MIT 6.S081学习笔记(第六章)(上)
〇、前言
本文主要完成:
- MIT 6.S081 实验六:Multithreading;
开始之前,切换分支:
$ git fetch
$ git checkout thread
$ make clean
- 对知识的回顾。
一、线程
1、线程概述
为什么需要线程?为了提升性能,单核性能已经很难提升,CPU 的频率几乎已经提升不了多少了,但是可以通过提升CPU 计算单元数来提高算力。
#include 什么是线程?线程就是一个执行单元,或者是一个串行执行代码的单元,也是编程的一个抽象。比如写一个简单的 hello world 打印函数 main()就可以理解为一个线程单元,被称为主线程,当然可以在这里通过创建新的线程或者 fork() 得到子进程来并发执行,分配更多的 CPU 来并行执行多个线程通过协作更快得完成同一个任务。比如底下的代码就是通过多线程来打印 hello world:
#include 虽然这里有夸张(没人完成这么简单的任务还用两个线程),但是至少能说明多个线程可以通过合作来完成同一个任务。
这里再顺便说说我们平时说的线程和进程之间的区别,谈谈自己的看法。在 Linux 中,一个进程就是一个进程,进程中也可以跑多个线程。不仅仅是进程之间可以并发,进程中也可以通过创建不同的线程来实现在线程之间的并发。
为了提高性能同时降低切换上下文带来的开销,我们更倾向于把一个任务编排在同一个进程中,而不是写两个进程(比如上面的多进程打印 hello world)。换句话说,一个活动最好是一个进程单元,而为了提高这个进程单元的执行速度,最大化利用 CPU 多核心性能,可以在这个进程中创建多个线程来完成任务。毕竟进程太大,切换上下文相当复杂,xv6 中的trapframe 太大,而线程中的 context 则小得多。以下是多线程打印 hello world:
#include 其中 printed_hello = 1 来控制打印顺序。虽然也有点夸张(这 hello world 不打印也罢!),但是却能很好地说明通过线程并发来共同完成一个任务的事实。
除此之外,线程还具有状态,我们可以随时保存线程的状态并暂停线程的运行,并在之后通过恢复状态来恢复线程的运行。线程的状态包含了三个部分:
- 程序计数器(Program Counter),它表示当前线程执行指令的位置;
- 保存变量的寄存器;
- 程序的Stack。
操作系统中线程系统的工作就是管理多个线程的运行。我们可能会启动成百上千个线程,而线程系统的工作就是弄清楚如何管理这些线程并让它们都能运行。
多线程的并行运行主要有两个策略:
- 第一个策略是在多核处理器上使用多个CPU,每个CPU都可以运行一个线程,如果你有4个CPU,那么每个CPU可以运行一个线程。每个线程自动的根据所在CPU就有了程序计数器和寄存器。
- 一个CPU在多个线程之间来回切换。
实际上,与大多数其他操作系统一样,xv6结合了这两种策略,首先线程会运行在所有可用的CPU核上,其次每个CPU核会在多个线程之间切换,因为通常来说,线程数会远远多于CPU的核数。
不同线程系统之间的一个主要的区别就是,线程之间是否会共享内存。一种可能是你有一个地址空间,多个线程都在这一个地址空间内运行,并且它们可以看到彼此的更新。比如说共享一个地址空间的线程修改了一个变量,共享地址空间的另一个线程可以看到变量的修改。所以当多个线程运行在一个共享地址空间时,我们需要用到锁。
xv6内核共享了内存,并且XV6支持内核线程的概念,对于每个用户进程都有一个内核线程来执行来自用户进程的系统调用。所有的内核线程都共享了内核内存,所以xv6的内核线程的确会共享内存。
2、xv6 线程调度
实现内核中的线程系统存在以下挑战:
- 第一个是如何实现线程间的切换。这里停止一个线程的运行并启动另一个线程的过程通常被称为线程调度(Scheduling)。xv6为每个CPU核都创建了一个线程调度器(Scheduler)。
- 第二个挑战是,当你想要实际实现从一个线程切换到另一个线程时,你需要保存并恢复线程的状态,所以需要决定线程的哪些信息是必须保存的,并且在哪保存它们。
- 最后一个挑战是如何处理运算密集型线程(compute bound thread)。对于线程切换,很多直观的实现是由线程自己自愿的保存自己的状态,再让其他的线程运行。但是如果我们有一些程序正在执行一些可能要花费数小时的长时间计算任务,这样的线程并不能自愿的出让CPU给其他的线程运行。所以,就要用到时间中断来让内核占有 CPU。
在xv6和其它的操作系统中,线程调度是这么实现的:定时器中断会强制的将CPU控制权从用户进程给到内核,这里是pre-emptive scheduling,之后用户内核线程使用 voluntary scheduling 让出 CPU。
在执行线程调度的时候,操作系统需要能区分几类线程:
- 当前在CPU上运行的线程;
- 一旦CPU有空闲时间就想要运行在CPU上的线程;
- 以及不想运行在CPU上的线程,因为这些线程可能在等待I/O或者其他事件。
这里不同的线程是由状态区分,下面是我们将会看到的一些线程状态:
- RUNNING,正在执行的线程;
- RUNNABLE,就绪线程,可以随时执行;
- SLEEPING,休眠的线程,调度器不会给它分配时间片或者调度它,它在等待某些事件发生(比如I/O)。
xv6 中给到状态有:
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
我们主要关注RUNNING和RUNNABLE这两类线程。
对于RUNNING状态下的线程,它的程序计数器和寄存器位于正在运行它的CPU硬件中。而RUNNABLE线程,因为并没有CPU与之关联,所以对于每一个RUNNABLE线程,当我们将它从RUNNING转变成RUNNABLE时,我们需要将它还在RUNNING时位于CPU的状态拷贝到内存中的某个位置,注意这里不是从内存中的某处进行拷贝,而是从CPU中的寄存器拷贝。我们需要拷贝的信息就是程序计数器(Program Counter)和寄存器。
当线程调度器决定要运行一个RUNNABLE线程时,这里涉及了很多步骤,但是其中一步是将之前保存的程序计数器和寄存器拷贝回调度器对应的CPU中。
3、xv6 线程切换
当用户程序在运行时,实际上是用户进程中的一个用户线程在运行。如果程序执行了一个系统调用或者因为响应中断走到了内核中,那么相应的用户空间状态会被保存在程序的 trapframe中,同时属于这个用户程序的内核线程被激活(进入到内核处理线程中)。
所以首先,用户的程序计数器,寄存器等等被保存到了 trapframe 中,之后CPU被切换到内核栈上运行,实际上会走到 trampoline 和 usertrap 代码中。之后内核会运行一段时间处理系统调用或者执行中断处理程序。在处理完成之后,如果需要返回到用户空间,trapframe中保存的用户进程状态会被恢复。
除了系统调用,用户进程也有可能是因为CPU需要响应类似于定时器中断走到了内核空间。上面提到的pre-emptive scheduling,会通过时钟中断将CPU运行切换到另一个用户进程。
在定时器中断程序中,如果xv6内核决定从一个用户进程切换到另一个用户进程,那么首先在内核中第一个进程的内核线程会被切换到第二个进程的内核线程。之后再在第二个进程的内核线程中返回到用户空间的第二个进程,这里返回也是通过恢复 trapframe 中保存的用户进程状态完成。
当 xv6 从A程序的内核线程切换到B程序的内核线程时:
- xv6会首先会将A程序的内核线程的内核寄存器保存在一个context对象中;
- 类似的,因为要切换到B程序的内核线程,那么B程序现在的状态必然是RUNNABLE,表明B程序之前运行了一半。这同时也意味着B程序的用户空间状态已经保存在了对应的 trapframe 中,更重要的是,B程序的内核线程对应的内核寄存器也已经保存在对应的 context 对象中。所以接下来,xv6会恢复B程序的内核线程的context对象,也就是恢复内核线程的寄存器;
- 之后B程序会继续在它的内核线程栈上,完成它的中断处理程序(注,假设之前B程序也是通过定时器中断触发的pre-emptive scheduling进入的内核)。
- 然后通过恢复B程序的trapframe中的用户进程状态,返回到用户空间的B程序中。
- 最后恢复执行B程序。
这里核心点在于,在xv6中,任何时候都需要经历:
- 从一个用户进程切换到另一个用户进程,都需要从第一个用户进程接入到内核中,保存用户进程的状态并运行第一个用户进程的内核线程;
- 再从第一个用户进程的内核线程切换到第二个用户进程的内核线程;
- 之后,第二个用户进程的内核线程暂停自己,并恢复第二个用户进程的用户寄存器;
- 最后返回到第二个用户进程继续执行。
这是一个相当曲折的一个线路,但是实际的线程切换流程会更复杂。
假设我们有进程P1正在运行,进程P2是RUNNABLE当前并不在运行。假设在xv6中我们有2个CPU核,这意味着在硬件层面我们有 CPU0 和 CPU1 。
我们从一个正在运行的用户空间进程切换到另一个RUNNABLE但是还没有运行的用户空间进程的更完整的故事是:
- 首先与我之前介绍的一样,一个定时器中断强迫CPU从用户空间进程切换到内核,trampoline代码将用户寄存器保存于用户进程对应的trapframe对象中;
- 之后在内核中运行usertrap,来实际执行相应的中断处理程序。这时,CPU正在进程P1的内核线程和内核栈上,执行内核中普通的C代码;
- 假设进程P1对应的内核线程决定它想出让CPU,它会做很多工作,这个我们稍后会看,但是最后它会调用swtch函数(译注:switch 是C 语言关键字,因此这个函数命名为swtch 来避免冲突),这是整个线程切换的核心函数之一;
- swtch函数会保存用户进程P1对应内核线程的寄存器至context对象。所以目前为止有两类寄存器:用户寄存器存在trapframe中,内核线程的寄存器存在context中。
以下是 xv6 内核的源码:
// interrupts and exceptions from kernel code go here via kernelvec,
// on whatever the current kernel stack is.
void
kerneltrap()
{
int which_dev = 0;
uint64 sepc = r_sepc();
uint64 sstatus = r_sstatus();
uint64 scause = r_scause();
if((sstatus & SSTATUS_SPP) == 0)
panic("kerneltrap: not from supervisor mode");
if(intr_get() != 0)
panic("kerneltrap: interrupts enabled");
if((which_dev = devintr()) == 0){
printf("scause %p\n", scause);
printf("sepc=%p stval=%p\n", r_sepc(), r_stval());
panic("kerneltrap");
}
// give up the CPU if this is a timer interrupt.
if(which_dev == 2 && myproc() != 0 && myproc()->state == RUNNING)
yield();
// the yield() may have caused some traps to occur,
// so restore trap registers for use by kernelvec.S's sepc instruction.
w_sepc(sepc);
w_sstatus(sstatus);
}
可以看到如果 devintr()返回为 2,那么就是一个时钟终端,进而调用 yield():
// Give up the CPU for one scheduling round.
void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}
yield()函数干了很简单的事,它拿到当前进程之后,修改当前 p->state 为 RUNNALBE。至于这里为什么加锁,这个很好理解,每个进程都有一个锁,称为进程锁。这个锁如果不加,直接修改为 RUNNABLE,那么在 sched() 之前,可能会有其它CPU 看到它是 RUNNABLE,就会给他分配 CPU,这样一个线程就会执行在两个 CPU 上(当前 CPU 仍然在运行它),这就是严重错误。
// Switch to scheduler. Must hold only p->lock
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->noff, but that would
// break in the few places where a lock is held but
// there's no process.
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}
可以看到 sched()开始要做一些重要的事情了,它首先进行了一些错误检查,然后开始调用swtch(&p->context, &mycpu()->context)。函数swtch()很重要,也很无脑。它直接将当前 CPU 中的寄存器中的值保存到 p->context,然后将当前 CPU 中的mycpu()->context 恢复到当前 CPU寄存器,有点像“打扫屋子另请客”。
# Context switch
#
# void swtch(struct context *old, struct context *new);
#
# Save current registers in old. Load from new.
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret
更加美妙的是,把寄存器更新之后,swtch()返回的地址是 scheduler(),然后开始执行进程调度程序。
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// The most recent process to run may have had interrupts
// turned off; enable them to avoid a deadlock if all
// processes are waiting.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
可以看到这个调度算法相当简单,它从一个进程数组里,循环找到第一个状态为 RUNNALE 的进程,然后继续简单暴力地执行 swtch()函数,将当前 CPU 的寄存器保存到 c->context 中,然后将被选中的进程的 p->context恢复到 CPU 寄存器中,又是“打扫屋子另请客”。
之后就切换完了,CPU 继续执行代码。首先执行:
void
sched(void)
{
...
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena; // 继续执行该行代码
}
然后返回到:
// Give up the CPU for one scheduling round.
void
yield(void)
{
...
sched();
release(&p->lock); // 继续执行,释放多余的锁?这里其实释放的是调度程序中选中程序的锁
}
然后返回到:
// interrupts and exceptions from kernel code go here via kernelvec,
// on whatever the current kernel stack is.
void
kerneltrap()
{
...
// give up the CPU if this is a timer interrupt.
if(which_dev == 2 && myproc() != 0 && myproc()->state == RUNNING)
yield();
// the yield() may have caused some traps to occur,
// so restore trap registers for use by kernelvec.S's sepc instruction.
w_sepc(sepc); // 恢复 sepc ,继续执行
w_sstatus(sstatus);
}
然后继续执行内核线程,完成其它内核中断操作,如恢复 trapframe 等,进入到目标用户空间。
这样就完成了两个用户线程的调度并切换。一个简单的流程图像这样:

当然,这个图太简单了,更复杂的流程图就像这样:

4、继续讨论几个问题
实际上swtch函数并不是直接从一个内核线程切换到另一个内核线程。xv6中,一个CPU上运行的内核线程可以直接切换到的是这个CPU对应的调度器线程。
所以如果我们运行在CPU0,swtch函数会恢复之前为CPU0的调度器线程保存的寄存器和stack pointer,之后就在调度器线程的 context 下执行 schedulder函数中。
每一个CPU都有一个完全不同的调度器线程。调度器线程也是一种内核线程,它也有自己的context对象。任何运行在CPU1上的进程,当它决定出让CPU,它都会切换到CPU1对应的调度器线程,并由调度器线程切换到下一个进程。
这里有一个术语需要解释一下。当人们在说context switching,他们通常说的是从一个线程切换到另一个线程,因为在切换的过程中需要先保存前一个线程的寄存器,然后再恢复之前保存的后一个线程的寄存器,这些寄存器都是保存在context对象中。
在有些时候,context switching 也指从一个用户进程切换到另一个用户进程的完整过程。也会看到context switching是指从用户空间和内核空间之间的切换。对于我们来说,context switching主要是指一个内核线程和调度器线程之间的切换。
这里有一些有用的信息可以记住。每一个CPU核在一个时间只会做一件事情,每个CPU核在一个时间只会运行一个线程,它要么是运行用户进程的线程,要么是运行内核线程,要么是运行这个CPU核对应的调度器线程。
所以在任何一个时间点,CPU核并没有做多件事情,而是只做一件事情。线程的切换创造了多个线程同时运行在一个CPU上的假象。类似的每一个线程要么是只运行在一个CPU核上,要么它的状态被保存在context中。线程永远不会运行在多个CPU核上,线程要么运行在一个CPU核上,要么就没有运行。
在xv6的代码中,context对象总是由swtch函数产生,所以context总是保存了内核线程在执行swtch函数时的状态。当我们在恢复一个内核线程时,对于刚恢复的线程所做的第一件事情就是从之前的swtch函数中返回。
另一件需要注意的事情是,swtch函数是线程切换的核心,但是swtch函数中只有保存寄存器,再加载寄存器的操作。线程除了寄存器以外的还有很多其他状态,它有变量,堆中的数据等等,但是所有的这些数据都在内存中,并且会保持不变。
我们没有改变线程的任何栈或者堆数据。所以线程切换的过程中,处理器中的寄存器是唯一的不稳定状态,且需要保存并恢复。而所有其它在内存中的数据会保存在内存中不被改变,所以不用特意保存并恢复。我们只是保存并恢复了处理器中的寄存器,因为我们想在新的线程中也使用相同的一组寄存器。
还有一个问题,当调用swtch函数的时候,实际上是从一个线程对于switch的调用切换到了另一个线程对于switch的调用。所以线程第一次调用swtch函数时,需要伪造一个“另一个线程”对于switch的调用。
来看一下第一次调用swtch时,“另一个”调用swtch函数的线程的context对象。proc.c文件中的allocproc函数会被启动时的第一个进程和fork调用,allocproc会设置好新进程的context,如下所示:
// Look in the process table for an UNUSED proc.
// If found, initialize state required to run in the kernel,
// and return with p->lock held.
// If there are no free procs, or a memory allocation fails, return 0.
static struct proc*
allocproc(void)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
}

在第一次fork()的时候(创建第一个用户进程的时候?无所谓,反正就是第一次 fork()的时候),进程需要切换到 B(假设每个进程执行一个线程),这时候A进程进入内核后,开始调用swtch()。swtch()保存 A内核线程的上下文,恢复调度器线程的上下文,调度器开始工作,终于选了一个 B 进程,并恢复它的上下文并打算让它开始运行。但是 B 进程的context 是空的,怎么办?
就如前面说的,当第一次使用 fork()时,proc.c文件中的allocproc函数会被调用,allocproc会设置好B进程的context:
static struct proc*
allocproc(void)
{
...
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
}
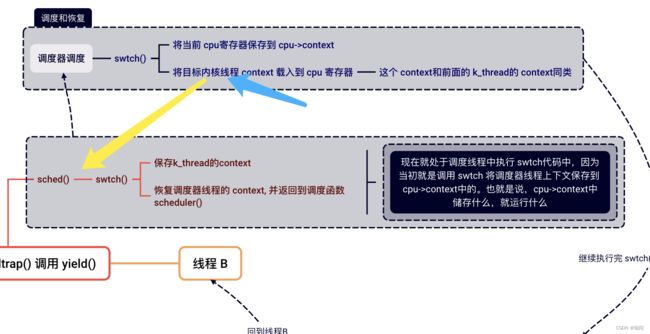
一般来说,此时swtch()返回的地址应该为目标进程上次调用 swtch()的sched()中:

这个 ra的值是什么呢?

可以看到,确实是这个 sched()。
因此,在这个问题,ra和sp都被设置了。这里设置的forkret函数就是进程的第一次调用swtch函数会切换到的“另一个”线程位置。
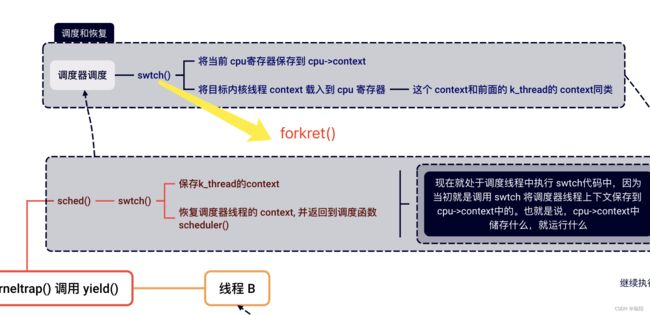
所以当swtch函数返回时,CPU会执行forkret中的指令,就像forkret刚刚调用了swtch函数并且返回了一样。
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void
forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
fsinit(ROOTDEV);
first = 0;
// ensure other cores see first=0.
__sync_synchronize();
}
usertrapret();
}
可以看到,它的工作其实就是释放调度器之前获取的锁。并且第一次运行时,完成了一些初始化工作fsinit(ROOTDEV)。函数最后的usertrapret函数其实也是一个假的函数,它会使得程序表现的看起来像是从trap中返回,但是对应的trapframe其实也是假的,这样才能返回到 userspace,跳到用户的第一个指令中。
void
scheduler(void)
{
...
swtch(&c->context, &p->context); // 底下的锁没有释放到
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
与之前的context对象类似的是,对于trapframe也不用初始化任何寄存器,因为我们要去的是程序的最开始,所以不需要做任何假设,对吗?其实程序计数器还是要被初始化为0的。
因为fork拷贝的进程会同时拷贝父进程的程序计数器,所以我们唯一不是通过fork创建进程的场景就是创建第一个进程的时候。这时需要设置程序计数器为0。
// Set up first user process.
void
userinit(void)
{
...
// prepare for the very first "return" from kernel to user.
p->trapframe->epc = 0; // user program counter
...
}
全文完,明天写下半篇,感谢阅读。