REDIS集群安装运维调优及常见问题处理
上篇详细阐述了redis集群的安装搭建以及集群监控变更相关运维操作,本篇继续对redis集群调优和常见问题的解决进行介绍。
一、集群调优
1.1 Linux 内存内核参数优化:
Vm.overcommit_memory
参数说明: 文件指定了内核针对内存分配的策略,其值可以是0、1、2。
- 0:表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存, 内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
- 1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
- 2:表示内核允许分配超过所有物理内存和交换空间总和的内存。
建议该参数设置为1
1.2 网络参数优化:
# 允许存在time_wait状态的最大数值,超过则立刻被清楚并且警告
# 默认是262144, 防止过多的time_wait导致端口资源被耗尽
net.ipv4.tcp_max_tw_buckets = 6000
# 允许系统打开的端口范围,
# 默认状态下系统自身可自动使用的端口范围是 32768 ,61000,
net.ipv4.ip_local_port_range = 10000 65000
# 启用timewait 快速回收 ,在nat环境存在问题
net.ipv4.tcp_tw_recycle = 1
# 开启重用。允许将TIME-WAIT sockets 重新用于新的TCP 连接。
net.ipv4.tcp_tw_reuse = 1
# 开启SYN Cookies,当出现SYN 等待队列溢出时,启用cookies 来处理。
net.ipv4.tcp_syncookies = 1
# 定义了系统中每一个端口最大的监听队列的长度
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
# 处于半连接状态的最大链接数,防止过多异常链接导致系统异常
net.ipv4.tcp_max_syn_backlog = 262144
# 时间戳可以避免序列号的卷绕, 在nat 环境会导致故障
net.ipv4.tcp_timestamps = 0
# 建立连接syn+ack 与syn 包重试次数
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2系统打开最大文件数设置:
fs.file-max:系统所有进程一共可以打开的文件数量
[root@elk-server etc]# sysctl -a | grep file
fs.file-nr = 4416 0 52565136
fs.file-max = 52565136Fs.file-nr:这个是一个状态指示的文件,一共三个值:
- 第一个代表全局已经分配的文件描述符数量
- 第二个代表自由的文件描述符(待重新分配的)
- 第三个代表总的文件描述符的数量。
cat /proc/sys/fs/file-nr
编辑 /etc/sysctl.conf
fs.file-max=52550148重启生效
查看和设置 Linux 当前用户的资源设置情况
swap设置:
为提高redis整体性能 ,避免redis内部的热数据被在内存不足的情况被交换到磁盘,读取数据的时候相应缓慢,建议尽量不使用swap或者禁用swap。对于内部不足 最好的方法还是扩大内存。
临时生效:
sysctl -w vm.swappiness=0
永久生效:
echo "vm.swappiness = 0">> /etc/sysctl.conf(尽量不使用交换分区,注意不不是禁用)
刷新SWAP:可以执行命令刷新一次SWAP(将SWAP里的数据转储回内存,并清空SWAP里的数据)
swapoff -a && swapon -a
sysctl -p (执行这个使其生效,不用重启)
或者直接关闭 swap
swapoff -a
并修改文件 /etc/fstab 注释掉swap行,并重启永久生效

关闭透明大页(Transparent Huge Pages):
在redis实例启动时候会报如下警告:
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
意思是:你使用的是透明大页,可能导致redis延迟和内存使用问题
执行以下命令可修复该问题:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
永久解决方案:
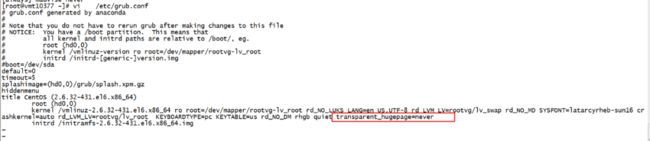
修改内核参数 /boot/grub/grub.conf
添加transparent_hugepage=never numa=off

重启生效
open-file:
用户会话级别的文件打开的最大数
[root@elk-server configs]# cat /etc/security/limits.conf | grep -v '#' | grep -v '^$'
* soft nofile 102400
* hard nofile 1024001.3 Redis配置参数调优:
禁用rdb持久化 rdb 持久化会导致redis实例频繁的做fork操作,fork 创建一个子进程,比较耗费资源。
- 在访问量比较大的系统中(特别是更新/插入比较频繁的系统中),会产生大量的增量数据,系统刷新大量的增量数据到磁盘会严重导致性能波动。
- rdb会丢数据
- 建议设置为 save “”
设置 maxmemory
默认值是 0,表示不限制内存使用,会导致系统资源被耗尽。建议根据项目系统需求设置一个最大值,但不建议单实例超过20gb。
设置timeout 超时时间
防止大量空闲链接占用大量资源 ,建议设置将超时链接设置为3600s Timeout 3600
slowlog-max-len
设置1000,记录慢查询的条数,默认128 ,增加该值,方便排查系统异常等问题。
tcp-backlog默认
TCP接收队列长度,受以下两个内核参数的影响:
- /proc/sys/net/core/somaxconn
- tcp_max_syn_backlog
在高并发的环境下,你需要把这个值调高以避免客户端连接缓慢的问题。
数据持久化策略
数据持久化策略 ,以场景为主
appendonly: 是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率。
appendfsync: appendonlylog如何同步到磁盘(三个选项,分别是每次写都强制调用fsync、每秒启用一次fsync、不调用fsync等待系统自己同步)。可以设置为 no,everysec,always
- no:只需让操作系统在需要时刷新数据。速度快。
- everysec (默认):fsync每秒只有一次。折中。
- always:每次写入仅附加日志后的fsync。慢,最安全。
发送使用fsync的默认策略,每秒写入性能仍然很好(使用后台线程执行fsync,并且当没有fsync正在进行时,主线程将努力执行写入。)建议设置为 everysec.
数据淘汰策略 待确认
maxmemory-policy 六种方式 :
- volatile-lru:只对设置了过期时间的key进行LRU(默认值)
- allkeys-lru :是从所有key里 删除 不经常使用的key
- volatile-random:随机删除即将过期key
- allkeys-random:随机删除
- volatile-ttl:删除即将过期的
- noeviction:永不过期,返回错误
建议设置为 volatile-ttl
repl-diskless-sync 启用无盘复制
复制过程中产生的rdb文件不落盘,避免造成过大的io,影响性能 该参数默认no
建议设置为 no
repl-disable-tcp-nodelay
是否启用TCP_NODELAY,如果启用则会使用少量的TCP包和带宽去进行数据传输到slave端,当然速度会比较慢;如果不启用则传输速度比较快,但是会占用比较多的带宽。
no-appendfsync-on-rewrite
bgrewriteaof机制,在一个子进程中进行aof的重写,从而不阻塞主进程对其余命令的处理,同时解决了aof文件过大问题。
现在问题出现了,同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形。
现在no-appendfsync-on-rewrite参数出场了:如果该参数设置为no,是最安全的方式,不会丢失数据,但是要忍受阻塞的问题。如果设置为yes呢?这就相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。
丢失多少数据呢?在linux的操作系统的默认设置下,最多会丢失30s的数据。因此,如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
tcp-keepalive
发送redis服务端主动向空闲的客户端发起ack请求,以判断连接是否有效 ,默认值为 0 ,表示禁用,可以通过tcp-keepalive配置项来进行设置,单位为秒。假如设置为60秒,则server端会每60秒向连接空闲的客户端发起一次ACK请求,以检查客户端是否已经挂掉,对于无响应的客户端则会关闭其连接。所以关闭一个连接最长需要120秒的时间。如果设置为0,则不会进行保活检测。默认为0
cluster-slave-validity-factor
设置slave断开master的时间因子在进行故障转移的时候全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了导致数据过于陈旧,不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长。
判断方法是:比较slave断开连接的时间和(node-timeout * slave-validity-factor)+ repl-ping-slave-period如果节点超时时间为三十秒, 并且slave-validity-factor为10,假设默认的repl-ping-slave-period是10秒,即如果超过310秒slave将不会尝试进行故障转移。
cluster-node-timeout
Cluster 集群中节点互联超时时间 ,默认15s
cluster-require-full-coverage
默认是yes
集群所有主节点状态为ok才提供服务。建议设置为no,可以在slot没有全部分配的时候提供服务。
cluster-migration-barrier
cluster-migration-barrier默认值
只有当一个主节点至少拥有其他给定数量个处于正常工作中的从节点的时候,才会分配从节点给集群中孤立的主节点。这个给定数量就是migration barrier。migration barrier 是1意味着一个从节点只有在其主节点另外至少还有一个正常工作的从节点的情况下才会被分配...
注:孤立的主节点:原本有slave,但slave离线的master,本身没有slave的master不属于孤立主节点。
min-slaves-to-write默认
master必须最少拥有的slave ,否则不允许写入 ,默认值为 0 ,表示禁用此特性

min-slaves-max-lag默认
限制slave延迟的最大时间,如超过这个时间,master拒绝写入
slave-serve-stale-data
设置从库是否可对外提供服务
- slave-serve-stale-data参数设置成yes,主从复制中,从服务器可以响应客户端请求;
- slave-serve-stale-data参数设置成no,主从复制中,从服务器将阻塞所有请求,有客户端请求时返回“SYNC with master in progress”
二、常见问题
2.1 redis链接超时
异常现象:
redis应用链接超时,zabbix监控链接超时获取不到监控数据 ,Linux系统层面,redis进程所在的cpu节点 ,cpu使用率100% ,可用内存比较多(free 比较小 ,cache比较多),磁盘写比较高,cpu sys 时间占比非常高。
磁盘现象:
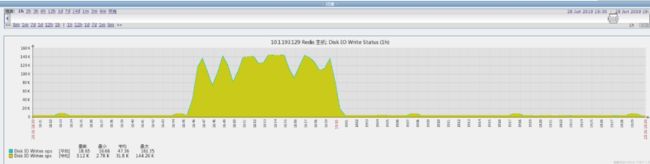
Cpu 现象:

内存状态:

分析:
通过查看redis错误日志,发现redis 6443实例正在执行aof rewrite操作。通过对比之前zabbix监控和aof rewrite时间点,几乎redis6443实例每次进行aof操作的时候 Linux出现以上现象(链接超时,cpu高) 。
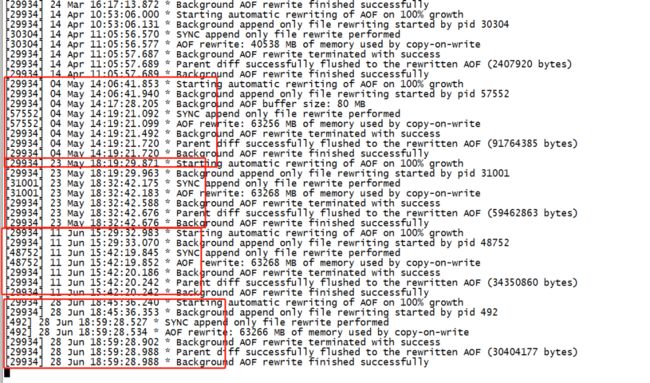
从日志中分析可以看出,在进行aof rewrite 的时,Linux额外分配了差不多60G的内存给redis的fork进程,而此时free内存不足60g理论上应该使用cache,但是从表象上看,并没有直接使用cache,而是在使用cache之前做了部分清理工作(cpu sys 时间比较高),腾出部分空闲空间 。
临时解决方案:清理cache
echo 1 > /proc/sys/vm/drop_caches
问题得到临时解决
永久解决方案:关掉 Linux的透明大页
临时关闭:
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
永久关闭
2.2 io 报错
I/O error reading bulk count from MASTER: Operation now in progress

调整 client-output-buffer-limit 解决
127.0.0.1:9003> config get client-output-buffer-limit
- "client-output-buffer-limit"
- "normal 0 0 0 slave 0 0 0 pubsub 33554432 8388608 60"
- 对于普通客户端来说,限制为0,也就是不限制。因为普通客户端通常采用阻塞式的消息应答模式,何谓阻塞式呢?如:发送请求,等待返回,再发送请求,再等待返回。这种模式下,通常不会导致Redis服务器输出缓冲区的堆积膨胀;
- 对于Pub/Sub客户端(也就是发布/订阅模式),大小限制是8M,当输出缓冲区超过8M时,会关闭连接。持续性限制是,当客户端缓冲区大小持续60秒超过2M,则关闭客户端连接;3. 对于slave客户端来说,大小限制是256M,持续性限制是当客户端缓冲区大小持续60秒超过64M,则关闭客户端连接。
2.3 aof文件损坏
出错过程:
实例在将aof文件读取到内存时,中断,redis进程自动关闭
日志报错:
# WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. [2716] 28 Apr 10:17:27.915 # Bad file format reading the append only file: make a backup of your AOF file, then use./redis-check-aof --fix
解决方法:
使用redis-check-aof修复aof文件,操作命令如下:
$:redis-check-aof --fix appendonly.aof
然后重新启动redis
2.4 新增节点至redis集群时报错
报错信息:
[ERR] Node 10.1.193.209:8006 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
原因:
新增节点不为空 解决:删除新增节点的node.file,aof文件,flushdb或者kill进程重新建立节点(有时候/var/run/下面没有进程文件,导致进程没有关闭)。到这里redis系列文章就暂时完结了,感谢大家的阅读和支持,后续将持续更新其他系列技术文章。
程序员的核心竞争力其实还是技术,因此对技术还是要不断的学习,关注 “IT 巅峰技术” 公众号 ,该公众号内容定位:中高级开发、架构师、中层管理人员等中高端岗位服务的,除了技术交流外还有很多架构思想和实战案例。
作者是 《 消息中间件 RocketMQ 技术内幕》 一书作者,同时也是 “RocketMQ 上海社区”联合创始人,曾就职于拼多多、德邦等公司,现任上市快递公司架构负责人,主要负责开发框架的搭建、中间件相关技术的二次开发和运维管理、混合云及基础服务平台的建设。