prometheus相关概念
prometheus相关概念
在安装好Prometheus后,会暴露一个/metrics的http服务(相当于安装了prometheus_exporter),通过配置,Prometheus就可以采集到这个/metrics下的所有监控样本数据.
样本
Prometheus会将所有采集到的监控样本数据以时间序列的方式保存在内存数据库中,并且定时保存到硬盘上.时间序列是按照时间戳和值的序列顺序存放的,我们称之为向量,每条时间序列通过指标名称和一组标签集命名.如下所示,可以将时间序列理解为一个以时间为X轴的数字矩阵:

在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric): 指标名和描述当前样本特征的标签集合
- 时间戳(timestamp): 一个精确到毫秒的时间戳
- 样本值(value): 一个float64的浮点型数据表示当前样本的值
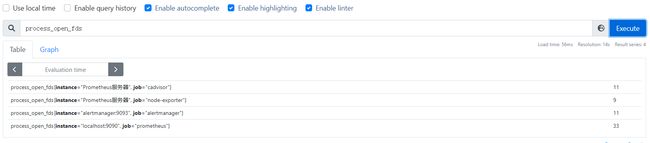
示例:

前面一段为指标名,中间那段为标签后面那段为时间戳和样本值
指标(Metric)
在形式上,所有的指标(Metric)都通过如下格式表示:
{ 指标的名称(metric name)可以反映被监控样本的含义(比如,process_open_fds-表示当前系统打开的文件描述),指标名称由ASCll字符,数字,下划线以及冒号组成必须符合正则表达式
[a-ZA_:][a-zA-Z0-9_]
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等.标签的名称只能由ASCll字符,数字,下划线以及冒号组成必须符合正则表达式.
其实以下划线作为前缀的标签,是系统保留的关键字,只能在系统内部使用.标签的值则可以包含任何Unicode编码的字符.在Prometheus的底层实现中指标名称实际上是以name = 形式保存在数据库中的,因此以下俩种方式均表示同一条time-series:
process_open_fds{instance="Prometheus服务器", job="cadvisor"}
等同于:
{_name_="process_open_fds",instance="Prometheus服务器", job="cadvisor"}
指标(Metric)的四种类型
Prometheus底层存储上其实没有对指标做类型的区分,都是以时间序列的形式存储,但是为了方便用户的使用和理解不同监控指标之间的差异,Prometheus定义了counter(计数器),gauge(仪表盘),histogram(直方图),以及sunmmary(摘要)这四种指标类型.
Gauge/Counter是数值指标,代表数据的变化情况,Histogram/Summary是统计类型的指标,表示数据的分布情况
在Exporter返回的样本数据中,其注释中也包含了该样本的类型.例如:
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.19.3"} 1
Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置).常见的监控指标.如http_request_total,node_cpud都是Counter类型的监控指标.一般定义Counter类型指标的名称是推荐使用_total作为后缀.
通过Counter指标可以统计HTTP请求数量,请求错误数,接口调用次数等单调递增的数据,同事可结合increase和rate等函数统计变化速率
例如,通过PromQL内置的聚合rate()函数获取HTTP请求量的评价增长率:
rate(promhttp_metric_handler_requests_total[5m])
查询当前系统中访问量前十的HTTP地址
topk(10,promhttp_metric_handler_requests_total)
Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态.因此这类指标的样本数据可增可减.常见指标如:node_memory_memFree_bytes(主机当前空闲的物理内存大小),node_memory_MemAvailable_bytes(可用内存大小)都是Gauge类型的监控指标.
通过Gauge指标,通过ProQL可以直接查看系统的当前物理内存大小:
node_memory_MemFree_bytes

对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况.例如,计算CPU温度在俩个小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
还可以使用deriv()计算样本的线性回归模型,甚至使用predict_linear()对数据的变化趋势进行预测.例如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_avail_bytes{}[1h],4*3600)

需要将最终结果78637829682.74074/1024/1024/1024得到最终GB为单位的空间大小
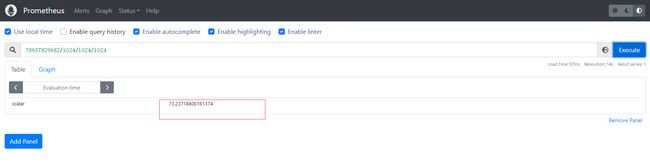
也就是73GB左右
Histogram :直方图
Histogram 会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中。但这句话还是不太好理解,下面通过具体的示例来说明。
假设我们想监控某个应用在一段时间内的响应时间,最后监控到的样本的响应时间范围为 0s~10s。现在我们将样本的值域划分为不同的区间,即不同的 bucket,每个 bucket 的宽度是 0.2s。那么第一个 bucket 表示响应时间小于等于 0.2s 的请求数量,第二个 bucket 表示响应时间大于 0.2s 小于等于 0.4s 的请求数量,以此类推。
Prometheus 的 histogram 是一种累积直方图,与上面的区间划分方式是有差别的,它的划分方式如下:还假设每个 bucket 的宽度是 0.2s,那么第一个 bucket 表示响应时间小于等于 0.2s 的请求数量,第二个 bucket 表示响应时间小于等于 0.4s 的请求数量,以此类推。也就是说,每一个 bucket 的样本包含了之前所有 bucket 的样本,所以叫累积直方图。
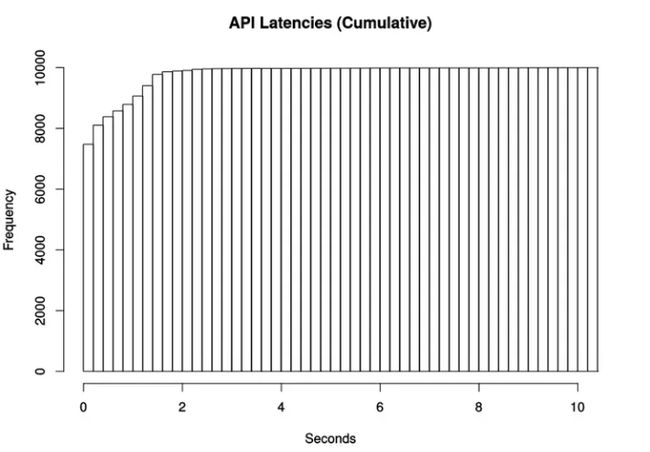
分位数计算
Prometheus 通过 histogram_quantile 函数来计算分位数(quantile),而且是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的。预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
假设有 10000 个样本,第 9501 个样本落入了第 8 个 bucket。第 8 个 bucket 总共有 368 个样本,其中第 9501 个样本在该 bucket 中属于第 93 个样本。
Summary:摘要
摘要用于记录某些东西的平均大小,可能是计算所需的时间或处理的文件大小,摘要显示两个相关的信息:count(事件发生的次数)和 sum(所有事件的总大小)
例如,指标 prometheus_tsdb_wal_fsync_duration_seconds 的指标类型为 Summary,它记录了 Prometheus Server 中 wal_fsync 的处理时间,通过访问 Prometheus Server 的 /metrics 地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
Job(任务)和instances(实例)
概述
在Prometheus中,任何被采集的目标,即每一个暴露监控样本数据的HTTP服务都被称为一个实例,例如在当前主机上运行的node exporter可以被称为一个实例.而具有相同采集目的的实例集合称为任务.
Job(任务)
例如,一下2个复制实例的node
* job: node
* instances 2:1.2.3.4:9100
* instances 4:5.6.7.8:9100
instances(实例)
通过在Prometheus.yml配置文件中,添加如下配置,我们让Prometheus可以从node exporter暴露的服务中获取监控指标数据.
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node_exporter:9100']
labels:
instance: Prometheus服务器
可以在targets处配置多个地址进行监控