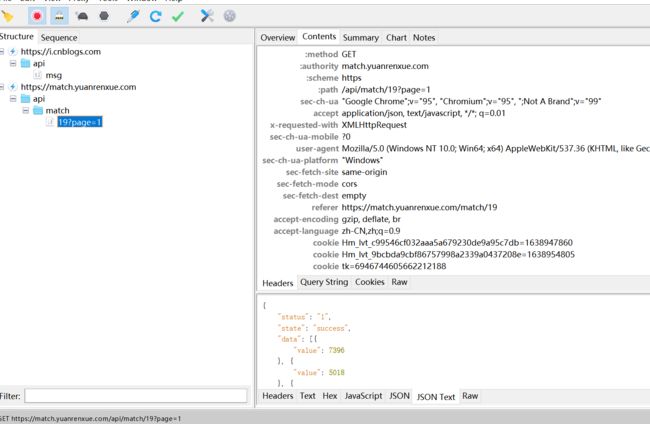
fiddler:

然后,我来了个神操作,这他妈出来了,好骚啊
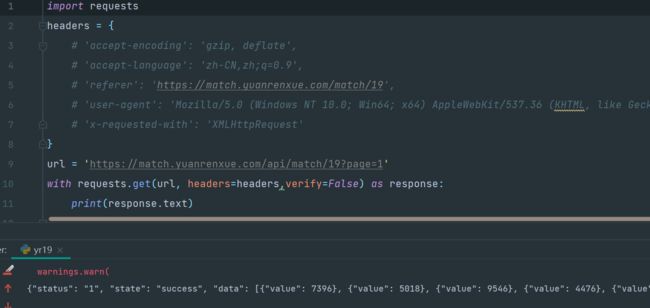
同时,上面的操作,我是开着fiddler可以的,把fiddler一关再请求,又不行了:
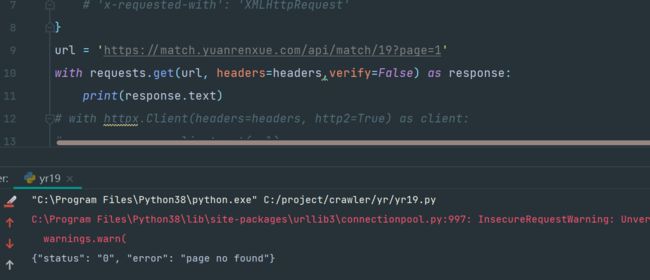
继续开上fiddler,然后把请求头放开:
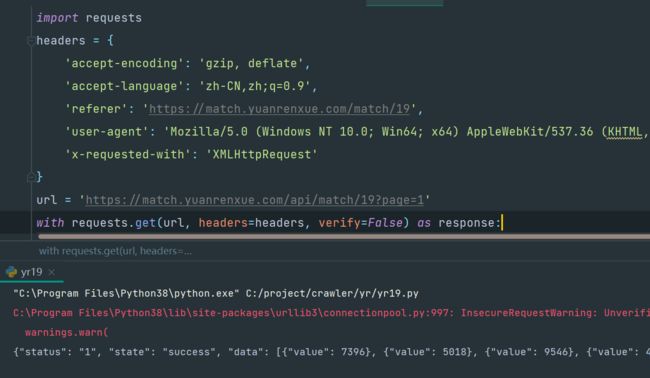
那说明验证的并不是请求头了,那此时你会不会想,一直开着fiddler然后请求,得出结果并提交就完了,但是这样一点都不符合我们程序员的套路,那以后遇到这种网站,而项目要部署在服务器上的,你不可能一边开着个抓包工具,一边请求吧,况且服务器用的都是linux,没记错,fiddler没有linux版啊
所以,还得是从原理上入手
那么思考下,开了fiddler跟没开fidder有什么区别,最容易想到的代理证书的区别。fiddler伪造证书,有关中间人攻击的理论就不说了,详细的可以百度
那还有个区别,利用中间人攻击原理,让服务端以为fiddler是客户端,而不再是爬虫脚本
到底是哪个原因?
还是先上个wireshark抓包吧:
需要用最新版的wireshark才能看到ja3指纹,因为ja3指纹是基于tls1.3的,旧版的wireshark只能看到tls1.2及以下的
最新版下载地址:https://www.wireshark.org/download.html
这是浏览器请求一个接口的数据
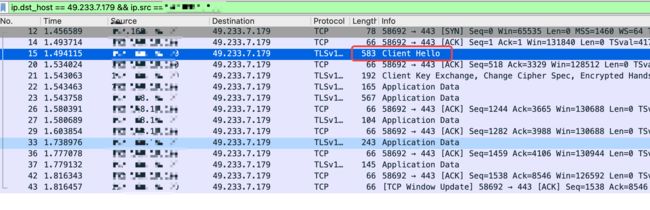
这是爬虫程序请求一次接口的数据:
卧槽,一眼就能看出来,这也太大区别了吧,所以,接下来就是分析区别了
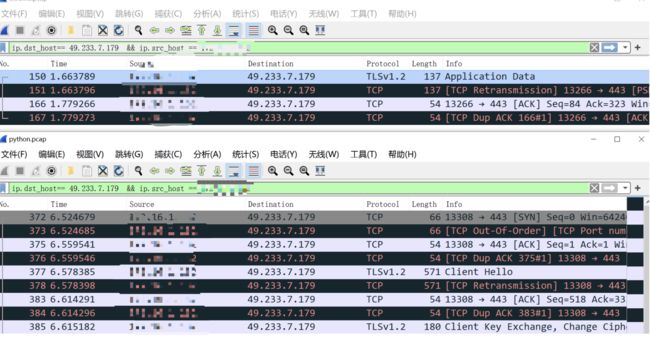
先看浏览器的:
选中那个【client Hello】包,展开最后这个
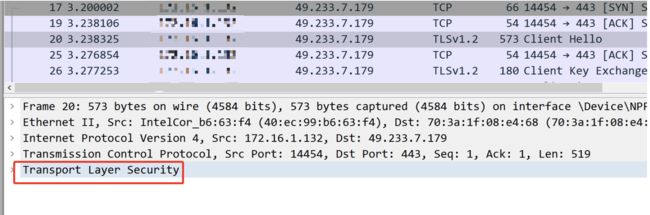
展开
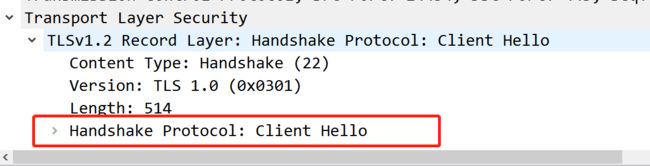
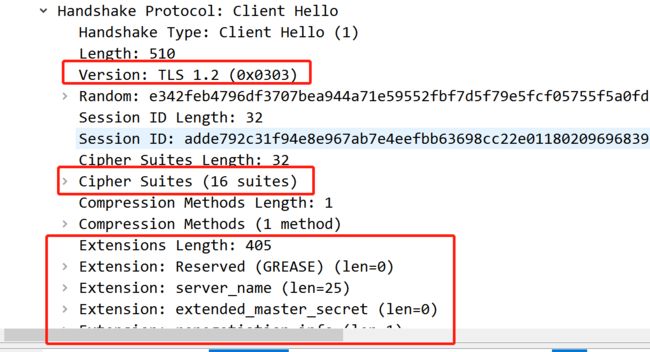
滑到最后,这他妈不就是ja3指纹算法吗
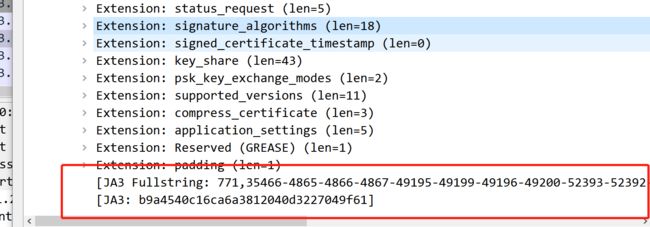
卧槽了
有关ja3指纹的,可以看这篇文章:为什么随机 IP、随机 UA 也逃不掉被反爬虫的命运
这好骚啊,也就是说,他用了ja3指纹,识别到了你用的python的请求库去请求,所以直接给你返回【page not found】。
那么怎么办?ja3指纹也伪造吗?按照理论,是不是把浏览器的指纹也伪造就可以了?那么现在的关键点来了,怎么找到浏览器的指纹呢?
再看,最后有个字段,b9开头的,不知道是不是,

复制-值
b9a4540c16ca6a3812040d3227049f61
现在再看下python脚本的指纹:
找到hello包:
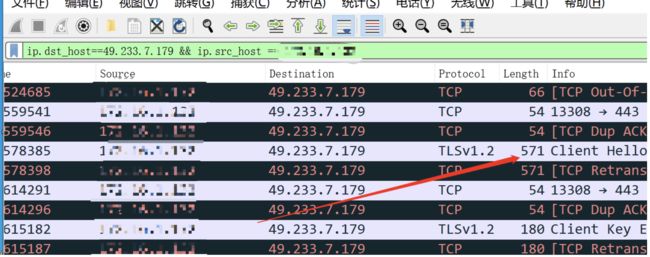
看到这个,记一下,
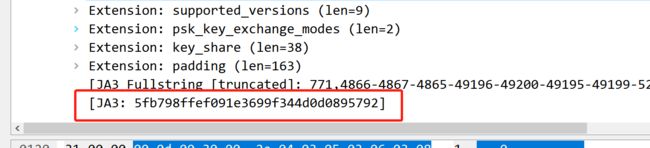
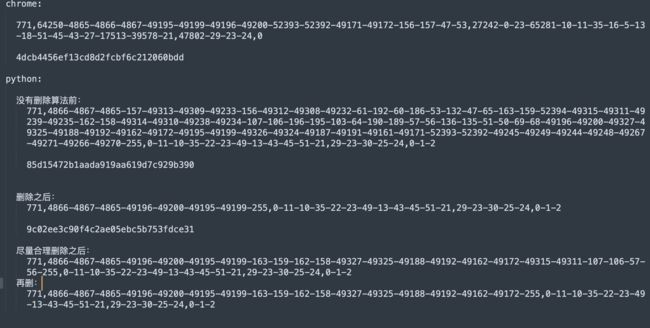
总结了下不同机制出现的ja3指纹
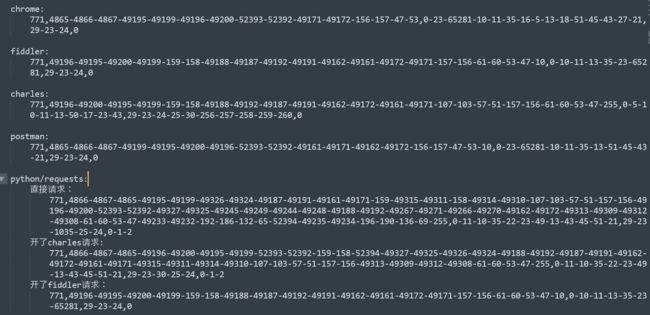
所以,从这个就可以很明显的发现不同了,长度啊,明显很长的都是不通过的,为什么那么长,说明底层的加密算法用的不一样啊,这就是原因了
那现在这个关键的问题,怎么做到跟浏览器一样啊,以前我们写爬虫,伪造跟浏览器一样,改了请求头就行了,可现在这个指纹,怎么改啊
先看一篇文章,一个黑客大佬写的,里面介绍了4种方法:SSL 指纹识别和绕过 | AresX's Blog
1.访问ip指定host绕过waf
上文提到过,套了阿里云waf的服务器cname解析到了yundunwaf3.com的域名,这种情况可以直接ping 域名获取真实ip,然后请求地址设置为真实ip 在 HTTP Header的Host字段中指定域名即可绕过waf的防护
当然这种方式如果目标服务器开启了强制域名访问会失效
2.代理中转请求
在本地启动代理服务器,如Burp Suite,发起http请求时指定代理服务器为burp的地址,让burp来进行TLS握手,算是一种曲线救国的方法
3.更换request工具库
Requests其实是对urllib3的一个封装,那python有没有不用urllib的http request库呢?
翻了翻aiohttp的源码发现貌似并没有用urllib3,抓包发现tls指纹和requests也有着明显的差异
实际测试aiohttp确实没有被拦截
4.魔改requests
从根本上解决问题,debug跟踪到了几处可能可以修改TLS握手特征的代码
/usr/local/lib/python3.9/site-packages/urllib3/util/ssl_.py
4个方法里,第一个,不行,我直接把域名替换成了host,仍然如此,说明不是cdn式的防护,第二个,开代理,这个我在windows+fiddler可以,mac下不行,这里也就解释上面为啥开fiddler可行,第三个,我换了httpx和aiohttp,都不行。
那就只剩第四个方法了,而,前面介绍ja3指纹的博主,也说了怎么魔改ja3指纹的:点我
先把代码拷贝下来看,执行看看能不能用:
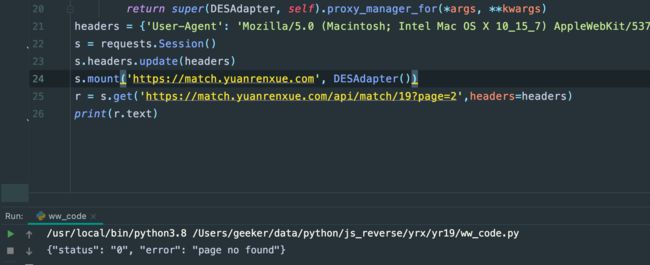
发现不行,因为其实目标不一样,上面的原贴的代码是为了欺骗对方,我不是同一个电脑发出的请求,而是多个,所以用了random.shuffle来乱序算法,达到每次出来都不是同一个ja3指纹,而这里我们要的是欺骗服务器,我们用的是浏览器访问,而不是爬虫程序访问
看ja3指纹的对比就知道,差太多了
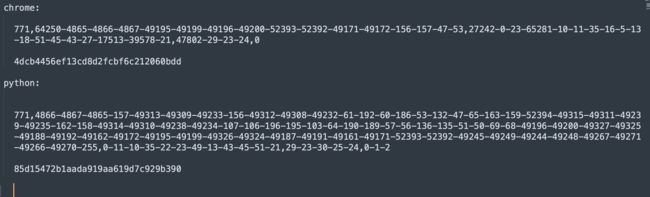
所以并不是说青南大佬(上面介绍ja3的国内大佬,公众号未闻code那个)的代码不行,只是不符合这里的场景
说白了就是指纹长度过长了,而且用random.shuffle,改变了一些算法顺序,那这第4个方法也不行吗?
那就无解了啊,查阅了大量资料,好多文章都是直接复制粘贴青南大佬的那篇,剩下的都是些介绍ja3原理的,找到个py库:pyja3,点我 我还以为有人写了个破解库呢,给我整的老激动了,结果仔细一看就是说可以从pcap文件里提取出ja3指纹字符串出来,此时此刻对于这里遇到的问题来说,没有用
相关破解和绕过的,只找到这一篇:点我,里面的代码跟青南大佬的代码几乎没区别,唯一的就是没有对加密算法进行random.shuffle。
得,继续看源码吧,看能不能找到点灵感,看下最原始的ssl的加密算法部分,以下这个是源码
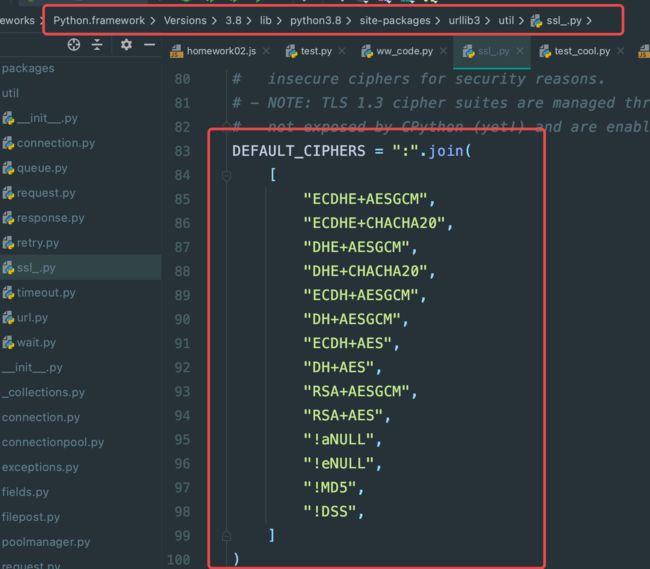
我突然想到,那行,既然就是长度不一样,长度不一样的原因就是用的算法不一样了,那我肯定没法再加算法,我删点试试呢?
我把圈出来的删了
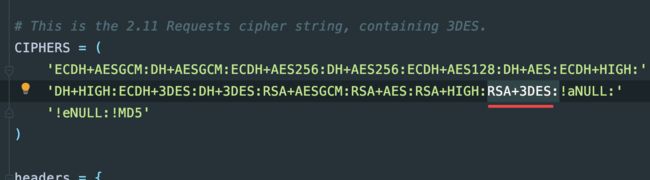
同时把__init__部分删了,因为模板场景不同
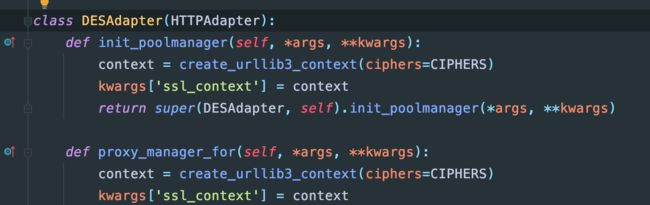
执行,还是不行:
当我开始一个个测试,一会儿删前面,一会儿删后面的,一会儿随机删一个或者两个
反正最后的结果都是不行,此时,根据我的经验,我突然想起,以前搞过的那些js加密过后很长的加密字段,都是用了很多次加密算法得算法得出来的,所以我大胆猜测,还是加密算法用的太多了,我直接删好几个加密算法看看:
我直接把下面选中都删了:
如下,一执行,发现,可行了
再看指纹:
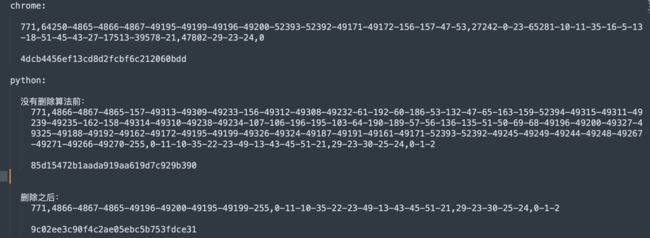
虽然搞出来了,有点激动,但是别急哈,从长远角度考虑,先看ja3指纹,确实变短了好多,不过已经比浏览器还短了,那假如某个网站要验证长度不能比浏览器的海长呢? 所以一定删到尽量跟浏览器一致
最后结果我的测试,把选中的都删了:
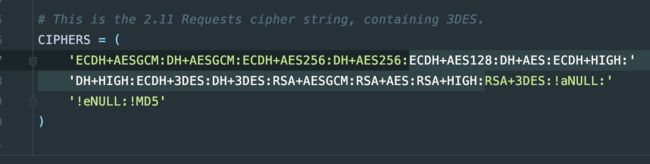
这样就可以了:
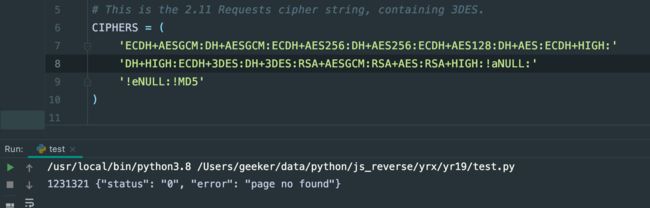
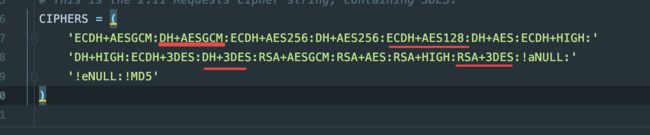
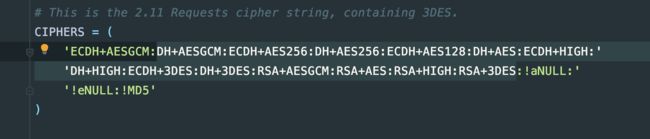
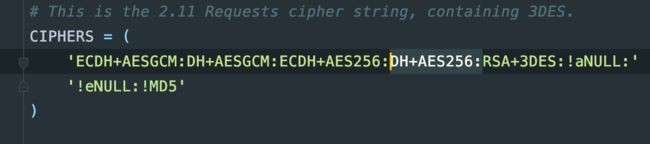
CIPHERS = (
'ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:!aNULL:'
'!eNULL:!MD5'
)
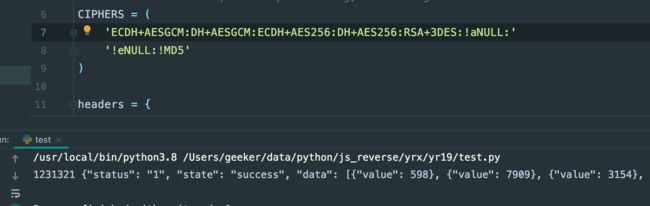
再看ja3指纹,最后的长度已经跟浏览器很接近了
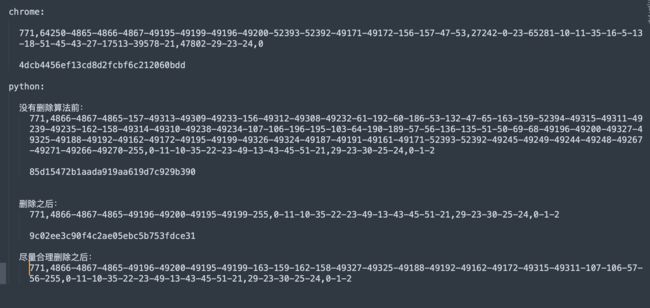
感觉还是有点长,再删一个:
看指纹,此时感觉又比浏览器还短了,那不行,就还是上面那个了
python调试
代码:
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.ssl_ import create_urllib3_context
# This is the 2.11 Requests cipher string, containing 3DES.
CIPHERS = (
'ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:!aNULL:'
'!eNULL:!MD5'
)
headers = {
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'user-agent': 'yuanrenxue.project',
'x-requested-with': 'XMLHttpRequest',
'cookie': 'sessionid=换成你的sessionid'
}
class DESAdapter(HTTPAdapter):
def init_poolmanager(self, *args, **kwargs):
context = create_urllib3_context(ciphers=CIPHERS)
kwargs['ssl_context'] = context
return super(DESAdapter, self).init_poolmanager(*args, **kwargs)
def proxy_manager_for(self, *args, **kwargs):
context = create_urllib3_context(ciphers=CIPHERS)
kwargs['ssl_context'] = context
return super(DESAdapter, self).proxy_manager_for(*args, **kwargs)
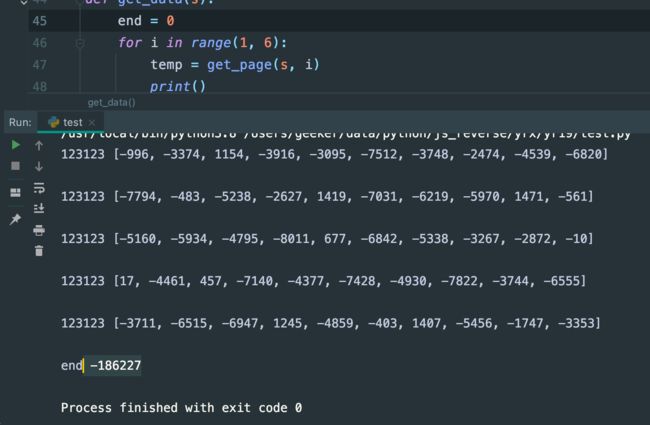
def get_page(s, page):
r = s.get(f'https://match.yuanrenxue.com/api/match/19?page={page}', headers=headers)
res = r.json()
data = res.get('data')
s = [int(d.get('value')) for d in data]
print(123123,s)
return s
def get_data(s):
end = 0
for i in range(1, 6):
temp = get_page(s, i)
print()
end += sum(temp)
print('end', end)
return end
s = requests.Session()
s.mount('https://match.yuanrenxue.com', DESAdapter())
get_data(s)
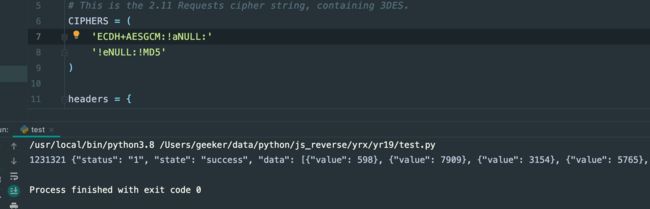
运行:
提交
结语
其实也没啥技术含量,就是刚出来没多久的ja3指纹验证,其他都没啥
那么,就真的这样吗?有了这个开头,相信以后很多网站都会用到这个
然后你再看上面的ja3指纹的截图,还有个很明显的特征,看最后一个数值,浏览器的是【0】,而这里是【0-1-2】,假如模板服务器验证了最后一个数字一定是【0】呢?怎么搞?我试了下,好像还没找到能直接为0的
我试了如下的,最后的数字都没法是【0】
- ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:!aNULL:!eNULL:!MD5
- ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:!aNULL:!eNULL
- ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:!aNULL
- ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:!NULL
- ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:NULL
- ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:RSA+3DES:0
你可以自己试试了。更多的ja3,自行研究了。
更多的解释
可以看我在公众号里写的深度剖析ja3指纹:深度剖析ja3指纹及突破
这里就不贴了,之前发过,玛德,被人机翻成英文放到外网去了,还有人抄袭我的内容在csdn开付费专栏,真他妈牛逼,还不给原帖地址,以后有质量的文章都不发csdn了