Stable-diffusion-webui本地部署和简要介绍
Stable Diffusion 是一款基于人工智能技术开发的绘画软件,它可以帮助艺术家和设计师快速创建高品质的数字艺术作品。是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,同时也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的翻译。
Stable Diffusion 项目本地化的部署,是纯代码界面,而Stable Diffusion WebUI,是基于 Stable Diffusion 项目的可视化操作项目。这里我们也是部署Stable Diffusion WebUI。
本地部署StableDiffusion UI
前置条件
在部署StableDiffusion前,如果instance是GPU的instance,需要安装Nividia的driver,如果对安装dirver等不熟悉,可查看我之前的博客“AWS instance上部署大模型”
按前置条件准备好instance环境后,就可以按照StableDiffusion官网的步骤快速安装StableDiffusion UI了。命令如下图所示,因为我自己的instance是ubuntu,属于Debian-based,所以,执行第一行的命令,安装相关的依赖。
# Debian-based:
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
# Red Hat-based:
sudo dnf install wget git python3 gperftools-libs libglvnd-glx
# openSUSE-based:
sudo zypper install wget git python3 libtcmalloc4 libglvnd
# Arch-based:
sudo pacman -S wget git python3一键安装stable-diffusion-webui
安装了基础依赖包后,下载webui.sh文件,执行该文件,即可一键完成stable-diffusion-webui的安装。具体命令如下图所示:
#下载shell脚本
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
#给文件分配执行权限
chmod -x webui.sh
#执行shell文件
./webui.sh
执行shell文件后,可以看到整个shell文件大致完成了三个任务。
第一:创建python虚拟环境并激活
第二:通过python执行launch.py文件,这也是stable-diffusion-webui的入口文件。
第三:执行launch.py文件时,会下载stable-diffusion的模型参数文件,即后缀是.safetensors的文件,最后启动整个webui应用。stable-diffusion-webui的前端是用gradio写的,默认启动在7860端口。
如果是在本机上运行,执行完上面的命令,就可以在浏览器中输入“http://127.0.0.1:7860”访问应用了。我的实验是在aws的instance上进行,所以需要在security group的inbound 中开放7860端口。另外,执行了下面的命令,将aws上instance的端口与自己的本地电脑端口做了映射,如果不做映射,无法在外面本地电脑上直接访问127.0.0.1 或者localhost等地址。当然,还有第二个办法,就是修改gradio的默认地址,将127.0.0.1修改成0.0.0.0也可以。
# -L 7860:localhost:7860: 设置本地端口转发,将本地端口 7860 转发到远程主机的本地回环地址(localhost)的端口 7860。
# 这种端口转发允许你在本地访问远程主机上的服务
ssh -i /Users/taoli/Downloads/taoli-tokyo.pem -N -f -L 7860:localhost:7860 ubuntu@aws public instance ip在本地浏览器上访问到的stable-diffusion-webui的界面如下图所示,这里的checkpoint list就是stablediffusion模型列表,在安装的时候默认下载了v1-5这个基础模型。

stable-diffusion-webui代码目录如下图所示,extensions下面放下载的所有插件,models下面放下载的所有模型,models下面又分了Stable-diffusion,Lora,VAE等目录,因为除了主模型外,还有很多用于特定作用的模型,例如Lora就是用于模型微调的。安装时下载的主模型存放在Stable-diffusion目录下面。

一些主要的模型以及其作用汇总如下图所示:

Stable-Diffusion-WebUI提供的主要功能
txt2image功能
顾名思义,通过文本生成图片,在生成图片的时候分prompt和negative prompt。prompt很容易理解,期望生成怎样的图片,在prompt中描述即可。negative prompt的含义是:不期望图片中生成的东西,例如写black hair在negative prompt中,理想情况下生成的图片中,人物都不是黑头发。
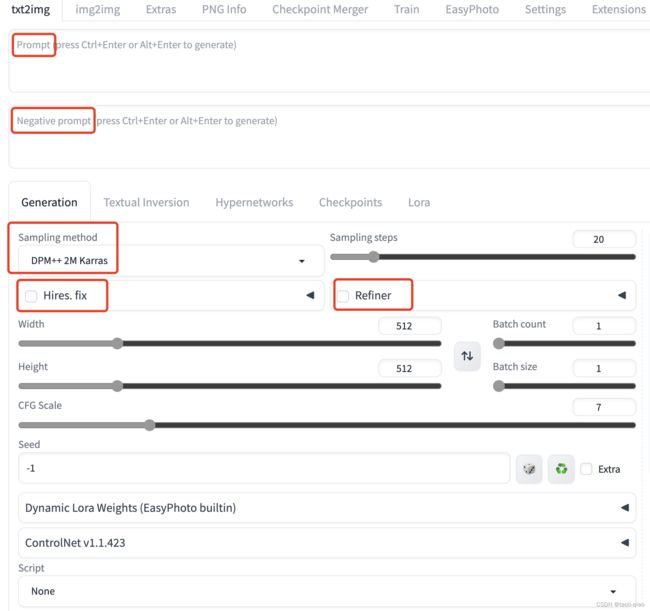
除了prompt,还有Sampling method,工具中提供了很多Sampling method。我们知道 sd webui 生成图像,大致会经过以下过程:
1、为了生成图像, Stable Diffusion 会在潜在空间中生成一个完全随机的图像
2、噪声预测器会估算图像的噪声
3、噪声预测器从图像中减去预测的噪声
4、这个过程反复重复 N 次以后,会得到一个干净准确的图像
这个去噪的过程,就被称为采样。采样中使用的方法被称为 Sampling method (采样方法或者是采样器)。总结而言不同采样器的特点大致如下:
- 如果想快速生成质量不错的图片,建议选择 DPM++ 2M Karras (20 -30步) 、UNIPC (15-25步)
- 如果想要高质量的图,不关心重现性,建议选择 DPM++ SDE Karras (10-15步 较慢) ,DDIM(10-15步 较快)
- 如果想要简单的图,建议选择 Euler, Heun(可以减少步骤以节省时间)
- 如果想要稳定可重现的图像,请避免选择任何祖先采样器(名字里面带a或SDE)
- 相反,如果想要每次生成不一样的图像,可以选择不收敛的祖先采样器(名字里面带a或SDE)
Hires.fix是Stable Diffusion中文网提供的一个功能,用于高清修复生成的图片。 通过应用Hires.fix,可以将图像放大并提高分辨率,以获得更清晰的结果。 这是一个非常实用的功能,可以提高图片的质量并满足您的需求。 无论是在打印还是在网络上展示,修复后的高清图片都能够给观看者带来更好的视觉体验。
Image2image功能
Image2Image的功能,顾名思义就是通过图片生成另外的图片,这里除了生成图片外,还有Inpaint功能,即如果只想修改原图中的某个部分,则使用Inpaint功能。如下图所示:将原图的人物头像换成了根据prompt中新生成的头像。

在Inpaint过程中,有两个关键参数CFG scale和Masked Content,需要理解其含义。
CFG scale:与文生图中的CFG类似,表示生成的图片要follow prompt的程度
1:基本忽略prompt
3:带些创造性
7:创造性与prompt之间的一个较好的平衡
15:紧跟prompt提示走
30:完全follow prompt
Masked content:控制覆盖的区域如何初始化
Fill:使用原图的高模糊图作为初始化
Original:无修改
Latent noise:先使用fill的模式对masked区域做初始化,然后再加入随机噪点到latent 空间
Latent nothing:与latent noise类似,但是不加入随机噪点
Extras功能
附加功能的主要作用就是:把一张小图、模糊的图、有噪点的图,放大、清晰化处理为更大的图。如下图所示,生成的图片比原始图片更大了。
除了上面的三个主功能外,在web ui上还可以安装各种插件,在Extension界面上进行安装。如下图所示:可以选择需要安装的插件,点击install后,就会下载插件,并存放在web-ui的extensions目录下。如果要让插件生效,需要重启应用(即执行python3 launch.py命令即可)。安装某些插件后,webui上会出现新的tab页,例如,EasyPhoto就是安装对应插件后才出现的新tab。

除了上面介绍的功能外,web-ui界面上还有Settings tab,主要用于设置各类参数。还有Checkpoint merger功能,主要用于合并多个模型成一个模型,并设置不同模型的权重。
以上就是对Stable-Diffusion-WebUI的主要功能的简要介绍,对于某些功能,后面还会在专门的博客中做详细介绍。